Remove Stopwords From a Block of Text
This chapter will guide you through removing stopwords, and by the end, you will have created a much clearer version of the previous chapter’s word cloud.
Count Word Frequencies
First, let’s download the Wikipedia Earth page’s content in a friendly text format using the wikipedia_page(title) function defined in the previous chapter.
import requests
# Get the Earth page
text = wikipedia_page('Earth').lower()
# Print the beginning of the text
print(text[:200] + '...')Now that you have downloaded the text, the next step is to count each word’s frequency. It will help identify non-subject-specific words that appear too frequently (and, or, the, are, etc.).
Remember the definition of stopwords?
Stopwords are words that do not provide any useful information to infer the content or nature of a text. It may be because they don’t carry any meaning (prepositions, conjunctions, etc.) or because they are too frequent.
Counting word frequencies is a three-step process:
The first step is to create a list of the most frequent words by splitting the text over the whitespace character
' 'with the functiontext.split(' ').Then, count how many times each word appears in the text using the
Counterfunction.
from collections import Counter
# we transform the text into a list of words
# by splitting over the space character ' '
word_list = text.split(' ')
# and count the words
word_counts = Counter(word_list)The result: word_counts is a dictionary. Each key is a unique word from the text. Each value is the number of times that word appears in the text.
Here is the list of the 20 most common words with
word_counts.most_common(20).
for w in word_counts.most_common(20):
print(f"{w[0]}: \t{w[1]} ")Returns:
the: 674
of: 330
and: 230
is: 173
to: 157
in: 145
a: 124
earth: 78
from: 75
earth's: 75
by: 69
that: 63
as: 57
at: 56
with: 52Remove Stopwords
It’s time to eliminate the meaningless words from that list.
# transform the text into a list of words
words_list = text.split(' ')
# define the list of words you want to remove from the text
stopwords = ['the', 'of', 'and', 'is','to','in','a','from','by','that', 'with', 'this', 'as', 'an', 'are','its', 'at', 'for']
# use a python list comprehension to remove the stopwords from words_list
words_without_stopwords = [ word for word in words_list if word not in stopwords ]Note the last line is equivalent to this code:
words_without_stopwords = []
for word in words_list:
if word not in stopwords:
words_without_stopwords.append(word)I personally prefer the more concise list comprehension over four lines of code.
The list of the top 20 most frequent words is now very different:
Counter(words_without_stopwords).most_common(20)Returns:
[('earth', 78), ("earth's", 75), ('on', 50), ('about', 45), ('solar', 36), ('million', 36), ('surface', 34), ('life', 30), ('it', 30), ('sun', 26), ('other', 26), ('has', 26), ('was', 26), ('have', 25), ('or', 25), ('than', 23), ('which', 22), ('be', 22), ('over', 21), ('into', 21)]The top 20 now contain multiple meaningful words such as million, surface, life, solar, and sun. Although there are still some stopwords we could get rid of (on, it, has, etc.), you can see that removing only a handful improves the value of the word cloud.

Use a Predefined List of Stopwords
There is no fixed or optimal list of stopwords in any language. Whether a word brings valuable information or not depends on the context. For example, temperature numbers would be significant for a text about the weather but less so for a text about songs or legal documents.
All major NLP libraries come with their own predefined set of stopwords. You can find very extensive and thorough lists online.
You can find stopwords in several languages in this GitHub repo.
You can find stopwords compiled from multiple sources in this GitHub repo.
The word cloud library comes with a predefined list of 192 stopwords. Here are the 20 from that list:
print(list(WordCloud().stopwords)[:20])Returns:
> ['because', 'i', 'myself', "shouldn't", 'down', 'your', 'above', 'been', "i'm", 'again', 'that', 'during', 'being', 'was', 'before', "wasn't", 'ought', 'and', 'own', 'both']You can also set your own list of stopwords with the stopwords parameter WordCloud(stopwords = [...]) , but the word cloud library will default to its own list.
Let’s put this default list of stopwords into action and see what happens.
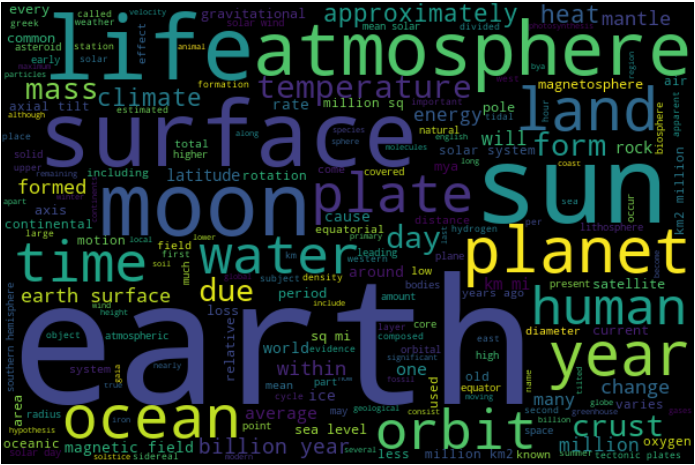
Let’s Recap!
You can obtain the list of all the words of a text by splitting over whitespaces.
To remove stopwords, simply define a list of words you want to remove from the text.
There is no fixed or optimal list of stopwords in each language. They depend on your context.
By default, if you do not specify a
stopwordparameter value, thewordcloudlibrary uses the built-in list of 192 stopwords.
In this chapter, you learned a simple but crude method to get a list of all the words in a given text by splitting over its whitespaces. This process is called tokenization, which is the subject of the next chapter!
