Determine Your Primary Keys
Up to now, you've seen that UML classes translate into tables. We’re going to look closer at these tables to analyze their component parts (i.e., rows and columns).
To begin with, you’ll see how the relational model allows you to identify a row within a table.
Identify the Primary Keys
Learn to Identify the Rows Within a Table
Do you remember that you need to ensure that each data item exists only once within the database to avoid redundancy?
Only having each data item exist once implies that there must not be two rows describing the same production in a table (e.g., Production ).
Production will contain exactly the same number of rows as the number of productions with movie scenes stored in your CSV file.
But how do you ensure that two rows in the production table refer to two different productions? In other words, how do you distinguish between two rows?
This question is fundamental to identity. You are unique - and your identity guarantees it. Two people can’t have the same identity, and one person can’t have more than one (legally — but that’s another story!).
In an RDBMS, every row must have an identifier.
A row identifier is called the primary key.
What does this mean?
If you're sure that you can retrieve any database row by knowing the value of some of its attributes, it means that these attributes make up the primary key.
This diagram will help to illustrate the idea:
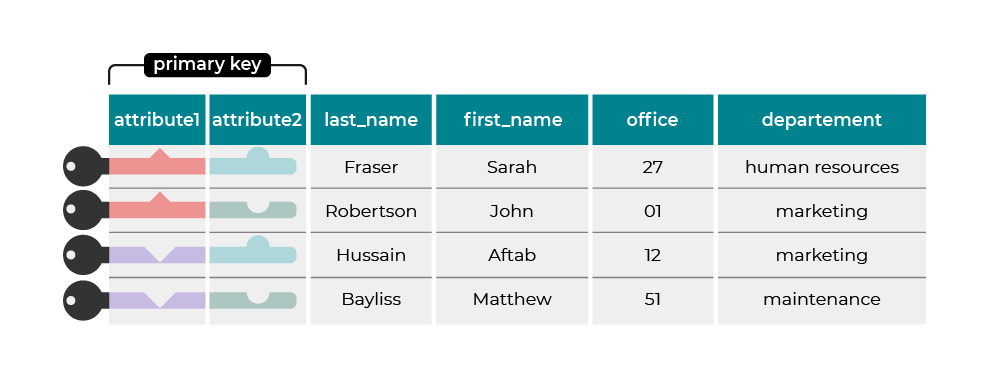
Let’s take a more concrete example. The concept of identification is essential for postal delivery workers who need to identify residences with certainty to deliver the mail. Imagine a table that holds residential details with the following columns:
Type of residence (house, apartment, etc.).
The number of bedrooms.
Residence number (e.g., apartment number 2).
Property number (e.g., 523).
Street name (e.g., Montrose Ave.).
Town/City (e.g., Chicago).
Zip code.
County.
Country.
This table’s primary key will be the minimum set of columns you can give to the postal delivery worker to ensure that they can deliver the mail to the correct residence.
If you just give them the street name , zip code , and town/city (i.e., Montrose Ave, Chicago, IL 60618), they will have difficulty delivering the mail because Montrose Avenue has many residential properties.
If you give them all these attributes, they can deliver the mail correctly. However, the set of columns 1 to 9 isn't considered minimal: you don’t need to know the number of bedrooms to deliver mail. Therefore, the number of bedrooms doesn't need to form part of the primary key.
A good primary key for this table would include attributes 3 to 9. Even if you don't need to know the residence number for a house, it's still important to have it in the table’s primary key to identify the different apartments within the same building.
In other words, you can't use ( street name , zip code ) as a primary key because rows “ 4300 N Lincoln Ave , 60618 ” and “ 4340 N Lincoln Ave, 60618 ” both have the same values for ( street name , zip code ) i.e., Lincoln Ave and 60618 . This set of attributes would violate the uniqueness constraint.
Now it's Your Turn!

Okay, now you're ready to determine the primary keys for your model. Here’s the model in its current form:
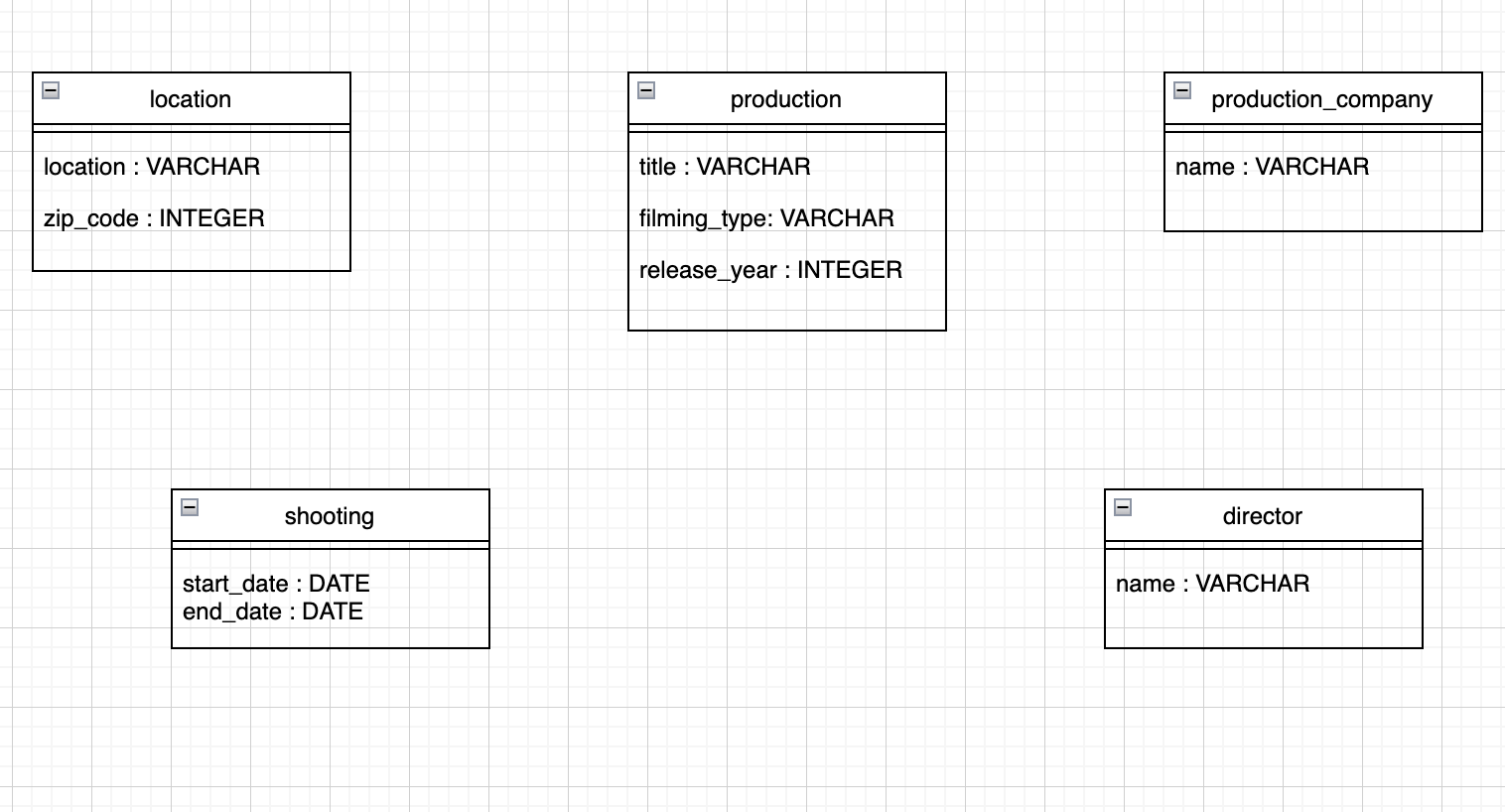
Tables ProductionCompany and director
There isn’t much choice for the ProductionCompany and director tables. So use the name attribute for both tables. Of course, this assumes that there aren't two production companies or directors with the same name. It’s doubtful, so consider the name a good primary key for these two tables.
Table location
There are three possible primary keys for the location table:
Attribute set (
location).Attribute set (
location,zip code).Hypothetical attribute set (
location,zip code,latitude,longitude).
You would have to assume that location includes at least the street name and the town/city in the first instance. The uniqueness constraint would be met in this case because one town/city can't have two street names. Even if there are towns or cities with the same name, the street name allows you to distinguish them. Assuming this condition is met, you could identify on which road a particular production was filmed with this primary key.
However, this solution has certain disadvantages. First of all, you can’t guarantee the people entering the data will put the full address or enter it in a standard way. For example, nothing forces them to provide the town/city name. They could enter the zip code, but that's already present in the zip code attribute. Hello, redundancy! Also, the user can type an address differently (e.g., 4772 N Lincoln St vs. 4772 N Lincoln Street) making it difficult to spot duplicates!
The second solution somewhat circumvents this problem. The user has to enter the zip code to distinguish locations (i.e., an address in the suburb of San Francisco has the same address as one in the city).
The third (hypothetical) key introduces latitude and longitude. This data exists but is not stored in the example shown. You might think this would be a good primary key and consider including it. However, this one has a problem of its own: precision. Should you consider a latitude-longitude pair (48.87512, 2.348979) as different from the pair (48.87506, 2.348963), even though these two locations are only three feet apart on the same street and essentially describe the same filming location?
Tables production and shooting
It’s impossible (for the moment) to identify a primary key for the production and shooting tables.
In the UML composition chapter , we said different films could have the same name. Therefore, if you want to identify a film uniquely, you need its title and the production company name, which proves a dependency between these two classes.
The problem is that the production table does not currently contain an attribute holding the production company’s name. You can’t have a primary key without this attribute.
There are only two attributes in the shooting table: start date and end date .
Two shooting events (for two different films in two different locations) might start and end on exactly the same dates, which means you can’t make it unique.
A Note on Notation and Diagrams
Attributes that make up the primary key in diagrams are most commonly shown in the central section of the table’s box, while all the other attributes are in the bottom section. But sometimes, you will come across formats that are not the same as those in this course. For example, the primary key might be in bold or underlined. It might also be indicated against the attributes using the abbreviation “PK.”
![Diagram of the relational model with primary keys indicated using [PK]](https://user.oc-static.com/upload/2022/04/13/16498870964727_image10.png)
Create Artificial Primary Keys
Sometimes, it’s impossible to find a primary key within the attributes of a table. Other times, the primary key is too complicated (e.g., too many attributes). In these cases, you can create an artificial key (also known as a surrogate key).
For example, your Social Security and Passport numbers are artificial keys that enable a U.S. citizen to be identified.
Let’s take this extract from your CSV file as an example:

If you transform the data to fit your relational model (with two tables: production and production_company , with a foreign key prod_company ) by adding artificial keys, you could be tempted to cut the file in half:
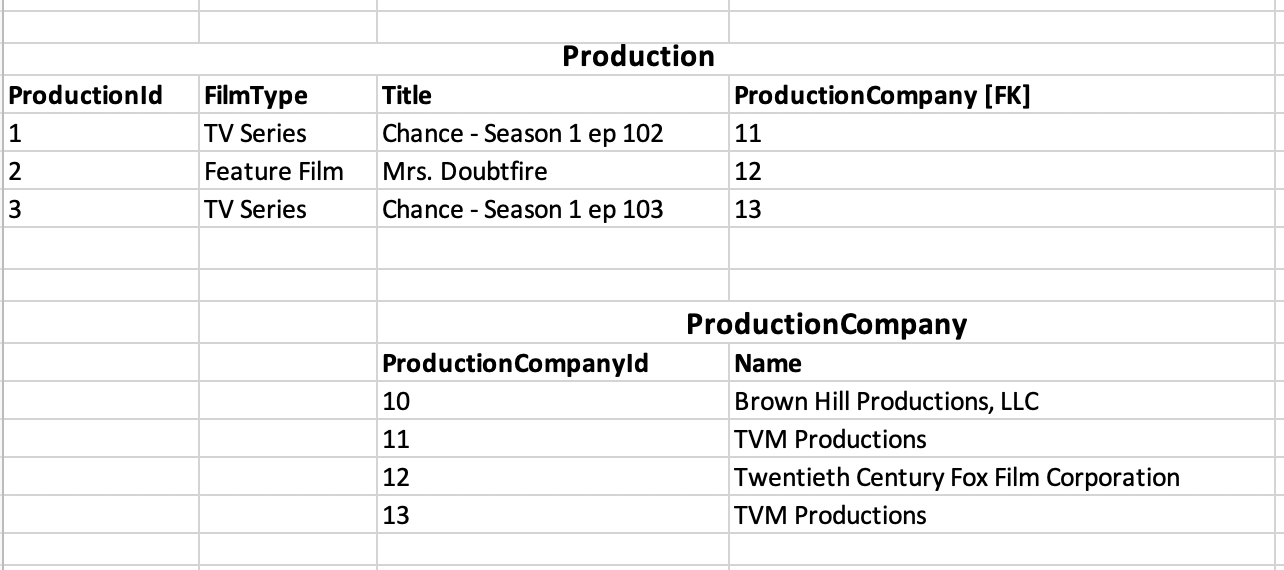
Remember that the primary key (name) in the ProductionCompany table is a uniqueness constraint, even when choosing an artificial key, so you must ensure that (name) doesn't contain any duplicates. If you do this, you will find the right solution:
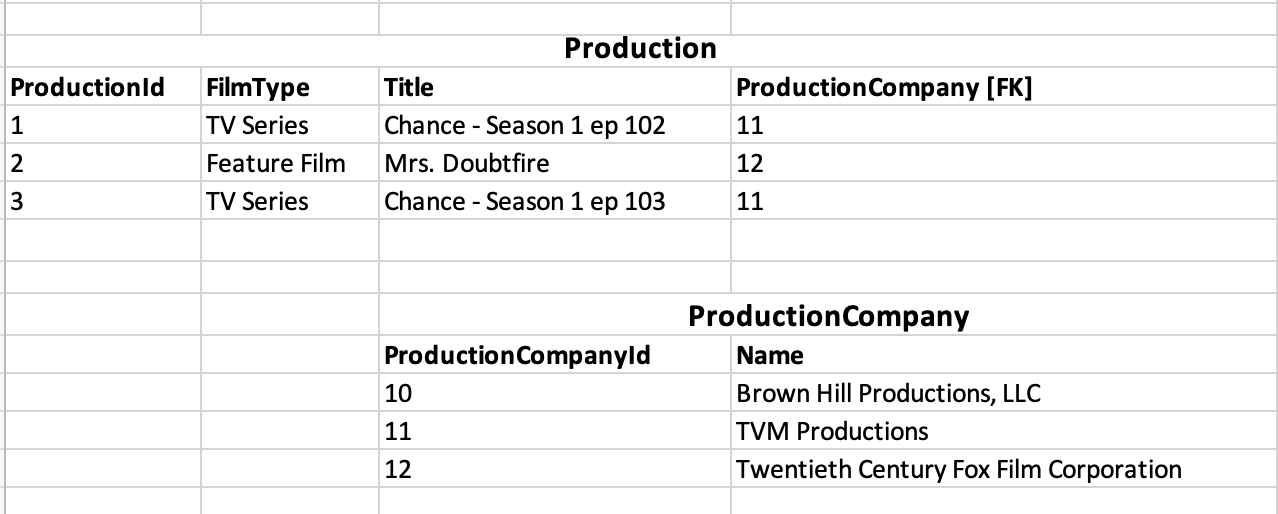
However, once you get to the PDM (the third step in the modeling process), you will often use artificial keys systematically because:
There’s always a risk that a natural primary key could lose its uniqueness (e.g., if a single production company produces two films with the same name).
If the value of a natural key is modified (e.g., if a production company changes its name), then all the foreign keys that reference it would also need to change.
Let’s Recap!
A table’s primary key is the minimum set of columns that allow a row to be uniquely identified.
A primary key must have a uniqueness constraint.
In some cases, it’s impossible to find a primary key within the existing columns. In other cases, the primary key is too complicated. In these cases, create an artificial primary key.
You only use an artificial primary key in the LDM for specific cases and take certain precautions.
You’ve identified your primary keys. Well done! But your tables are still separate. In the next chapter, you’ll see how to link them together.
