Trouvez et collectez des données
Identifiez les sources de données pour votre projet
Dans la première partie, vous avez pu voir la façon dont le pipeline de données explique la façon de traiter les données, de les transformer en informations et d’en retirer des connaissances. Parfois, le plus dur dans ce processus consiste d’abord à trouver des données utiles !
Mais dans le cas de Sarah, nous avons la possibilité d’extraire des données à partir de son application de suivi et de son fichier de santé, pas vrai ?
Oui et non. Le fichier de santé semble facile à obtenir puisqu’il se trouve sur l’ordinateur de Sarah. Par contre, le traqueur de forme physique peut représenter un défi. Elle peut visualiser les données dans l’application, mais nous avons besoin de les collecter dans un format informatique exploitable. Il doit exister un moyen d’extraire les données dans un format compatible avec des outils de gestion, comme un tableur.
Quand on collecte et qu’on exploite des données, il est important de tenir compte des aspects légaux et éthiques. Deux éléments vous aideront à décider : la propriété et le caractère sensible des données.
Découvrez comment collecter des données
Il existe plusieurs façons d’obtenir des données. Examinons celles qui sont présentées sur cette illustration :
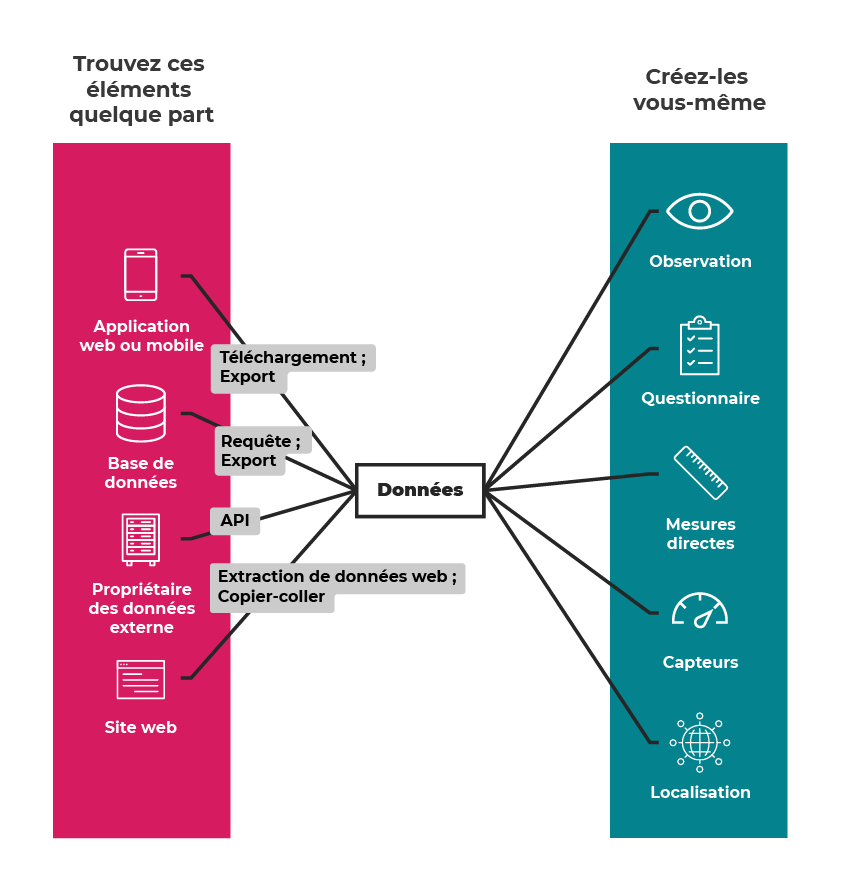
On peut obtenir des données en les créant soi-même. C’est ce que Sarah a fait avec son journal de données de santé. Il existe plusieurs façons de produire des données.
Vous pourriez :
observer (vous asseoir dans un parc et compter le nombre d’oiseaux d’espèces différentes que vous voyez, par exemple) :
interroger un groupe de personnes (par exemple, leur demander leurs intentions de vote);
prendre des mesures directes (la taille des arbres, par exemple) ;
utiliser des capteurs pour collecter automatiquement des données (par exemple, un capteur pour mesurer la température dans votre salon) ;
utiliser des traqueurs dans des situations diverses (suivre le nombre de visites de chaque page d’un site web, par exemple).
Si les données sont liées à une application web ou mobile, vous pourriez être en mesure de les télécharger ou de les exporter. Par exemple, l’application de forme physique de Sarah ou le site web associé peuvent proposer les données en téléchargement.
Si vous êtes en charge d’un projet pour votre entreprise, vous pouvez retrouver des données dans une base de données. Vous devriez pouvoir y accéder sans aide extérieure ou demander à une personne du service informatique de l’exporter pour vous.
Dans les autres cas, il se peut que les données appartiennent à un tiers. Vous aurez peut-être besoin de contacter cette personne ou entité pour obtenir les données. On pourrait aussi vous donner la possibilité d’y accéder légalement en les téléchargeant depuis un site web ou d’utiliser une API (application programming interface ou « interface de programmation d’application ») par vous-même.
On peut faire un copier-coller des données d’une page web, comme les tableaux d’une page Wikipédia, dans une feuille de calcul, ou extraire des données web, opération qui nécessite d’avoir des connaissances en programmation.
Évaluez l’intérêt des données
Les données sont-elles toutes utiles ?
Non ! Il vous faut des données que vous pouvez facilement transformer en informations et en connaissances. Il faut se poser deux questions clés :
Peuvent-elles être traitées à l’aide d’un ordinateur ?
Ont-elles une valeur informative ?
On doit d’abord stocker les données sur un ordinateur pour pouvoir les traiter. Ainsi, si vos données se trouvent sur un support papier, vous devez d’abord les retranscrire dans un fichier informatique. Vous pouvez y parvenir de plusieurs façons.
Le format .xlsx d’Excel est pratique, car il peut être ouvert sur tous les tableurs les plus courants. Les données peuvent à la fois être traitées sur ordinateur et être lues par des utilisateurs. Les tableurs sont un excellent support pour présenter les données. Le tableur présentant les données de santé de Sarah peut être mis en forme et enregistré au format Excel. Il pourrait ressembler à ceci :
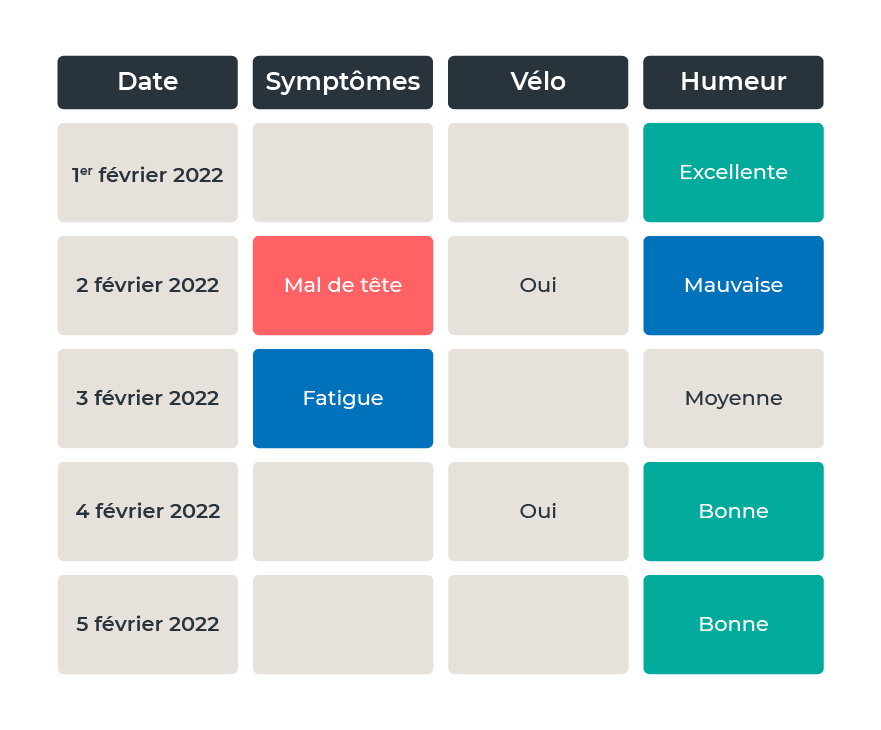
Un autre format très pratique est le CSV (comma-separated values ou « données séparées par une virgule »). Des tableurs comme Excel, Numbers ou Google Sheets peuvent générer ce format. Comme pour Excel, les fichiers CSV contiennent des lignes et des colonnes présentées sous forme de tableau. Le format CSV est un format de texte brut qui contient une série de valeurs séparées par des virgules. On peut le considérer comme un fichier Excel sans options de mise en forme (les couleurs, les polices de caractère, les styles, etc. ne peuvent pas être modifiés).
Dans le tableau ci-dessus, les colonnes contiennent des données qui peuvent changer de valeur, appelées variables.
Dans les données ci-dessus, l’humeur est une variable qui peut contenir les valeurs « excellente », « mauvaise », « moyenne » ou « bonne ».
Le tableau ci-dessus est un exemple de données structurées.
À l’inverse, les images, les vidéos et les documents texte sont des exemples de données non structurées.
Disons que Sarah souhaite savoir si ses problèmes de santé peuvent être liés à ses habitudes alimentaires. Elle prend donc en photo tous les plats qu’elle mange avec son smartphone. Elle obtient ainsi une galerie de photos :
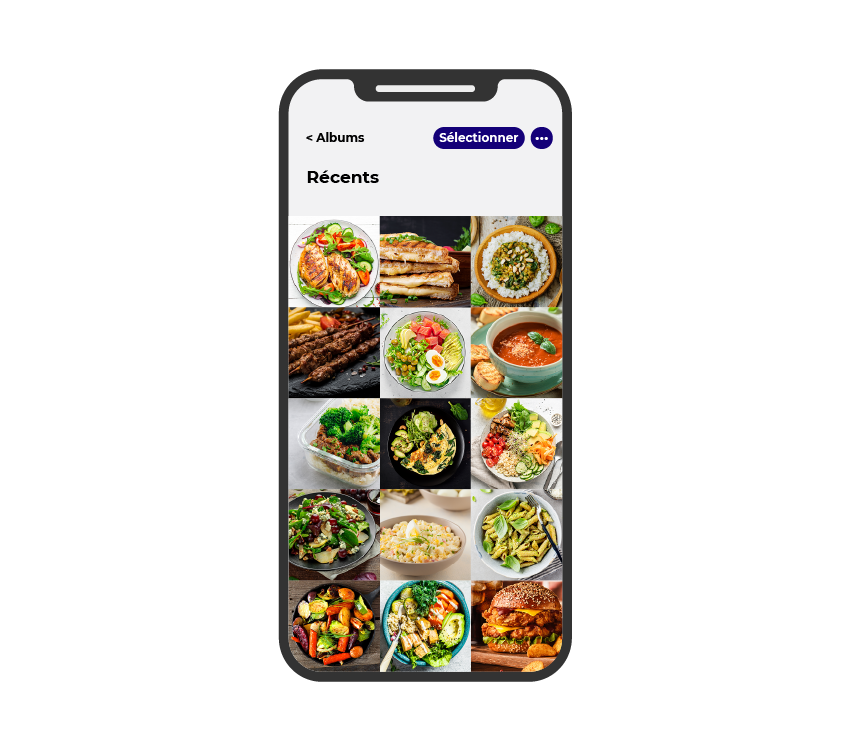
Remarquez-vous que ces données non structurées ne sont pas aussi faciles à utiliser que le tableur de données CSV ci-dessus ? Prenez une photo :

Même si les données sont informatisées (comme une image sur le smartphone de Sarah), les informations qu’elle contient seront difficiles à extraire. Un humain pourra y voir du saumon, des asperges et des tomates, mais l’ordinateur ne perçoit pas ces informations immédiatement. Il faudrait procéder à un traitement de l’image, soit manuellement (en ajoutant ces informations), soit en ayant recours à l’IA pour extraire l’information (ce qui n’est pas si simple !). En fin de compte, il faut que vous traitiez les images pour obtenir des données présentées de cette façon :
Date | Déjeuner | Dîner |
1er février 2022 | Soupe de tomates | Saumon, asperges, tomates |
2 février 2022 | Sandwich au fromage | Risotto aux champignons |
3 février 2022 | Salade aux œufs | Nouilles sautées au poulet |
4 février 2022 | Houmous et pita | Pâtes, pesto, parmesan |
5 février 2022 | Salade de légumes grillés | Épinards et curry de lentilles au riz |
Comme vous pouvez le voir, ces données sont maintenant structurées. C’est bien plus pratique !
Maintenant que nous savons que les données peuvent faire l’objet d’un traitement informatique, il est temps de passer au deuxième test pour vérifier leur valeur informative.
On peut faire appel aux mathématiques pour évaluer la valeur informative d’une donnée, mais nous n’aborderons pas cela ici  . Néanmoins, on peut souvent détecter la valeur informative d’une donnée. Prenons, par exemple, les données de forme physique de Sarah :
. Néanmoins, on peut souvent détecter la valeur informative d’une donnée. Prenons, par exemple, les données de forme physique de Sarah :
Date | Nombre total de pas | Fréquence cardiaque au repos |
01-févr-22 | 8 372 | 68 |
02-févr-22 | 4 928 | 67 |
03-févr-22 | 4 941 | 67 |
04-févr-22 | 9 783 | 68 |
05-févr-22 | 7 994 | 67 |
06-févr-22 | 7 682 | 67 |
07-févr-22 | 7 881 | 68 |
… | ... | … |
Vous pouvez remarquer que le nombre total de pas varie significativement chaque jour, tandis que la fréquence cardiaque au repos est plutôt stable et varie seulement de 67 à 68. Sarah aimerait que des éléments supplémentaires expliquent la variation du nombre total de pas, comme ses changements d’humeur. Cependant, si l’on observe les données relatives à la fréquence cardiaque au repos, la variance n’est pas assez significative pour en savoir plus sur la santé et la forme physique de Sarah.
Il convient de considérer la valeur informative comme le pouvoir explicatif des données. Ainsi, quand vous collectez des données, demandez-vous si elles ont une valeur informative en réfléchissant à leur capacité à expliquer une tendance ou une observation.
À vous de jouer : Entraînez-vous à collecter des données et à y accéder

Il est temps de passer à la pratique ! D’abord, vous aiderez Sarah en réunissant des données dans des fichiers de données. Ce groupe de fichiers de données constitue un ensemble de données.
Données issues de l’application de forme physique
Sarah a exporté dans un fichier nommé traqueur_forme_physique.xlsx les données du mois de février à partir de son application de forme physique. Cliquez sur ce lien pour télécharger les données.
Journal des données de santé
Sarah a créé une feuille de calcul journal_données_santé.xlsx où sont consignées ses données de santé. Vous pouvez télécharger ce fichier en cliquant ici.
Photos de plats
Collectons maintenant quelques données. Sarah a exporté les photos de plats de son smartphone et les a stockées ici. Elle prend seulement le plat principal en photo tous les jours. Pouvez-vous l’aider à convertir ces données non structurées en données structurées ? Créez une feuille de calcul comprenant trois colonnes : Date, Bon pour la santé et Consistant. Les premières lignes doivent être présentées ainsi :
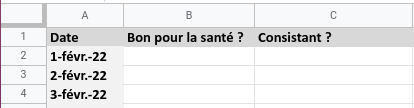
Nommez la feuille de calcul Journal d’alimentation.
Complétez la feuille de calcul en vous basant sur les photos. Dans la colonne « Bon pour la santé ? », vous devez indiquer si le plat est bon pour la santé ou pas. Indiquez « non » en face de la date si vous pensez que le plat n’est pas bon pour la santé et laissez la cellule vide si vous pensez le contraire. Dans la colonne « Consistant ? », indiquez si le plat vous paraît consistant ou pas.
Ce screencast illustre la façon dont j’ai complété les étapes ci-dessus :
Vous pouvez télécharger l’intégralité de mes fichiers d’exercices ici.
Avez-vous découvert une autre source de données ici ?
Oui, bien sûr ! Vous pouvez l’ajouter au pipeline de données comme ceci :
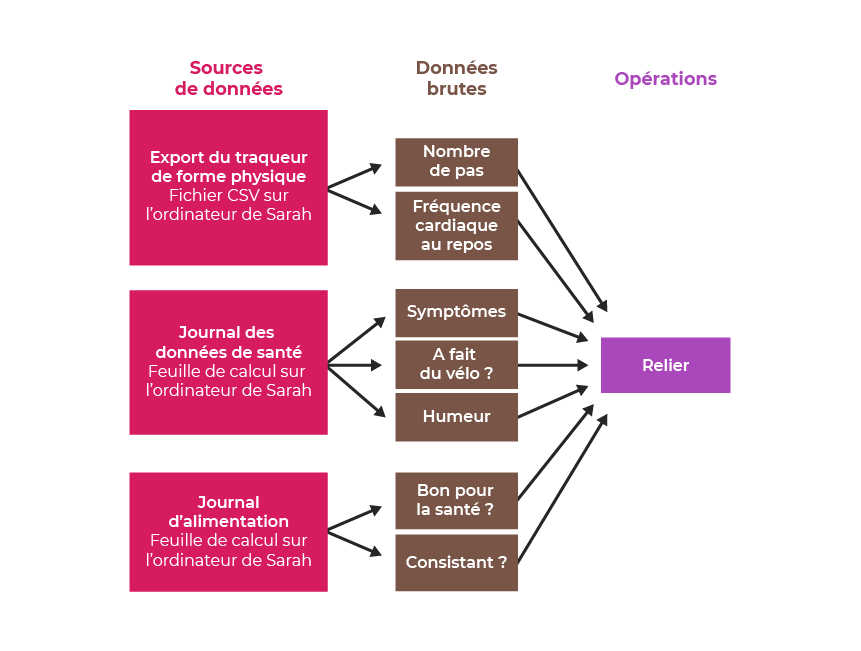
En résumé
Très théorique, tout cela, mais il s’agit de concepts importants. Résumons ce que vous avez appris :
Les données sont utiles quand elles peuvent à la fois faire l’objet d’un traitement informatique (au format .xls et .csv, par exemple) et avoir de la valeur informative (généralement, elles doivent varier pour que vous puissiez en retirer quelque chose d’intéressant).
Les données peuvent être vraiment précieuses ! Par conséquent, avant de vous en servir, vérifiez à qui elles appartiennent et quel est leur niveau de sensibilité.
Les données qui se trouvent à différents endroits peuvent nécessiter des démarches de regroupements : intégration manuelle, téléchargement à partir de la source, accès à une base de données, utilisation d’API ou extraction de données web. Mais vous avez aussi la possibilité de le faire !
Les données structurées sont organisées de façon classique et on peut procéder facilement à leur traitement à l’aide d’un ordinateur, à l’inverse des données non structurées.
Bravo pour avoir collecté des données et pour avoir vérifié leur utilité ! Maintenant que vous les avez analysées, il est temps de passer à leur traitement.
