Mesurez la couverture de vos tests
Avant de parler de tests d’intégration, je voudrais vous parler un peu de couverture de code. Plus vous allez écrire de tests et plus vous aurez besoin d’avoir des indicateurs sur ce qui est testé. La mesure de la couverture de code est un indicateur intéressant que tout développeur qui se respecte doit connaître.
Principe de la couverture de code
La couverture de code est une mesure utilisée pour déterminer le taux de code source exécuté lorsqu’une suite de tests est lancée. Pour essayer de limiter les bugs, les tests doivent couvrir une large proportion de code.
Il y a plusieurs indicateurs de couverture de code :
Couverture des fonctions (ou méthodes) : est-ce que toutes les méthodes du code ont été appelées par les tests ?
Couverture des instructions : est-ce que les tests sont passés sur chaque ligne de code ?
Couverture des chemins d’exécution : est-ce que l’on est passé dans toutes les branches de notre code ? Par exemple, l’instruction
ifgénère deux branches de code : une dans laquelle la condition évaluée est vraie, une autre où la condition est fausse.Couverture des points de tests : est-ce que chaque condition sur le test d’une variable a été couverte ?
En général, la plupart des outils proposent la couverture des instructions et des chemins d’exécution. Et la métrique la plus fiable est celle des chemins d’exécution, c’est celle que vous devez privilégier.
Les différents outils de mesure
Il existe plusieurs outils permettant de mesurer la couverture de code. Nous allons passer en revue les plus connus.
Visual Studio possède un outil de mesure de code.
Par contre, il n’est utilisable qu’à partir de l’édition professionnelle de Visual Studio, qui est payante (contrairement à la version community, que j’utilise ici, qui est gratuite). Si vous avez une version payante de Visual Studio, et c’est très souvent le cas en entreprise, n’hésitez pas à utiliser cette fonctionnalité de couverture de code. Vous trouverez plus d’informations ici.
Il existe aussi DotCover, qui est l’outil de Jetbrains.
C’est un logiciel payant également, mais certaines entreprises achètent des licences de Resharper.
DotCover est inclus avec certaines licences des produits JetBrains. N’hésitez pas à vérifier si vous utilisez déjà un autre logiciel de JetBrains, vous aurez peut-être accès à DotCover. Vous trouverez plus d’informations ici.
Un autre outil assez connu est NCover.
Toujours payant, c’est un outil qui existe depuis très longtemps et que l’on retrouve parfois associé à d’autres logiciels. Suivez ce lien si vous souhaitez avoir plus d’informations.
Et je terminerai par une dernière option : OpenCover.
Il s’agit d’un outil open source sous licence MIT. C’est celui que nous allons utiliser dans ce cours, sachant qu’il ne fonctionne que sous Windows et que nous allons donc installer également des extensions pour pouvoir l’utiliser correctement. Le projet se trouve sur github, mais vous n'avez pas besoin de le cloner, il suffira de référencer le bon package Nuget.
Utilisez OpenCover
Pour utiliser OpenCover, il faut commencer par référencer notre package Nuget, directement dans notre projet de test :
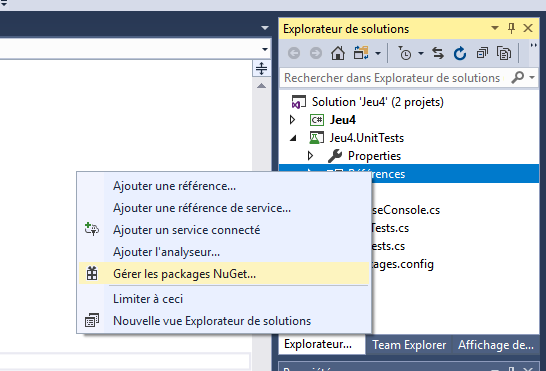
Il faut ensuite trouver OpenCover et l’installer :
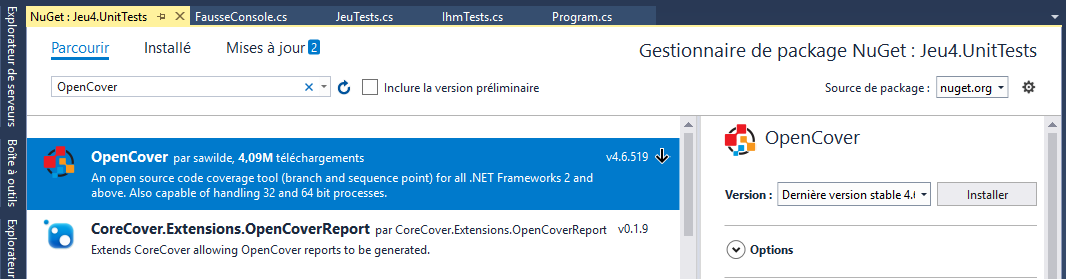
OpenCover est le moteur d’analyse de la couverture de code. Il nous faut maintenant une interface permettant de lire les résultats de l’analyse. Avec Visual Studio 2017, nous pouvons installer l’extension AxoCover :
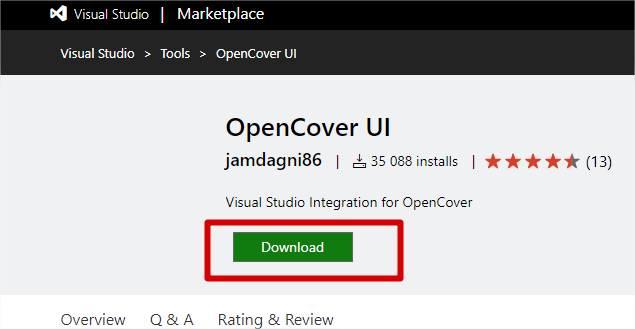
Une fois l’extension téléchargée, vous pouvez l’installer :
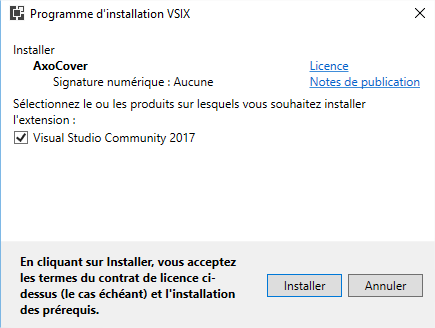
Une fois l’installation terminée, redémarrez Visual Studio et rouvrez votre solution.
Vous avez désormais un nouvel élément dans le menu outils :
Si vous cliquez dessus, une nouvelle fenêtre s'ouvre :

Normalement, nous y voyons nos tests.
Il ne vous reste plus qu’à cliquer sur Cover pour démarrer les tests et l’analyse.
Après l’exécution, vous pouvez constater l’apparition d’un nouvel onglet Report :
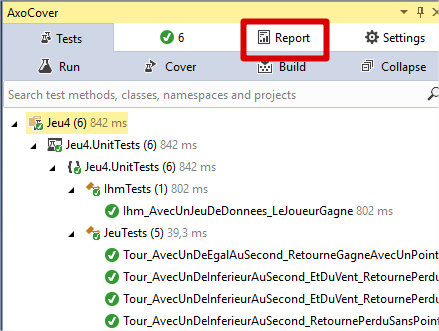
Cliquez dessus pour voir les résultats de la couverture de code :
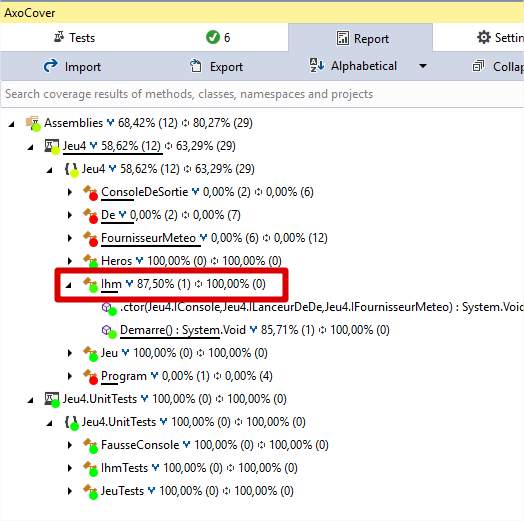
Nous pouvons voir plein de petites choses. 🙂
Vous voyez notamment les noms des namespaces et des classes, ainsi que deux pourcentages à leurs côtés.
Le premier correspond au pourcentage des branches qui sont couvertes et le second au pourcentage de lignes couvertes. Par exemple, nous pouvons voir que la classe Heros est couverte à 100 %, alors que la classe Ihm n’est couverte qu’à 87,5 % au niveau des chemins d’exécution.
Vous voyez aussi que les classes
De,FournisseurMeteoetConsoleDeSortiesont à 0 %.
Eh oui, lors des tests, nous avons remplacé ces dépendances aléatoires par de fausses implémentations...
Si nous cliquons sur la classe Ihm , nous avons des précisions supplémentaires sur l’analyse de cette classe :
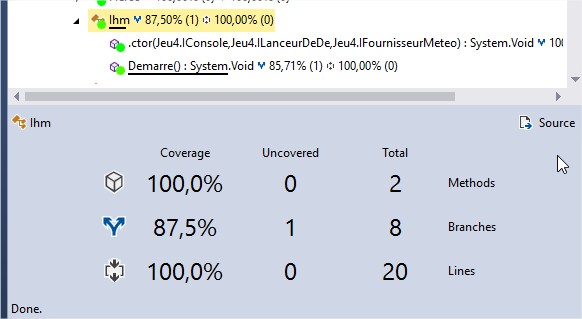
Nous voyons donc que nous avons une branche qui n’est pas couverte par nos tests et qu'elle est dans la méthode Demarre() .
Mince ! Mais quelle est cette branche non couverte et qui va prendre froid ? 😜
Pour le savoir, il suffit de cliquer sur Source - à droite - et nous voilà redirigés dans le code de la classe. Mais il n’est plus tout à fait comme avant. Sur la gauche, nous avons des couleurs :
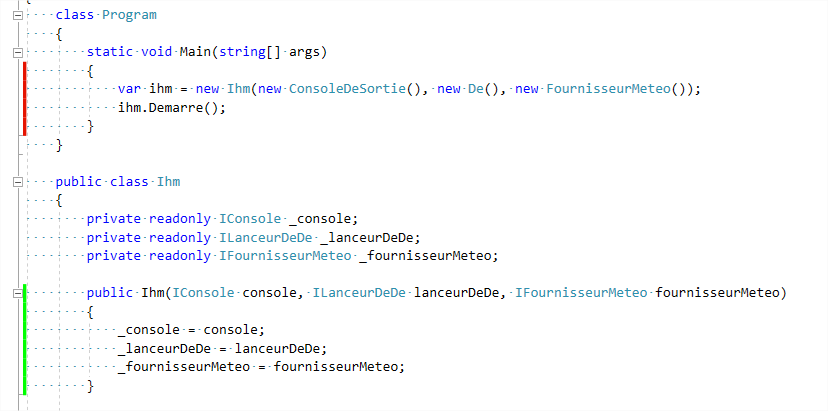
Un trait rouge indique qu’une ligne (ou plusieurs) n’est pas couverte. Vous le voyez, c’est le cas pour le contenu de la méthode Main . C’est bien normal, étant donné que nous n’avons aucun test qui appelle ce bout de code. Évidemment, la ligne verte indique que la ligne est couverte.
Pour les branches, c’est un petit peu plus subtil, car il s’agit d’un petit cercle sur la gauche :
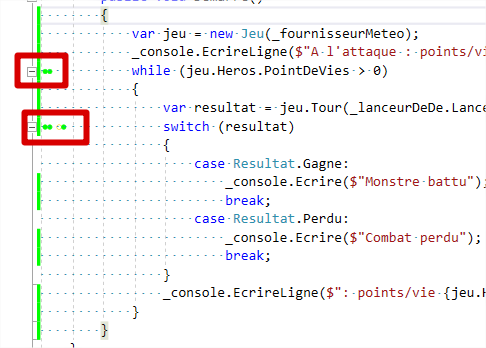
Lorsque tout est vert, c’est que toutes les options sont couvertes. Typiquement, pour la condition de la boucle while, il faut avoir un cas où elle est vraie et un cas où elle est fausse, ce qui est le cas dans nos tests.
Pour le switch - et c’est ce qui explique notre score de 85,7 % -, nous n’avons pas géré de cas par défaut. En fait, c’est comme si nous avions écrit ce code :
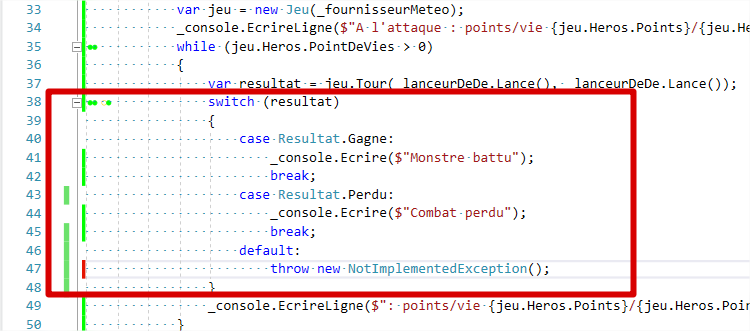
Nous voyons bien, sur cette capture d’écran, avec le résultat de la couverture de code, que nous ne passons jamais dans le cas default . En effet, nous n’avons que 2 valeurs dans notre énumération, difficile de se retrouver dans le cas d’une valeur qui n’existe pas !
On pourrait considérer ici que l’outil de couverture de code nous remonte un faux positif, car dans notre code, nous avons couvert toutes les possibilités. Mais techniquement, il pourrait être envisageable d’avoir d’autres options. Une enum n’est rien de plus qu’un entier, finalement. Le tour de jeu pourrait très bien renvoyer ceci à un moment ou à un autre :
public Resultat Tour(int deHeros, int deMonstre)
{
return (Resultat)3;
}Ce code compile et fonctionne. Mais alors, ce cas n’est pas traité par notre première version du code. En revanche, avec la seconde version, nous aurons une exception levée pour cette valeur qui n’est pas gérée explicitement.
Donc, vous avez deux options :
Il faut écrire un nouveau test pour gérer ce cas-là.
Cela nécessiterait d’extraire une interface de la classe Jeu , de récupérer la dépendance dans le constructeur et d’utiliser un bouchon ou un simulacre pour renvoyer une valeur qui ne fait pas partie de l’énumération. Et là, cela nous fait pas mal de travail pour pas grand-chose…
L’autre option est de réécrire le premier code pour avoir un
defaultà la place duResultat.Perdu(ligne 6) :
switch (resultat)
{
case Resultat.Gagne:
_console.Ecrire($"Monstre battu");
break;
default:
_console.Ecrire($"Combat perdu");
break;
}Avec ce code-là, la couverture de code repasse à 100 % pour la classe Ihm . Chouette ! 🙂
Couverture de code et qualité
Nous venons de voir que la mesure peut être différente en fonction de la façon dont nous avons écrit notre code. Cependant, on pourrait se demander si la réécriture présentée ci-dessus est bien utile.
En effet, nos tests couvraient avec succès tous les cas fonctionnels de notre tour de jeu. Alors, faut-il nous obstiner à modifier le code et passer de 85 % à 100 % ?
C’est là qu'il faut être capable de se rendre compte de ce qu’est vraiment cet indicateur de couverture de code.
Pour qu’il puisse vous être utile, il faut bien comprendre comment il fonctionne et ce qu’il nous dit vraiment derrière les chiffres.
On pourrait penser que plus le pourcentage est élevé, plus le code est de qualité.
Qu’en pensez-vous ?
C’est la première chose qui vient à l’esprit. En conséquence, il paraîtrait logique de vouloir atteindre 100 % de couverture de code.
Pour nous en convaincre, prenons un exemple simpliste :
[TestClass]
public class ExempleTest
{
[TestMethod]
public void Test1()
{
StringHelper.EstCeQueLaChaineEstLongue("abc");
}
}
public static class StringHelper
{
public static bool EstCeQueLaChaineEstLongue(string chaine)
{
if (chaine.Length > 10)
return true;
else
return false;
}
}Le code parle de lui-même, on veut savoir si une chaîne est longue ou pas.
Oui, je décide arbitrairement qu’une chaîne est longue si elle dépasse dix caractères. 🙂
Notre test appelle la méthode avec une chaîne courte ; nous avons donc une couverture de code de 66,67 % au niveau des branches, et de 80 % au niveau des lignes de code :
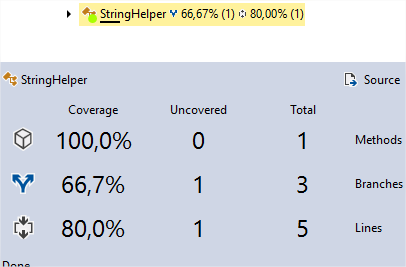
En effet, nous ne sommes pas passés par le cas où la chaîne est longue.
La logique voudrait que nous ajoutions un cas de test, cette fois-ci avec une chaîne longue. Mais soyons fous et changeons plutôt le code de la méthode à tester :
public static bool EstCeQueLaChaineEstLongue(string chaine)
{
return chaine.Length > 10;
}Maintenant, relançons l’analyse. Nous obtenons :

Nous avons cette fois-ci une couverture de code à 100 % . 😲 Pourtant, le code fait exactement la même chose que précédemment ! Il nous manque toujours un cas de test, mais l’indicateur dit bien 100 %.
C’est grave, non ?
Mais il y a pire que ça ! Vous voyez ? Oui, j’espère que vous avez vu. 🙂
En vérité, avec ce test, nous ne testons rien. Nous avons simplement démarré une méthode. Le code correct de test aurait dû être dans ce cas, a minima :
StringHelper.EstCeQueLaChaineEstLongue("abc").Should().BeFalse();Ici, nous vérifions un résultat, il y a une assertion.
Alors, que pouvez-vous en penser ?
Nous avons vu que l’indicateur de couverture de code était à 100 %, alors que tous les scénarios de tests n’existaient pas et que le test ne testait finalement rien.
Je vous l’accorde, mon exemple est extrême. Mais son objectif est de vous faire comprendre qu’un haut pourcentage de couverture de code n’est pas forcément synonyme de qualité de test. Cet indicateur fournit une tendance, il faut l’utiliser sur la durée.
En général, si l'on a peu de couverture de code, c’est un indicateur pour rajouter des tests. Au contraire, avoir une grosse couverture de code ne veut pas forcément dire que tout est bien testé et que les tests sont de qualité.
Il faut aussi rester raisonnable et pragmatique. Le Graal de 100 % de couverture de code est en général impossible à atteindre. Sur un vrai projet, il demande bien souvent trop d’efforts (et donc un coût trop important) par rapport à l’intérêt d’avoir une telle couverture. D’autant plus que nous venons de voir que ce taux ne garantit pas la qualité.
