Réalisez une modélisation

Nous allons voir dans ce nouveau chapitre, comment nous pouvons utiliser la régression linéaire pour faire des prévisions ou encore pour trouver des valeurs manquantes. Pour commencer, explorons les valeurs atypiques de notre jeu de données avec la technique de l’écart interquartile.
Effectuez des modélisations performantes
Nous allons faire une régression linéaire afin de prédire la valeur d’un bien en fonction des mètres carrés des appartements pour Paris.
Commençons donc par extraire tous les appartements avec leurs valeurs foncières et les surfaces Carrez en faisant un filtre sur Paris.
Nous avons donc un tableau de 4 401 lignes. Créez un graphique sous forme de nuage de points afin de visualiser toutes les données.
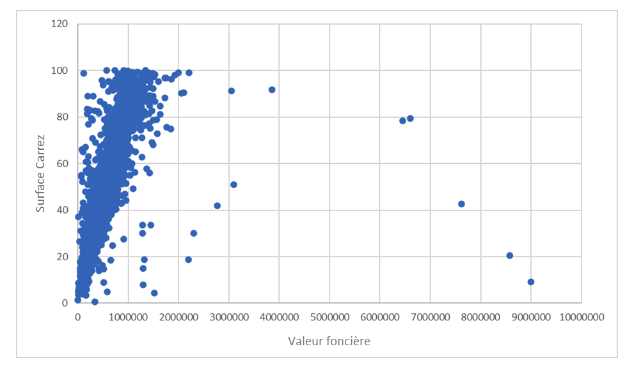
Comme nous pouvons le voir sur le graphique, il y a une grosse concentration des données à gauche, puis quelques points qui se baladent un peu partout sur notre nuage de points.
En calculant notre coefficient de Pearson (avec la formule Pearson), nous constatons un coefficient de 0,64. Il y a donc une corrélation positive entre le prix et la surface.
Le problème, c’est que les modèles n’aiment pas vraiment les valeurs dites aberrantes ou atypiques.
Prenons par exemple le cas de notre point tout en bas à droite du graphique. Nous pouvons voir que c’est un appartement qui fait 9 m² Carrez pour un prix de 9 millions d’euros. Pour nous représenter ce chiffre, nous pouvons essayer de calculer le prix au mètre carré pour ce bien. Il est de 1 million d'euros. Sans être un spécialiste, nous pouvons facilement nous dire que ce n’est pas vraiment le prix moyen dans la capitale française.
OK, je vois où on veut en venir, mais moi je ne suis pas un spécialiste de l’immobilier parisien et je n’ai pas envie de me questionner sur tous les appartements.
Je suis complètement d’accord avec vous, et c’est pour cela qu’il existe plusieurs techniques pour trouver des valeurs aberrantes ou atypiques. Dans notre cas, nous allons utiliser l’écart interquartile, que nous avons déjà vu précédemment dans ce cours.
Voici le code pour la colonne “Valeur foncière” :
Sub ecart_interquartile()
Dim Q1 As Double
Dim Q3 As Double
Dim IQR As Double
Dim borne_basse As Double
Dim borne_haute As Double
Q1 = WorksheetFunction.Quartile(Range("B2:B4402"), 1)
Q3 = WorksheetFunction.Quartile(Range("B2:B4402"), 3)
IQR = Q3 - Q1
borne_basse = Round(Q1 - (1.5 * IQR), 0)
borne_haute = Round(Q3 + (1.5 * IQR), 0)
If borne_basse < 0 Then
borne_basse = 0
MsgBox ("attention borne basse inférieure à 0")
Range("$A$1:$C$4845").AutoFilter Field:=1, Criteria1:=">" & borne_haute, _Operator:=xlAnd
test = ">" & borne_haute
End If
End SubNous voyons qu’il y a 137 valeurs qui sont considérées comme des valeurs aberrantes, nous allons les supprimer pour améliorer notre modélisation.
Je vous laisse faire la même chose pour la colonne "Surface Carrez", en supprimant également les données : normalement 11 valeurs.
Nous pouvons maintenant calculer un nouveau coefficient de Pearson sur nos données pour voir la différence, avec seulement 148 valeurs considérées comme atypiques. Nous trouvons un coefficient de Pearson de 0,89. Nous sommes maintenant en présence d’une corrélation très forte entre les deux variables.
Pour synthétiser, nous avons supprimé 3 % des valeurs et le coefficient est passé de 0,64, qui est une corrélation moyenne, à 0,89, qui est une corrélation très forte.
Pour mieux comprendre, je vous propose de refaire un nuage de points avec ce nouveau jeu de données nettoyé.

Ce graphique confirme bien que le nettoyage des données que nous avons réalisé a eu un impact sur les données que nous avons gardées. Elles sont beaucoup plus homogènes.
Appréhendez la régression linéaire simple
Maintenant que nous avons un jeu de données qui est propre, nous allons pouvoir passer à la régression linéaire.
Après les tests statistiques, on veut vraiment essayer de me perdre avec la régression linéaire ?
Mais non, je vous rassure, le nom fait plus peur que la technique et nous allons voir tout cela ensemble.
Pour commencer, à quoi cela sert une régression linéaire ?
L’idée générale, c’est qu’une variable (la variable dépendante) est dépendante d’une ou plusieurs variables explicatives. Il est alors possible d’écrire l'équation linéaire qui permet de trouver les valeurs de la variable dépendante en fonction de la ou des variables explicatives.
Cette technique consiste à trouver la droite qui permet de réduire au maximum la somme des valeurs résiduelles au carré (c’est la méthode des moindres carrés ordinaires).
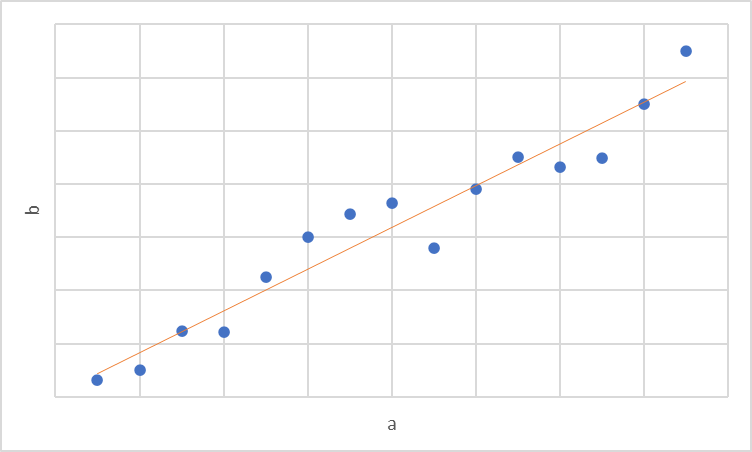
Comme nous pouvons le voir sur le graphique ci-dessus, la courbe en rouge essaye de se rapprocher le plus possible de l’ensemble des points. Nous pouvons voir qu’il y a une relation linéaire forte entre les deux variables dans notre graphique, car l’ensemble des points sont très proches de notre courbe. Le coefficient de Pearson sur ce graphique est de 0,95 : la corrélation est donc très forte !
Maintenant que nous savons que nos deux variables sont très corrélées, nous pouvons supposer que s’il nous manque une valeur de Y, nous allons pouvoir la compléter en fonction de la valeur de X. C’est ce qu’on appelle la régression linéaire simple.
Je vous laisse me suivre dans le screencast pour la réalisation de la régression linéaire simple :
Notre régression linéaire a donc de bons paramètres (le R² ainsi que la p-valeur). Nous pouvons donc en conclure que cette régression permet de bien expliquer les différentes valeurs et donc également d’en prédire. L’équation que nous avons vue permet de choisir, pour n’importe quelle valeur de X, une valeur de Y. Nous pouvons donc prédire pour chaque mètre carré à Paris une valeur de vente théorique. Nous allons détailler ce calcul dans la prochaine section.
Réalisez une prédiction avec la régression linéaire
Vous êtes maintenant capable de réaliser une régression linéaire et de comprendre les principaux paramètres de cette régression. Nous allons maintenant essayer de prédire des valeurs grâce à l’équation de la régression linéaire simple.
Ah ! Enfin la prévision 😀 !
Nous allons refaire notre régression linéaire, mais cette fois nous allons cocher “Résidus”, puis “OK”. En plus de notre rapport détaillé et de l’analyse de la variance, nous obtenons un gros tableau avec la prévision des valeurs foncières et les résidus.
Les résidus ? Mais on ne devait pas parler de prévision ?!
Nous allons y arriver : justement, la première colonne de ce gros tableau, c’est la prévision de notre modèle. Cette prévision est faite sur les valeurs que nous lui avons donné à étudier. Le modèle a utilisé les données pour faire une prédiction sur le réel.
Si nous prenons la première valeur, nous pouvons voir que la prévision est de 29 533 €, alors que dans notre tableau initial la valeur foncière est de 336 740 €. Il y a un écart assez considérable entre les deux valeurs, cet écart justement s’appelle le résidu, et il est de 307 207 € pour cette première valeur.
Si nous regardons la moyenne des valeurs absolues (formule ABS ) des résidus, nous pouvons voir qu’en moyenne notre modèle se trompe de 70 000 € sur les prévisions.
Cela peut paraître beaucoup, mais notre modèle se base sur la totalité des ventes à Paris, et nous savons que le prix de vente dans le 16e arrondissement n’est pas le même que dans le 20e arrondissement. Si nous souhaitons affiner notre modèle, nous pouvons réaliser une régression linéaire multiple en rentrant de nouveaux paramètres explicatifs du prix (nombre de pièces, jardin, balcon, arrondissement, etc.).
Pour faire la prévision, il n’y a rien de plus simple : nous allons écrire l’équation qui a permis de faire la prévision.
Je vous détaille cela en screencast :
Pour la première ligne nous avons donc : Prévision valeur foncière = 0,5 x 10 287 + 24 390.
Ce calcul nous donne 29 533, exactement la valeur de la prévision réalisée par la régression linéaire.
Si maintenant je veux connaître le prix de vente d’un appartement de 54,47 m², il me suffit de remplacer la taille de l’appartement :
Prévision valeur foncière = 54,47 x 10 287 + 24 390. Ce qui nous donne une prévision de prix pour l’appartement de 584 722 €.
À vous de jouer !

Votre manager a une dernière demande à vous faire, il souhaite savoir si vous pouvez prédire les quantités de produits vendus en fonction du prix de vente des produits.
En effet, le marketing vient de lui soumettre de nouveaux modèles de pâtes, mais il ne sait pas quoi penser, car les prix varient beaucoup sur les différents modèles. Il vous précise que c’est un modèle de pâtes classique (non bio et non gluten free).
Il vous demande de prédire les ventes de la marque Brescia pour les prix suivants :
modèle A : 0,99 € ;
modèle B : 1,99 € ;
modèle C : 2,99 €.
N’hésitez pas à affiner votre modèle pour avoir une prédiction le plus proche possible de la réalité.
En résumé
Le nettoyage des données permet d’avoir des corrélations et des modèles performants.
La courbe de régression est une courbe qui essaye de minimiser l’écart entre la courbe et les différentes valeurs.
Pour évaluer la performance d’une régression linéaire, on utilise le R².
Une fois que le modèle est performant, on peut l’utiliser pour réaliser des prévisions en utilisant l’équation de la régression linéaire.
Félicitation vous avez terminé cette partie ! Je vous invite à réaliser le quiz qui suit. Et on se retrouve dans la dernière partie.
