Récupérez les informations d'échec et analysez-les

Visualisez les informations d’échec
Lors de l'exécution de tests automatisés avec Cypress, la visualisation des informations d'échec revêt une importance cruciale pour identifier, analyser et résoudre rapidement les problèmes dans votre application. Cypress offre un ensemble d'outils visuels et de rapports détaillés pour faciliter la compréhension des raisons des échecs de test et pour vous permettre d'effectuer des actions correctives de manière efficace.
Nous avons vu le launchpad dans le chapitre Exécutez les tests grâce au launchpad. Chaque fois que vous exécutez un test, Cypress ouvre une fenêtre du navigateur dans laquelle vous pouvez suivre en temps réel l'exécution du test. Si un test échoue, la fenêtre de Cypress reste ouverte à l'état où le test a échoué. Cette fonctionnalité unique vous permet d'inspecter visuellement l'interface utilisateur à l'état où l'échec s'est produit, facilitant ainsi l'identification des problèmes d'interface utilisateur et leur résolution. Vous pouvez inspecter les éléments DOM (Document Object Model), consulter les messages d'erreur et explorer l'état actuel de l'application pour déterminer la cause de l'échec.
Par exemple, dans le test ci-dessous, j’ai demandé l’ID 10000 en sachant qu’il n’y en avait pas autant. J’obtiens donc une erreur attendue 404 :
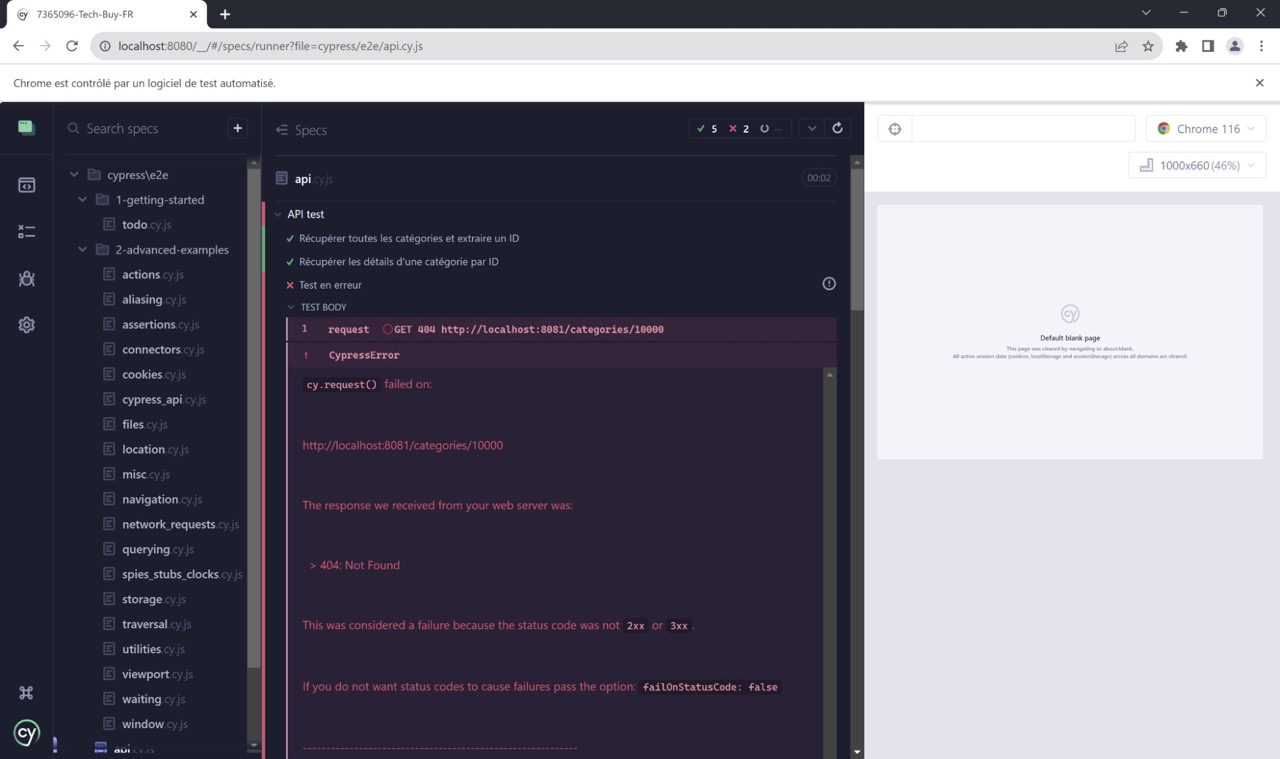
En cliquant sur la ligne request GET 404 http://localhost:8081/categories/10000, on peut voir plus de détails dans la console :
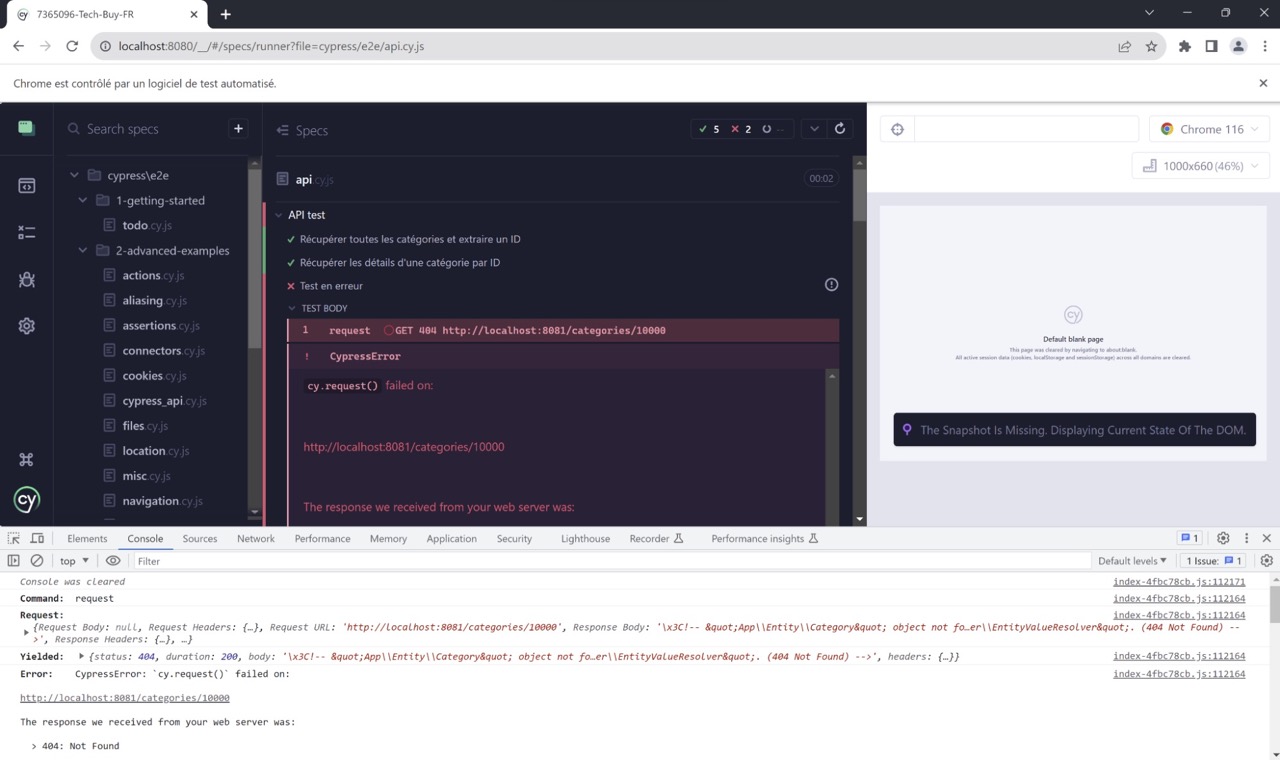
Cypress offre également des messages d'erreur clairs et des informations de débogage détaillées pour aider les développeurs à comprendre rapidement ce qui s'est mal passé. Les messages d'erreur indiquent souvent l'emplacement exact du problème, qu'il s'agisse d'une assertion qui a échoué, d'une erreur réseau, d'une exception JavaScript ou d'autres types d'erreurs.
De plus, Cypress génère automatiquement des captures d'écran et des vidéos de chaque test exécuté. Ces ressources visuelles sont associées à chaque étape du test, ce qui facilite grandement l'analyse ultérieure des échecs. Elles permettent de documenter visuellement les erreurs, de les partager avec les membres de l'équipe et de conserver une trace des problèmes rencontrés.
Cypress propose également divers rapporteurs de test qui présentent les résultats d'exécution de manière claire et lisible. Par exemple, le rapporteur "mochawesome" génère des rapports HTML interactifs contenant des informations détaillées sur chaque test, y compris les étapes, les erreurs et les assertions. Ces rapports sont faciles à parcourir et à partager. Voici un exemple de rapport généré avec mochawesome :
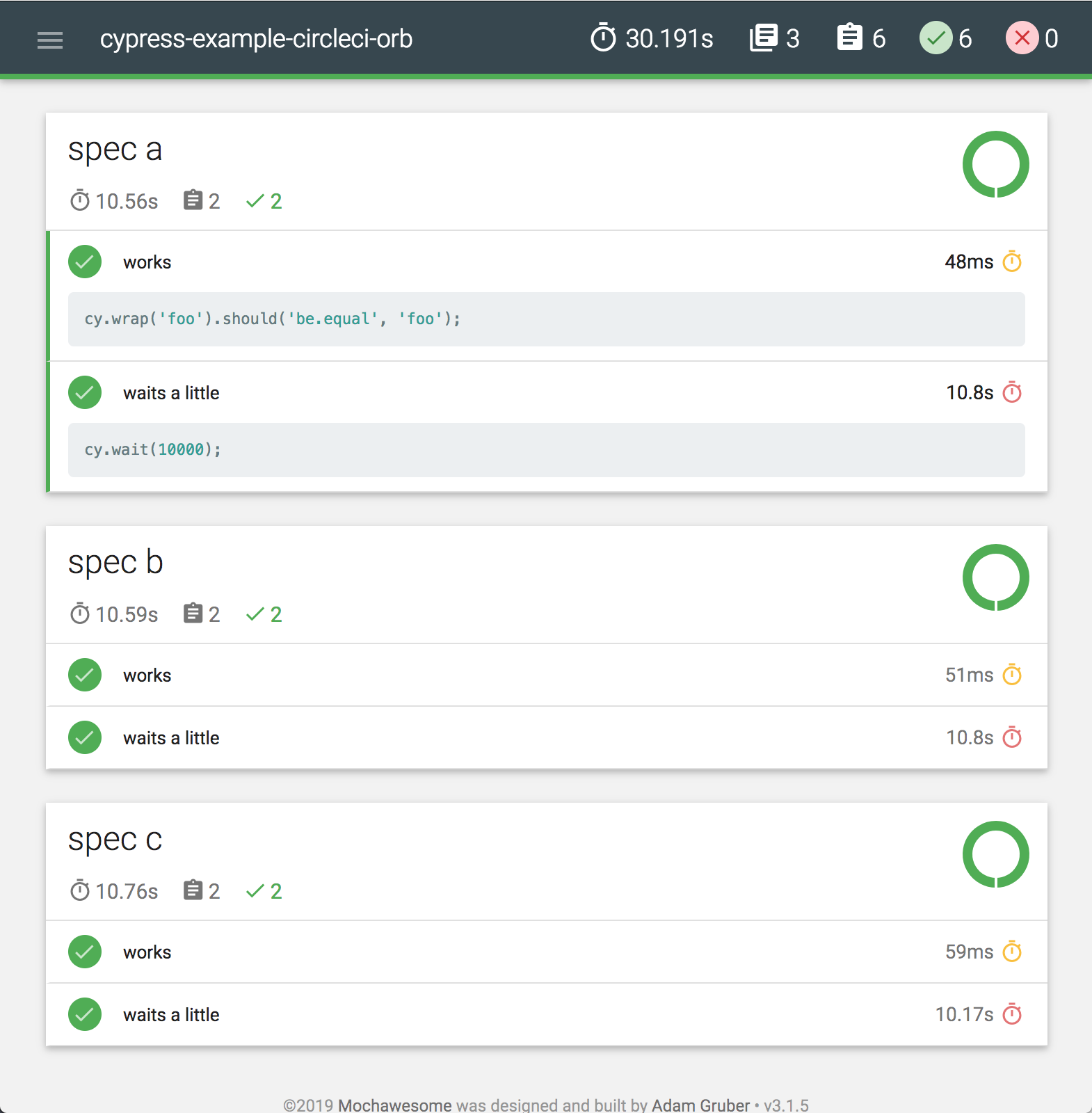
Une fois les informations d’échec obtenues, il convient d’analyser les erreurs.
Analysez les erreurs
L'analyse des erreurs dans Cypress revêt une importance cruciale pour garantir la qualité et la stabilité des tests automatisés. Lorsqu'un test échoue, il est essentiel de comprendre la cause profonde de l'échec afin de pouvoir prendre des mesures correctives appropriées. Comme vous venez de le voir, Cypress offre une gamme d'outils et de fonctionnalités pour faciliter cette analyse et aider les équipes de développement à identifier rapidement les problèmes.
En premier lieu, vous devez savoir si le problème que vous avez trouvé est une erreur, un défaut, une défaillance ou une anomalie tels que définis par l’ISTQB :
Erreur | Une erreur est une action humaine produisant un résultat incorrect. On parle aussi de confusion. |
Défaut | Un défaut est une imperfection ou une déficience d’un produit lorsqu’il ne répond pas à ses exigences ou à ses spécifications. On parle aussi de bug ou faute. |
Défaillance | Une défaillance est un événement dans lequel un composant ou un système n’exécute pas une fonction requise dans les limites spécifiées. |
Anomalie | Une anomalie est toute condition qui dévie des attentes basées sur les exigences de spécifications, documents de conception, documents utilisateurs, standards, etc, ou des perceptions ou expériences de quelqu’un. |
Ensuite, Il peut y avoir plusieurs types d’erreurs ou de défauts. La liste qui suit n’est pas exhaustive car ils dépendent du contexte de test et de l’application que vous testez :
Une erreur flaky : C’est une erreur de votre côté qui peut être corrigée. Vous en apprendrez plus dans la prochaine section.
Un défaut API : Il survient lorsque les appels à des services web ou à des API échouent ou renvoient des réponses inattendues. Cela peut inclure des codes d'état HTTP incorrects, des erreurs de syntaxe JSON, des erreurs de requête réseau, etc.
Un défaut front : Il est lié à l'interface utilisateur de l'application. Ces défauts peuvent inclure par exemple des éléments DOM introuvables, des interactions utilisateur incorrectes, des messages d'erreur affichés à l'écran, des problèmes de mise en page ou de style, etc.
Une erreur de données : Elle se produit lorsque les données utilisées dans les tests sont incorrectes ou inappropriées. Cela peut inclure des problèmes de format de données, des données manquantes ou corrompues, des valeurs incorrectes, etc.
Une erreur de configuration : Elle se produit lorsque les paramètres de test, les dépendances ou les configurations de Cypress ne sont pas correctement définis. Cela peut entraîner des échecs de test dès le début de l'exécution.
Un défaut de sécurité : Il se produit lorsque l'application ne respecte pas les pratiques de sécurité recommandées. Cela peut inclure des vulnérabilités de sécurité (comme une faille XSS, que nous avons vue), des erreurs d'autorisation (un utilisateur qui a accès à des données alors qu’il ne devrait pas), des fuites d'informations sensibles, etc.
Une erreur de gestion des états : Elle survient lorsque les tests ne sont pas correctement conçus pour gérer les états de l'application. Cela peut inclure des problèmes de nettoyage après les tests, des interactions avec des données résiduelles, etc.
Un défaut de performance : Il se produit lorsque l'application ne répond pas aux exigences de performance attendues. Cela peut inclure des temps de chargement excessifs, des ralentissements, des goulots d'étranglement, etc.
Vous devez ensuite évaluer la criticité de ces problèmes. L'identification de la criticité d'une erreur, d'un défaut, d'une défaillance ou d'une anomalie est une étape cruciale dans le processus de développement d’applications et de tests.
Cette évaluation permet de déterminer l'impact potentiel de l'incident sur l'application, les utilisateurs et le fonctionnement global du système.
Voici quelques étapes et considérations pour identifier la criticité d'un problème :
Analyse de l'impact | Lorsque vous avez détecté une erreur ou un défaut, la première étape consiste à analyser l'impact de l'incident. Il est important de comprendre quelles parties de votre application sont affectées, quels scénarios sont impactés et si l’incohérence peut potentiellement causer des problèmes dans d'autres parties de votre système. |
Priorisation | Une fois l'impact évalué, il est essentiel de prioriser le problème en fonction de sa gravité. - Les défauts critiques peuvent entraîner des dysfonctionnements majeurs, des pertes de données ou des risques pour la sécurité. - Les défauts mineurs peuvent avoir un impact limité sur l'expérience utilisateur. |
Fréquence d'occurrence | Il est important que vous considériez la fréquence à laquelle le problème peut se produire. Un problème qui se produit fréquemment peut avoir un impact plus important qu'un problème rare, même si son impact intrinsèque est moins grave. |
Utilisateurs affectés | Il faut évaluer le nombre d'utilisateurs susceptibles d'être affectés par le problème. Un problème qui touche un grand nombre d'utilisateurs peut avoir un impact plus important sur la satisfaction des clients et la réputation. |
Contexte opérationnel | Le contexte opérationnel dans lequel le problème se produit peut également influencer sa criticité. Par exemple, un problème survenant dans un environnement de production peut avoir des conséquences plus graves qu'un problème dans un environnement de test. |
Conséquences commerciales ou financières | Il est crucial d'évaluer les conséquences commerciales potentielles du problème. Un problème qui perturbe les opérations commerciales, les transactions financières ou les processus critiques peut être considéré comme plus critique, comme vous l’avez vu précédemment dans la partie Évaluez ce qui est risqué ou critique. |
Risques pour la sécurité | Les problèmes liés à la sécurité, tels que les vulnérabilités ou les fuites de données, sont généralement considérés comme critiques en raison de leur impact potentiel sur la confidentialité et l'intégrité des données. |
Impact sur l'image de l'entreprise | Les problèmes dans une application peuvent avoir un impact direct sur l'image de l'entreprise. Si un problème est visible par les utilisateurs finaux, il peut affecter la perception de l'entreprise en termes de professionnalisme, de qualité et de fiabilité de ses produits ou services. Des problèmes fréquents ou graves peuvent potentiellement nuire à la réputation de l'entreprise et entraîner une perte de confiance des clients. |
Expérience utilisateur | L'image de l'entreprise est étroitement liée à l'expérience utilisateur. Les problèmes qui perturbent l'expérience utilisateur, qui rendent l'application difficile à utiliser ou qui entraînent des frustrations peuvent affecter la satisfaction des clients et l'image de l'entreprise. Une application instable ou sujette à des problèmes peut laisser une impression négative sur les utilisateurs. |
Réactions des utilisateurs | Les utilisateurs réagissent souvent publiquement aux problèmes qu'ils rencontrent avec une application, que ce soit sur les réseaux sociaux, les forums ou les critiques en ligne. Les problèmes qui attirent l'attention des utilisateurs et suscitent des commentaires négatifs peuvent rapidement circuler et affecter l'image de l'entreprise. |
Concurrence | Dans un marché concurrentiel, les problèmes peuvent avoir un impact sur la compétitivité d'une entreprise. Si les concurrents offrent des produits ou des services plus stables et fiables, une application sujette à des problèmes peut entraîner la perte de clients au profit de la concurrence. |
Confiance des partenaires et investisseurs | Les problèmes techniques peuvent également influencer la confiance des partenaires commerciaux, des investisseurs et d'autres parties prenantes. Une application instable peut soulever des doutes quant à la capacité de l'entreprise à fournir des solutions technologiques fiables. |
Parmi les erreurs que vous avez identifiées, il peut y en avoir qui sont dues à du code flaky, c'est-à-dire instable. Voyons ensemble comment les identifier et les corriger.
Corrigez les tests flaky
Un test flaky (aussi appelé test instable ou test capricieux) est un type de test automatisé qui peut produire des résultats variables d'une exécution à l'autre, même lorsque le code testé et l'environnement n'ont pas changé. En d'autres termes, un test flaky peut réussir lors d'une exécution et échouer lors de la suivante, sans que des changements significatifs n'aient été apportés au code ou à l'application. Par ailleurs, le test s’exécute correctement en mode manuel.
Les tests flaky peuvent être particulièrement problématiques dans les processus de tests automatisés, car ils créent de l'incertitude quant à la fiabilité des résultats des tests. Ces tests instables peuvent :
entraîner une perte de confiance dans les résultats des tests automatisés ;
retarder la détection et la résolution de problèmes réels ;
perturber le flux de travail de l'équipe de développement.
Les causes courantes des tests flaky comprennent des dépendances externes, des conditions de concurrence, des retards réseau, des délais d'attente inappropriés, des manipulations incorrectes de l'état de l'application, et d'autres facteurs qui peuvent entraîner une exécution inconsistante des tests.
Il est important de détecter et de corriger les tests flaky dès que possible pour garantir la validité des résultats des tests automatisés. Cela peut impliquer d'identifier les sources de flakiness, de mettre à jour les tests pour les rendre plus stables, de gérer les dépendances de manière appropriée, et de mettre en œuvre des mécanismes de reprise en cas d'échec.
Cypress est capable de réexécuter automatiquement les tests qui ont échoué, contribuant ainsi à minimiser les résultats instables des tests. Ce faisant, vous gagnerez du temps et des ressources précieuses afin que vous puissiez vous concentrer sur ce qui compte le plus pour vous.
Par défaut cependant, les tests Cypress ne s’exécutent qu’une fois, c'est-à-dire qu'ils ne sont pas relancés en cas d’échec. On peut donc configurer les tests pour avoir un nombre déterminé de nouvelles tentatives.
Pour cela, rien de plus simple. Dans le fichier cypress.config.js, configurez le nombre de fois que les tests doivent être exécutés :
module.exports = defineConfig({
e2e: {
"retries": {
"runMode": 0,
"openMode": 2
},
env: {
apiUrl: "http://localhost:8081",
},
setupNodeEvents(on, config) {
// implement node event listeners here
},
baseUrl: "http://localhost:8080/"
},
});Où runMode permet de définir le nombre de tentatives de test lors de l’exécution de npx cypress run et openMode permet de définir le nombre de tentatives de test lors de l’exécution de npx cypress open .
Dans cet exemple, vous avez donc défini que Cypress réessaiera les tests jusqu’à deux fois lors de l’exécution de npx cypress open (donc un total de 3 tentatives si le test échoue) et 0 fois lors de l’exécution de npx cypress run (donc un total d’une unique tentative même si le test échoue).
Vous pouvez également configurer le nombre de nouvelles tentatives de test pour tous les tests exécutés à la fois dans npx cypress open et npx cypress run :
{
"retries": 2
}et là tous vos tests seront réexécutés jusqu'à 3 fois si le test échoue.
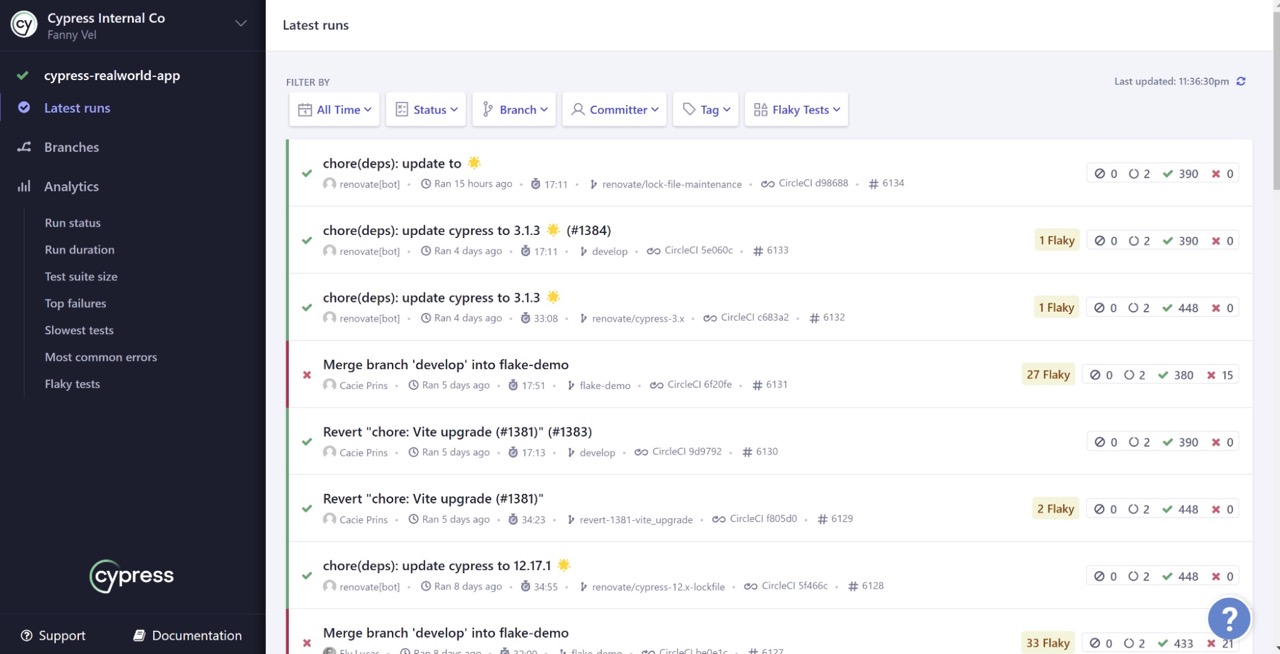
Si vous utilisez Cypress Cloud, alors les informations relatives aux nouvelles tentatives de test sont affichées dans l'onglet Test Results.
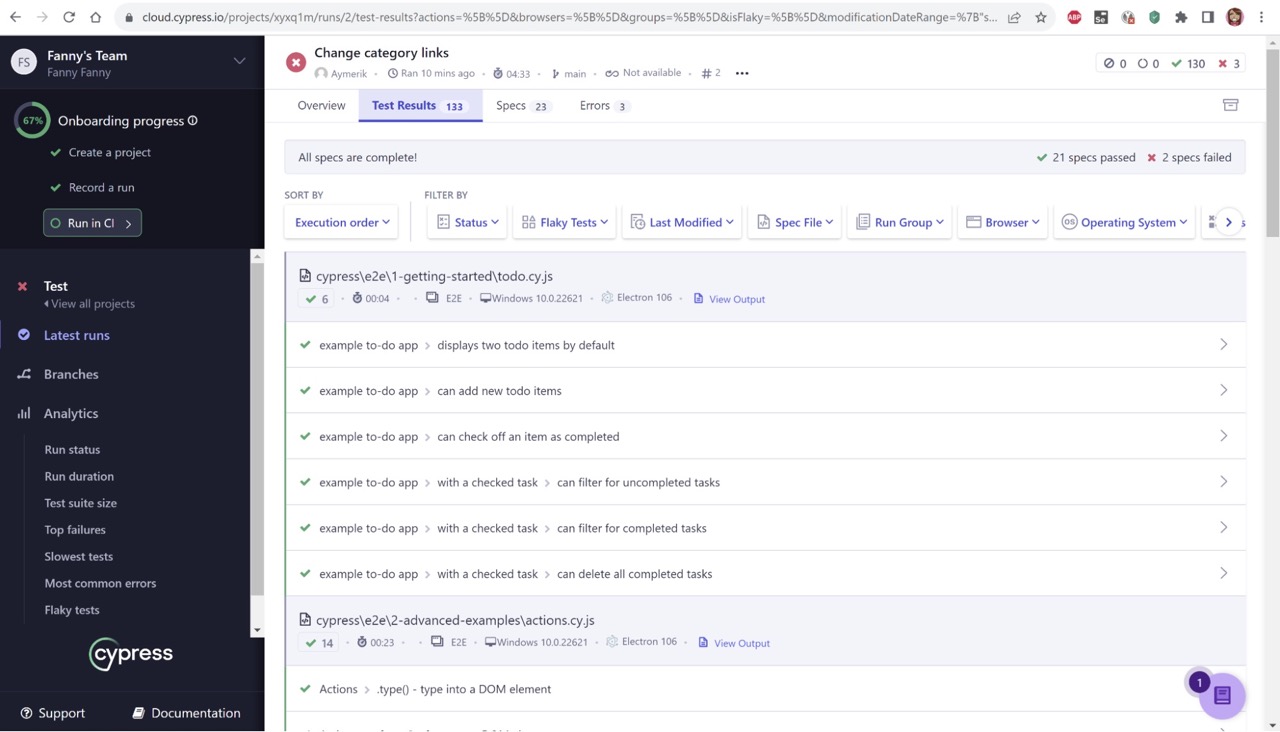
La sélection du filtre Flaky affiche les tests qui ont été réessayés puis réussis pendant l'exécution. Ces tests sont également indiqués par un badge Flaky sur la page Latest runs et l'onglet Test Results sur la page Execution Details.
À vous de jouer !

Imaginons que vous testiez que le formulaire ne s’envoie pas quand le message est supérieur à 250 caractères.
Créez votre cas de test.
Indice : vous pouvez utiliser un générateur de texte pour vous aider : https://www.npmjs.com/package/lorem-ipsum.
La section Créez votre premier test réel peut aussi s’avérer utile.
Ce test ne s’est pas terminé comme nous le voulions car le formulaire s’est envoyé, peu importe le nombre de caractères dans le message. C’est donc un test en échec.
Consultez la suggestion de corrigé.
En résumé
Les tests flaky sont des tests automatisés instables, produisant des résultats variables et pouvant compromettre la fiabilité des processus de test.
La correction des tests flaky est essentielle pour garantir la fiabilité, la confiance et la détection précoce des problèmes.
L'analyse des erreurs dans Cypress implique l'utilisation de fonctionnalités telles que la visualisation en direct, les captures d'écran et les messages d'erreur pour résoudre les problèmes efficacement.
Identifier la criticité d'une incohérence implique d'évaluer l'impact, la fréquence, les utilisateurs affectés, le contexte opérationnel et les conséquences commerciales, tout en tenant compte de l'image de l'entreprise.
Vous pouvez modifier le fichier de configuration de Cypress pour exécuter à nouveau les tests en échec mais Cypress n’exécute pas les hooks before et after même s’ils sont en échec. Cependant, si un test est en échec, il exécute les hooks beforeeach et aftereach.
Maintenant que vous avez toutes les informations de réussites et d'échecs, il est temps d’officialiser et de communiquer correctement à vos parties prenantes vos résultats et analyses en vous basant sur ce que vous avez identifié.
