Tirez un maximum de ce cours
Découvrez l’objectif du cours
Dès le deuxième chapitre de ce cours, vous allez explorer les fondamentaux du streaming de données et découvrir pourquoi Redpanda est une solution performante pour le traitement des flux en temps réel.
Le troisième chapitre est consacré à l’installation et à la configuration de Redpanda.
Dans le quatrième chapitre, vous allez entrer dans la phase d’analyse des flux de données. Vous apprendrez à :
récupérer et traiter des événements en temps réel ;
appliquer des transformations sur les données avec Apache Spark ;
stocker les résultats dans un datalake optimisé.
Enfin, le cinquième et dernier chapitre va vous permettre d’explorer des outils et systèmes complémentaires pour une gestion avancée des flux de données : Redpanda Connect et Schema Registry.
Rencontrez votre professeur
Je suis Alexandre Bergère, passionné des technologies de données et de cloud basé à Paris, spécialisé dans l'architecture des données cloud et les solutions SaaS. Actuellement, je suis Head of Data & AI Engineer chez DataGalaxy. J'ai deux passions : implémenter des modern data stacks performantes et économiques (comme DuckDB, Delta et Redpanda), et développer Kaiten, une plateforme open source qui centralise la gestion des déploiements, des métriques d’usage et des fonctionnalités pour les applications SaaS. Fort d'une solide expérience dans l'enseignement et le mentorat, je m'engage à former la prochaine génération de professionnels des données tout en contribuant activement à des projets innovants.
Découvrez le fonctionnement du cours
Ce cours suit une progression logique que l'on a séquencée en cinq principaux chapitres.
Qu’est-ce que Redpanda University et que contient exactement cette plateforme ?
Redpanda University est une plateforme de formation gratuite et accessible à tous. Elle est conçue pour enseigner les fondamentaux du streaming de données en temps réel. Elle s’appuie sur Redpanda, une solution de streaming compatible avec Apache Kafka.
Les cours sont conçus pour un apprentissage autonome, permettant à chacun de progresser à son propre rythme. Tout le contenu est en anglais et chaque lien que nous allons vous fournir vous indique un temps estimatif de complétion. Dans le cas ci-dessous, le temps estimé du chapitre est de 2h.
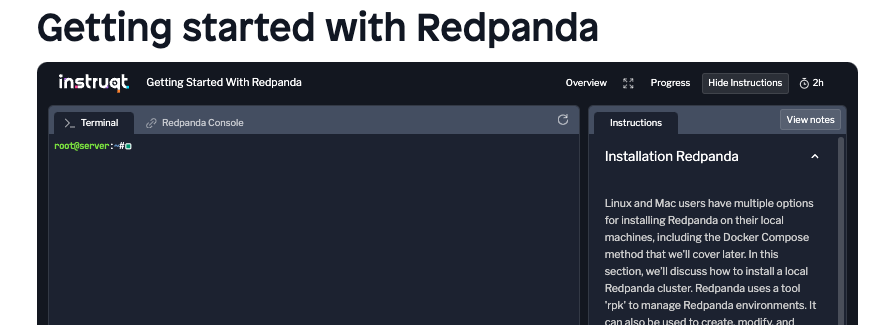
La majorité des chapitres contiennent :
Des vidéos explicatives permettant d'assimiler les concepts clés. En passant par les paramètres, les vidéos YouTube peuvent être sous-titrées en anglais puis traduites automatiquement en français.
De la documentation technique détaillée, accessible à tout moment.
Des tutoriels interactifs pour une mise en pratique progressive.
Des exemples de code et projets concrets afin d’appliquer directement les notions abordées. Vous aurez alors accès à un environnement virtuel.
Des scénarios réels et des études de cas, comme le suivi de commandes.
Des quiz et évaluations pour vérifier la compréhension.
Un support communautaire permettant d’échanger avec d’autres apprenants et experts.
Pour vous inscrire sur la plateforme, vous devez remplir votre prénom, votre nom, le nom de votre entreprise, votre adresse professionnelle et un mot de passe. Pour le nom de l’entreprise et l’adresse mail associée, vous pouvez utiliser, ou non, votre compte OpenClassrooms.
Avant de démarrer, voici quelques conseils pour exploiter au mieux le contenu de ce cours et optimiser votre apprentissage :
Lisez le texte dans chaque chapitre pour comprendre pourquoi les concepts abordés sont importants.
Profitez de chaque occasion de pratiquer en faisant une pause dans le cours pour vous entraîner de votre côté, et reproduire pas à pas ce que vous avez lu dans le cours !
Découvrez le projet fil rouge
Vous travaillez en tant que Data Engineer pour la boutique en ligne fictive Click et Achète. Après avoir centralisé les données grâce à Airbyte dans un bucket Amazon S3, l’entreprise fait maintenant face à un nouveau défi : elle souhaite analyser et traiter les données en temps réel pour prendre des décisions plus rapides et améliorer ses opérations.
En effet, des besoins critiques ont émergé :
Suivi des commandes en temps réel : l’équipe logistique doit être alertée instantanément des nouvelles commandes pour optimiser les livraisons.
Détection des fraudes : une surveillance instantanée des transactions permettrait d’identifier des comportements suspects et de réduire les fraudes.
Personnalisation des recommandations : l’équipe marketing veut proposer des recommandations dynamiques aux clients en fonction de leur navigation et de leur historique d’achats.
De plus, Click et Achète est désormais une entreprise internationale. Chaque pays possède sa propre base de données PostgreSQL, ce qui génère plusieurs sources de données identiques, chacune nécessitant son propre système pour traiter les informations. Cette multiplication des sources et des consommateurs crée des défis supplémentaires pour la gestion et l’analyse des données.
Pour répondre à ces enjeux, l’entreprise a décidé de mettre en place un pipeline de streaming de données, basé sur Redpanda pour gérer les flux d’événements et permettre un traitement rapide et efficace des données en mouvement.
Votre mission est donc de concevoir ce pipeline de streaming afin de traiter, transformer et stocker ces données efficacement, tout en garantissant une latence minimale et une scalabilité optimale pour répondre aux besoins des différentes équipes internes.
Prêt à installer Redpanda ? Rendez-vous dans le prochain chapitre !
