Analysez les données provenant de Redpanda en temps réel
Une fois vos données stockées et diffusées via Redpanda, il est essentiel de pouvoir les analyser en temps réel pour en tirer des informations exploitables. C’est là qu’intervient Apache Spark, un framework de traitement de données distribué utilisé pour des calculs complexes. Grâce à sa capacité à traiter des données en temps réel, il est particulièrement adapté aux applications de streaming. Spark Streaming, une fonctionnalité de Spark, permet de traiter des données en continu. Cela est crucial pour des applications nécessitant des réponses instantanées en fonction des données qui arrivent, comme dans les cas de la détection de fraudes ou de l'analyse de logs en temps réel.
Dans ce contexte, Redpanda joue un rôle clé en tant que système de messagerie événementielle haute performance. Il sert de canal fiable pour la transmission des événements en continu, tandis que Spark Streaming les consomme, les analyse et les transforme en temps réel.
Pour mieux comprendre l'intégration de Redpanda et Spark Streaming, nous allons découper le processus en trois étapes :
Dans cette première étape, vous allez configurer votre environnement local pour pouvoir récupérer et afficher les données en temps réel depuis un cluster Redpanda. L’objectif est de créer une application Spark Streaming qui consomme les données envoyées dans un topic Redpanda.
Suivez le tutoriel jusqu’à la connexion au topic Redpanda, soit jusqu’au deuxième bloc de code après Creating the Spark Streaming application. Vous effectuerez alors les étapes suivantes :
Configurer Redpanda et Spark en local : Suivez la première partie du tutoriel pour installer Redpanda et Spark. Cette configuration est nécessaire pour interagir avec les données en temps réel (Même si vous avez déjà installé Redpanda précédemment, il est recommandé de relancer votre conteneur Docker avec une image adaptée à ce nouveau cas d’usage.)
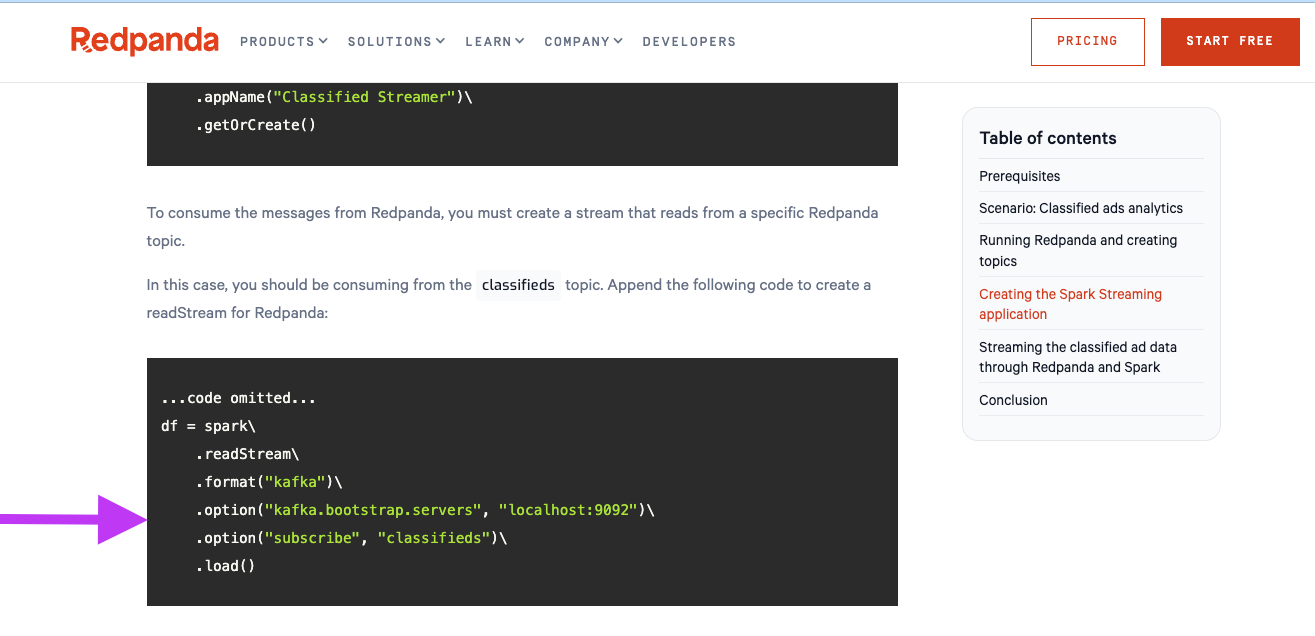
Créer une application Spark : Créez une application Spark Streaming en Python pour lire les données depuis un topic Redpanda.
Lire les données depuis Redpanda : Configurer Spark afin de pouvoir récupérer les données associées au topic.
Arrêtez-vous ici
Une fois ces étapes terminées, vous pourrez consommer les données envoyées dans le topic Redpanda. Afin de vérifier que votre configuration fonctionne bien, vous pouvez afficher les données directement dans la console via le code supplémentaire suivant :
Une fois que vous avez récupéré vos données depuis Redpanda, l’étape suivante consiste à appliquer des transformations en temps réel sur ces données. Avec Spark Streaming, vous pouvez transformer vos flux de données de manière flexible et puissante. Cela inclut des opérations telles que :
Filtrage : éliminer des données non pertinentes en fonction de critères spécifiques.
Enrichissement : ajouter de nouvelles informations ou calculs aux données existantes.
Agrégation : effectuer des calculs sur des groupes de données, comme des moyennes, des sommes ou des comptages.
Application de règles conditionnelles : ajouter de la logique métier pour prendre des décisions instantanées (par exemple, valider une transaction ou un événement).
En utilisant ces transformations, vous pouvez enrichir, filtrer et analyser les flux de données en temps réel, ce qui permet de prendre des décisions instantanées et d'agir rapidement sur les données.
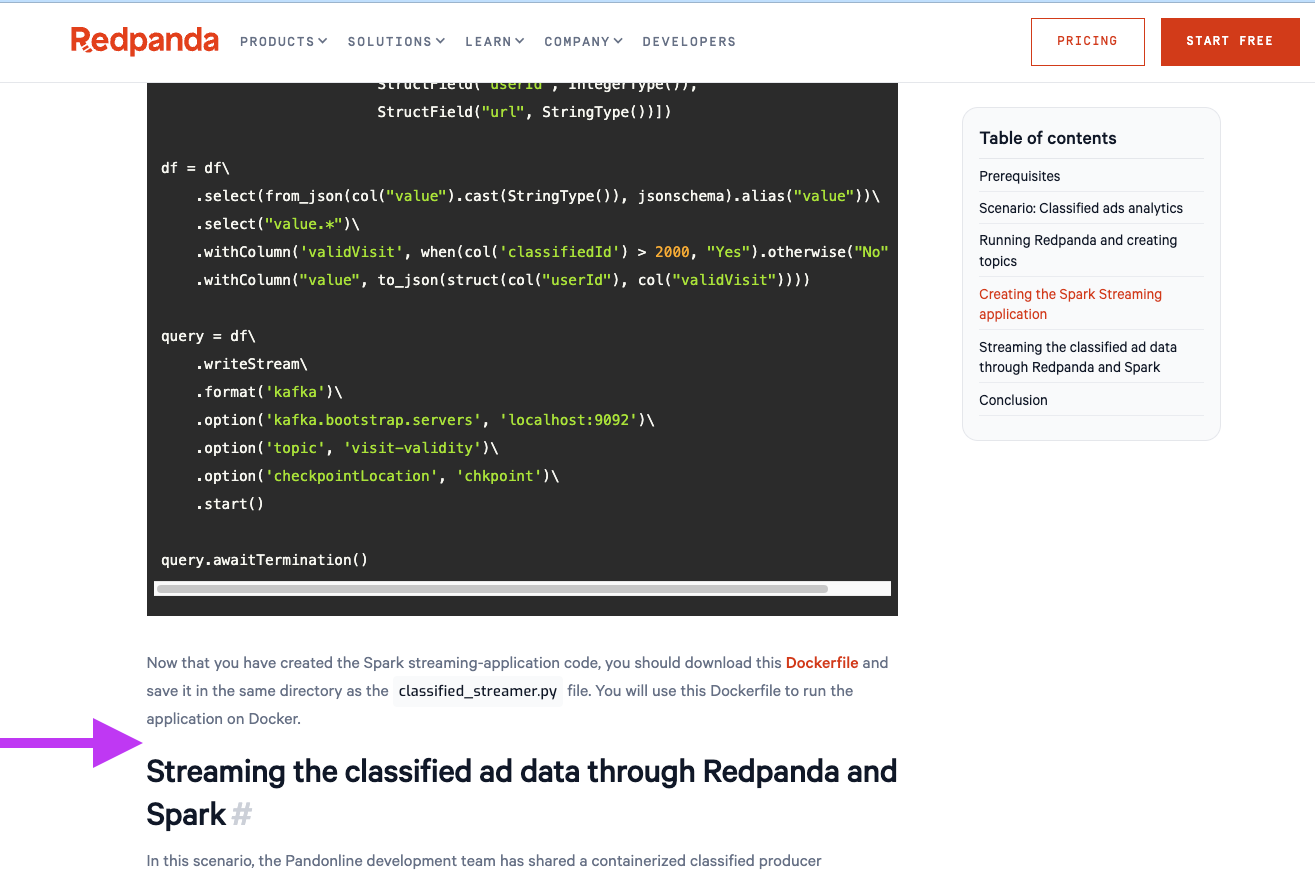
Définir un schéma pour interpréter les données JSON provenant de Redpanda.
Appliquer des transformations sur les données, par exemple pour ajouter une colonne conditionnelle qui détermine si une visite d‘un utilisateur sur le site web est valide ou non, ou encore filtrer les données en fonction de certaines conditions.
Arrêtez-vous ici
Une fois les données transformées et prêtes à l'emploi, la dernière étape consiste à les rendre disponibles à d'autres systèmes.
3. Stockez les données
Dans la dernière étape du tutoriel, vous allez apprendre à envoyer les informations transformées dans un autre topic Redpanda. Cela permet de rendre les données disponibles en temps réel pour d'autres consommateurs. Ce mécanisme garantit que les données traitées sont immédiatement accessibles pour des applications ou services qui en ont besoin, tout en permettant à plusieurs consommateurs de se connecter à ce nouveau topic. Cependant, il est important de noter que Redpanda n'est pas une base de données, mais un système de streaming conçu pour transporter et distribuer des événements en temps réel. Il ne remplace donc pas un stockage de longue durée.
Au-delà de la réécriture dans un autre topic Redpanda, il est souvent nécessaire de stocker ces données à long terme dans un datalake, où elles peuvent être utilisées pour des analyses futures ou des traitements supplémentaires. L'utilisation de formats de stockage optimisés, comme Delta Lake ou Apache Iceberg, offre plusieurs avantages, notamment la gestion des versions de données, la cohérence des écritures et la possibilité d'effectuer des requêtes analytiques à grande échelle.
Voici un exemple de code qui montre comment écrire les données au format Delta à partir de Spark Streaming :
Ce code envoie les données traitées dans un répertoire spécifique de votre datalake, en utilisant le format Delta pour garantir l'optimisation des lectures futures. Vous pouvez adapter cette méthode pour utiliser le format Iceberg ou tout autre format similaire, en fonction de vos besoins en matière de gestion des données.
Récupérez, transformez et stockez les données de Click et Achète
Il est temps de mettre en place l'architecture nécessaire pour répondre aux besoins critiques identifiés plus tôt :
Suivi des commandes en temps réel : Un script Python indépendant se connecte directement à Redpanda, récupère les événements dès qu'une nouvelle commande est créée, et déclenche immédiatement une alerte (simulation d'un envoi vers une application comme Slack). Ce mécanisme garantit une réponse instantanée pour optimiser la logistique.
Détection des fraudes et personnalisation des recommandations : Spark Streaming consomme les événements envoyés par Redpanda, applique des transformations adaptées et sauvegarde ces données dans un format optimisé (Delta). Ce stockage facilite par la suite les analyses avancées nécessaires pour identifier des comportements frauduleux et améliorer les recommandations clients.
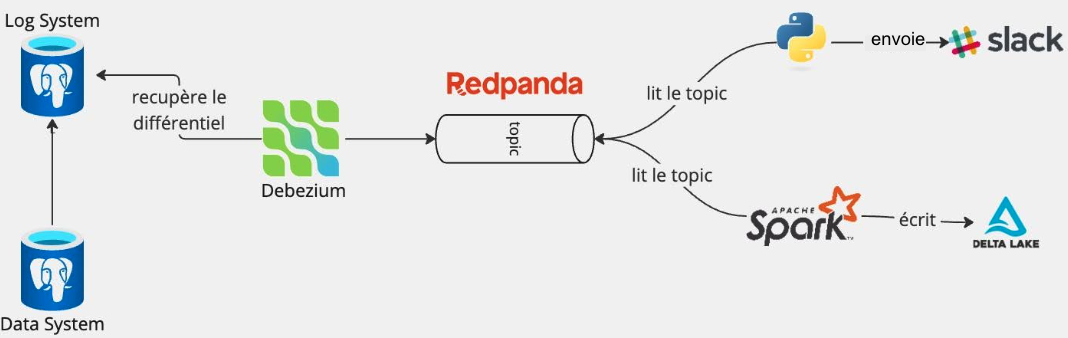
Pour simplifier ce cas pratique, nous utiliserons une seule base de données. Toutefois, dans un contexte réel, cette même configuration pourra être déployée pour gérer l’ensemble des bases de données PostgreSQL du groupe Click et Achète, en intégrant la diversité des sources à traiter. Voici l’architecture data que nous allons mettre en place pour Click et Achète.
Architecture Click et Achète
On va maintenant mettre en place l’infrastructure associée pour répondre aux deux cas d’usage. Nous allons :
Mettre en place un environnement Docker avec Redpanda, PostgreSQL, Debezium, Spark et Python (vidéo 1).
Configurer le système d’envoi des données provenant des bases PostgreSQL en différentiel (Change Data Capture) (vidéo 1).
Récupérer les données avec Spark Streaming, les transformer et les stocker au format Delta (vidéo 2).
Utiliser Python pour récupérer les données stockées et les intégrer dans une application (par exemple, envoi d’alertes via Slack) (vidéo 2).
Modifier des données dans PostgreSQL et observer les changements en temps réel via Redpanda Console, Spark Streaming et Python (vidéo 3).
Voici une première vidéo de démonstration qui présente les principales étapes à suivre pour configurer votre système.
La deuxième vidéo de démonstration vous montre les étapes pour gérer les données avec Spark Streaming et récupérer les données stockées.
La dernière vidéo vous décrit l’étape finale qui est de modifier les données et d’observer les changements en temps réel.
En résumé
Redpanda est un système de messagerie événementielle haute performance qui permet la transmission continue de données en temps réel.
Spark Streaming est utilisé pour récupérer, transformer et stocker les données issues de Redpanda en temps réel.
Spark Streaming applique des transformations en temps réel sur les flux de données, comme le filtrage, l’agrégation ou l’ajout de règles métier.
Les données transformées peuvent être réécrites dans un autre topic Redpanda pour d’autres consommateurs ou stockées durablement dans un datalake avec des formats comme Delta Lake ou Apache Iceberg.
Après avoir exploré les étapes de récupération et de transformation des données en temps réel avec Spark Streaming, nous allons maintenant découvrir une autre approche pour gérer l’ingestion et la distribution des données.
 Une fois vos données stockées et diffusées via Redpanda, il est essentiel de pouvoir les analyser en temps réel pour en tirer des informations exploitables. C’est là qu’intervient Apache Spark, un framework de traitement de données distribué utilisé pour des calculs complexes. Grâce à sa capacité à traiter des données en temps réel, il est particulièrement adapté aux applications de streaming. Spark Streaming, une fonctionnalité de Spark, permet de traiter des données en continu. Cela est crucial pour des applications nécessitant des réponses instantanées en fonction des données qui arrivent, comme dans les cas de la détection de fraudes ou de l'analyse de logs en temps réel.
Une fois vos données stockées et diffusées via Redpanda, il est essentiel de pouvoir les analyser en temps réel pour en tirer des informations exploitables. C’est là qu’intervient Apache Spark, un framework de traitement de données distribué utilisé pour des calculs complexes. Grâce à sa capacité à traiter des données en temps réel, il est particulièrement adapté aux applications de streaming. Spark Streaming, une fonctionnalité de Spark, permet de traiter des données en continu. Cela est crucial pour des applications nécessitant des réponses instantanées en fonction des données qui arrivent, comme dans les cas de la détection de fraudes ou de l'analyse de logs en temps réel.