Implémentez la pipeline CD de votre projet ML avec Github Actions
Je vais commencer ce chapitre par vous donner une bonne nouvelle : la CD partage la même structure et la même syntaxe que la CI, à savoir un fichier .YAML avec un trigger, des jobs et des steps.
Vous savez donc déjà lire une CD même si le contenu et le but de ce workflow sont complètement différent. Rentrons dans le dur sans plus tarder !
La CD appliquée aux projets Data
Commençons par une définition :
La CD (Continuous Delivery) est un workflow qui s’active automatiquement au moment où la branche principale évolue, afin de simuler son déploiement dans un environnement de test, de préproduction, ou de carrément déployer le code dans l’environnement de production.
Qui dit simuler déploiement dit… Docker ?
Eh oui ! On avait évoqué il y a deux chapitres qu’on ne va pas manuellement copier-coller des images Docker dans des Container Registry. En effet, la pipeline CD est l’outil qui vous permet d’automatiser un docker build et son transfert au Container Registry.
Sans surprises, La CD arrive chronologiquement après la CI ! En effet, on ne va pas aller Dockeriser un projet où des erreurs ou des incohérences subsistent. Nous pouvons illustrer tout ceci en prolongeant la mise en situation du chapitre précédent :
Vous avez codé de nouvelles features pour un modèle ML que vous avez “API-sé” avec FastAPI , tout fonctionne en local chez vous.
La CI n’a pas remonté d’erreurs et votre collègue a validé la pull request, qui a été intégrée avec la branche principale.
C’est souvent à ce moment-là que la CD active ! Elle va exécuter un workflow avec plusieurs étapes, dont un docker build et un transfert vers le Container Registry, l’objectif étant de s’assurer que vos nouvelles lignes de codes fraîchement intégrées ne créent pas de bug inédit et involontaire dans le docker build, ce qui peut être assez grave.
Pour illustrer l’importance cruciale de cette étape, prenons du recul et imaginons que notre modèle ML est en production, en train d’être utilisé par des utilisateurs métiers.
Votre modèle en production, comme on l’a établie avant, est le fruit d’un docker run d’une image dans une compute instance.
Cette compute instance a récupéré l'image à run depuis le Container Registry, qui est alimenté par la pipeline CD.
C’est pour cela que l’on croise rarement une CD qui va directement transférer votre image Docker de votre répo Git à l’environnement de prod. On a très souvent, un environnement intermédiaire en plus (l’environnement de préprod), voir d’autres couches supplémentaires en fonction des besoins et des spécificités de votre équipe Data.
Effectivement, avec seulement votre repo Git (environnement de dev) et la prod, nous ne pouvons pas être à 100% sûrs que l’image s’exécute correctement… avant d’être déjà en prod !
L’environnement de préprod sert justement à cela, c’est un environnement en principe identique à celui de la prod, où l’on peut lancer un compute instance figurant un conteneur qui encapsule le code fraîchement intégré dans la branche liée à l’environnement de préprod. Ainsi on peut utiliser le modèle ML à distance, comme le ferait l’utilisateur final. Cela permet de simuler le plus possible un environnement de prod, avec les nouvelles fonctionnalités que vous avez tout juste poussé.
Cette façon de travailler implique deux branches en plus de vos branches de développement :
Une branche Git liée à l’environnement de prod, que l’on appelle souvent la branche “release” (car il s’agit d’une livraison aux yeux de l’utilisateur final)
Un branche Git liée à l’environnement de préprod, que l’on appelle souvent la branche “master” ou “main”.
La différence entre les deux, c’est que le premier CD va aller jusqu’à remplacer automatiquement l’image Docker actuellement en production par la nouvelle, fraîchement pushé dans la branche de prod ou préprod. Alors que le deuxième CD va pousser dans l’image Docker fraîche dans le Container Registry, sans faire le dernier kilomètre qui consiste à rafraîchir l’image utilisée par le compute instance. En fonction des situations, on peut juger que cette dernière étape doit être lancée manuellement par un humain.
Découvrez votre première pipeline CD
La théorie est claire ? Si ce n’est pas encore complètement le cas, la pratique vous aidera à appréhender les concepts. Dans le screencast qui suit, nous montrons un fichier .yaml de CD, basé sur un environnement Github Actions et AWS.
Si vous voulez reproduire le code dans le screencast, il va falloir créer un compte AWS et un container registry dans ACR. Il faudra en plus paramétrer la politique d’accès réseau aux ressources de votre compte depuis l’extérieur. Faute de quoi l’étape Login to Amazon ECR ne fonctionnera pas. Pour cela, se référer au repo d’AWS.
La CD joue aussi le rôle de sécurité ! Souvent, seule la CD a les droits d’écriture dans l’environnement de prod, et c’est délibéré ! Ce n’est jamais une bonne idée de laisser la prod accessible en écriture à une action manuelle d’un collègue, sans CI ou CD pour s’assurer que la pipeline executée est propre.
Run de la pipeline CD sur Github Actions
Dans la continuité directe du screencast précédent, et tout comme dans le dernier chapitre, je vous propose de démo l’activation de la pipeline CD suite à l’acceptation de la pull request vers la branche principale du repo. Il s’agit en effet d’un cas très répandu d’activation de la CD :
Comme expliqué il y a deux chapitres quand on s’intéressait à la Big Picture de la Dockerisation, il existe plusieurs solutions au sein d’un Cloud Provider pour instancier l’image Docker que nous venons de pousser avec la CD en conteneur actif.
Chez AWS, nous pouvons utiliser SageMaker Real-Time Endpoints, SageMaker Serverless Inference, EKS (Elastic Kubernetes Service) ou encore Lambda… et j’en passe ! Le seul point commun entre tous ces services, c’est qu’ils peuvent partir de cette image Docker que nous avons construite ensemble (via la commande docker pull) pour l’instancier en conteneur, chacun à sa manière, en fonction des besoins des projets : Besoin d’un service managé ou pas, besoin d’une réponse en temps réel, besoin de ressources physiques spécialisés pour de l’inférence en ML etc.
“Dois-je faire du BYOC ou utiliser une image clé en main d’un Cloud Provider ?”
Vous l'avez compris, ça dépend.
Enrichissez votre pipeline CI/CD pour le ML
Restons dans le thème des spécificités des projets Machine Learning !
Pour le moment, tout ce que l’on a vu dans nos fichiers .yaml en CI comme en CD peut s’appliquer également à des projets de Software Engineering en Python ! En effet, notre code ML et toutes ses particularités sont encapsulées dans la commande docker build de la CD et dans les tests unitaires côté CI. Dans plusieurs projets, cela suffit déjà largement !
Toutefois, vous pouvez être confrontés à des projets avec de la donnée qui change TRÈS rapidement, ce qui peut rendre obsolète rapidement un modèle ML et justifier la nécessité d’aller plus vite sur la phase d’évaluation de la robustesse d’un remplaçant. Si en plus vous êtes plusieurs Data Scientists à travailler sur un tel projet et à créer des branches dans le repo pour tester des modèles ou du feature engineering, alors il sera très opportun d’avoir un job ou un yaml supplémentaire pour vous facilier la partie ML avec Github Actions.
Voici un screenshot directement issu du site de CML :
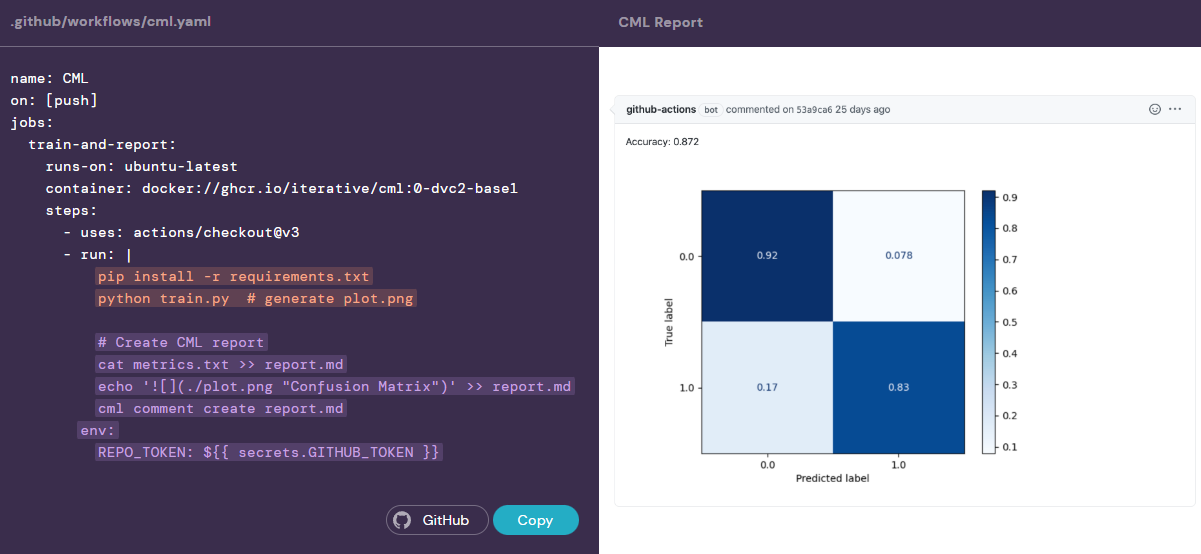
À ce stade, vous devez être capable de lire le template de yaml proposé et je vous en félicite d’ailleurs.
Ici, au moment du push sur une branche, Github va automatiquement créer un rapport en markdown, consultable sur votre branche par vos collègues, où l’on peut analyser la matrice de confusion d’un modèle de classification que vous venez de pusher ! Ici, la pipeline va lire un fichier metrics.txt, mais vous pouvez vous organiser différemment.
On pourrait même dans une telle pipeline, lancer un script d'entraînement et de test du modèle sur notre historique avec une validation croisée ou un Time Series Split, pour se donner les moyens de rapidement mesurer si un nouveau modèle est robuste quand testé sur notre historique !
Ceci dit, attention aux coûts, si chaque push dans chaque branche par chaque collègue active un processus aussi lourd, vous risquez de vous faire surprendre par la facture.
Vous voila arrivés au bout ! Vous maîtrisez désormais les bases des pipelines CI/CD, étape importante dans votre transition du rôle de Data Scientist vers le rôle de Machine Learning Engineer.
En résumé
Activez une pipeline CD pour automatiser le build Docker et le push de l’image vers un Container Registry.
Prévoyez un environnement de préproduction pour tester l’image avant son déploiement en production.
Ne déployez en prod qu’après validation de la CI, pour éviter de "casser la prod".
Enrichissez vos YAML avec des étapes spécifiques à vos projets ML (CML, Continuous Training).
Choisissez entre BYOC et images clés en main selon la complexité, les besoins et les ressources de votre projet.
Prêts à aller plus loin ? Passons au dernier chapitre pour découvrir comment orchestrer tout ce que nous avons mis en place avec des outils comme Airflow !
