Préparez votre environnement dbt Cloud et vos sources de données
Votre mission est de préparer le terrain de jeu où vous allez construire toutes les transformations à venir. Avant de nettoyer, structurer et fiabiliser les données de l’entreprise, il vous faut un environnement dbt Cloud opérationnel, connecté au data warehouse, et contenant vos premières sources déclarées. Sans cela, aucun pipeline ne pourra tenir debout.
Comprenez les versions de dbt et installez dbt Cloud
Identifiez les différences entre dbt Cloud et dbt Core
Avant de vous lancer dans la configuration, prenons un moment, en vidéo, pour remettre les choses en perspective.
Cela explique pourquoi l’entreprise MadeInFrance a choisi dbt Cloud — mais examinons concrètement les différences pour que vous sachiez ce que cela implique.
Critère | dbt Cloud | dbt Core |
Installation | Simple installation (création de compte), fonctionne directement dans le navigateur | Installation locale (Python + dépendances) |
Interface | IDE intégré avec coloration SQL, autocomplétion, exécutions intégrées | Pas d'interface : nécessite un IDE externe |
Mode d'exécution | Exécutions via l’interface web, orchestrées dans le cloud | Exécution en igne de commande uniquement ( |
Collaboration | Interface collaborative, aperçu des changements, PRs intégrées | Dépend du workflow Git local |
Orchestration | Jobs programmés directement dans dbt Cloud | Nécessite un outil externe (Airflow, GitHub Actions, etc.) |
DAG (graph des dépendances) | Visualisation intégrée et mise à jour automatique dans l’interface | Visualisation générée localement puis ouverte dans un navigateur |
Sécurité / Accès | Gestion centralisée des accès et permissions | Dépend de l’environnement local |
Performances | Exécutions dans le cloud, indépendantes de votre machine | Exécutions locales, limitées par votre machine |
Coût | Version gratuite + offres professionnelles disponibles | Gratuit (open source) |
Adapté à | Équipes souhaitant une expérience intégrée, collaborative et simple à maintenir. | Équipes souhaitant un environnement entièrement customisable, souvent intégré à un orchestrateur externe |
Installez dbt Cloud et Snowflake sur votre machine
Vous allez maintenant créer l’environnement qui accueillera votre premier projet.
Avant de créer votre premier projet dbt, assurez-vous de bien être inscrit à la version Free. Et voici les étapes à suivre pour créer votre compte dbt :
1. Sélectionner la version Free.
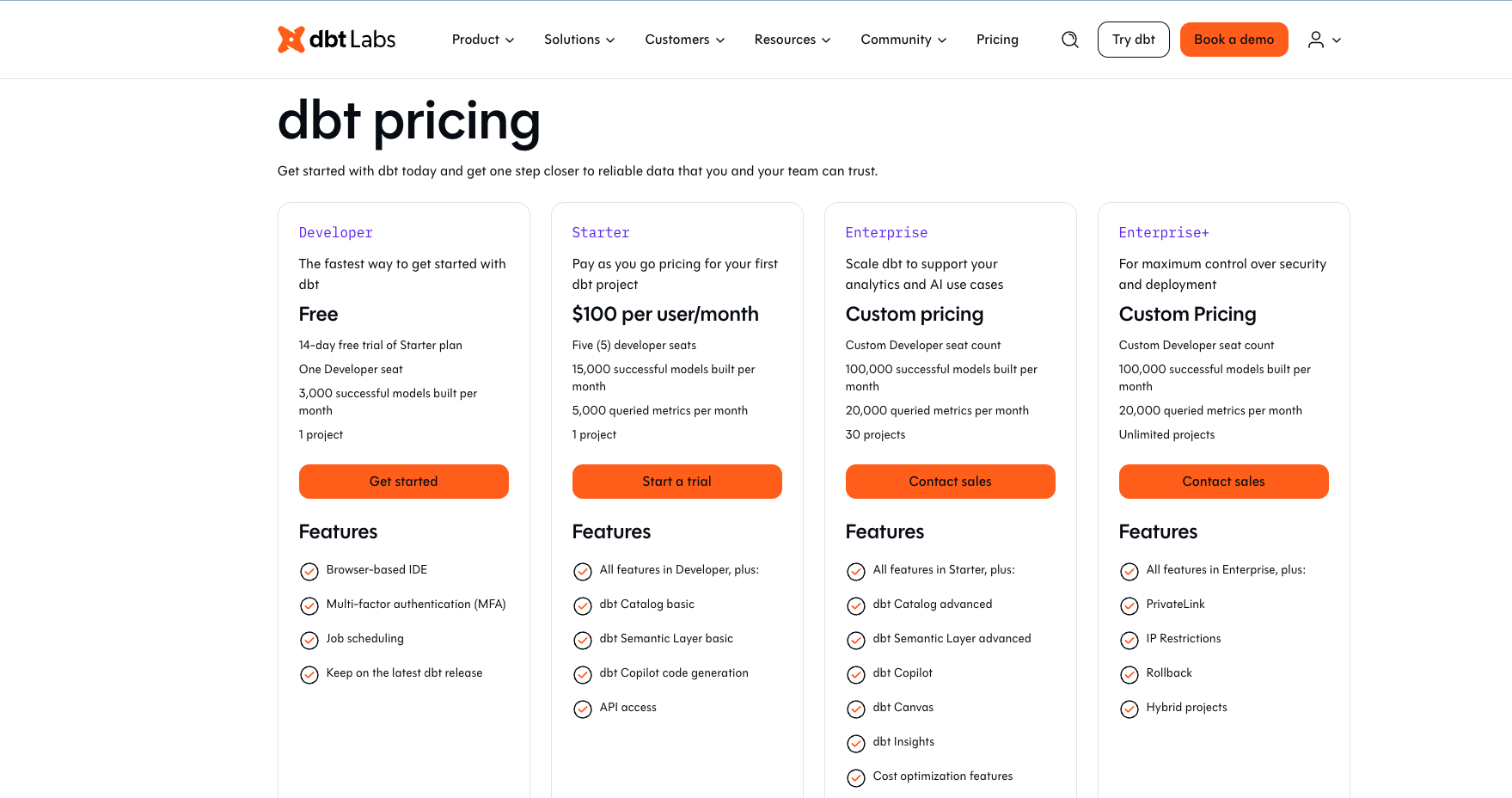
2. Créer votre compte utilisateur.
3. Configurer votre organisation (Organisation Name) : indiquez un nom simple et unique (ex. : Openclassrooms). Ce nom identifiera votre espace de travail global.
Créez votre espace de travail dbt Cloud et connectez dbt Cloud à votre data warehouse
Votre compte est maintenant actif. Il est temps de créer un projet dbt. Dans cette vidéo, vous allez configurer votre premier projet et la connexion technique qui permet à dbt Cloud de dialoguer avec Snowflake.
L’entreprise utilise Snowflake comme data warehouse. Vous avez déjà créé votre compte Snowflake. Il est maintenant temps de relier dbt Cloud à ce warehouse pour que vos transformations puissent enfin prendre vie. L’objectif est simple : saisir les paramètres de connexion nécessaires, vérifier que dbt peut se connecter correctement, puis associer cette connexion à votre projet.
Dans cette vidéo, on a :
créé notre premier projet dbt,
connecté notre outil à notre data warehouse Snowflake,
créé notre environnement dans dbt Cloud et
testé la connexion.
Une fois connecté, dbt Cloud vous guide pour créer votre premier workspace. Considérez-le comme votre atelier, celui où vous stockerez tout ce qui concerne votre pipeline.
OK, mais à quoi sert ce workspace ?
Il sert à :
centraliser votre code,
gérer l’accès aux membres de l’équipe,
stocker les connexions vers les différents data warehouses,
exécuter et monitorer vos transformations.
Collectez et déclarez votre source de données
Vous devez expliquer à dbt où se trouvent ces données. Cette étape consiste à créer une première couche de structure dans votre pipeline : les sources dbt. Elles jouent un rôle central dans la traçabilité et dans la qualité des données, car elles permettent de documenter clairement l’origine des tables que vous utiliserez dans vos modèles.
Dans votre mission, la table orders sera votre point d’entrée : c’est elle qui servira de base à vos premiers modèles de transformation.
Dans cette vidéo, vous allez apprendre à mettre en place une source dbt à partir de la table que vous avez importée dans Snowflake. Vous verrez comment créer le fichier de configuration schema.yml, y définir votre source et interroger dbt pour vérifier qu’elle est correctement prise en compte.
Dans cette vidéo, on a :
créé un dossier dédié pour organiser les données brutes,
créé un fichier
schema.yml,déclaré la source Snowflake et
vérifié la déclaration de la source.
Maintenant que vos données brutes sont bien configurées, vos données sont prêtes à être utilisées pour vos premières transformations.
Bien organiser vos sources

À vous de jouer
Contexte
Vous arrivez au terme de la préparation de votre environnement. Jusqu’ici, vous avez suivi le fil de l’équipe Data : import des données brutes dans Snowflake, création de votre espace dbt Cloud, connexion entre les deux, et déclaration des premières sources. Vous avez désormais tout ce qu’il faut pour reproduire ces actions par vous-même — une étape essentielle pour prendre en main votre environnement et commencer à vous sentir à l’aise dans votre rôle au sein de l’équipe.
Consigne
Reprenez exactement les étapes décrites dans le chapitre et mettez-les en pratique avec le fichier CSV mis à votre disposition.
Votre objectif est de :
importer les données brutes dans Snowflake,
établir votre projet dbt Cloud,
y connecter Snowflake,
organiser vos fichiers,
déclarer votre première source,
et vérifier que dbt la reconnaît bien.
Livrable
À la fin, vous devez obtenir :
un projet dbt Cloud fonctionnel,
une connexion valide à Snowflake,
vos données du fichier CSV chargées dans Snowflake,
un fichier
schema.ymlcontenant votre source déclarée.
En résumé
dbt Cloud permet de développer, exécuter et organiser un pipeline de transformation directement dans le navigateur, sans installation locale.
Un projet dbt repose sur une structure de fichiers définie (dont
dbt_project.ymlet le dossiermodels/) qui sert de base à toutes les transformations.La connexion entre dbt Cloud et un data warehouse, comme Snowflake, est indispensable pour exécuter des modèles et accéder aux données brutes.
Déclarer des sources dans un fichier
schema.ymlpermet à dbt de localiser précisément les tables du data warehouse et de garantir la traçabilité du pipeline.Organiser les fichiers du projet — en créant notamment un dossier dédié aux données brutes — facilite la lisibilité du pipeline et prépare le terrain pour les transformations futures.
Une fois les sources déclarées et reconnues par dbt, l’environnement est prêt pour créer les premiers modèles de transformation.
Vos sources sont maintenant prêtes, décrites et reconnues par dbt. Vous allez pouvoir entrer dans la partie la plus créative de votre mission : transformer ces données brutes en tables propres, cohérentes et prêtes à alimenter les analyses des équipes métier.
