Vérifiez la cohérence et la fiabilité des données
Mettez en place des tests dbt
Les données brutes de MadeInFrance contiennent des incohérences : dates invalides, montants non numériques, statuts hétérogènes… Même après le staging, elles doivent être validées pour garantir qu’aucune anomalie ne remonte dans les analyses.
dbt propose des tests génériques, simples à configurer, qui permettent de vérifier :
l’unicité des identifiants,
la présence obligatoire de champs (not null),
la cohérence de valeurs possibles (accepted values),
les relations entre tables (relationships).
Ces tests sont définis en YAML, sont compilés et exécutés en SQL et s'intègrent directement au flux d'exécution. Ils constituent la première brique de fiabilisation de votre pipeline.
Dans cette vidéo, vous allez apprendre à ajouter vos premiers tests génériques dans dbt pour vérifier la qualité de vos modèles de staging et intermediate.
Dans cette vidéo, on a :
configuré des tests génériques dans dbt,
exécuté les tests pour valider la cohérence des données et
mis en place des vérifications essentielles : unicité, présence obligatoire de champs, valeurs autorisées et cohérence des clés entre modèles.
Écrivez des tests personnalisés
Les tests génériques sont très utiles, mais ils ne couvrent pas tous les besoins métier de MadeInFrance.
Par exemple :
s’assurer que
amount > 0,vérifier qu’une date correspond à un format attendu,
garantir que les montants gratuits ou incorrects ont été filtrés,
valider qu’un modèle intermediate ne produit pas de doublons.
Pour cela, dbt permet d’écrire des tests personnalisés, sous forme de modèles SQL retournant des lignes qui ne doivent pas exister.
C’est un moyen d’intégrer vos règles métier directement dans le pipeline.
Dans cette vidéo, vous allez apprendre à créer vos propres tests SQL personnalisés pour valider des règles spécifiques au métier de MadeInFrance.
Dans cette vidéo, on a :
crée des tests personnalisés pour valider des règles métier spécifiques. Ces tests complètent les tests génériques et permettent de renforcer la robustesse du pipeline.
structuré un test SQL et
associé ce test à un modèle dbt.
Analysez les résultats et fiabilisez vos pipelines
Une fois vos tests en place, vous disposez enfin d’un moyen systématique de vérifier la cohérence et la fiabilité de vos données. Dans un contexte comme celui de MadeInFrance, où les décisions opérationnelles s’appuient directement sur les analyses issues du pipeline, il est crucial de savoir interpréter rapidement les résultats des tests, d’identifier les causes réelles des erreurs et de corriger les modèles concernés.
Les tests dbt ne se limitent pas à signaler des problèmes : ils constituent un outil de pilotage de la qualité. À chaque exécution du pipeline, ils vous permettent d’identifier :
des ruptures dans la cohérence des données,
des anomalies introduites par une évolution métier,
des incohérences héritées des sources brutes,
ou encore des erreurs logiques dans vos propres transformations.
Dbt Cloud présente ces résultats de manière structurée : pour chaque modèle, vous voyez immédiatement quels tests ont réussi (PASS), ceux qui ont échoué (FAIL), et le détail des lignes posant problème.
Corriger une erreur détectée par dbt suit toujours la même logique :
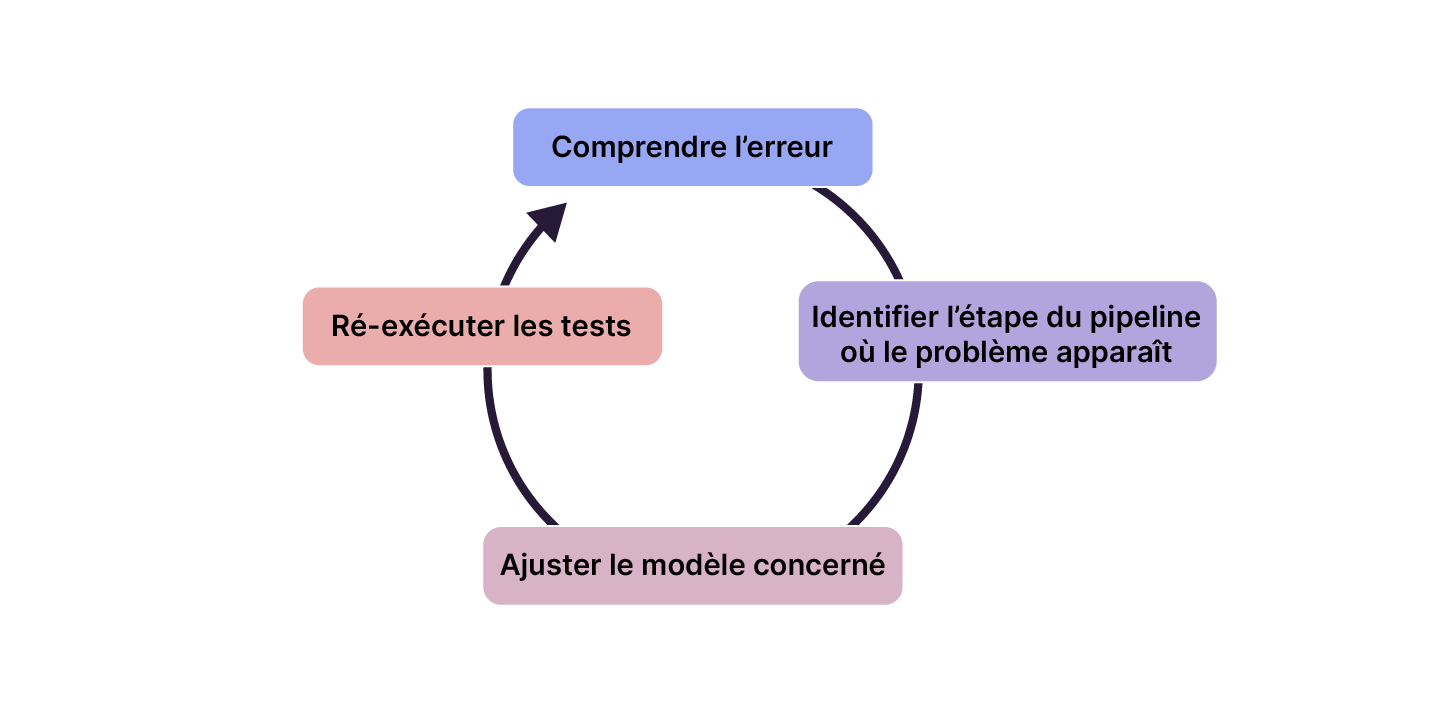
1. Comprendre l’erreur (type de test, colonne impactée, lignes en cause).
2. Identifier l’étape du pipeline où le problème apparaît :
la source brute ?
le nettoyage staging ?
l’enrichissement intermediate ?
3. Ajuster le modèle concerné en corrigeant la transformation ou en normalisant les données.
4. Ré-exécuter les tests pour valider la correction.
C’est ainsi que les équipes Data maintiennent un pipeline sûr, robuste et transparent, même lorsque les sources évoluent ou que le volume de données augmente.
Les tests échouent rarement “sans raison”. Chaque erreur suit un schéma fréquent que vous apprendrez à reconnaître. Ce tableau vous aidera à comprendre ce que dbt essaie de vous dire et où chercher la source du problème.
Type d’erreur détectée | Description | Cause fréquente | Exemples de corrections potentielles |
| Une colonne censée être obligatoire contient des valeurs vides | Donnée brute incomplète ou nettoyage insuffisant | Ajouter un |
| Une clé censée être unique apparaît plusieurs fois | Doublons dans la source ou erreur dans une jointure intermediate | Dédupliquer ou corriger la logique de jointure |
| Une colonne contient une valeur non autorisée | Incohérence métier, faute de frappe, casse non harmonisée | Uniformiser en staging (ex. |
| Une clé étrangère n’a pas de correspondance dans la table référencée | Données orphelines (client manquant) | Vérifier la source ou ajuster les filtres en intermediate |
| Montants négatifs, nuls ou non numériques | Données brutes incorrectes ou typage insuffisant | Filtrer, convertir ou corriger la transformation en staging |
| Dates impossibles | Multiples formats ou erreurs de saisie | Normaliser les formats, utiliser |
Erreur logique dans un modèle | Le test échoue malgré une source correcte | Jointure incorrecte, mauvaise colonne, oubli de filtre | Revoir la logique du modèle intermediate |
Ce tableau constitue un premier repère pour diagnostiquer efficacement les tests FAIL, surtout lorsque vous débutez. Avec l’expérience, vous reconnaîtrez rapidement les motifs récurrents et gagnerez en efficacité dans le débogage.
Dans cette vidéo, une erreur a été identifiée. Les corrections nécessaires à vos modèles y sont directement apportées et décrites.

À vous de jouer
Contexte
Votre pipeline de transformation commence à produire des données nettoyées et enrichies. Mais pour que les équipes de MadeInFrance puissent s’appuyer dessus en toute confiance, vous devez maintenant garantir que ces données sont cohérentes et fiables.
Consigne
En vous appuyant sur les explications du chapitre et les démonstrations des screencasts :
Ajoutez un test générique sur l’un des modèles que vous avez créés dans le chapitre précédent (modèle de staging ou modèle intermédiaire).
Exemples :unique, not null, accepted_values, relationships.Créez un test personnalisé simple, sous forme de requête SQL, pour capturer une règle métier ou une anomalie potentielle dans vos données.
Exemples : montant positif, date valide, absence de doublons inattendus.Exécutez
dbt testpour analyser les résultats.
Si aucun test n’échoue, introduisez volontairement une petite anomalie dans votre modèle (par exemple en retirant une ligne de nettoyage ou en modifiant une valeur de test) afin de générer unFAIL.Corrigez l’anomalie détectée, ajustez le modèle concerné, puis relancez les tests pour valider votre correction.
Livrable
À la fin de l’activité, vous devez obtenir :
un test générique déclaré dans le fichier YAML associé à votre modèle
(ex.stg_orders.yml,int_orders_enriched.yml),un test personnalisé SQL dans un fichier
.sqldans le dossiertests/,le rapport d’exécution de
dbt test(avec PASS / FAIL),un modèle corrigé, reflétant la résolution d’une anomalie détectée par vos tests.
En résumé
Les tests dbt permettent de valider automatiquement la qualité et la cohérence des données produites par vos modèles.
Les tests génériques (
not null,unique,accepted_values,relationships) sont définis dans les fichiers YAML associés aux modèles.Les tests personnalisés sont écrits en SQL dans le dossier
tests/et permettent de capturer des règles métier spécifiques.Un test échoue dès qu’il retourne au moins une ligne : un FAIL n’est pas forcément une erreur de modélisation, mais un signal de qualité à traiter.
L’analyse des résultats de
dbt testpermet d’identifier rapidement les transformations incorrectes ou les incohérences dans les données sources.Corriger un test FAIL implique d’ajuster les modèles concernés, puis de réexécuter le pipeline.
La validation continue (exécuter les tests à chaque changement) garantit la fiabilité durable du pipeline et évite les régressions.
Maintenant que votre pipeline est testé et fiabilisé, il est temps de le rendre plus transparent et plus facile à maintenir. Dans le chapitre suivant, vous apprendrez à documenter vos modèles et à visualiser vos dépendances pour offrir une vision claire de votre travail à toute l’équipe.
