Visualisez des fichiers

Etant donné que Linux est un système d'exploitation dont la conception initiale est très orientée fichier, vous allez passer votre temps à consulter ces fichiers pour administrer votre serveur. Heureusement, Linux fournit une trousse à outils complète permettant de visualiser de manière efficace le contenu de ces fichiers.
Nous aborderons dans ce chapitre les commandes cat et le couple infernal more et less.
Nous verrons également les trois canaux permettant de manipuler les flux de données, mais aussi les commandes grep, sed et awk qui ajoutent des fonctionnalités de filtrage et de transformation de ces flux.
Enfin nous terminerons par la fonctionnalité favorite de tout administrateur : la possibilité de chaîner des commandes avec les pipes Linux !
Affichez le contenu des fichiers
Dans le chapitre précédent vous avez pu consulter le contenu du fichier /proc/cpuinfo grâce à la commande cat:
seb@thor:~$ type cat cat est /bin/cat
Cette commande est externe au shell. Elle est très connue des administrateurs Linux et Unix avant eux. En effet c'est une commande historique qui permet de prendre un ou plusieurs flux de données en paramètre d'entrée, et de les afficher à l'écran sur le terminal.
Je vous propose maintenant de :
vous familiariser avec cette commande
catqui deviendra vite indispensable dans votre travail d’administration,découvrir quelques fichiers intéressants supplémentaires de l’arborescence Linux.
Vous avez pu remarquer que cat affiche tout le flux passé en entrée en une fois. Ainsi, la commande lancée sur le fichier/etc/passwd affiche toutes les lignes en un seul flux. Ce qui va probablement vous obliger à remonter dans l'affichage à l'écran pour consulter les premières lignes du fichier. Idéalement, il faudrait que l'affichage soit "paginé" en fonction du terminal.
C'est exactement ce que propose la commande less : elle va afficher les données passées en paramètre, paginées directement sur le terminal.
Dans la vidéo suivante, nous allons manipuler la commande less (et notamment les touches de commandes au clavier permettant de manipuler le flux de données paginé) et découvrir le rôle du fichier /etc/pam.d/login:
Je citerai pour finir, la documentation d'une excellente distribution Linux sur le sujet :
“Less is more, but more more than more is, so more is less less, so use more less if you want less more. (...)” - Slackware Linux Essentials
Quoi qu'il en soit, je vous conseille de vous familiariser avec less.
Utilisez les canaux de Linux
Dans le chapitre précédent, j'ai utilisé le mot-clé “sortie” pour évoquer les données transmises à l'écran sur le terminal par une commande. Sous Linux, cette notion est conceptualisée avec des canaux (streams en anglais).
Dans la majorité des cas, tous les programmes exécutés sous Linux disposent de 3 canaux de données :
stdin(pour standard input) : c'est le canal de l'entrée standard, et par défaut, lorsque vous lancez une commande, c'est votre clavier. La commande sera éventuellement capable de lire les informations saisies avec le clavier via ce canal. Il porte le descripteur de fichier numéro 0 ;stdout(pour standard output) : c'est le canal de la sortie standard, et lorsque vous lancez une commande depuis un terminal, c'est l'écran par défaut. Le résultat et les données affichées par la commande sont diffusés sur l'écran. Il porte le descripteur de fichier numéro 1 ;stderr(pour standard error) : c'est le canal du flux concernant les erreurs, et par défaut, lorsque vous lancez une commande, c'est aussi l'écran. La commande va différencier les données “normales” des données “erreur” et peut changer de canal pour diffuser ces informations.
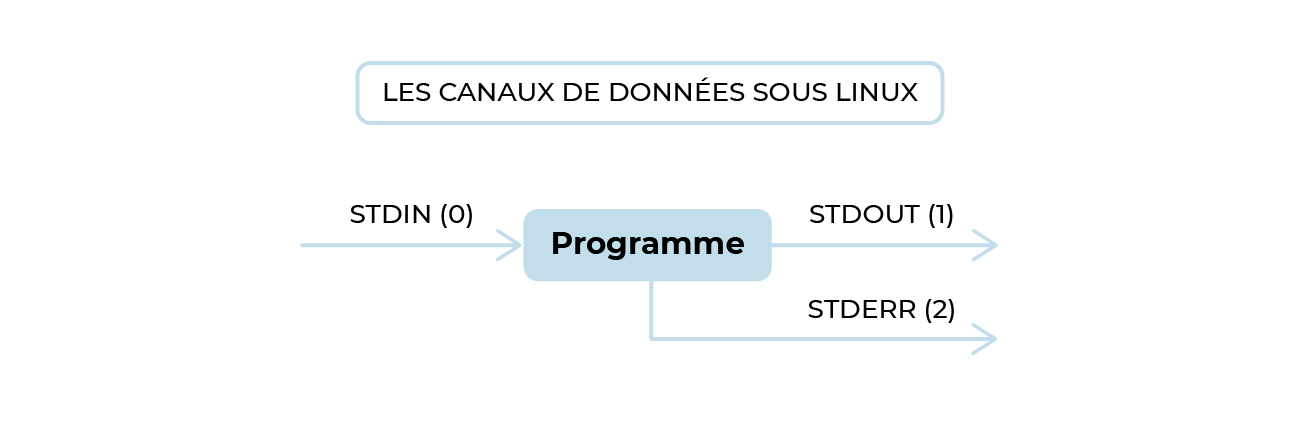
Pour manipuler ces canaux, il est nécessaire d'utiliser les caractères représentant des :
chevrons simples tels que
>et<,mais aussi doublés tels que
>>et<<.
Je vous propose d’utiliser les canaux standard de Linux pour :
effectuer des actions sur les flux (rediriger la sortie d’une commande dans un fichier ou différencier les sorties
stdoutetstderr) ;découvrir le fichier
/var/logs/messages.
Filtrez le contenu des fichiers
Très souvent vous n'aurez besoin que d'une partie de l'information affichée à l'écran suite à l'exécution d'une commande. Par exemple sur la commande suivante :
seb@thor:~$ cat /etc/os-release PRETTY_NAME="Debian GNU/Linux 9 (stretch)" NAME="Debian GNU/Linux" VERSION_ID="9" VERSION="9 (stretch)" ID=debian HOME_URL="https://www.debian.org/" SUPPORT_URL="https://www.debian.org/support" BUG_REPORT_URL="https://bugs.debian.org/"
Vous pourriez tout à fait souhaiter récupérer uniquement la ligne contenant le champ NAME pour simplement connaître la distribution que vous exploitez. Pour cela, vous allez utiliser la commande grep. Cette commande permet de filtrer le flux de données selon un motif (pattern en anglais) passé en paramètre.
Explorons maintenant les possibilités de la commande grep :
Pour les deux commandes suivantes, il existe une petite bataille de geeks entre :
les administrateurs pro commande
sed;et les administrateurs pro commande
awk.
Souvent les utilisateurs de sed s'appliqueront à tout faire avec cette commande. Ce qui est vrai également pour les utilisateurs de awk. De mon côté, je suis plutôt fervent de sed, mais awk me rend service assez souvent également !
Ces deux commandes sont très appréciées des administrateurs car elles permettent de réaliser des opérations sur les flux de données, fichiers, entrée et sortie de manière non interactive. Les deux s'appuyant sur les expressions régulières, qu'il est intéressant de rappeler ici.
Une expression régulière est la modélisation d'un motif dans un flux de données à l'aide de méta-caractères, c'est-à-dire de caractères particuliers auxquels on ajoute une expression ou un opérateur.
Parmi les méta-caractères les plus couramment utilisés on peut retrouver :
Méta- caractères | Fonctionnement |
| Le point remplace n'importe quel caractère (hors retour chariot), par exemple l'expression régulière suivante : |
| Le point d'interrogation indique que l'expression modélisée peut être présente 0 ou 1 fois. Par exemple, |
| L'étoile fonctionne comme le |
| Petit dernier de la famille, il permet de modéliser au moins une fois (1 ou n). |
| Nous l'avons vu précédemment en exemple, il permet de modéliser la première position, le début. |
| À l'inverse, ici, permet de modéliser la dernière position, la fin. |
| Les crochets, accompagnés souvent de Il est possible également d'utiliser le caractère |
La commande sed peut utiliser ces expressions régulières pour transformer un flux de données à la volée de manière non interactive (sed signifie Stream EDitor). Très pratique pour les traitements automatiques. On essaie ?
Ce langage et la commande associée sont très puissants. Je vous propose ici simplement de donner l'équivalent des fonctions énoncées pour sed :
Search/Replace :
seb@thor:~$awk '{gsub(/.ebian/,"Ubuntu")}1' /etc/os-releaseDelete :
seb@thor:~$ awk '!/.ebian/' /etc/os-release
Sous-partie :
seb@thor:~$ awk 'NR==2,NR==4' /etc/os-release
Enchaînez les commandes
Maintenant que vous maîtrisez les différents canaux de données, entrée et sortie standard et erreur, ainsi que les différentes commandes permettant de filtrer un flux selon un motif, il est temps de passer à la vitesse supérieure et d'utiliser toutes ces notions en même temps.
Ainsi il est possible d'écrire quelque chose comme :
commande options arguments | commande options arguments | commande options arguments | ...
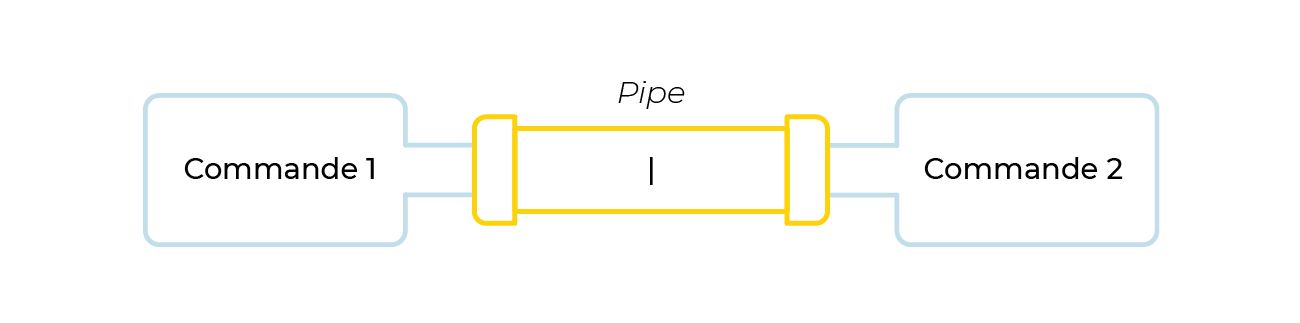
Je vous propose d’utiliser le pipe de Linux pour enchaîner les commandes que nous avons rencontrées. Pour cela nous allons travailler avec le fichier /etc/passwd et découvrir deux nouvelles commandes :sort et cut!
En résumé
Vous pouvez utiliser les commandes
catetlesspour visualiser le contenu des fichiersLe fichier
/etc/pam.d/loginpermet de gérer le processus d'authentification sous LinuxLes canaux Linux permettent de rediriger la sortie d'une commande vers un fichier
Le fichier
/var/log/messagescontient les traces du système LinuxLes commandes
grep,sedetawkpermettent de filtrer les flux de donnéesLe fichier
/etc/os-releasecontient les informations sur la distribution LinuxLe
pipede Linux permet de chaîner les commandes Linux grâce à la redirection des canauxLes commandes
sortetcutpermettent de manipuler des flux de données sous Linux
Dans le chapitre suivant, nous allons voir comment éditer et supprimer des fichiers, allez on y va !
