Préparez vos données

Découvrez les différents types de données non structurées
Dans une mairie comme Trifouillis-sur-Loire, les agents d’accueil comme Josiane doivent souvent traiter des données provenant de diverses sources : fichiers PDF pour des actes de mariage, scans de documents administratifs ou encore des e-mails demandant des subventions agricoles. Ces informations, bien que essentielles, sont dites non structurées, car elles ne suivent pas de format exploitable directement par des systèmes informatiques. Cela complique la recherche et le traitement rapide d'informations.
L'objectif de ce chapitre est de transformer ces données en un format exploitable : le texte structuré. Vous découvrirez comment structurer ces données pour les rendre exploitables, une étape essentielle pour créer un système RAG efficace. Prêt à transformer des données brutes en connaissances actionnables ?
Prenez en main les outils pour extraire des données non structurées
Les fichiers PDF sont une source fréquente de données dans les mairies (actes, délibérations, etc.).
Voici plusieurs méthodes pour extraire leur contenu :
# PyPDF2
!pip install PyPDF2 --quiet
import PyPDF2
# Ouvrir le fichier PDF en mode lecture binaire
with open(pdf_path, "rb") as pdf_file:
# Créer un lecteur PDF
pdf_reader = PyPDF2.PdfReader(pdf_file)
# Extraire le texte de chaque page
text = ""
for page_num in range(len(pdf_reader.pages)):
page = pdf_reader.pages[page_num]
text += page.extract_text()
# Afficher le texte extrait
print(text)PyPDF2, solution pure Python, permet des opérations classiques (fusion, découpage, extraction) mais peut rencontrer des difficultés pour restituer correctement la structure et le formatage sur des documents complexes.
# pymupdf4llm
!pip install pymupdf4llm --quiet
import pymupdf4llm
# Ouvrir le fichier PDF
md_text = pymupdf4llm.to_markdown(pdf_path)
print("=== Contenu Markdown extrait avec PyMuPDF4LLM ===")
print(md_text)PyMuPDF excelle dans l'extraction rapide et précise du texte, images et métadonnées, gérant ainsi de nombreux formats (PDF, XPS, EPUB, etc.) avec fidélité.
# markitdown
!pip install markitdown
from markitdown import MarkItDown
# Ouvrir le fichier PDF
md = MarkItDown()
result = md.convert(pdf_path)
print(result.text_content)Markitdown, quant à lui, convertit divers formats en Markdown pour faciliter le traitement textuel, au prix parfois d'une perte de mise en forme et de limites sur les PDF complexes.
Dans les mairies, de nombreux documents sont numérisés sous forme de PDF d'images (scans d'actes, délibérations, ou demandes administratives). Ces fichiers ne contiennent pas de texte directement exploitable. Pour en extraire le contenu textuel, on utilise la reconnaissance optique de caractères (OCR), une technologie qui permet de convertir des images en texte exploitable.
L bibliothèque Python EasyOCR offre une solution simple et efficace pour effectuer cette opération, adaptée aux besoins administratifs, comme la recherche de noms, de dates ou de montants dans des documents scannés.
Voici ce que cela donne en action :
# Easy OCR
!pip install easyocr --quiet
import easyocr
import os
# Initialiser EasyOCR
reader = easyocr.Reader(['fr'])
# 'fr' pour le français, ajoutez d'autres langues si nécessaire
# Extraire le texte de chaque image
full_text = ""
# Appliquer l'OCR sur l'image
results = reader.readtext(image_path)
# Formater les résultats
for (bbox, text, prob) in results:
full_text += text + "\n"
print(full_text)Après avoir exploré EasyOCR, il est pertinent de comparer cette bibliothèque à d'autres solutions OCR populaires telles que Tesseract OCR ou GOT OCR.
GOT OCR est un modèle de reconnaissance optique de caractères, conçu pour offrir une solution unifiée et de bout en bout pour l'extraction de texte. Il est capable de traiter divers types de documents, y compris des textes formatés et des documents multi-pages. GOT OCR est disponible en open source.
# GOT OCR
!pip install tiktoken --quiet
!pip install verovio --quiet
from transformers import AutoModel, AutoTokenizer
# Initialiser GOT OCR
tokenizer = AutoTokenizer.from_pretrained('ucaslcl/GOT-OCR2_0', trust_remote_code=True)
model = AutoModel.from_pretrained('ucaslcl/GOT-OCR2_0', trust_remote_code=True, low_cpu_mem_usage=True, device_map='cuda', use_safetensors=True, pad_token_id=tokenizer.eos_token_id)
# plain texts OCR
res = model.chat(tokenizer, image_path, ocr_type='ocr')
print(res)Maintenant que nous savons extraire les textes inclus dans les images, voyons comment convertir un fichier audio en texte.
Lorsque le maire présente ses vœux aux citoyens via la radio, il peut être utile de transcrire automatiquement le discours pour des besoins administratifs, de communication ou d'archivage. Grâce aux technologies de reconnaissance vocale (Speech-to-Text), il est possible d'extraire le contenu oral d'un audio ou d’une vidéo et de le convertir en texte exploitable.
Whisper est un système de reconnaissance automatique de la parole (ASR) conçu pour transcrire le langage parlé en texte écrit en utilisant des techniques d'apprentissage profond. Entraîné sur un vaste ensemble de données multilingues, il offre une précision et une robustesse accrues, notamment face aux accents variés, au bruit de fond et au langage technique.
# Whisper
!pip install -U openai-whisper --quiet
import whisper
# Transcrire avec Whisper
def transcribe_audio_with_whisper(audio_file, model_name="base"):
# Charger le modèle Whisper
model = whisper.load_model(model_name)
# Transcrire le fichier audio
result = model.transcribe(audio_file)
# Afficher la transcription
print("Transcription :")
print(result["text"])
# Transcrire l'audio avec Whisper
transcribe_audio_with_whisper(audio_path)Il est essentiel de noter que, bien que Whisper soit un outil puissant pour la transcription automatique, il est recommandé de toujours vérifier manuellement les transcriptions, surtout dans des contextes où la précision est cruciale.
Dans cette démonstration, nous avons exploré trois techniques essentielles pour extraire des données non structurées à partir de formats couramment utilisés dans les mairies :
Nous avons extrait le contenu textuel de documents PDF standards où le texte est directement accessible, comme des délibérations ou des actes.
Pour les PDF contenant des scans ou des images, nous avons utilisé la reconnaissance optique de caractères (OCR) afin de convertir les images en texte exploitable, utile pour des documents numérisés comme des demandes administratives ou des registres scannés.
Nous avons transcrit automatiquement une vidéo dans laquelle le maire présente ses vœux aux citoyens en texte. Cette technique permet d'archiver et d'utiliser efficacement les discours vidéo.
Gérez le cycle de vie des données
La gestion du cycle de vie des données est un processus fondamental pour offrir des services performants.
Dans le cadre de la mise en place de notre système RAG, il est essentiel d'accompagner la mairie de Trifouillis-sur-Loire dans la gestion du cycle de vie de ses données. Une gestion optimale des données est cruciale pour garantir la qualité des services municipaux et assurer la conformité aux réglementations en vigueur, notamment le Règlement Général sur la Protection des Données (RGPD).
Analysons ensemble les étapes clés de la vie de nos données :
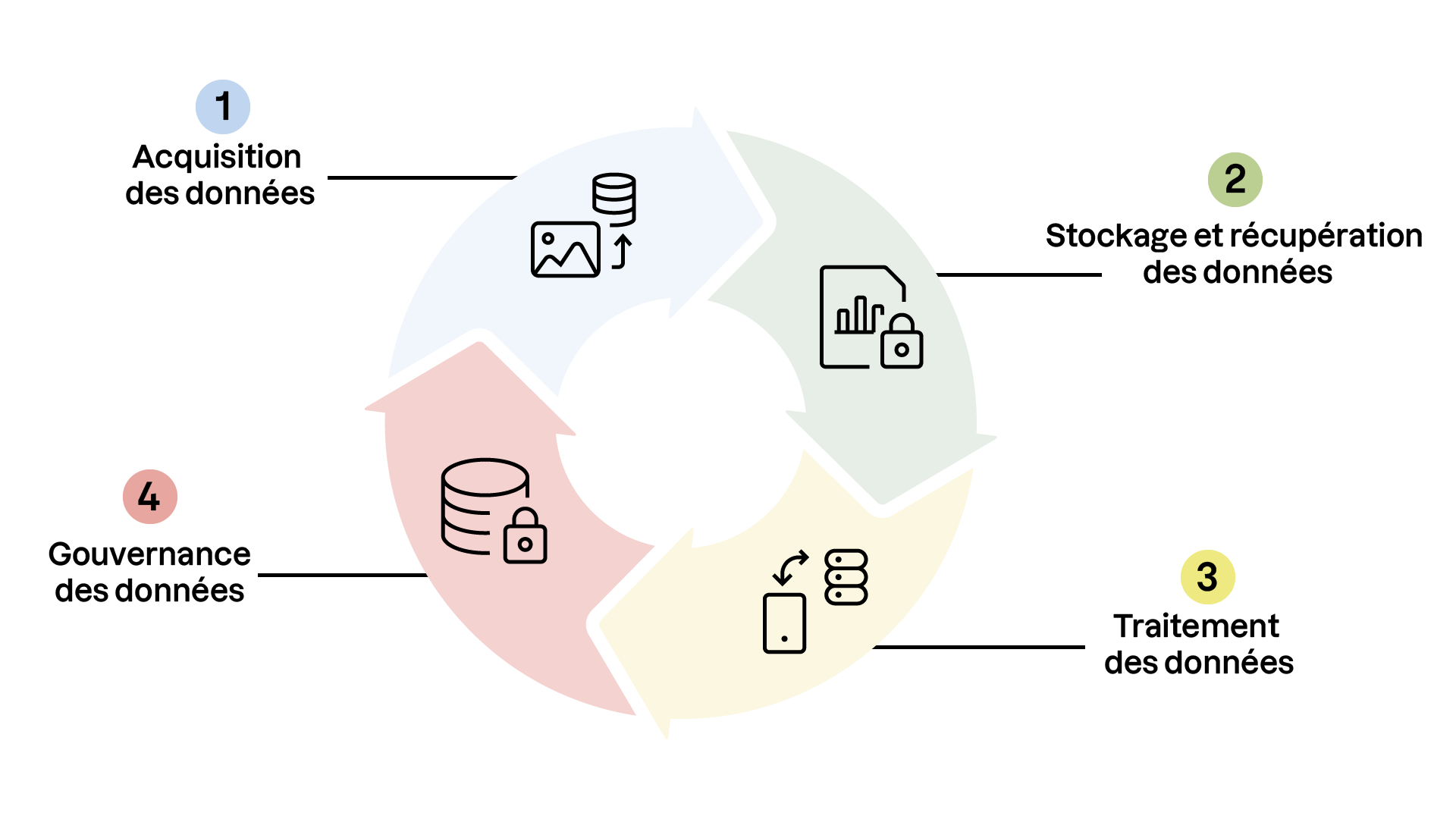
1. Acquisition des données
Objectif : Collecter des données pertinentes et de qualité.
L'acquisition des données est la première phase du cycle de vie et la base de toute gestion efficace. L'objectif est de recueillir des informations utiles, en respectant les besoins des citoyens et des services municipaux. Cette collecte peut se faire de manière directe, comme via des formulaires en ligne, ou à travers d'autres canaux numériques ou physiques.
Lors de l'organisation du marché de Noël, la mairie de Trifouillis-sur-Loire a besoin de connaître les commerçants locaux intéressés par l’événement. Pour ce faire, un formulaire en ligne est mis en place, dans lequel les commerçants remplissent leurs informations (nom, type de commerce, dimensions de l’espace nécessaire). Ces données sont ensuite collectées de manière structurée, permettant une gestion efficace des inscriptions.
2. Stockage et récupération des données
Objectif : Gérer efficacement le stockage des données et optimiser la récupération pour des recherches rapides.
Une fois les données collectées, elles doivent être stockées de manière optimale pour pouvoir être utilisées facilement et rapidement. Le choix du système de stockage dépend des besoins spécifiques des données : bases de données relationnelles, bases de données NoSQL, ou bases de données vectorielles.
Bases de données relationnelles : Si les données sont structurées et nécessitent des relations complexes, comme les inscriptions aux événements ou les demandes de subventions, une base de données relationnelle (SQL) peut être utilisée pour gérer les informations.
Bases de données NoSQL : Conçues pour des données moins structurées ou des volumes massifs, elles s'adaptent à des scénarios variés comme le stockage de documents, de données en temps réel ou de contenus hiérarchiques, avec une grande flexibilité et scalabilité.
Bases de données vectorielles : Pour des données plus complexes, comme des informations textuelles ou multimédias, les bases de données vectorielles, qui permettent des recherches et des analyses sémantiques rapides, sont adaptées.
Les inscriptions pour le marché de Noël sont stockées dans une base de données relationnelle avec des informations sur chaque commerçant. La mairie doit pouvoir accéder rapidement à cette base pour planifier les emplacements, vérifier les demandes et envoyer des notifications, ce qui nécessite une gestion efficace de la récupération des données.
3. Traitement des données
Objectif : Préparer et traiter les données pour les rendre prêtes à l’utilisation dans des systèmes décisionnels et de recherche.
Le traitement des données est une étape clé qui permet de transformer les données brutes en informations utilisables. Cela inclut des processus comme le nettoyage, la conversion des formats de données, et l’enrichissement des données. Pour garantir que les données soient prêtes à l’emploi, il faut aussi s'assurer qu’elles respectent les formats et structures attendus par les applications et les utilisateurs.
Nettoyage des données : Cela inclut la suppression des doublons, la correction des erreurs typographiques, et l'alignement des formats de données.
Conversion et Enrichissement (Embedding) : Parfois, les données doivent être transformées ou enrichies pour des analyses spécifiques, par exemple, la transformation d’une donnée textuelle en un vecteur d'embedding pour une recherche sémantique.
Optimisation du pipeline de traitement : Il est crucial de disposer d’un pipeline de traitement de données bien défini, permettant une gestion fluide et rapide des informations, tout en minimisant les risques d'erreurs.
Avant de planifier les emplacements pour le marché de Noël, la mairie doit vérifier la cohérence des informations de chaque commerçant (par exemple, la taille de l'espace requis). Ensuite, ces données peuvent être transformées en un format vectoriel pour faciliter les recherches sur des critères comme la catégorie de commerce ou les préférences d’emplacement.
4. Gouvernance des données
Objectif : Garantir la confidentialité, la sécurité et la conformité réglementaire des données.
La gouvernance des données est essentielle pour assurer la confiance des citoyens et se conformer aux réglementations en vigueur. Cela inclut la mise en place de politiques de sécurité, de confidentialité et de conformité aux lois sur la protection des données, telles que le RGPD.
Confidentialité et Sécurité : Les données sensibles, comme les informations personnelles des citoyens ou des commerçants, doivent être protégées contre toute forme de fuite ou de perte. Cela peut inclure des techniques comme le chiffrement des données et l'authentification renforcée pour l’accès aux données.
Conformité réglementaire : La mairie doit s'assurer que les processus de collecte, de stockage, et de traitement respectent les exigences légales, notamment en matière de conservation des données et des droits des utilisateurs.
Politique de gouvernance des données : Un cadre de gouvernance des données doit être mis en place, incluant des rôles et responsabilités clairs pour la gestion des données, ainsi que des audits réguliers pour vérifier la conformité et la sécurité.
Lors de la collecte des informations des commerçants pour le marché de Noël, la mairie doit garantir que les données personnelles des commerçants sont stockées de manière sécurisée, qu’elles ne sont utilisées que pour des fins administratives liées à l’événement, et qu’elles ne sont conservées que pour la durée légale autorisée.
Pour une mairie comme Trifouillis-sur-Loire, bien gérer le cycle de vie des données, de leur collecte à leur utilisation, c'est garantir des services efficaces, modernes et respectueux des citoyens. Chaque étape, bien pensée, renforce la confiance et simplifie la vie quotidienne. Passons maintenant à la mise en pratique !
À vous de jouer

Contexte
Vous êtes chargé d'analyser un ensemble de documents municipaux numérisés, regroupés dans une archive contenant divers formats tels que PDF, Word, Excel et images.
Consignes
1. Installation de Docling : Assurez-vous d'avoir Python installé sur votre système. Installez Docling en exécutant la commande suivante dans votre terminal :
pip install docling2. Extraction de l'archive ZIP :
Décompressez l'archive ZIP contenant les documents dans un répertoire de votre choix.
3. Conversion des documents :
Écrivez un script Python pour convertir tous les documents du répertoire extrait en fichiers Markdown.
Le script doit parcourir chaque fichier du répertoire, détermine son format et effectue la conversion appropriée en utilisant Docling.
En résumé
Pour permettre une analyse efficace et une utilisation optimale dans les systèmes de Récupération et Génération (RAG), il est essentiel de transformer les données non structurées (PDF, documents scannés, e-mails, images, audio, vidéo) en texte structuré.
L’utilisation d’outils open source permet d’extraire du texte, d’effectuer une reconnaissance optique de caractères (OCR) sur des documents au format image, et de transcrire des fichiers audio en texte, garantissant ainsi une couverture exhaustive des différentes sources de données.
Le cycle de vie des données inclut l’acquisition, le stockage optimisé, le prétraitement et la gouvernance des données. Cela garantit leur qualité, leur sécurité et leur conformité aux exigences des systèmes RAG.
Les approches simples, souvent plus faciles à mettre en œuvre, à maintenir et à comprendre, s’avèrent particulièrement adaptées aux environnements à ressources limitées.
Maintenant que nous savons extraire et gérer le cycle de vie de nos données, passons à la vectorisation de nos données dans le chapitre suivant.
