Mettez en place un tracking collaboratif avec MLflow
Nous avons vu FastAPI pour simplifier l’utilisation d’un modèle ML par un utilisateur métier. De plus, nous avons parlé de Docker et la CI/CD pour packager le projet ML et automatiser ses livraisons en production, tout en minimisant le risque de bugs et en maximisant la reproductibilité des résultats par votre équipe.
Tout ceci est considérablement utile pour déployer un nouveau modèle, quand on a décidé que celui-ci était prêt au déploiement. Mais pour arriver justement à cette décision, la boîte à outils que nous avons vue à date n’est pas la plus pratique. C’est ici que le package MLflow tire son épingle du jeu. Il s’agit de l’outil incontournable pour comparer des modèles, les monitorer, mais également travailler en équipe !
Prêts ? Allons-y !
Comment gérer tous mes projets ML packagés ?
Avant de pousser votre nouveau modèle robuste dans votre branche pour créer une pull request (et donc, avant d’activer la CI puis la CD), il a été nécessaire de tester plusieurs modèles, de les benchmarker et de les passer au crible.
Dans le chapitre sur MLflow cité plus haut, vous voyez en pratique comment stocker des modèles et d’autres éléments connexes (métriques, données etc.) dans des runs et des experiments, très pratiques justement pour comparer les différents modèles ML entrainés. Ces runs et experiments sont stockés dans un dossier mlruns, créé et géré automatiquement par MLflow.
Maintenant, supposons que vous avez shortlisté un modèle. Avant de vous précipiter à pousser votre code dans Git et créer une pull request, une bonne pratique à adopter consiste à Dockeriser votre projet et de faire tourner le conteneur chez vous, en local. C’est en effet une façon d'approcher l’environnement de prod pour s’assurer que le code est vraiment propre.
Quel rapport avec MLflow ?
Eh bien, commençons par regarder de nouveau le Dockerfile que nous avons vu il y a 3 chapitres.
# ------------------- Base Image + Global Configs -------------
FROM ghcr.io/astral-sh/uv:python3.12-bookworm-slim
WORKDIR /app
ARG POSTGRES_HOST
ARG POSTGRES_PORT
ARG POSTGRES_DB
ARG POSTGRES_USER
ARG POSTGRES_PASSWORD
ENV POSTGRES_HOST=$POSTGRES_HOST
ENV POSTGRES_PORT=$POSTGRES_PORT
ENV POSTGRES_DB=$POSTGRES_DB
ENV POSTGRES_USER=$POSTGRES_USER
ENV POSTGRES_PASSWORD=$POSTGRES_PASSWORD
ENV MLFLOW_TRACKING_URI=/app/mlruns
# --------------------- UV Configs -------------------------
ENV UV_COMPILE_BYTECODE=1
ENV UV_LINK_MODE=copy
ENV UV_HTTP_TIMEOUT=1000
# --------------------- Main Steps ---------------------
COPY pyproject.toml uv.lock /app/
RUN --mount=type=cache,target=/root/.cache/uv \
uv sync --locked --no-dev
COPY . /app
ENV PATH="/app/.venv/bin:$PATH"
EXPOSE 8000
CMD ["uvicorn", "p1_c4_orm:app", "--host", "0.0.0.0", "--port", "8000"]Où est le problème ? Eh bien c’est très simple ! C’est au niveau de la définition du MLFLOW_TRACKING_URI et du COPY . /app !
Normalement, votre dossier mlruns continent TOUTES vos tentatives de modélisations, qu’elles soient pertinentes ou pas. Il était bien évidemment nécessaire de tester plusieurs modèles avant d’arriver à celui que vous souhaitez déployer. Mais une fois ce modèle sécurisé, les autres ne servent plus pour le déploiement.
Or, le problème ici est que la commande COPY va rajouter dans l’image Docker absolument TOUTES ces modélisations et rendre votre image inutilement lourde à build, à stocker et à run.
Il suffirait alors que je rajoute le dossier mlruns dans le fichier .dockerignore non ?
Cela nous mènera à une autre impasse, car notre modèle API-sé est chargé grâce à MLflow depuis le dossier mlruns ! Avec ce fonctionnement actuel, si l’on se débarrasse du dossier, on se débarrasse de tous les modèles.
Mais pour que mes collègues bénéficient puissent accéder à toutes mes tentatives de modélisations, il faut que mon dossier mlruns soit partagé avec les autres à un moment donné. Il faut pousser ce dossier dans le repo Git ?
Eh bien non, et ce pour la même raison qui nous décourage de pousser toutes nos images Docker dans Git !
Regardons ensemble comment sortir de cette situation dans les sections qui suivent !
Du localhost au remote tracking server
Dans le chapitre sur Docker, on a évoqué qu’il était techniquement possible de stocker toutes les images Docker dans Git, mais qu’il s’agissait d’une mauvaise pratique et que le Container Registry est une solution plus adaptée. C’est exactement la même chose pour les modèles ML et plus généralement le dossier mlruns en local il nous faut comme un espèce de Model Registry collaboratif, conçu spécifiquement pour les modèles.
Ça tombe bien, MLflow propose exactement cela, un Model Registry hébergé à distance pour versionner et transférer des modèles vers d’autres systèmes ! Pour ce faire, MLflow permet de mettre en place un Remote Tracking Server. La documentation de MLflow schématise son fonctionnement à merveille :
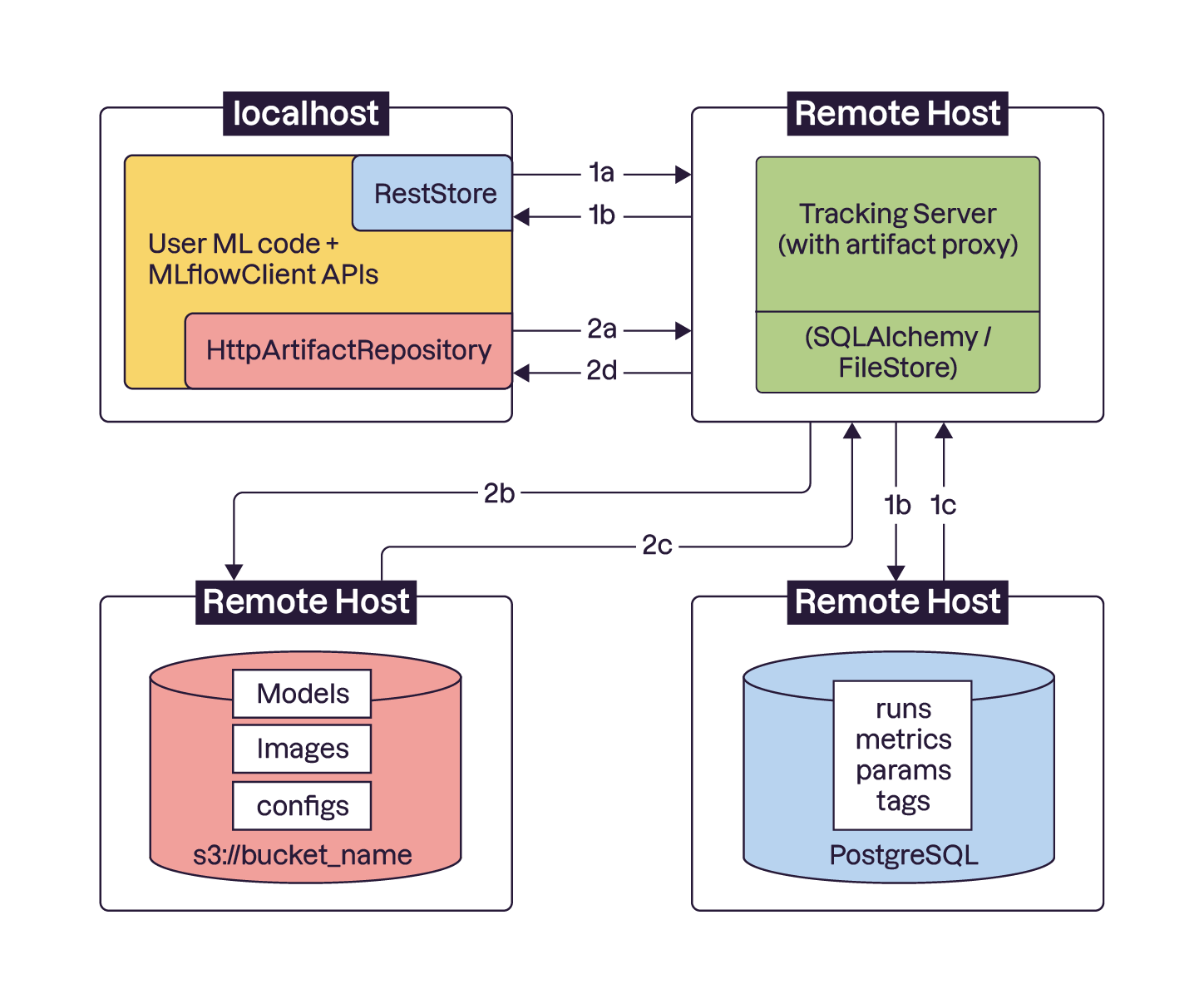
Comme le nom l’indique, tous les éléments de la boîte “localhost” sont stockés localement, autrement dit, dans votre PC ou dans un conteneur qui tournera en prod dans la compute instance. Ensuite, nous avons 3 systèmes à distance. Si vous combinez les éléments de ces 3 systèmes et que vous les stockez en local chez vous, vous allez reconstruire tout le contenu du dossier mlruns. En revanche, nous allons voir qu’il est pratique d’éclater le fichier mlruns en 3 systèmes différents si nous voulons avoir un fonctionnement à distance.
Commençons par le plus simple, celui en rouge en bas à gauche : On y voit les modèles, images etc. Tout ce qu’on appelle dans le langage MLflow des artifacts. Ce sont des données non structurées, c’est-à-dire, des fichiers qu’on ne peut pas ouvrir avec Excel, ou avec SQL. Ce sont également des fichiers volumineux. Pour ces deux raisons, nous avons besoin d’une méthode de stockage adaptée.
Avec un comportement diamétralement opposé, la boîte en bleu en bas à droite ne contient que de la donnée structurée et extrêmement légère : des métriques, des IDs, des tags… Globalement, des chaînes de caractères et des chiffres. C’est le domaine où SQL excelle en termes de vitesse de stockage, de lecture et d’écriture et c’est exactement pour cette raison là que ces éléments sont gérés séparément des modèles et des autres artefacts volumineux et non structurés.
Pour comprendre la boîte verte (le Remote Tracking Server) en haut à droite, intéressons-nous aux blocs bleus et rouges de la boîte localhost. Ce sont des interfaces qui font des appels API à la boîte verte, qui en retour va interpréter la demande pour déterminer s’il faut renvoyer des infos stockées dans la boîte bleue, ou dans la boîte rouge, ou dans les deux. Le Remote Tracking Server est tout simplement un intermédiaire avec lequel le localhost communique par API.
Résumons avec deux exemples :
Votre collègue veut interroger MLflow et connaître quel modèle a le meilleur score RMSE ? La requête ne demande pas de charger le modèle, mais simplement de faire un tri parmi les métriques des modèles versionnés. Sous le capot, le localhost va faire un appel API au Tracking Server pour interroger en SQL la BDD de la boîte bleue et récupérer l’info voulue.
Votre collègue veut charger le modèle le plus récemment entraîné, indépendamment des métriques de performances. Sous le capot, il s’agit d’un appel API au Tracking Server pour charger des artefacts stockés et versionnés dans la boîte rouge.
Demo d’un remote tracking server
Pour répondre enfin à la question : vous n’allez jamais pousser vos modèles dans Git. Par contre, avec votre code Python (qui lui-même est bien sûr dans Git), vous allez pouvoir écrire vos runs et vos expérimentations dans des systèmes de stockage à distance, accessible à vous et vos collègues via des appels API gérés par MLflow.
Comme expliqué plusieurs fois au fil du cours, les équipes Data travaillent souvent dans un contexte Cloud chez Azure, GCP ou AWS. Ces Cloud Providers proposent justement des services qui, entre autres, intègrent MLflow facilement à leur système de stockage natif et à leur Container Registry.
Par exemple, Azure propose Azure Machine Learning qui s’intègre très bien avec le système de stockage d’Azure nommé Blob et le Container Registry nommé ACR (Azure Container Registry). C’est la même chose pour AWS avec le trio SageMaker, S3 et ECR qu’on a déjà vu, ainsi que pour GCP avec le trio Vertex AI, Google Storage et Google Artefact Registry
Nous allons désormais regarder tout cela en action, toujours dans un contexte AWS.
Le screencast se base sur une configuration des services AWS faite au préalable en suivant ce tutoriel : MLflow on AWS: A Step-by-Step Setup Guide.
Synthèse : Le process pour remplacer un modèle
Nous venons tout juste de regarder ensemble le dernier screecast de cours ! Il est désormais temps de synthétiser tout notre apprentissage en mettant en musique tous les concepts que nous avons appris.
Comment déployons-nous un modèle alors ?
Déjà on crée une nouvelle branche Git et on commence à faire tout notre travail de Data Science pour construire le modèle et éventuellement l’API-ser ! On s’assure que le modèle est robuste (MLflow peut bien nous aider) et que le code est fonctionnel en local chez nous. Pour cette dernière partie, les tests unitaires sont alors très utiles
Ensuite, nous Dockerisons le projet en et nous faisons tourner l’image buildé en local pour vérifier que le code fonctionne correctement. Si ce n’est pas le cas, c’est qu’il manque des éléments dans notre Dockerfile (la recette de cuisine de l’image Docker) et qu’il faut le compléter.
Tout va bien ? On pousse notre branche dans le repo pour créer un pull request ! Cela active la CI codée au préalable dans un fichier YAML. Si la pipeline échoue, nous devons appliquer des correctifs. Sinon, on peut demander à un collègue de valider la pull request.
La pull request est validée ? On peut merge notre branche avec la branche de preprod ! Cela va activer la CD. Si la pipeline échoue, nous devons appliquer des correctifs. Sinon, nous pouvons vérifier que notre nouvelle image Docker est bel et bien dans le Container Registry !
Enfin, nous lançons un compute instance (souvent dans le Cloud) qui va héberger et faire tourner le container. Celui-ci contient notre modèle, que je peux requêter par API, soit via mon terminal, un script Python, ou une interface web (construite avec Streamlit par exemple).
Si vous comprenez techniquement ce qui se passe sous le capot de chaque bullet point, eh bien félicitations, vous avez acquis les bases du Machine Learning Engineering ! Le reste de votre apprentissage se fera sur le tas, à force de déployer des modèles et de croiser des situations plus complexes que celles décrites dans ce cours.
Vous me parlez comme si le cours était fini, mais il reste encore un chapitre ?
C’est vrai. Cependant, il ne s’agit que d’un chapitre d’ouverture à d’autres problématiques du ML Engineering. Il ne sera pas du tout hands-on, mais il aborde en surface des concepts dont vous allez CERTAINEMENT au moins entendre parler, si ce n’est implémenter dans votre carrière !
En résumé
Utilisez MLflow pour tracer, comparer et versionner tous vos modèles ML, localement et à distance.
Évitez de copier le dossier
mlrunsdans votre image Docker ou dans Git : passez par un Remote Tracking Server.Stockez séparément les artefacts lourds (modèles, images) et les métadonnées légères (métriques, tags) pour optimiser le suivi.
Connectez MLflow à des services Cloud (Azure, AWS, GCP) pour centraliser les modèles et faciliter leur déploiement.
Maîtrisez la chaîne complète : création, validation, dockerisation, CI/CD, déploiement et monitoring du modèle ML.
Maintenant que vous maîtrisez toutes les briques opérationnelles du ML Engineering, passons au dernier chapitre pour découvrir les enjeux d’orchestration et les outils comme Airflow !
