Préparez des données temporelles fiables avec Pandas
Dans un contexte professionnel, vous recevrez rarement des données “prêtes à l’emploi”. Elles arrivent souvent :
depuis plusieurs sources (donc des formats différents),
avec des dates incohérentes (jour/mois inversés, séparateurs variés, timezone),
avec des trous (jours manquants),
et parfois avec des doublons (deux lignes pour la même date).
Le problème, c’est que les séries temporelles sont très sensibles à ces défauts :
un doublon peut gonfler artificiellement un total hebdomadaire,
une date mal parsée devient
NaNet fait disparaître une ligne au tri,un trou dans les dates peut casser un calcul de moyenne mobile ou tromper un modèle,
et une “fuite temporelle” (data leakage) peut donner l’illusion d’un modèle excellent… jusqu’au jour où il échoue en production.
Votre mission est donc simple à formuler : partir de données brutes et obtenir une série continue, dédupliquée, alignée sur une fréquence, et exploitable (features OK, pas de fuite).
Avant toute modélisation, vous devez pouvoir répondre “oui” à ces questions :
Est-ce que toutes mes dates sont converties correctement ?
Ai-je une seule valeur par date (ou une règle explicite si plusieurs) ?
Ma série est-elle continue sur la fréquence choisie (jour, semaine, etc.) ?
Est-ce que mes variables (lags, moyennes mobiles…) n’utilisent jamais le futur ?
Vous vous demandez peut-être :
“OK, mais pourquoi être aussi strict ?”
Parce qu’en entreprise, une série temporelle sert souvent à déclencher des décisions (stocks, effectifs, alerte sanitaire, budget). Une erreur de date, c’est parfois une mauvaise décision au mauvais moment.
Imaginez un tableau de bord “consultations grippe” affiché chaque lundi. Si une source du dimanche arrive en double, votre courbe hebdomadaire grimpe sans raison : l’équipe panique, renforce les effectifs… pour rien. Le nettoyage, c’est aussi de la fiabilité opérationnelle.
Si maintenant l’enjeu du nettoyage des données est clair, on peut avancer : commençons par le point le plus critique, autrement dit convertir les dates et créer un index temporel solide.
Convertissez les dates en un format exploitable
Nous allons utiliser un jeu de données qui concernent le nombre de consultations par jour pour la grippe (Influenza-like illness ou ili).
Commençons par charger les données et vérifier la structure des colonnes :
import pandas as pd
import plotly.express as px
df = pd.read_csv("epidemioscope_raw_daily.csv")
display(df.head())
display(df.dtypes)Appliquons des vérifications minimales :
La colonne de date (
date_raw) est bien présente,La variable cible (
ili_consultations) est aussi bien présente,On détecte des valeurs manquantes évidentes.
Corrigez le format de vos dates et définissez votre index temporel
Convertissez la date en `datetime` robuste, puis fixez-la comme index.
df["date"] = pd.to_datetime(df["date_raw"], dayfirst=True, errors="coerce")
print("Dates invalides :", df["date"].isna().sum())
display(df.loc[df["date"].isna()].head(10))Dates invalides : 3004
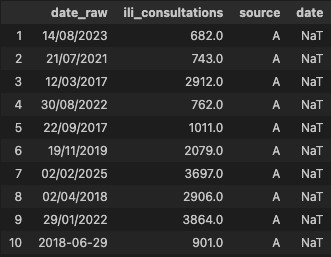
Nous pouvons voir que certaines dates sont en format dd/mm/yyyy et yyyy-mm-dd. Ces dates n'ont pas été transformées, nous allons donc y remédier. L'objectif est d'appliquer une conversion “multi-formats” de manière explicite, pour éviter les surprises.
s = df["date_raw"].astype(str).str.strip()
df["date"] = pd.to_datetime(s, format="%Y-%m-%d", errors="coerce")
m = df["date"].isna()
df.loc[m, "date"] = pd.to_datetime(s[m], format="%d/%m/%Y", errors="coerce")Vérifions le travail :
print("Dates invalides :", df["date"].isna().sum())
display(df.loc[df["date"].isna()].head(20))Dates invalides : 161
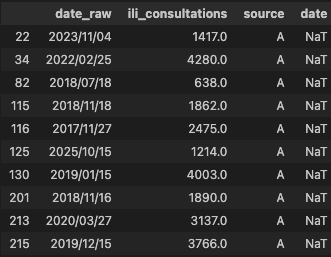
Il reste encore les dates au format yyyy/mm/dd
m = df["date"].isna()
df.loc[m, "date"] = pd.to_datetime(s[m], format="%Y/%m/%d", errors="coerce")
print("Dates invalides :", df["date"].isna().sum())
display(df.loc[df["date"].isna()].head(20))Dates invalides : 0

Le format de toutes les dates est enfin corrigé nous allons pouvoir créer un index temporel.
df = df.dropna(subset=["date"]).sort_values("date").set_index("date")
display(df)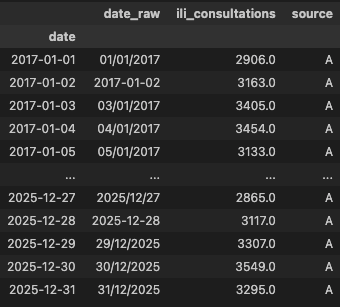
Une fois l’axe du temps est fiable, on vérifie qu’on n’a pas plusieurs lignes pour la même date.
Gérez vos doublons
Une date doit correspondre à une seule ligne. Si des doublons existent, appliquez une règle explicite. Affichez d'abord les dates dupliquées et leurs valeurs :
dup_mask = df.index.normalize().duplicated(keep=False)
doublons = df.loc[dup_mask].sort_index()
display(doublons[["ili_consultations", "source"]])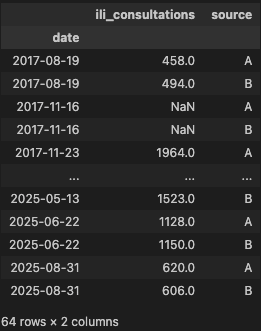
Nous pouvons observer que sur une même date le nombre de consultations varie en fonction de la source. Plusieurs règles peuvent être appliquées en fonction des cas :
La moyenne des valeurs
Le maximum des deux valeurs
Le minimum des deux valeurs
La valeur d’une des deux sources
En pratique, votre choix dépend d’une question métier : “est-ce que les sources mesurent la même chose, ou des choses complémentaires ?”. Si elles sont censées mesurer le même indicateur, la moyenne est souvent une option raisonnable (mais vous devez la documenter).
Nous allons décider arbitrairement de prendre la moyenne :
serie_daily = df["ili_consultations"].groupby(level=0).mean().sort_index()
print("Nb dates uniques:", serie_daily.index.nunique())
display(serie_daily)Même avec des dates uniques, il peut manquer des jours. On va rendre la série continue.
Changez la fréquence de vos données avec le resampling
Choisir une stratégie pour les jours manquants
Une fois l’index temporel créé et les doublons traités, il reste encore la bête noire de la data : les valeurs manquantes.
serie_daily = serie_daily.asfreq("D")
jours_manquants = int(serie_daily.isna().sum())
print("Jours manquants:", jours_manquants)Dans notre cas 58 valeurs manquantes sont présentes dans le dataset. Les supprimer viendrait faire des “trous” dans notre dataset, ce que l’on veut éviter en séries temporelles. Nous allons utiliser une méthode appelée l’interpolation* pour “deviner” les valeurs manquantes.
serie_daily = serie_daily.interpolate(method="time")
display(serie_daily)L’interpolation “time” suppose que la valeur évolue de façon progressive dans le temps. C’est souvent acceptable pour un signal “assez lisse”, mais risqué en cas de ruptures brusques (ex. pics épidémiques très courts). En entreprise, notez toujours la méthode choisie dans votre documentation ou votre notebook.
✅ Quand c’est pertinent | ⚠️ Quand c’est risqué |
Signal plutôt continu et “lisse” (ex. température, fréquentation, capteurs, indicateurs déjà lissés). | Signal avec pics brusques ou ruptures (ex. pannes, promotions, épidémies, événements exceptionnels). |
Notez toujours quelle méthode d’interpolation vous avez utilisée (et pourquoi), car elle influence directement les analyses et les modèles.
Appliquez la méthode du resampling
Dans notre cas, je veux changer la fréquence en semaine (”W”) et je choisis dimanche comme jour d’ancrage (”SUN”) :
serie_weekly = serie_daily.resample("W-SUN").sum()
Les données sont sommées du lundi au dimanche, et la valeur est ancrée le dimanche. D’autres options sont possibles dans la documentation du resample.
Comparons graphiquement l’impact de notre resampling :
fig_daily = px.line(
x=serie_daily.index,
y=serie_daily.values,
labels={"x": "Date", "y": "Consultations"},
title="Série journalière après interpolation"
)
fig_weekly = px.line(
x=serie_weekly.index,
y=serie_weekly.values,
labels={"x": "Date", "y": "Consultations"},
title="Série Hebdomadaire après resampling"
)
fig_daily.show()
fig_weekly.show()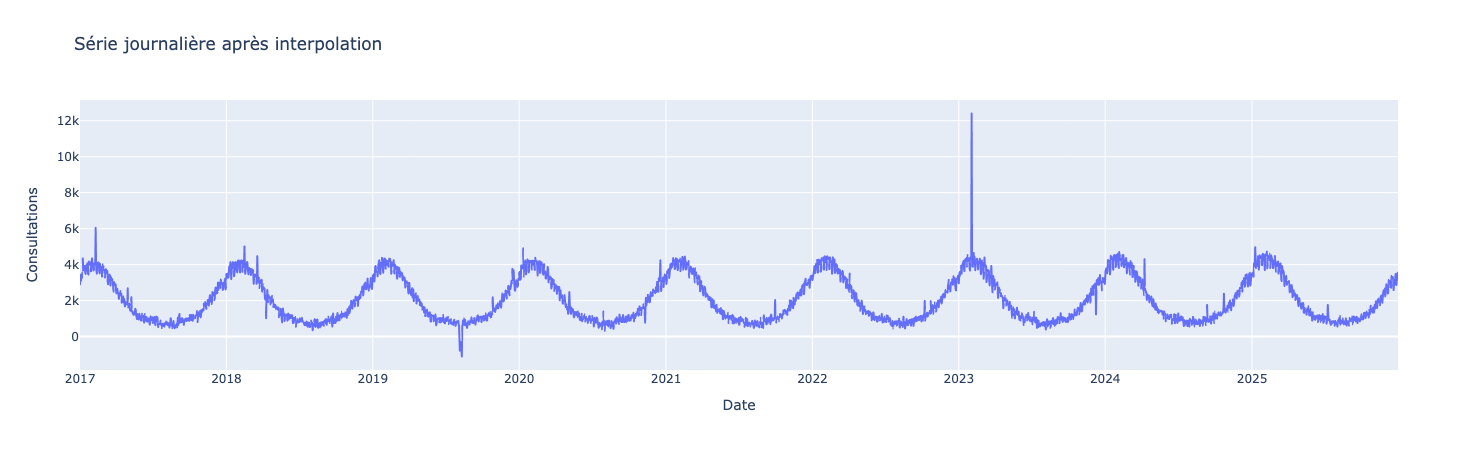
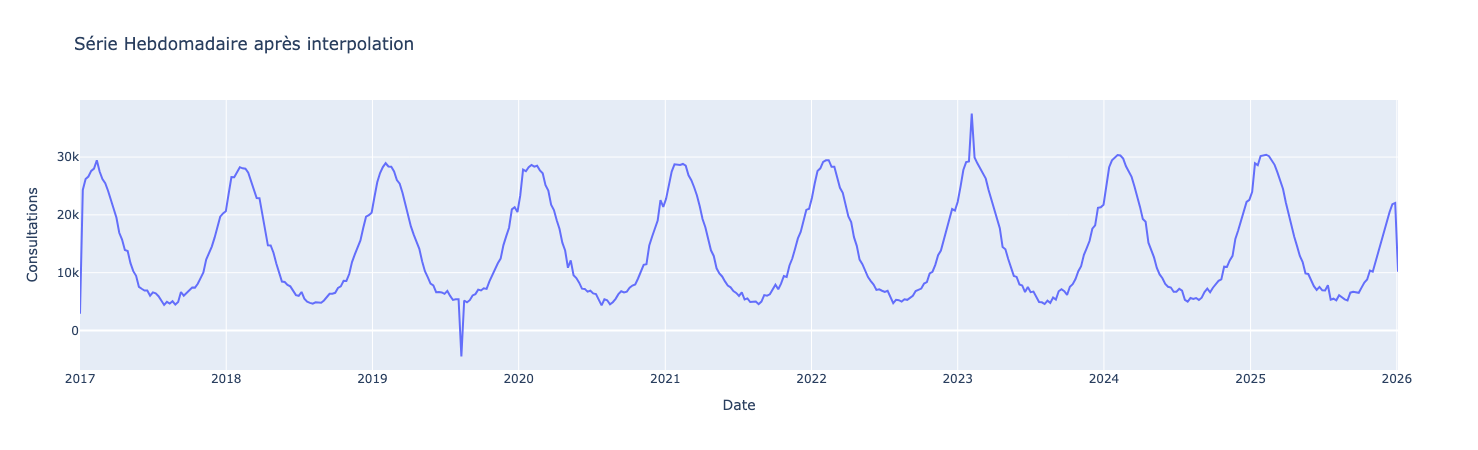
Observez comment les variations locales diminuent
Vous pouvez jouer en utilisant du resampling sur le mois, le trimestre, le semestre ou bien encore l’année pour observer visuellement l’impact de ces changements.
Une fois la fréquence fixée, on peut fabriquer des variables temporelles simples pour enrichir vos analyses et vos modèles.
Créez des variables temporelles simples
Fabriquez des lags pour comparer facilement des périodes entre elles
Les lags ajoutent de la mémoire et facilitent la comparaison semaine à semaine. Imaginez répondre en direct à la question, combien j'ai eu de consultations la semaine dernière ? La même semaine mais l'année dernière ?
Pour se faire on créé des colonnes en plus et on récupère les valeurs avec la fonction shift .
features_weekly = pd.DataFrame({"y": serie_weekly})
features_weekly["lag_4w"] = features_weekly["y"].shift(4)
# Avec 52 semaines dans l'année, 4 mois équivaut à 17 semaines
features_weekly["lag_4m"] = features_weekly["y"].shift(17)
display(features_weekly.head())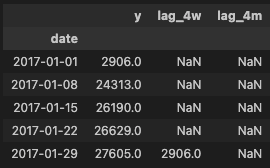
D’un coup d’œil pour une date donnée, nous pouvons la comparer à la valeur de la série il y a 4 semaines ou 4 mois.
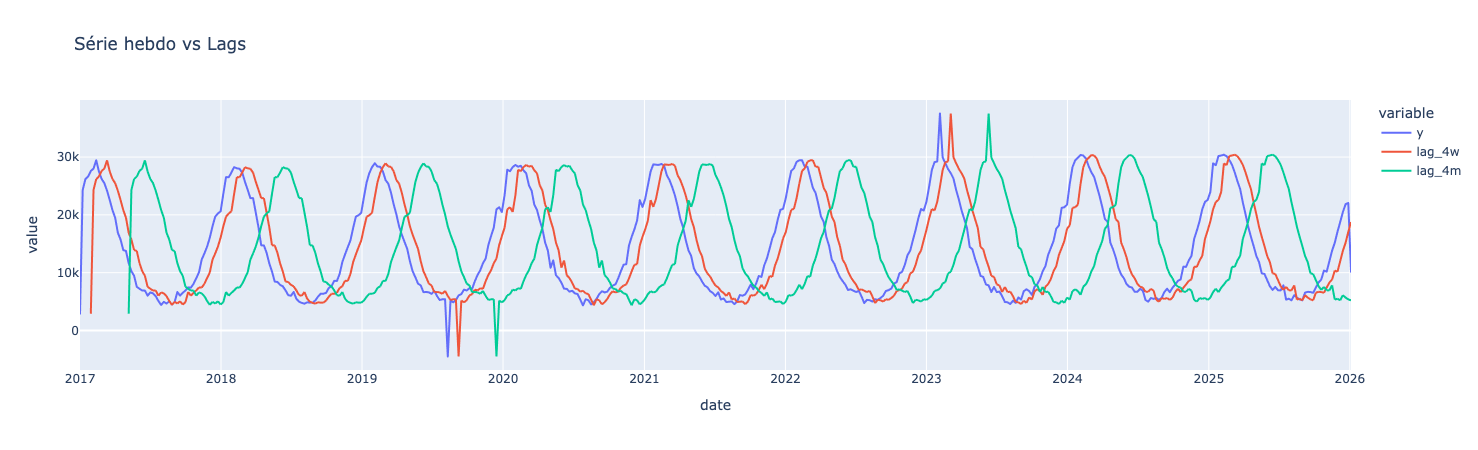
Question de réflexion : dans votre cas métier, quel lag est le plus logique ? 1 semaine (effet “court terme”) ? 52 semaines (saisonnalité annuelle) ?
Calculez les moyennes mobiles pour lisser les variations et évaluer les tendances
L'objectif principal d'une moyenne mobile est d'identifier les tendances en réduisant le bruit. Techniquement les moyennes mobiles se ressemblent fortement avec le resampling.
Voici les étapes de construction d’une moyenne mobile :
Choix de la période moyenne —> Par exemple 4 périodes (4 semaines, 4 jours, 4 mois), la période correspond à votre index temporel
Récupération de la valeur d’un point de données et des 3 périodes précédentes
Calcul de la moyenne sur ces 4 valeurs
Prenons un exemple dans notre cas :
features_daily = pd.DataFrame({"y": serie_daily})
features_daily["ma_4d"] = features_daily["y"].rolling(window=4).mean()
features_daily["ma_12d"] = features_daily["y"].rolling(window=12).mean()
display(features_daily[["y","ma_4d"]].head(4))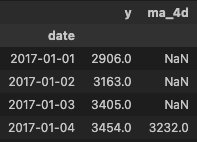
Question : Comment retrouver la valeur de 3232 correspondant à la valeur de la moyenne mobile sur 4 jours en date du 04/01/2017 ?
display(features_daily[["y","ma_12d"]].head(12))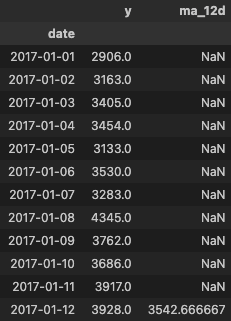
Question : Comment retrouver la valeur de 3542 correspondant à la valeur de la moyenne mobile sur 12 jours en date du 12/01/2017 ?
Vous pouvez observer visuellement une moyenne mobile :
df_plot = features_daily.reset_index()
fig = px.line(
df_plot,
x=df_plot.columns[0],
y=["y", "ma_4d", "ma_12d"],
title="Signal vs Moyennes mobiles"
)
fig.update_layout(width=None)
fig.show()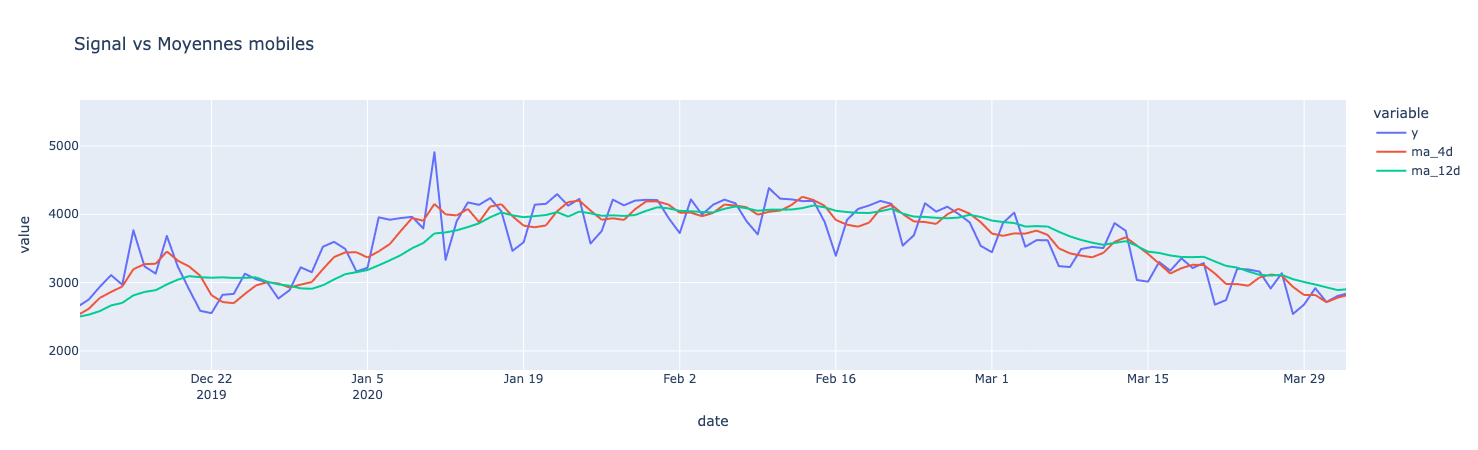
Ces variables sont utiles, mais elles peuvent aussi introduire un piège classique : la fuite temporelle. Nous verrons cela dans les prochains chapitres.
À vous de jouer !

Exercice 1 : Nettoyage “raw → weekly”
Objectif : à partir de data/epidemioscope_raw_daily.csv vous allez produire une série hebdomadaire propre.
Livrables :
une série
weekly(index hebdoW-SUN, sans NaN)un mini `quality_report` (doublons, jours manquants, nb lignes finales)
Corrigé :
import pandas as pd
df = pd.read_csv("data/epidemioscope_raw_daily.csv")
df["date"] = pd.to_datetime(df["date_raw"], dayfirst=True, errors="coerce")
df = df.dropna(subset=["date"]).copy()
df = df.drop(columns=["date_raw"]).sort_values("date").set_index("date")
daily = df["ili_consultations"].groupby(level=0).mean().sort_index()
daily_full = daily.asfreq("D")
missing_days = int(daily_full.isna().sum())
daily_full = daily_full.interpolate("time").round()
weekly = daily_full.resample("W-SUN").sum()
assert weekly.isna().sum() == 0
quality_report = {
"rows_raw": int(len(df)),
"days_after_dedup": int(len(daily)),
"missing_days_detected": missing_days,
"weekly_points": int(len(weekly)),
}
weekly.head(), quality_reportExercice 2 : Feature sans fuite
À partir de `weekly`, construisez un DataFrame avec :
lag_1w,lag_4wroll_4w_mean,roll_12w_mean
Corrigé :
features = pd.DataFrame({"y": weekly})
features["lag_1w"] = features["y"].shift(1)
features["lag_4w"] = features["y"].shift(4)
features["roll_4w_mean"] = features["y"].rolling(4).mean()
features["roll_12w_mean"] = features["y"].rolling(12).mean()
features = features.dropna().copy()
features.head()En résumé
Une série temporelle fiable commence par un axe du temps propre : dates converties, triées, indexées.
Les doublons doivent être traités avec une règle explicite et documentée.
Une série destinée à la modélisation doit souvent être continue : on gère les jours manquants (suppression, interpolation, ou autre stratégie).
Le resampling permet de changer de fréquence (jour → semaine, etc.) et modifie la “texture” du signal.
Les variables temporelles (lags, moyennes mobiles) sont puissantes, mais attention aux fuites temporelles : jamais d’information future.
