Construisez des prévisions statistiques avec Holt-Winters et ARIMA

Vous avez maintenant une série propre, comprise, et décomposée (tendance / saisonnalité / bruit). L’étape suivante, c’est celle qui intéresse souvent tout le monde en entreprise : prévoir.
Concrètement, vous allez apprendre à construire une prévision qui se défend en réunion :
produire une prévision Holt-Winters “niveau + tendance + saisonnalité”,
construire une prévision SARIMA pour une série saisonnière,
et présenter un résultat sous forme de fourchette exploitable.
Appliquez le lissage exponentiel
Un modèle se comporte comme une personne qui apprend de l’expérience récente. Si la réalité change, il s’adapte. Si tout est stable, il ne s’affole pas.
Afin de prolonger une série dans le futur, il lui faut une règle dynamique :
"Ma meilleure estimation du futur, c’est une moyenne intelligente qui oublie progressivement le passé pour mieux suivre le présent."
Le lissage exponentiel privilégie les observations récentes. En forecasting, c'est souvent un excellent premier choix, car c'est :
Rapide à mettre en place
Robuste
Interprétable
Nous n’allons pas rentrer dans les détails mathématiques, retenez juste que vous pouvez donner plus d’importance ou non aux dernières données avec un paramètrealphaqui se comporte de la manière suivante :
alphaproche de 1 : importance extrême envers les valeurs les plus récentesalphaproche de 0 : importance minime envers les valeurs les plus récentes.
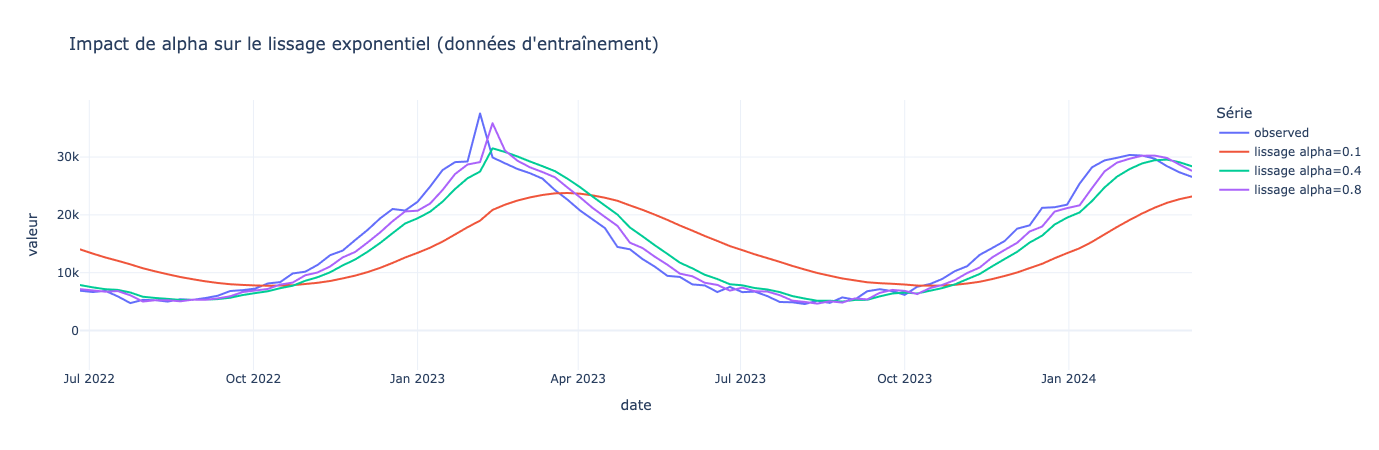
Le lissage exponentiel simple fonctionne bien quand la série oscille autour d’un niveau relativement stable.
Mais que se passe-t-il si la série monte progressivement (tendance) ? Et qu’un motif se répète chaque année / mois / semaine (saisonnalité) ?
Dans ce cas, une simple moyenne pondérée ne suffit plus. Il faut une règle plus complète.
L’idée est simple, si la série contient :
un niveau (valeur moyenne actuelle),
une tendance (direction),
une saisonnalité (cycle répétitif),
…alors il faut estimer les trois en même temps.
Passons désormais à la pratique !
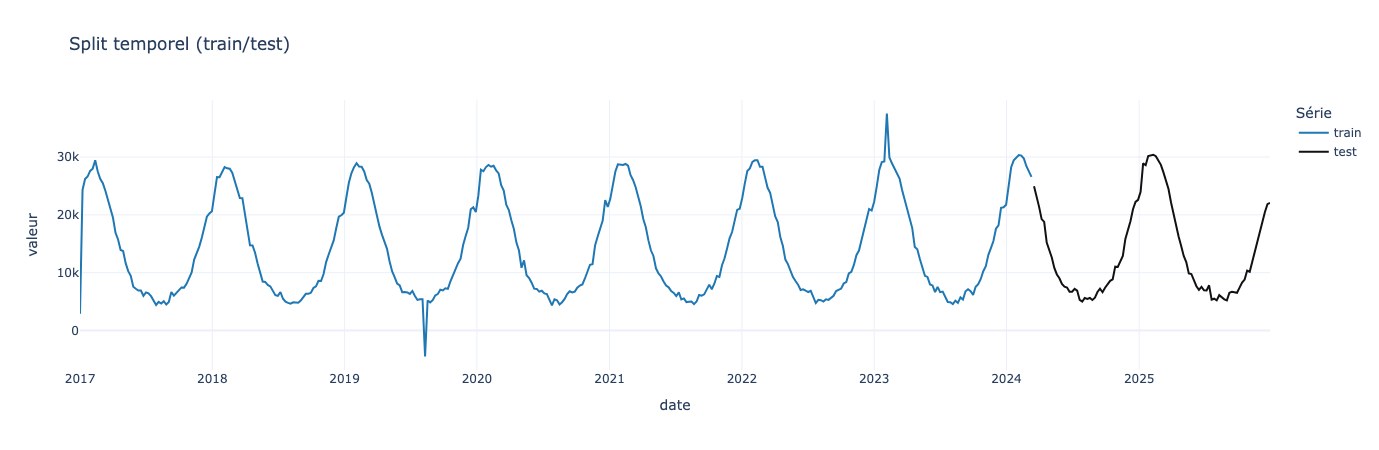
Nous allons dans un premier temps splitter notre série entre train et test
import pandas as pd
import plotly.express as px
weekly = pd.read_csv("../../data/epidemioscope_clean_weekly.csv", parse_dates=["date"])
weekly = weekly.set_index("date")["ili_consultations"].sort_index()
h = 94
train, test = weekly.iloc[:-h], weekly.iloc[-h:]
df_split = pd.concat([
train.rename("train"),
test.rename("test"),
], axis=1).reset_index().melt(id_vars="date", var_name="serie", value_name="valeur")
fig = px.line(
df_split,
x="date",
y="valeur",
color="serie",
title="Split temporel (train/test)",
color_discrete_map={"train": "#1f77b4", "test": "#111111"},
)
fig.update_layout(template="plotly_white", legend_title_text="Série")
fig.show()
from statsmodels.tsa.holtwinters import ExponentialSmoothing
alphas = [0.1, 0.4, 0.8]
alpha_curves = {"observed": train, "test": test,}
for a in alphas:
fit_alpha = ExponentialSmoothing(
train,
trend=None,
seasonal=None,
freq='W-SUN'
).fit(smoothing_level=a, optimized=False)
# Ici on recréé la courbe de lissage avec les données fittées et prédites
alpha_curves[f"lissage alpha={a}"] = pd.concat([
fit_alpha.fittedvalues.rename(f"alpha={a}"),
fit_alpha.forecast(len(test)).rename(f"alpha={a}")
]).sort_index()
df_alpha = pd.concat(alpha_curves, axis=1).reset_index().melt(
id_vars="index", var_name="serie", value_name="valeur"
)
fig = px.line(
df_alpha,
x="index",
y="valeur",
color="serie",
title="Impact de alpha sur le lissage exponentiel (données d'entraînement)",
)
fig.update_layout(template="plotly_white", legend_title_text="Série")
fig.show()
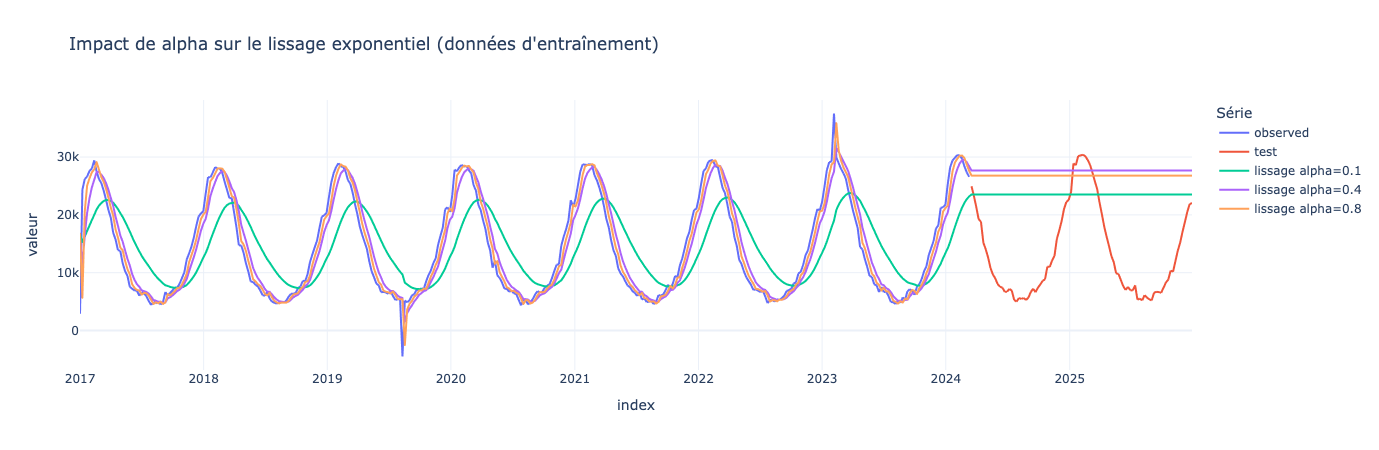
Mais alors pourquoi le lissage reste constant ?
Tout simplement car il n’estime que le niveau de la série et rien d’autre.
Que se passe-t-il si nous ajoutons la tendance (modèle Holt) ?
La tendance est aussi modifiable avec un paramètrebeta
betas = [0.1, 0.4, 0.8]
beta_curves = {"observed": train, "test": test,}
for b in betas:
fit_beta = ExponentialSmoothing(
train,
trend='add',
seasonal=None,
freq='W-SUN'
).fit(smoothing_level=0.5 ,smoothing_trend=b, optimized=False)
# Le niveau alpha est arbitrairement fixé à 0.5 pour nos tests
beta_curves[f"lissage beta={b}"] = pd.concat([
fit_beta.fittedvalues.rename(f"beta={b}"),
fit_beta.forecast(len(test)).rename(f"beta={b}")
]).sort_index()
df_beta = pd.concat(beta_curves, axis=1).reset_index().melt(
id_vars="index", var_name="serie", value_name="valeur"
)
fig = px.line(
df_beta,
x="index",
y="valeur",
color="serie",
title="Holt : prévisions vs réalité",
)
fig.update_layout(template="plotly_white", legend_title_text="Série")
fig.show()
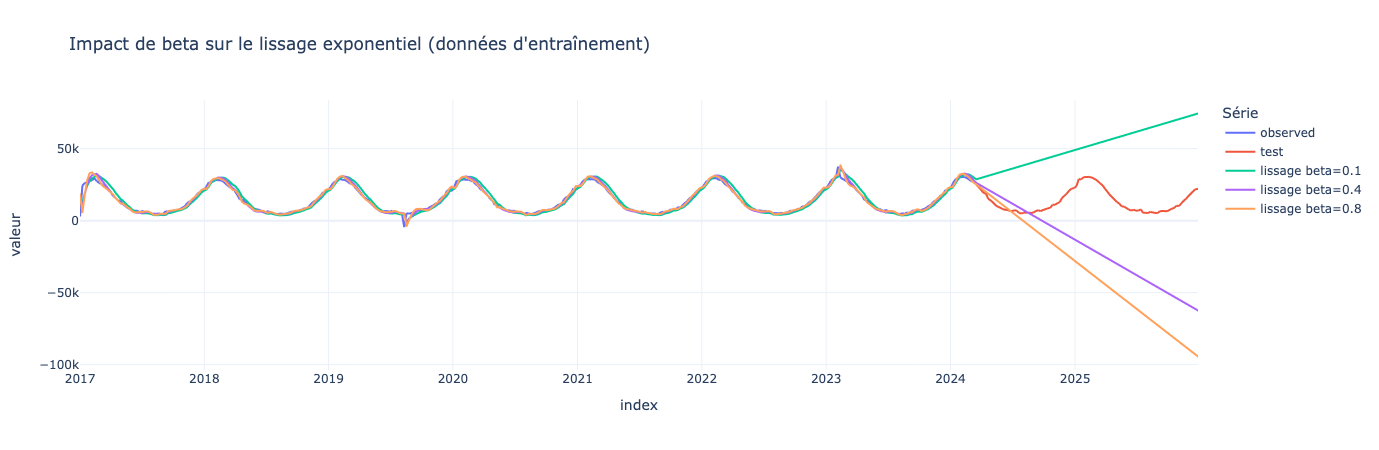
Cette fois-ci en ajoutant la tendance, le modèle prédit bien la tendance qu’il observe sur les dernière valeurs des données train. Il nous manque encore un paramètre à ajouter : la saisonnalité !
Ce qui nous fait enfin passer sur notre modèle Holt-Winters :
gammas = [0.1, 0.4, 0.8]
gamma_curves = {"observed": train, "test": test,}
for g in gammas:
fit_gamma = ExponentialSmoothing(
train,
trend='add',
seasonal='add',
seasonal_periods=52,
freq='W-SUN'
).fit(smoothing_level=0.5 ,smoothing_trend=0.5, smoothing_seasonal=g, optimized=False)
gamma_curves[f"lissage gamma={g}"] = pd.concat([
fit_gamma.fittedvalues.rename(f"gamma={g}"),
fit_gamma.forecast(len(test)).rename(f"gamma={g}")
]).sort_index()
df_gamma = pd.concat(gamma_curves, axis=1).reset_index().melt(
id_vars="index", var_name="serie", value_name="valeur"
)
fig = px.line(
df_gamma,
x="index",
y="valeur",
color="serie",
title="Holt-Winters : prévisions vs réalité",
)
fig.update_layout(template="plotly_white", legend_title_text="Série")
fig.show()
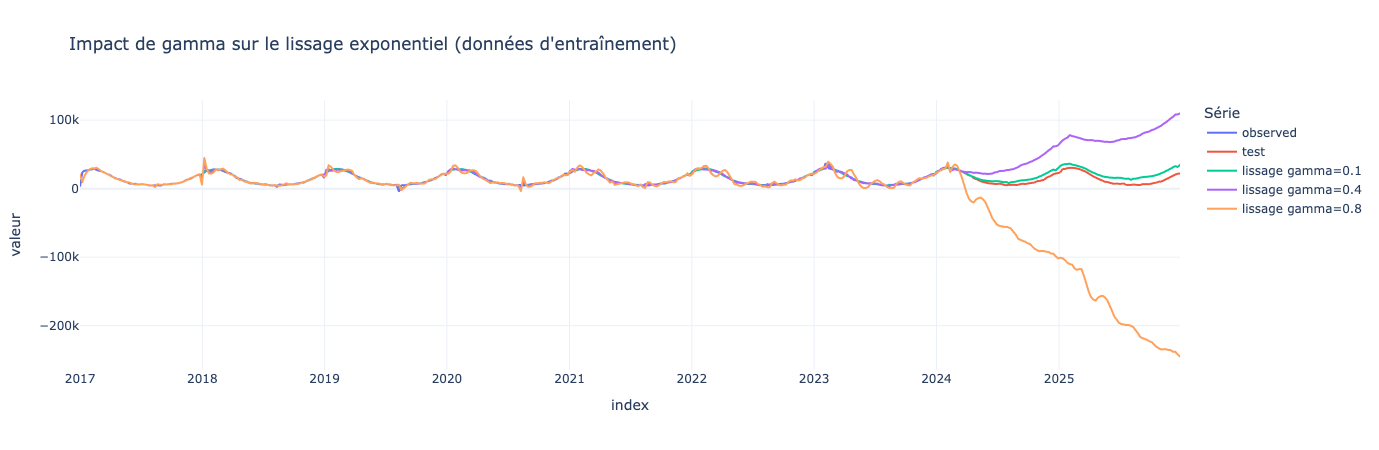
Ok, mais comment je trouve les bons paramètresalpha,betaetgamma?
Grâce au paramètreoptimizedde la fonctionfitque nous avions passé àFalsele temps des explications
hw = ExponentialSmoothing(
train,
trend="add",
seasonal="add",
seasonal_periods=52,
freq='W-SUN'
).fit(optimized=True)
df_hw = pd.concat([
train.rename("train"),
test.rename("test"),
pred_hw.rename("HW forecast"),
], axis=1).reset_index().melt(id_vars="index", var_name="serie", value_name="valeur")
fig = px.line(
df_hw,
x="index",
y="valeur",
color="serie",
title="Holt-Winters : prévisions vs réalité",
color_discrete_map={"train": "#1f77b4", "test": "#111111", "HW forecast": "#2ca02c"},
)
fig.update_layout(template="plotly_white", legend_title_text="Série")
fig.show()
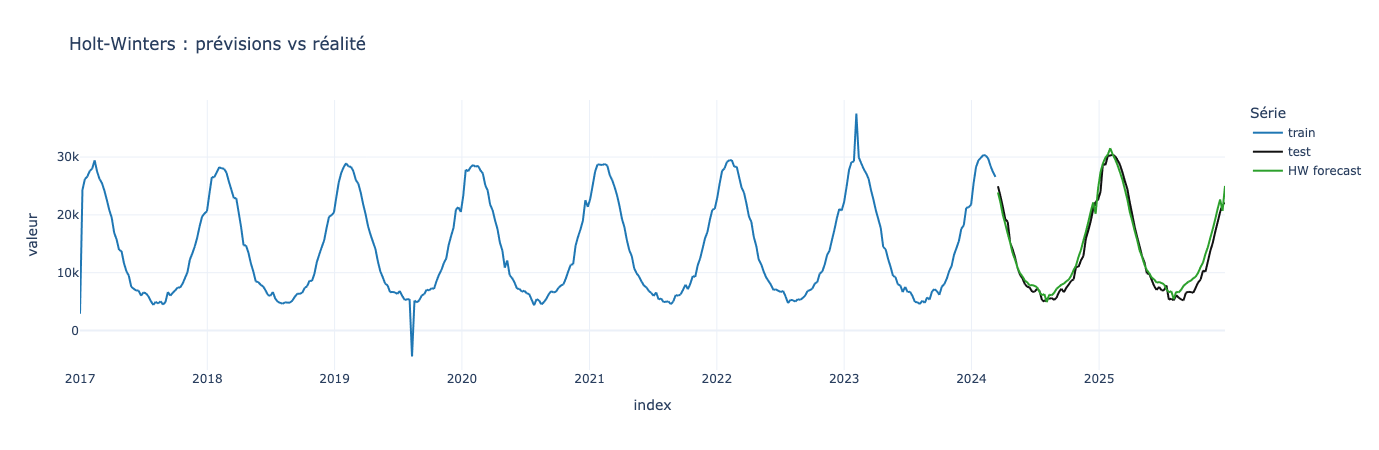
Voilà une belle courbe avec une prédiction plutôt sympa ! Tout ça grâce à une logique finalement assez simple : “On corrige progressivement nos estimations.”
Regardons maintenant comment une autre philosophie de prédiction peut être utilisée !
Décodez ARIMA
Comprenez les 3 paramètres principaux d’ARIMA
Cette fois-ci on ne corrige plus progressivement les estimations, on cherche à modéliser la structure statistique de la série. La modélisation ARIMA repose sur 3 paramètres :
Paramètre | Objectif | Description |
| Modélise la dépendance aux valeurs passées | Est-ce que la valeur d’aujourd’hui dépend des valeurs passées et si oui combien ? |
| Stabiliser la série | Combien de fois je dois enlever la tendance pour stabiliser la série ? |
| Modélise la dépendance aux erreurs passées | Est-ce que les erreurs passées influencent encore la série ? |
Finalement, ARIMA c’est modéliser une série stabilisée en fonction de son passé et des erreurs passées.
Utilisez une approche progressive
Cette fois-ci, pas de paramètreoptimized=Truepour connaître les meilleurs paramètresd,p, etq.
Nous allons commencer pardet le processus est simple :
initialiser d=0
Tester la stationnarité de la série (vous savez déjà faire ça)
Si la série est déjà stationnaire alors d=0
Sinon tester avec une première différenciation
diff1 = train.diff().dropna()Si la série devient stationnaire alors d=1
Sinon (rare) tester avec une deuxième différenciation
diff2 = diff1.diff().dropna()Si la série devient stationnaire alors d=2
le paramètre d ne dépasse quasiment jamais 2, plus la différenciation augmente, plus l’information est détruite.
Passons maintenant au paramètrepqui répond à la question “Combien de retards ont un effet direct sur la valeur actuelle ?”
from statsmodels.graphics.tsaplots import plot_pacf
import matplotlib.pyplot as plt
series = train.diff().dropna()
plot_pacf(series, lags=20)
plt.show()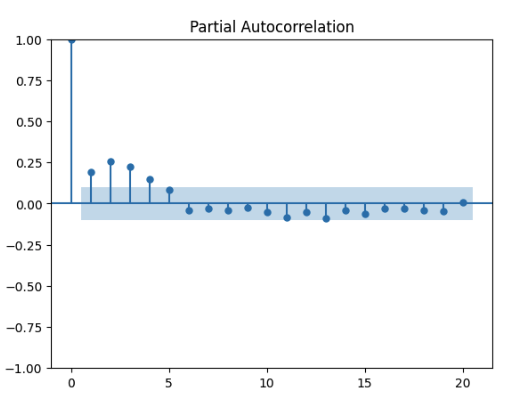
Analysons ensemble ce graphique :
Les points que vous voyez correspondent aux “lag” ou décalages temporels par rapport à la série.
Les bandes bleues correspondent aux intervalles de confiances (point dans les barres = hasard = pas de corrélation).
Donc le lag à 0 qui correspond à lui-même a une corrélation de 1, la série a une corrélation de 1 par rapport à elle-même.
Les lags dans les bandes n'ont pas de corrélations significatives sur la série.
Nous observons ainsi que les lags 1,2,3 et 4 sont hors des bandes bleues.
Nous pouvons donc considérer que la valeur d’aujourd’hui dépend principalement des quatre périodes précédentes. —>p=4
Nous avonsd=1,p=4, regardons désormais le paramètreq
from statsmodels.graphics.tsaplots import plot_acf
import matplotlib.pyplot as plt
series = train.diff().dropna()
plot_acf(series, lags=20)
plt.show()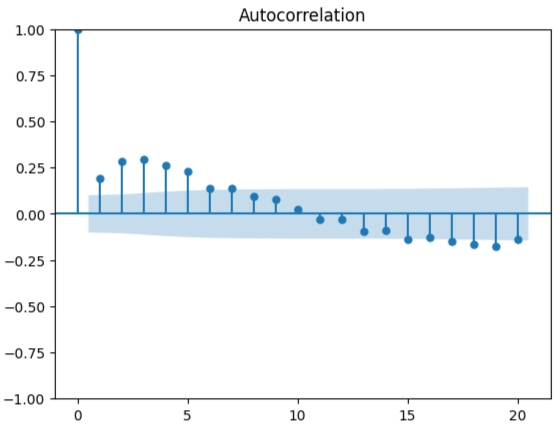
Pour choisirq, on regarde l’ACF : si les corrélations sont significatives jusqu’à un certain lag puis disparaissent, on prend ce lag comme q (candidat).
Dans notre cas le dernier lag se trouve à 5.
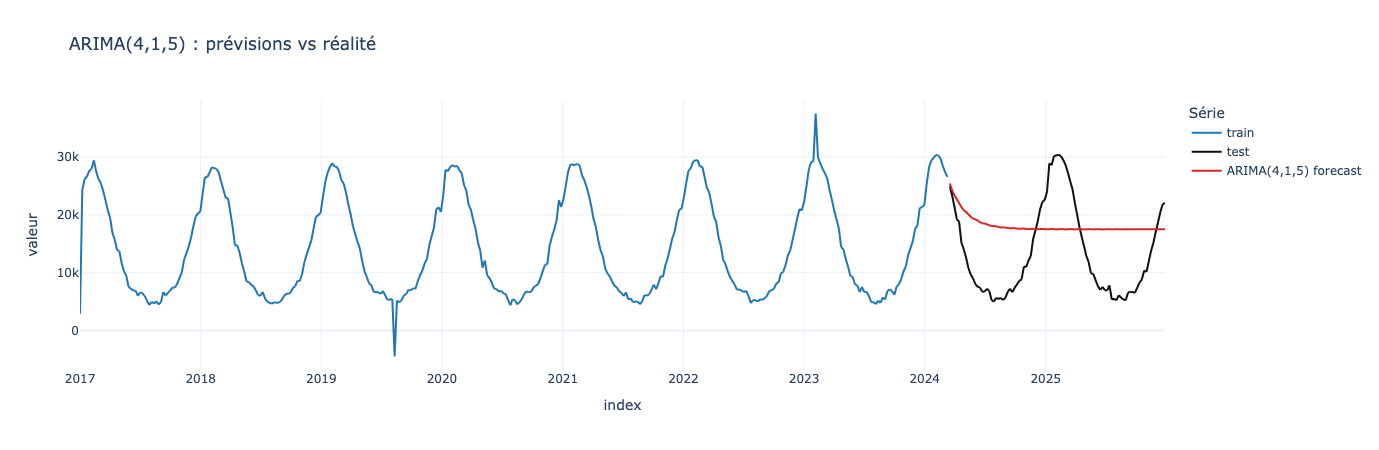
Malgré les analyses d’ACF et de PACF, la prédiction est loin d’être bonne. Les mathématiques nous donnent que la série est stationnaire une fois différenciée, que la valeur d’aujourd’hui dépend principalement des 4 valeurs précédentes et des 5 erreurs précédentes.
Si vous vous dites “mais alors ça sert à quoi ?”, c’est une réaction saine ! 😄
ARIMA “pur” est souvent décevant sur des séries fortement saisonnières. Ce n’est pas un échec : c’est un diagnostic.
Comme d’habitude, il nous manque un élément crucial dans notre cas précis : la saisonnalité ! Et c’est exactement pour ça qu’on passe à SARIMA.
Ajoutez la saisonnalité avec SARIMA
Attendez, vous ne nous avez pas expliqué ce que voulait dire ARIMA et maintenant vous nous ajoutez un S devant ?
En fait je l’ai fait pour les plus attentionnés d’entre vous :
Vous pouvez donc deviner que SARIMA n’est rien d’autre que la version d’ARIMA intégrant la Saisonnalité!
Avec les paramètrespetq, ARIMA dépend des valeurs et des erreurs des lags précédents, mais dans le cas d’une saisonnalité, la valeur d’aujourd’hui peut dépendre aussi de la valeur d’il y a un an.
Quand ARIMA regarde les valeurs du passé proche, SARIMA regarde les valeurs du passé proche et de l’an dernier à la même époque.
Un décideur ne pense pas “corrélations et lags”. Il pense : “Noël revient”, “la rentrée revient”, “l’hiver revient”. Le S de SARIMA, c’est littéralement : “le modèle a compris que certains événements reviennent”.
Et maintenant que l’on a dit cela, mettons en pratique en ajoutant une période réaliste avec un paramètresqui correspond à la longueur de cycle :
Données mensuelles avec saison annuelle :
s = 12Données journalières avec saison hebdo :
s = 7
À partir du paramètress, on vient ajouter 3 paramètres (oui encore je sais, mais attendez finalement vous les avez déjà vus) :
P: Combien de cycle précédents influencent ma valeur d’aujourd’hui ?D: Est-ce que la saisonnalité augmente avec le temps ?Q: Est-ce que les erreurs des dernières saisonnalités influencent ma valeur d’aujourd’hui ?
Vous avez sûrement reconnu les termesp,detqque nous avons vu pour ARIMA, et bien ce sont les mêmes mais appliqués à la saisonnalité !
Regardons ce que cela donne pour notre cas :
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
import matplotlib.pyplot as plt
# Nos données ont une saisonnalité annuelle
s = 52
# La saisonnalité est très marqué donc nous allons la différencier une fois (D=1)
train_seasonal_diff = train.diff(s).dropna()
plot_pacf(train_seasonal_diff, lags=2*s)
plot_acf(train_seasonal_diff, lags=2*s)
plt.show()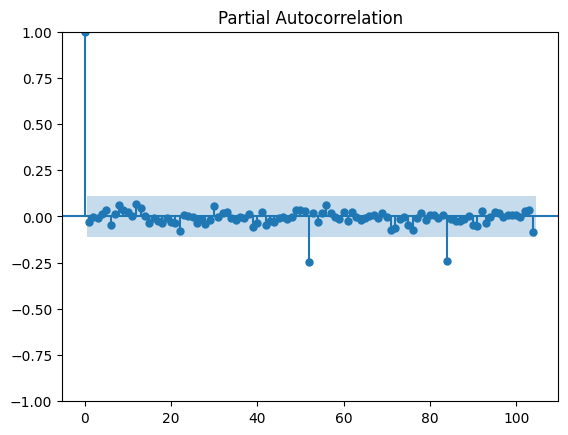
Le PACF avec saisonnalité nous montre que les petits lags restent dans les bandes, doncp=0(pas d’influence sur les valeurs proches précédentes). Il y a un pic à 52, qui correspond bien à notre saisonnalité, et l’on voit qu’il y a un pic à la limite des bandes à 104. Nous pouvons en conclure que la période précédente (Lag 52) influe notre valeur, et que cette influence s’arrête à 1 saisonnalité, car le lag 104 reste dans l’intervalle de confiance, doncP=0.
Le pic autour de 84, ne correspond à aucune logique métier connue de notre série, nous considérerons du coup ce pic comme du bruit.
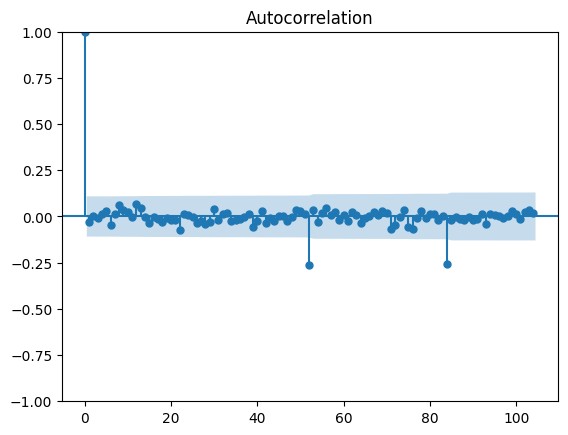
Les premiers lags sont dans les bandes, donc non significatifs,q=0. Nous observons aussi un pic clair à 52 et toujours le pic bruit à 84. Nous garderons doncQ=1.
Cela nous donne un SARIMA (0,d,0)x(0,1,1,52). Le premierdpeut être testé avec 0 ou 1, nous allons prendre 0.
from statsmodels.tsa.statespace.sarimax import SARIMAX
p=0
d=0
q=0
P=0
D=1
Q=1
s=52
sarima = SARIMAX(
train,
order=(p, d, q),
seasonal_order=(P, D, Q, s)
).fit()
pred_sarima = sarima.forecast(steps=h)
df_sarima = pd.concat([
train.rename("train"),
test.rename("test"),
pred_sarima.rename(f"SARIMA({p},{d},{q})x({P},{D},{Q},{s}) forecast"),
], axis=1).reset_index().melt(id_vars="index", var_name="serie", value_name="valeur")
fig = px.line(
df_sarima,
x="index",
y="valeur",
color="serie",
title=f"SARIMA({p},{d},{q})x({P},{D},{Q},{s}) : prévisions vs réalité",
color_discrete_map={"train": "#1f77b4", "test": "#111111", f"SARIMA({p},{d},{q})x({P},{D},{Q},{s}) forecast": "#d62728"},
)
fig.update_layout(template="plotly_white", legend_title_text="Série")
fig.show()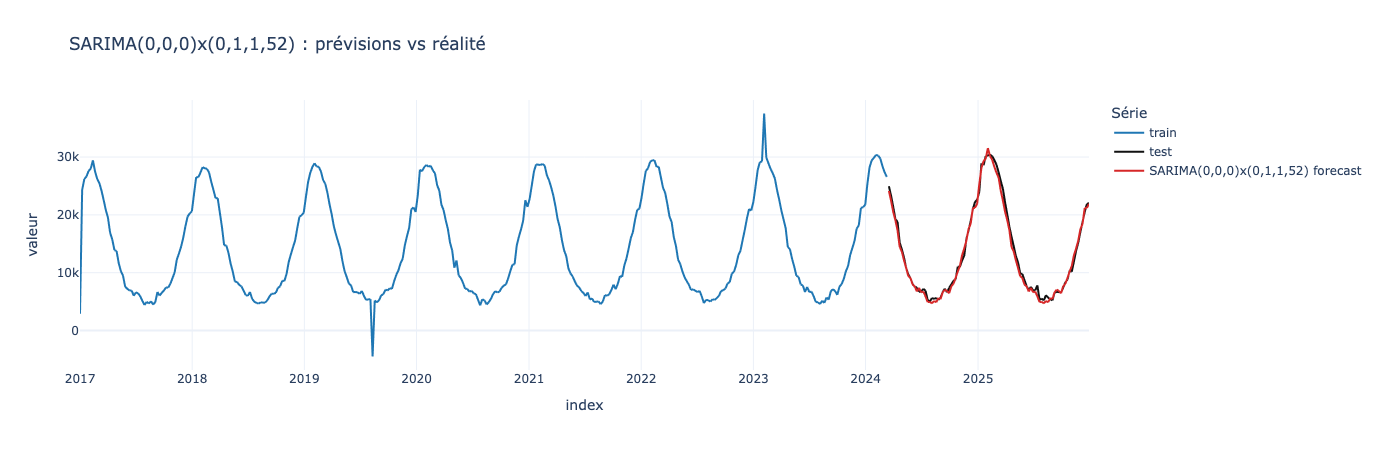
Et voilà une prédiction bien modélisée !
Présentez des intervalles de confiance, et non un chiffre “magique”
Comprenez la différence entre “prévision” et “incertitude”
Nous venons de modéliser une prédiction avec SARIMA. Cependant un modèle ne “voit” pas le futur. Il estime une trajectoire probable avec un niveau d’incertitude. Tout cela reste du domaine de la statistique, et toute prévision statistique n’est qu’une distribution de valeurs plausibles.
Une prévision contient deux éléments :
La valeur centrale, qui correspond à la meilleur estimation du modèle
L’intervalle de confiance qui correspond à la zone dans laquelle la vraie valeur a une probabilité élevée de se trouver
Voyons ce que cela donne avec une précision à probabilité à 95% (alpha = 0.05)
pred_sarima = sarima.get_forecast(steps=h)
mean = pred_sarima.predicted_mean
ci95 = pred_sarima.conf_int(alpha=0.05)
df_sarima_with_intervals = pd.concat([
train.rename("train"),
test.rename("test"),
mean.rename("Prévision SARIMA"),
ci95.iloc[:, 0].rename("IC 95% bas"),
ci95.iloc[:, 1].rename("IC 95% haut"),
], axis=1).reset_index().melt(id_vars="index", var_name="serie", value_name="valeur")
fig = px.line(
df_sarima_with_intervals,
x="index",
y="valeur",
color="serie",
title="Prévision SARIMA avec IC 95%",
color_discrete_map={
"train": "#1f77b4",
"test": "#111111",
"Prévision SARIMA": "#2ca02c",
"IC 95% bas": "#98df8a",
"IC 95% haut": "#98df8a",
},
)
fig.update_layout(template="plotly_white", legend_title_text="Série")
fig.show()
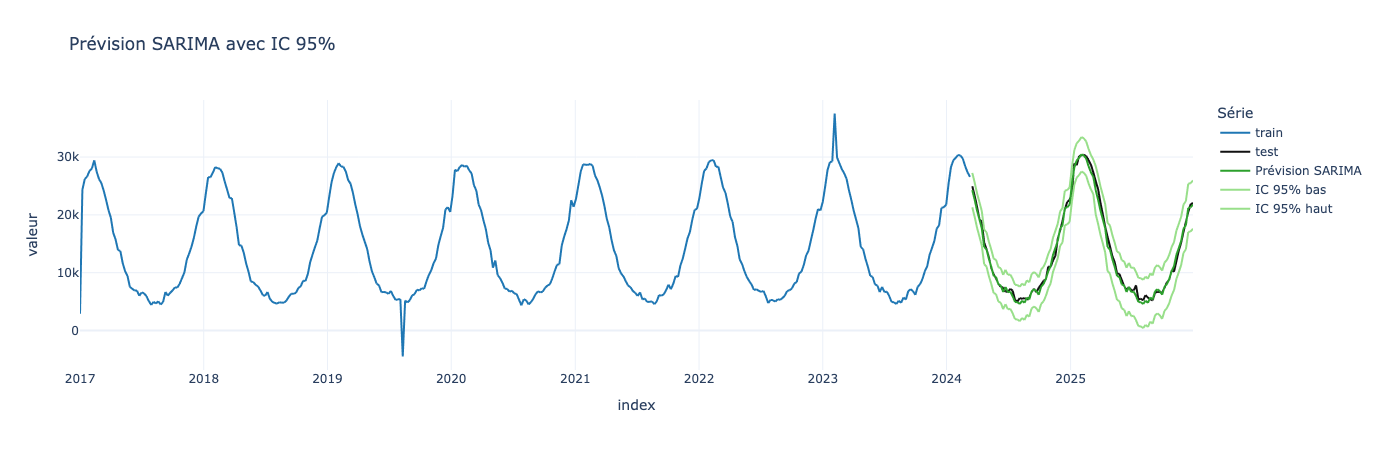
Présentez une fourchette utilisable (“entre X et Y”)
Maintenant que vous savez comment réaliser un intervalle de confiance, il reste la partie la plus importante : la communication.
Un décideur n’a pas besoin d’une moyenne avec un intervalle de confiance, il a besoin d’une fourchette utilisable, une zone d’atterrissage opérationnelle.
Par exemple :
Pour la semaine 6 de 2025, nous prévoyons un nombre de consultations aux alentours de 30500, avec un scénario optimiste à 27000 et un scénario pessimiste à 33000.
Vous notez que les chiffres ont été arrondis pour faciliter la compréhension, et surtout la rétention par l’auditoire.
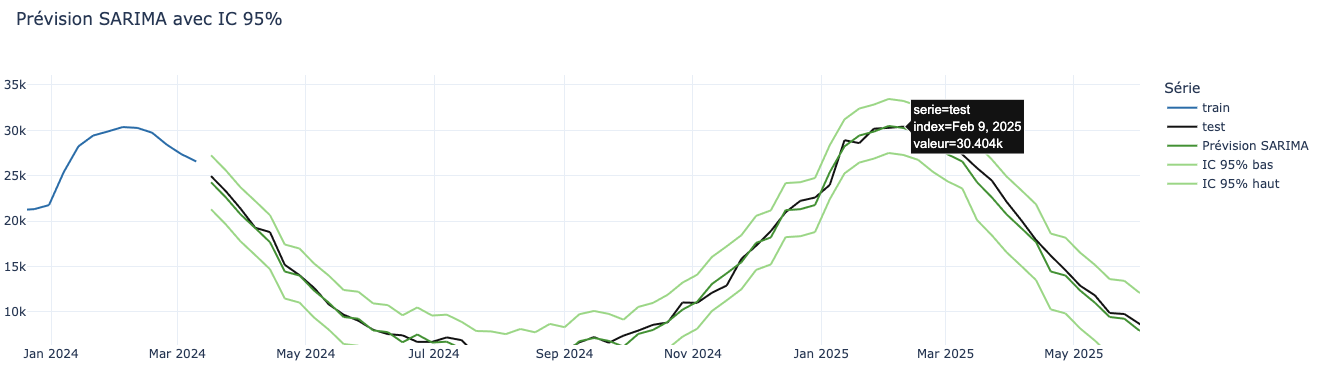
Reliez l’incertitude au contexte (périodes atypiques, peu d’historique)
Plus vous avez un intervalle d’incertitude serré, plus cela signifie que vous avez confiance en vos prédictions, ce qui dénote souvent de la saisonnalité régulière sur vos données ou un comportement historique stable.
Dès que vous manquez d’historique, que vous avez une série instable, ou qu’une rupture récente a eu lieu, votre intervalle de confiance va s’élargir mécaniquement.
Rappelez-vous d’une chose, dans un contexte d’entreprise, ce qui protège une organisation c’est la compréhension de la zone de risque.
À vous de jouer !

Consigne :
Entraînez un modèle Holt-Winters sur les données de consultations hebdomadaires en utilisant les 12 dernières semaines en test. Entraînement modèle SARIMA.
Entrainez un modèle SARIMA sur les données hebdomadaires et proposer une prévision à 15 semaines avec un intervalle de confiance de 93%
Corrigé :
import pandas as pd
import plotly.express as px
from statsmodels.tsa.holtwinters import ExponentialSmoothing
weekly = pd.read_csv("epidemioscope_clean_weekly.csv", parse_dates=["date"])
weekly = weekly.set_index("date")["ili_consultations"].sort_index()
h = 12
train, test = weekly.iloc[:-h], weekly.iloc[-h:]
hw = ExponentialSmoothing(
train,
trend="add",
seasonal="add",
seasonal_periods=52,
freq='W-SUN'
).fit(optimized=True)
pred_hw = hw.forecast(h)
df_hw = pd.concat([
train.rename("train"),
test.rename("test"),
pred_hw.rename("HW forecast"),
], axis=1).reset_index().melt(id_vars="index", var_name="serie", value_name="valeur")
fig = px.line(
df_hw,
x="index",
y="valeur",
color="serie",
)
fig.show()import pandas as pd
import plotly.express as px
import matplotlib.pyplot as plt
from statsmodels.tsa.statespace.sarimax import SARIMAX
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
weekly = pd.read_csv("epidemioscope_clean_weekly.csv", parse_dates=["date"])
weekly = weekly.set_index("date")["ili_consultations"].sort_index()
h = 15
train, test = weekly.iloc[:-h], weekly.iloc[-h:]
s = 52
train_seasonal_diff = train.diff(s).dropna()
plot_pacf(train_seasonal_diff, lags=2*s)
plot_acf(train_seasonal_diff, lags=2*s)
sarima = SARIMAX(
train,
order=(0, 1, 0),
seasonal_order=(0, 1, 1, 52),
).fit()
pred_sarima = sarima.forecast(steps=h)
df_sarima = pd.concat([
train.rename("train"),
test.rename("test"),
pred_sarima.rename(f"SARIMA({p},{d},{q})x({P},{D},{Q},{s}) forecast"),
], axis=1).reset_index().melt(id_vars="index", var_name="serie", value_name="valeur")
fig = px.line(
df_sarima,
x="index",
y="valeur",
color="serie",
title=f"SARIMA({p},{d},{q})x({P},{D},{Q},{s}) : prévisions vs réalité",
)
fig.show()
pred_sarima = sarima.get_forecast(steps=h)
mean = pred_sarima.predicted_mean
ci95 = pred_sarima.conf_int(alpha=0.07)
df_sarima_with_intervals = pd.concat([
train.rename("train"),
test.rename("test"),
mean.rename("Prévision SARIMA"),
ci95.iloc[:, 0].rename("IC 93% bas"),
ci95.iloc[:, 1].rename("IC 93% haut"),
], axis=1).reset_index().melt(id_vars="index", var_name="serie", value_name="valeur")
fig = px.line(
df_sarima_with_intervals,
x="index",
y="valeur",
color="serie",
title="Prévision SARIMA avec IC 93%",
)
fig.show()
En résumé
Le lissage exponentiel donne plus de poids aux observations récentes et constitue une première méthode rapide, robuste et interprétable pour produire des prévisions.
Holt-Winters améliore cette approche en estimant simultanément le niveau, la tendance et la saisonnalité, ce qui le rend adapté aux séries qui évoluent et répètent des cycles.
ARIMA modélise la structure statistique d’une série stabilisée à partir de ses valeurs passées et de ses erreurs, mais il reste souvent limité lorsque la saisonnalité est forte.
SARIMA ajoute une composante saisonnière à ARIMA et permet de mieux représenter les phénomènes récurrents, ce qui le rend plus pertinent pour de nombreuses données métier.
Une prévision utile ne se résume pas à une valeur unique et doit être présentée sous forme de fourchette avec intervalle de confiance pour éclairer la décision et le risque.
Dans le prochain chapitre, nous allons voir comment valider un modèle temporel correctement, c'est parti !
