Déterminez vos clés primaires
Jusqu’à maintenant, vous avez vu que les classes UML se traduisent en tables. Ici, nous allons plonger plus en détail au cœur des tables pour analyser ce qui les compose : les lignes et les colonnes.
Pour commencer, vous verrez comment le modèle relationnel permet d’identifier une ligne d’une table.
Identifiez les clés primaires
Apprenez à identifier les lignes d’un table
Prenons quelques secondes pour raisonner. Est-ce que vous vous souvenez que pour éviter la redondance, il faut que chaque information ne soit présente qu’une seule fois dans la BDD ?
Si chaque information ne doit être présente qu’une seule fois, cela implique que dans une table donnée, par exempleoeuvre, il ne doit pas y avoir deux lignes décrivant une même œuvre.
Ainsi,oeuvrecontiendra exactement autant de lignes qu’il y a d'œuvres dont les lieux de tournage ont été enregistrés dans notre fichier CSV.
Mais cela pose une question fondamentale : comment nous assurer que deux lignes deoeuvre font bien référence à 2 œuvres différentes ?
Autrement dit, comment différencier deux lignes ?
Cette question fondamentale, c’est celle de l’identité. Dans le monde, chaque personne est unique. Ce qui garantit votre unicité, c’est votre identité. En effet, deux personnes ne peuvent pas avoir la même identité, et une personne ne peut avoir deux identités différentes (à part dans le monde des espions et espionnes, mais ça c’est une autre histoire).
Dans un SGBDR, chaque ligne doit avoir une identité.
L’identité d’une ligne est appelée clé primaire.
Qu’est-ce que cela veut dire ?
Si on est sûr que n'importe quelle ligne peut être retrouvée en connaissant la valeur de quelques-uns de ses attributs, c'est que ces quelques attributs forment une clé primaire !
Cette illustration vous aidera peut-être à visualiser ce concept :
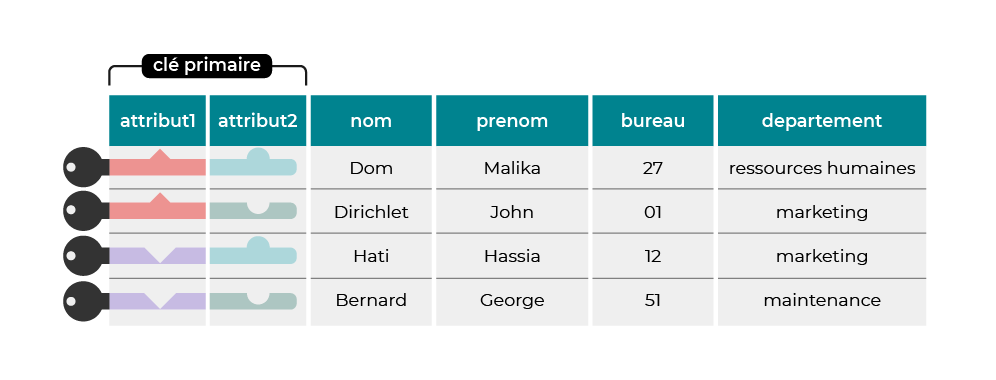
Illustrons cela par un exemple plus concret : cette notion d’identification est essentielle pour les facteurs qui doivent identifier de manière certaine les logements pour lesquels ils distribuent le courrier. Imaginez une table qui répertorie des logements, possédant ces colonnes :
Type de logement (maison, appartement, etc.).
Superficie.
N° de logement (ex. : appartement numéro 203).
N° de voie (ex. : 5).
Complément (ex. : 5 bis).
Intitulé de la voie (ex. : rue de la République).
Commune (ex. : Passillac-les-Flots).
Code postal.
Pays.
La clé primaire de cette table, ce sera le groupe de colonnes minimum que l’on peut donner au facteur pour qu’il soit sûr de pouvoir distribuer un courrier au bon logement.
Si on lui donne uniquement les attributsintitulé de la voie,code postaletcommune (par exemple « rue de la République, 93124 Passillac-les-Flots »), il lui sera difficile de donner le courrier, car la rue de la République de Passillac contient plusieurs logements.
Si au contraire, on lui donne tous les attributs, le courrier pourra à coup sûr être distribué. Cependant, le groupe d’attributs 1 à 9 n’est pas considéré comme minimal : la superficie n’a pas besoin d’être connue pour distribuer un courrier. superficiene doit donc pas figurer dans la clé primaire.
Une bonne clé primaire pour cette table sera donc le groupe des attributs 3 à 9. Même si pour une maison, l’attributn° de logementn’a pas besoin d’être connu, il est quand même important de le placer dans la clé primaire de la table, afin de pouvoir identifier les différents appartements d’un même immeuble.
Autrement dit, le groupe(code_postal, commune)ne peut pas être une clé primaire car les lignes « 3 rue de la Charrue avant les bœufs, 93124 Passillac-les-Flots » et « 5 rue du Pangolin superstitieux, 93124 Passillac-les-Flots » ont toutes les deux les mêmes valeurs pour (code_postal, commune), soit93124etPassillac-les-Flots. Ce groupe d’attributs violerait donc la contrainte d’unicité.
À vous de jouer

Ça y est, vous êtes prêt à déterminer les clés primaires de votre modèle. Je vous remets ici l’état actuel du modèle :
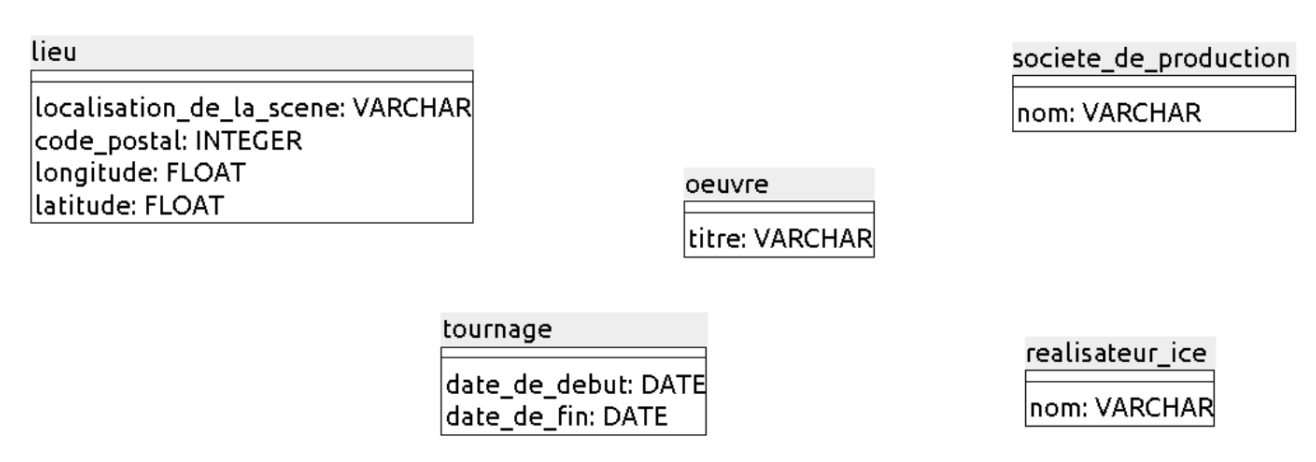
Tablessociete_de_productionetrealisateur_ice
Pour les tablessociete_de_productionetrealisateur_ice, il n’y a pas beaucoup de choix : nous prendrons l’attributnompour chacune de ces deux tables. Bien sûr, cela suppose qu’il n’y ait pas deux sociétés de production ayant le même nom, ni deux réalisateurs/réalisatrices ayant le même nom. C’est très peu probable, donc on peut considérer quenomest une bonne clé primaire pour ces 2 tables.
Tablelieu
Pour la tablelieu, c’est moins évident. Il pourrait y avoir deux clé primaires possibles :
Le groupe
(localisation_de_la_scene, code_postal).Le groupe
(latitude, longitude).
Pour la première solution, il faut supposer quelocalisation_de_la_scenecontienne bien au moins le nom de la rue (de la voie) ainsi que la commune. Dans ce cas, la contrainte d’unicité est respectée car il n’existe pas deux noms de voie identiques pour une même commune. Et même s’il existe en France plusieurs communes ayant le même nom, le code postal permet de lever cette ambiguïté. Avec cette clé primaire, on peut donc identifier dans quelle rue est tournée une œuvre donnée.
Mais cette première solution a des inconvénients. Tout d’abord, l’attribut localisation_de_la_scene est de mauvaise qualité : l’utilisateur qui entre une adresse n’est pas contraint d'indiquer cette adresse de manière normalisée : rien ne l'oblige à indiquer le nom de la commune. Il pourrait même indiquer le code postal, alors que celui-ci est censé être déjà présent dans l’attribut code_postal: bonjour la redondance ! De plus, l’utilisateur peut écrire une même adresse de deux manières différentes, par exemple « 2, boulevard Joffre» et « 2 Bd Joffre » : cela rend difficile la détection de doublons !

Il aurait été plus judicieux de demander à l’utilisateur de saisir les adresses dans des champs séparés : numéro de voie, nom de voie, complément d’adresse, commune, code postal, etc.
Quant à la solution 2, elle pose un autre problème : celui de la précision. Faut-il considérer le couple latitude-longitude (48.87512, 2.348979) comme étant différent du couple (48.87506, 2.348963), alors que ces deux endroits sont séparés de 3 mètres, se trouvent dans la même rue et désignent donc le même lieu de tournage ?
Tablesoeuvreet tournage
Pour les tables oeuvreettournage , il est impossible, pour le moment, de trouver une clé primaire.
En effet, dans le chapitre où nous parlions de la composition en UML, nous avions dit cela : « Il existe parfois des films différents ayant le même nom (exemple : au moins quatre films portent le titre Home). Ainsi, pour identifier un film de manière certaine, on a besoin de son titre mais aussi du nom de sa société de production, ce qui prouve le lien de dépendance entre ces deux classes. »
Problème : la table oeuvrene contient pas, pour l’instant, d’attribut donnant le nom de la société de production. Sans cet attribut, on ne peut pas avoir de clé primaire.
Pour la table tournage, nous n’avons que deux attributs : la date de début et la date de fin.
Problème : deux tournages (de deux films différents, sur deux lieux différents) peuvent avoir débuté et s’être terminés exactement aux mêmes dates. Pour vous en convaincre, vous pouvez vérifier aux lignes 2016-87 et 2016-189 ;) . Il n’y a donc pas d’unicité possible.
Un point sur les notations et représentations graphiques
Graphiquement, il est courant de représenter les attributs qui constituent la clé primaire dans la partie centrale du rectangle qui représente la table, et tous les autres attributs sont inscrits dans la partie basse. Mais il peut arriver que vous rencontriez d’autres représentations, ailleurs que dans ce cours. Par exemple avec la clé primaire en gras ou soulignée.
Aussi, on peut indiquer les attributs de la clé primaire par l’abréviation « PK », mise pour « Primary Key ».
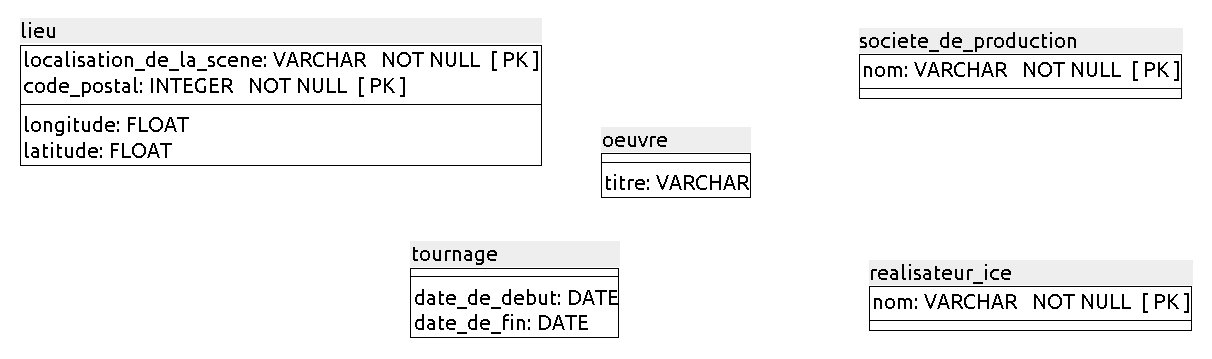
Créez des clés primaires artificielles
Parmi les attributs d’une table, il est parfois impossible de trouver une clé primaire. Dans d’autres cas, la clé primaire est trop complexe (trop d’attributs, par exemple). Dans ce cas, il est possible de créer une clé artificielle.
Exemple : le numéro de Sécurité sociale ou le numéro de carte d’identité sont des clés artificielles permettant d'identifier les personnes de nationalité française.
Par exemple, prenez cet extrait de votre fichier CSV :

Si vous le transformez pour le faire coller à votre modèle relationnel (donc avec deux tables oeuvreetsociete_de_production, avec une clé étrangèresociete_prod) en y ajoutant des clés artificielles, vous pourriez être tenté de simplement découper le fichier en deux :
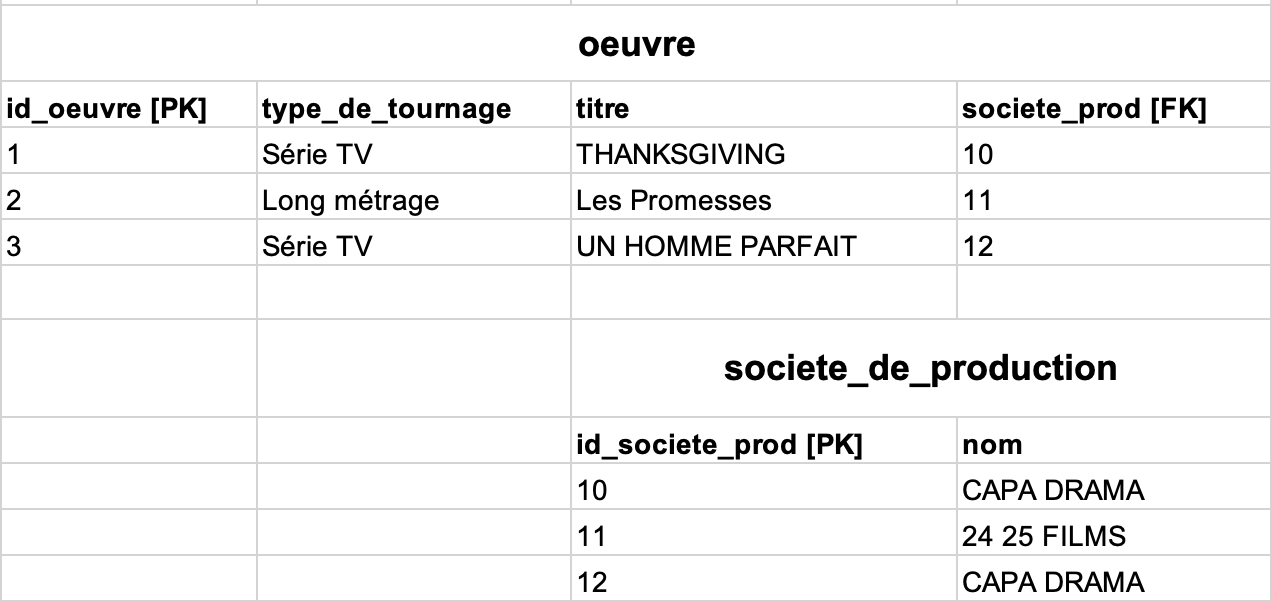
Voilà pourquoi, même en choisissant une clé artificielle, il faut garder en tête la contrainte d’unicité de la clé primaire(nom)desociete_de_productionet vérifier que(nom)ne contient pas de doublons. Si vous faites cela, vous arriverez à cette solution correcte :
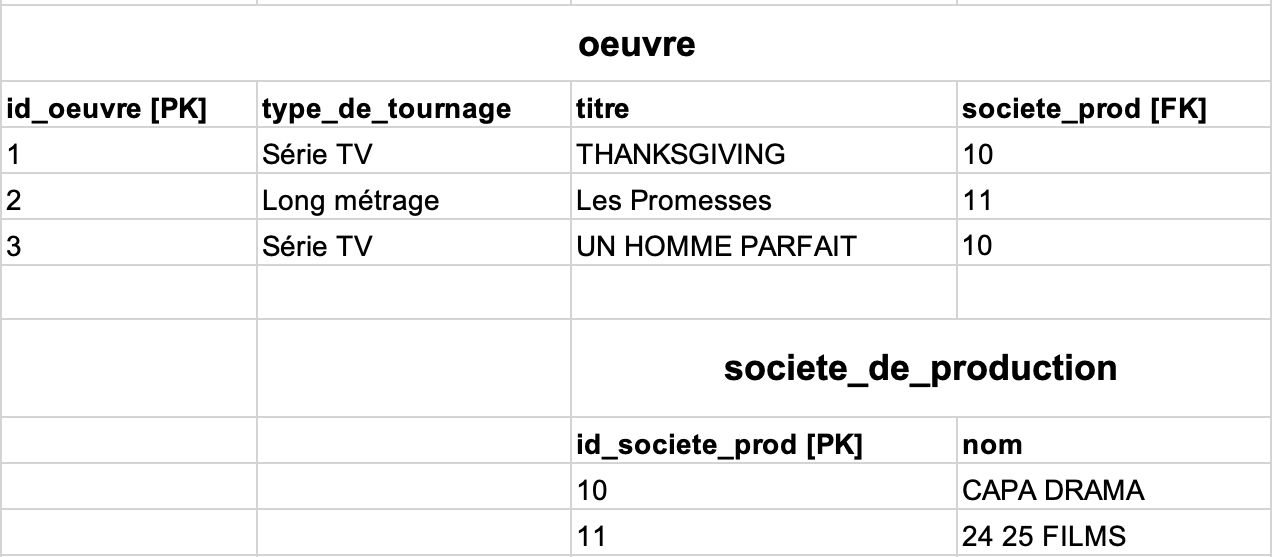
Par contre, quand on passe au MPD (la troisième étape de la modélisation), il est fréquent d’utiliser des clés artificielles systématiquement, car :
Il y a toujours un risque qu’une clé primaire non artificielle perde la propriété d’unicité (exemple : si une même société de production produit deux films ayant le même nom).
Si la valeur d’une clé non artificielle est modifiée (si par exemple une société de production change de nom), il faut modifier toutes les clés étrangères qui la référencent.
En résumé
La clé primaire d’une table est un groupe de colonnes minimum permettant d'identifier une ligne d'une table.
Une clé primaire a donc forcément une contrainte d'unicité.
Dans certains cas, il est impossible de trouver une clé primaire parmi les colonnes présentes. Dans d’autres cas, la clé primaire est trop complexe. On crée alors une clé primaire artificielle.
Dans le MLD, l'usage de clé primaire artificielle est à réserver pour les cas particuliers, et il faut prendre certaines précautions.
Vous avez identifié vos clés primaires, c’est bien. Mais vos tables sont encore séparées les unes des autres. Dans le chapitre suivant, vous verrez comment les relier entre elles.
