Augmentez la robustesse de vos modèles

Compensez l'overfit avec la régularisation
La régularisation est une technique qui permet de tempérer les ardeurs d'un modèle. Nous allons rajouter une contrainte sur le modèle pour qu'il ne puisse plus coller aux données d'entraînement.
La documentation de scikit-learn pour le modèle Ridge indique :
Minimise la fonction de coût :
Nous avons vu que définir une fonction de coût permet de fixer un objectif d'apprentissage au modèle. Dans la régression linéaire simple, la fonction de coût est , où est la variable cible, la matrice des prédicteurs et représente le vecteur de coefficient de la régression linéaire. La fonction de coût est dans ce cas la norme quadratique de l'erreur d'estimation.
Pour Ridge, on ajoute un terme à cette fonction de coût où :
joue le rôle d'une contrainte sur les coefficients de la régression. C'est la régularisation du modèle ;
et est le paramètre qui permet de régler la quantité de régularisation que l'on va ajouter.
Pour montrer l'impact de la régularisation il nous faut un dataset et un modèle qui overfit, donc qui soit complexe, et qui offre de la régularisation de type L2.
Ridge est un modèle de régression linéaire donc par définition simple. On peut le rendre plus complexe en l'appliquant à une régression polynomiale.
Nous l'avons brièvement vu au chapitre 2 de la partie 2, la régression polynomiale consiste à régresser la cible …
… non plus seulement à partir du prédicteur :
y ~
… mais à partir des puissances du prédicteur :
y ~
La complexité du modèle, et donc sa tendance à overfitter, croît avec la puissance du polynôme en . Nous allons donc comparer des modèles de régression polynomiale avec différents niveaux de régularisation L2.
Nous suivons les étapes :
Étape 1 : Mise en scène
Créer un dataset simple à une variable prédictrice avec make_regression.
from sklearn.datasets import make_regression
X, y = make_regression(n_samples=30, n_features=1, noise=40, random_state=random_state)Entraîner une régression linéaire simple y ~ avec le modèle Ridge et sans régularisation.
from sklearn.linear_model import Ridge
model = Ridge(alpha=0)
model.fit(X, y)
y_pred = model.predict(X)En effet, la régularisation n'est pas nécessaire puisque le modèle n'overfit pas. Comme on peut l'observer, il sous-performe.
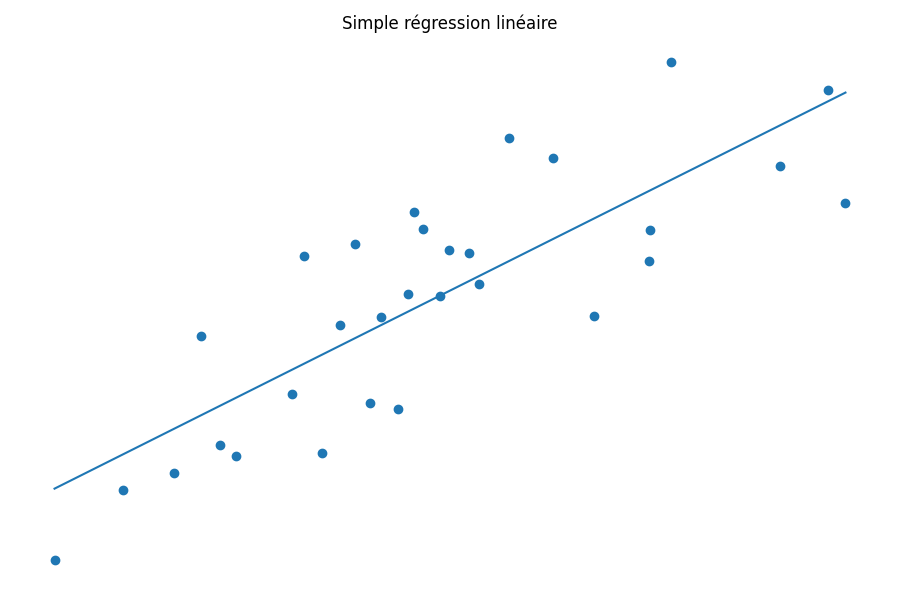
Étape 2 : L'overfit
Considérons ensuite la régression polynomiale de degré 12 (autrement plus complexe que la simple régression linéaire).
Pour créer la matrice des prédicteurs, nous utilisons la transformation PolynomialFeatures :
from sklearn.preprocessing import PolynomialFeatures
pol = PolynomialFeatures(degree, include_bias = False)
X_poly = pol.fit_transform(X)
model = Ridge(alpha=0)
model.fit(X_poly, y)Ce modèle overfit fortement le dataset.
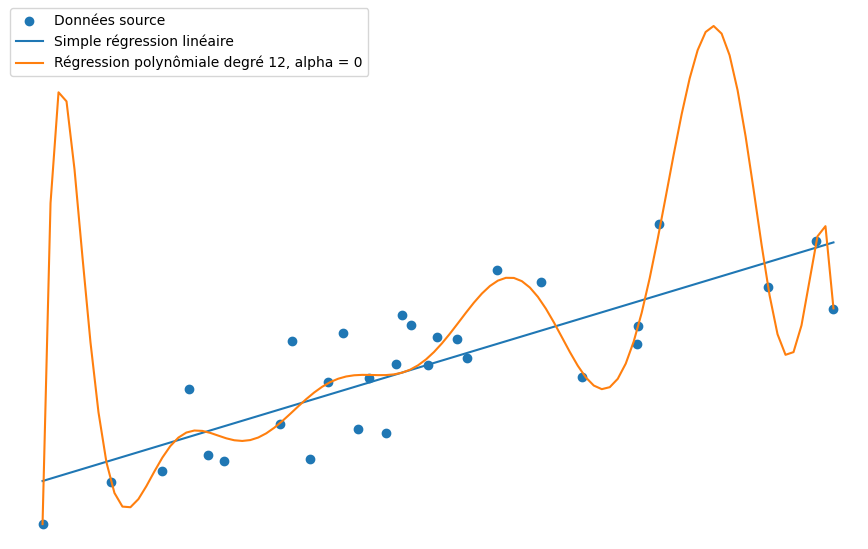
Étape 3 : La régularisation
En augmentant la quantité de régularisation (à travers des valeurs croissantes du paramètre ), on observe bien un effet d'atténuation de la sensibilité du modèle qui cherche de moins en moins à passer par tous les points du dataset. La régularisation réduit l'overfit.
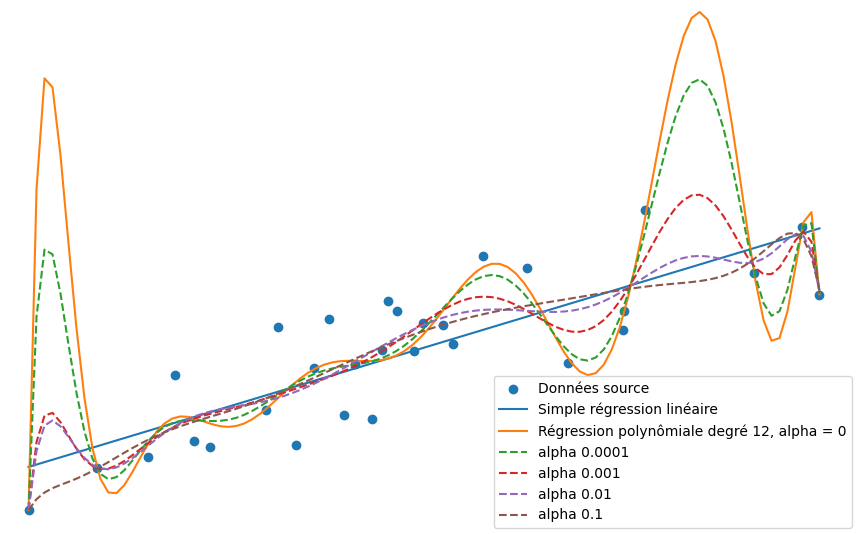
Voilà pour un bref aperçu sur la théorie de la régularisation. Ce qu'il faut en retenir c'est que la régularisation, quand elle est disponible, permet dans la plupart des cas de remédier à l'overfit.
La régularisation d'un modèle peut prendre des formes différentes.
L1 au lieu de L2 : Ce terme de régularisation apparaît avec soit la norme quadratique L2 soit la norme de premier degré L1. Le terme de régularisation de la fonction de coût est alors de la forme où est la somme de la valeur absolue des coefficients du vecteur .
L'équivalent du modèle Ridge avec la régularisation L1 s'appelle Lasso.
Pour les arbres de décision, régulariser le modèle consiste à limiter la profondeur de l'arbre ou à jouer sur d'autres paramètres.
Dans les réseaux de neurones, la régularisation prend une autre forme comme la technique du Dropout, mais le principe sera le même.
Implémentez la validation croisée
Imaginez par exemple que dans notre dataset des arbres de Paris, la plupart des arbres particulièrement hauts se retrouvent dans la partie test. Le modèle ne verrait que très peu d'arbres hauts pendant l'entraînement et donc serait bien à la peine pour prédire des arbres de cette nature. Son score(test) serait mauvais.
La validation croisée permet de réduire le risque de ces anomalies potentielles dues à une mauvaise répartition des échantillons entre les sous-ensembles de test et d'entraînement
Qu'est-ce que la validation croisée ?
Nous allons diviser le dataset en K sous-ensembles de taille égale.
À tour de rôle, chacun des sous-ensembles jouera le rôle de sous-ensemble de test, les K-1 autres sous-ensembles serviront à entraîner le modèle.
Pour chaque configuration entraînement/test on va calculer le score de performance du modèle.
À la fin, on choisira le modèle qui offre la meilleure moyenne des scores sur toutes les configurations entraînement/test.

Utilisons-la pour (re)trouver la valeur optimale de max_depth sur notre dataset d'arbres.
from sklearn.model_selection import GridSearchCVDéfinissons l'espace des valeurs possibles du paramètre :
parameters = {'max_depth':np.arange(2, 30, 2)}On ne précise pas le paramètre lorsque l'on instancie le modèle :
model = DecisionTreeClassifier(
random_state = 808
)On passe le modèle et le dictionnaire des paramètres à GridSearchCV . Le paramètre cv correspond au nombre de sous-ensembles, de splits de la validation croisée. On choisit le plus souvent une valeur autour de cv = 5 .
clf = GridSearchCV(model, parameters, cv = 5, scoring = 'roc_auc_ovr', verbose = 1)
clf.fit(X, y)L'objet clf permet de voir tout de suite…
… la meilleure valeur des paramètres :
clf.best_params_
> {'max_depth': 10}… le meilleur score obtenu :
clf.best_score_
> 0.9364145767567329… et le meilleur modèle :
clf.best_estimator_
> DecisionTreeClassifier(max_depth=10, random_state=808)Attention ! Comme on a choisi 14 valeurs possibles du paramètre max_depth et que l'on fait une validation croisée à 5 plis, on doit donc entraîner 4 x 10 = 70 instances de DecisionTreeClassifier !
En cherchant à optimiser plusieurs paramètres à la fois, on risque de faire exploser le nombre de modèles et donc le temps d'entraînement du classificateur global. Il vaut mieux être circonspect et limiter l'espace des paramètres.
En résumé
La régularisation permet d'éviter que le modèle colle trop aux données d'apprentissage et perde sa capacité d'extrapolation à des données fraîches.
La régularisation prend des formes différentes en fonction des modèles envisagés. On retiendra la profondeur des arbres de décision et les régularisations de type L2 et L1, appelées aussi Ridge et Lasso.
La validation croisée permet de s'affranchir de l'influence des échantillons hors normes en moyennant l'entraînement du modèle sur plusieurs sous-ensembles de test et d'entraînement.
La fonction
GridSearchCVpermet à la fois d'implémenter une validation croisée et de sélectionner les paramètres optimaux du modèle.
Dans le chapitre suivant vous allez découvrir comment construire un excellent modèle à partir de nombreux modèles peu performants, grâce à l'apprentissage ensembliste.
