Comprenez le fonctionnement de Spark
Plongez dans l’architecture de Spark
Pour bien comprendre comment Spark fonctionne, il faut d’abord explorer son architecture. Heureusement, puisque nous avons déjà vu ensemble les différents composants du calcul distribué, vous allez tout de suite vous y retrouver ! Il suffit de donner un nouveau nom à chacun des concepts, et hop, je vous présente l’équipe de travail Spark. Cette équipe est composée de trois acteurs principaux : le Driver, les Executors, et le Cluster Manager. Chacun joue un rôle clé pour que tout fonctionne de manière fluide et efficace. 🚀
Vous vous souvenez du nœud maître, qui coordonne et distribue les tâches? Chez Spark, il s'appelle le Driver. Il agit comme le cerveau de l’application, transformant votre code en un plan d’exécution, qui prend la forme d’un graphe orienté acyclique , ou Directed Acyclic Graph (DAG). Nous reviendrons plus précisément sur ce point dans la section suivante.
Allez, assez parlé du Driver, passons aux Executors. Ce sont les travailleurs du cluster (les nœuds esclaves), exécutant les tâches assignées et retournant les résultats au Driver.
Enfin, le petit dernier, vous l’aurez sûrement un peu moins attendu, j’ai nommé le Cluster Manager. Souvenez-vous, dans la première partie de ce cours, je vous disais:
Le nœud maître doit donc surveiller constamment la mémoire disponible et ajuster les allocations en conséquence.
Et bien, pour Spark, ce n’est pas au noeud maître de se soucier de cela, mais au Cluster Manager. Il joue le rôle de gestionnaire des ressources, allouant la mémoire et le CPU nécessaires aux Executors et au Driver, tout en surveillant l’état du cluster. Ensemble, ces composants permettent à Spark de paralléliser les calculs et de traiter efficacement des volumes massifs de données.
Voici donc ce qui se passe à chaque fois que Spark distribue un calcul pour vous:
Le Driver reçoit votre programme et le transforme en un DAG.
Le Cluster Manager alloue les ressources nécessaires (mémoire, CPU) aux Executors.
Les Executors exécutent les tâches assignées par le Driver et renvoient les résultats.
Le Driver collecte les résultats et les retourne à votre programme.
Avec PySpark, votre point d'entrée pour manipuler cette architecture est l’objet SparkSession. Voici comment le configurer :
from pyspark.sql import SparkSession
# Créer une SparkSession avec une configuration
spark = SparkSession.builder \
.appName("MonAppSpark") \ # Nom de l'application
.master("local[*]") \ # Mode d'exécution (local ou cluster) (ici, local avec tous les cœurs disponibles) (vous pouvez mettre un chiffre à la place de l’étoile pour indiquer le nombre de coeurs à utiliser si vous préférez)
# Configuration de la mémoire
.config("spark.driver.memory", "4g") \ # Mémoire allouée au driver
.config("spark.executor.memory", "8g") \ # Mémoire allouée à chaque executor
# Vous pouvez ajouter à cela autant de points de config que vous souhaitez.
# Quand vous avez mis toutes les points de config souhaités, créer ou récupérer la session Spark
.getOrCreate()Pas de souci si vous ne connaissez pas encore les RDD ! On va découvrir ça ensemble.
Découvrez le DAG et les RDD, les piliers de la performance
Maintenant que vous connaissez les acteurs principaux de l’architecture Spark, plongeons dans son fonctionnement interne. Spark repose sur deux concepts clés : le DAG (Directed Acyclic Graph) et les RDD (Resilient Distributed Datasets). Ces deux éléments sont les piliers qui permettent à Spark d’être aussi rapide et efficace. 🚀
Le DAG (ou graphe orienté acyclique) est le plan d’exécution que Spark crée pour organiser les tâches de votre programme.
Voici un exemple de DAG:
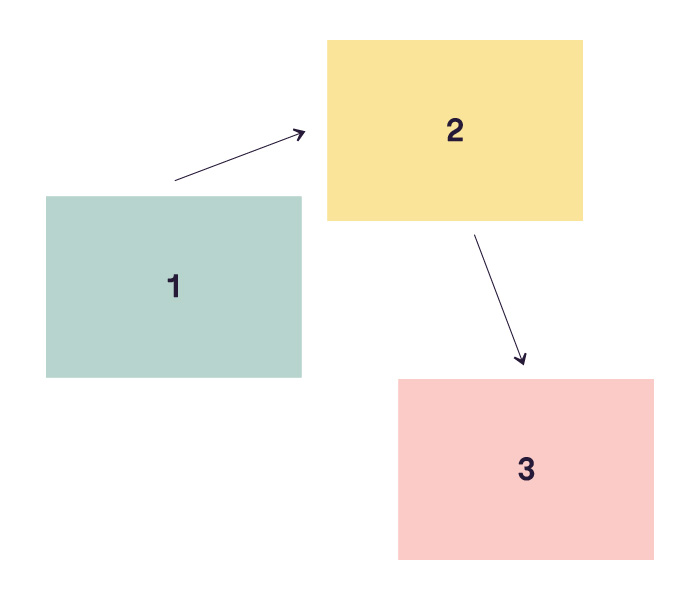
Le graphe acyclique est représenté par les rectangles et les flèches que vous voyez ici. On peut également parler de nœuds et d'arêtes. On voit bien qu’il y a un sens à respecter, le graphe est donc orienté. Et le plus important… on ne peut pas tourner en rond ! Bah oui, vous ne voudriez pas que vos nœuds fassent la même chose en boucle sans s’arrêter 😱. Du coup, tout s’arrête quand on arrive à l'étape 3 😌. Le graphe doit absolument être sans cycle (acyclique) pour que tout se passe bien. Au final, c’est comme une recette de cuisine : chaque étape est une tâche à accomplir, et les flèches représentent l’ordre dans lequel ces tâches doivent être exécutées.
Pourquoi est-il si important ?
Il permet à Spark d’optimiser l’exécution des tâches en évitant les calculs redondants.
Il garantit que les tâches sont exécutées dans le bon ordre, sans cycles ni boucles infinies (d’où le terme acyclique).
Il facilite la tolérance aux pannes : si une tâche échoue, Spark peut la rejouer à partir du DAG.
Les RDD sont la structure de données fondamentale de Spark. Ils représentent des collections d’objets distribuées sur le cluster et immutables (c’est-à-dire qu’ils ne peuvent pas être modifiés après leur création). Chaque RDD est divisé en partitions, ce qui permet à Spark de paralléliser les calculs.
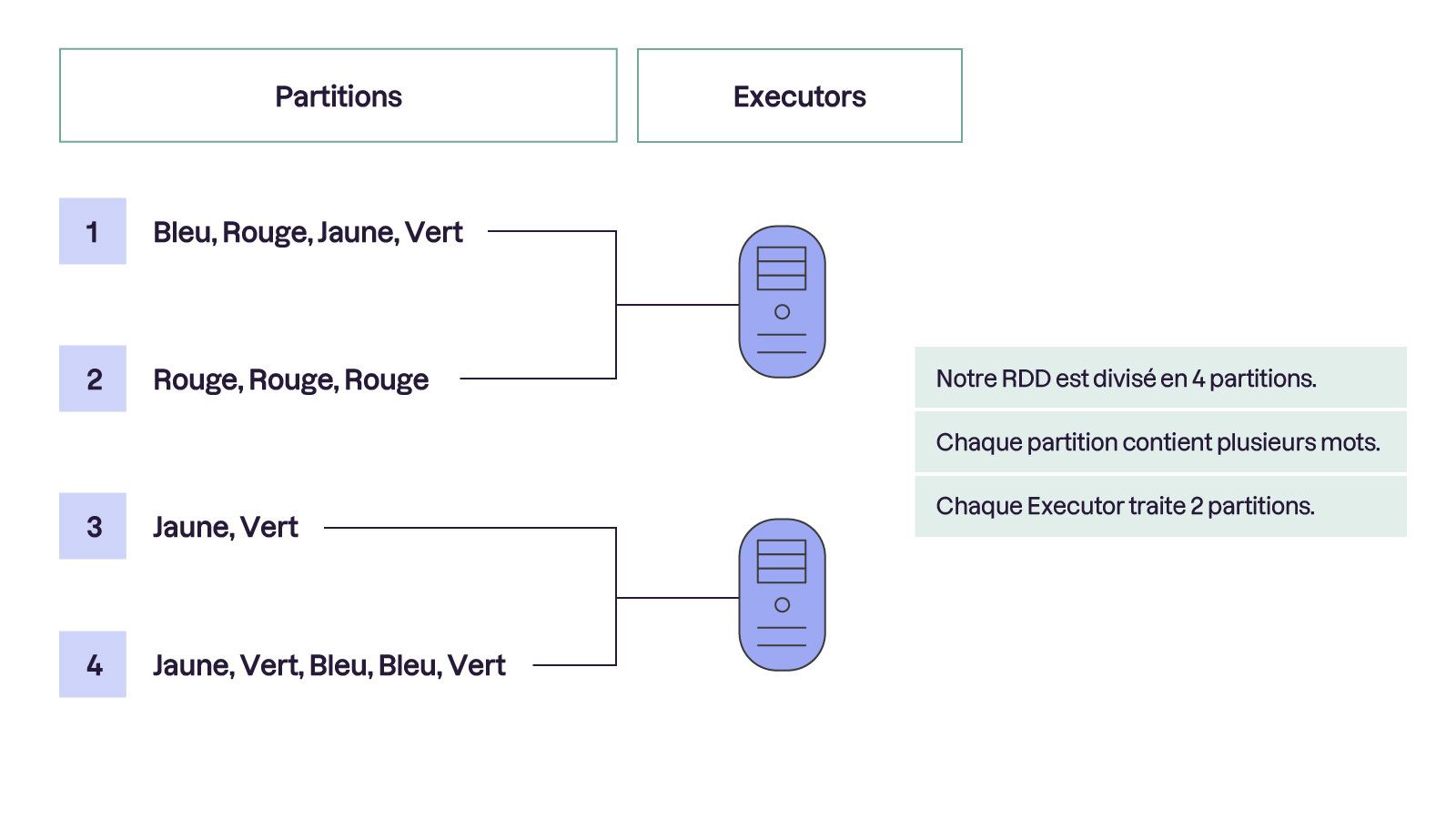
Et voici comment faire des partitions avec votre RDD :
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName(“appName”).setMaster(“Local”)
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], numSlices=4) # Crée 4 partitions
rdd_repartitioned = rdd.repartition(2) # Réduit à 2 partitionsA ce stade, nous comprenons donc que Spark va utiliser le DAG comme une recette de cuisine lui permettant de savoir quoi faire, étape par étape, pour chaque partition du RDD.
Avant cela cependant, pour faire vos RDD, vous aurez surtout besoin de charger vos données avec Spark. Allez, voyons ça ensemble ! 📈
Chargez vos données avec Spark
Que vous travailliez avec des fichiers CSV, JSON, Parquet ou même des bases de données SQL, Spark a tout prévu pour vous 🤓. Ces formats couvrent la grande majorité des besoins, que vos données soient structurées ou semi-structurées, et ils sont donc tous inclus dans Spark.
Pour l'essentiel, voici comment vous pouvez facilement charger vos données avec Spark:
Vos données CSV:
# Charger un fichier CSV
csv_df = spark.read.csv("chemin/vers/fichier.csv", header=True, inferSchema=True)Vos données JSON:
# Charger un fichier JSON
json_df = spark.read.json("chemin/vers/fichier.json")Vos données Parquet:
# Charger un fichier Parquet
parquet_df = spark.read.parquet("chemin/vers/fichier.parquet")Vos données SQL:
csv_df.createOrReplaceTempView("ma_table")
result = spark.sql("SELECT colonne, AVG(valeur) FROM ma_table GROUP BY colonne")
result.show()Maintenant que vos données sont chargées dans un DataFrame, il est temps de leur donner vie grâce aux transformations et aux actions qui façonneront votre DAG. Prêt à explorer ces opérations clés pour orchestrer l'exécution de votre workflow Spark ? Allons-y ! 🚀
Comprendre les Transformations et Actions
Plus précisément, les transformations sont les opérations qui définissent les étapes du DAG. Elles décrivent comment les données doivent être modifiées ou transformées, mais elles ne sont pas exécutées immédiatement. Chaque transformation crée un nouveau RDD (ou Dataframe / Dataset) à partir d'un RDD existant. Et oui, souvenez-vous, un RDD est immuable et donc non modifiable par une transformation ! 🤓
Voici quelques exemples de transformations :
map: Applique une fonction à chaque élément du RDD.filter: Filtre les éléments selon une condition.groupBy: Regroupe les éléments par clé.join: Combine deux RDD en fonction d'une clé commune.
Les actions sont les opérations qui déclenchent l'exécution du DAG. Elles demandent à Spark de calculer un résultat et de le retourner au programme. Les actions ne font pas partie des étapes du DAG, mais elles sont le point de départ de son exécution.
Exemples d'actions :
count: Compte le nombre d'éléments dans le RDD.collect: Récupère tous les éléments du RDD sur le Driver.saveAsTextFile: Sauvegarde les éléments du RDD dans un fichier.show: Affiche les éléments du RDD (ou DataFrame).
Mais pourquoi le DAG ne s'exécute-t-il pas immédiatement ?
Parce qu’il est comme vous, fin moi, fin… bref, fainéant quoi ! Spark utilise une évaluation dite “paresseuse” (lazy evaluation). Autrement dit, si on ne lui dit pas clairement et explicitement de s’activer…, bah il … réfléchit 🤔. En effet, Spark passe son temps à essayer d'optimiser le DAG en regroupant les transformations et en évitant le plus possible les calculs inutiles. Donc sa fainéantise nous est bien utile, alors que la nôtre… 😕 😉.
Voici un petit code illustrant tout ce que nous venons d’énoncer:
# Créer un RDD à partir d'une liste de nombres
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# Appliquer des transformations
rdd_mapped = rdd.map(lambda x: x * 2) # Transformation 1 : Multiplier chaque élément par 2
rdd_filtered = rdd_mapped.filter(lambda x: x > 10) # Transformation 2 : Filtrer les éléments > 10
rdd_grouped = rdd_filtered.groupBy(lambda x: x % 2) # Transformation 3 : Grouper par pair/impair
# Appeler une action
result = rdd_grouped.count() # Action : Compter le nombre de groupesChaque étape (map, filter, groupBy) est un nœud dans le DAG, et l'action count déclenche l'exécution du DAG.
Manipulez des images avec PySpark
Que diriez-vous d’un petit exercice? Super idée ! 🚀 (Oui, je sais… 😉) Rien de mieux qu’un petit exercice pratique pour se familiariser avec PySpark. Et pour l’occasion, prenons l’un des jeux de données les plus connus de Kaggle, à savoir: Dogs vs. Cats. 📸✨
Voici nos objectifs:
Charger des images de chats et de chiens.
Extraire des caractéristiques à l’aide d’un modèle de machine learning pré-entraîné (transfert learning).
Entraîner un modèle de classification automatique pour prédire si l’image contient un chat ou un chien.
Notez les cellules sous les sous-titres “calcul distribué”. Et bien c’est là que la “magie” de Spark entre en jeu. Et je reviendrai plus en détails sur ce qui se passe dans les parties suivantes de ce cours. Mais voilà, vous avez réalisé votre premier calcul distribué !
Reverrons le code ensemble dans ce screencast :
Vous voyez, rien de compliqué ! Si vous avez l’habitude de faire du machine learning en python, et bien vous n’avez quasiment rien à changer par rapport à ce que vous savez déjà faire. C’est l’un des avantages de PySpark, c’est de vous permettre de faire du calcul distribué sans que vous ayez à y réfléchir plus que ça.
Allez, pour célébrer l’occasion, je vous propose de refaire exactement la même chose mais avec vos scanners médicaux. Prêt ?
À vous de jouer

Vous vous souvenez de l'hôpital qui souhaite centraliser l’analyse des scans médicaux. Et bien, il vient de vous contacter pour faire un premier poc pour prouver votre capacité à catégoriser automatiquement ces scans. Au passage, faites vous la main en identifiant les différentes étapes du DAG et changez le nombre de partitions pour voir ce qui change.
Allez, au travail !
Voici les étapes pour réussir :
Trouvez un dataset. Vous pouvez utiliser un dataset public de scanners médicaux comme Chest X-Ray Images (pour des radiographies de la poitrine) par exemple.
Téléchargez le dataset et chargez une petite partie des images dans votre environnement de travail.
Utilisez PySpark pour distribuer le chargement des images ainsi que toute autre étape du travail qui pourrait constituer un goulot d’étranglement lorsque le volume d’image augmentera.
Vous pouvez utiliser un modèle simple comme une régression logistique ou un arbre de décision avec les caractéristiques extraites. Pensez à diviser les données en jeux d’entraînement et de test.
Voici un indice : vous aurez besoin de cet import supplémentaire =>
from pyspark.ml.feature import PCA
# écrivez votre code ici pour compresser les imagesMaintenant, relancer le notebook que vous avez réalisé plus tôt pour classifier automatiquement des scanners médicaux et essayer d’identifier les différentes étapes du DAG. Changer le nombre de partitions et voyez ce qui change.
Pourquoi ne pas essayer de compresser vos images à l’aide d’une ACP avant de les sauvegarder ? Là aussi, voyez ce qui change en termes de DAG.
En résumé
L’architecture de Spark repose sur trois acteurs principaux : le Driver (coordination), les Executors (exécution des tâches), et le Cluster Manager (gestion des ressources).
Le DAG est le plan d’exécution de Spark, qui permet d’organiser les tâches de manière efficace et d’optimiser les calculs.
Les RDD sont la structure de données fondamentale de Spark, immuables et distribuées en partitions pour faciliter le traitement parallèle.
Spark utilise des transformations (définition des étapes) et des actions (déclenchement des calculs) avec une évaluation paresseuse pour maximiser les performances.
Et voilà, vous maîtrisez maintenant les rouages internes de Spark ! Prochaine étape : vos gains de performances ! 🚀
