Votre objectif en tant que Data Engineer est clair. Vous allez devoir ingérer (ou collecter), centraliser, transformer et présenter les données qu'on vous a fournies pour en faire un véritable levier stratégique. Et tout ça grâce à l'outil DuckDB.
Mais avant de passer à l'action, prenez un instant pour poser les bases avec l'exploration de certains concepts comme OLAP, OLTP et in-process.
Découvrez DuckDB et ses objectifs
Optez pour une approche scale-up
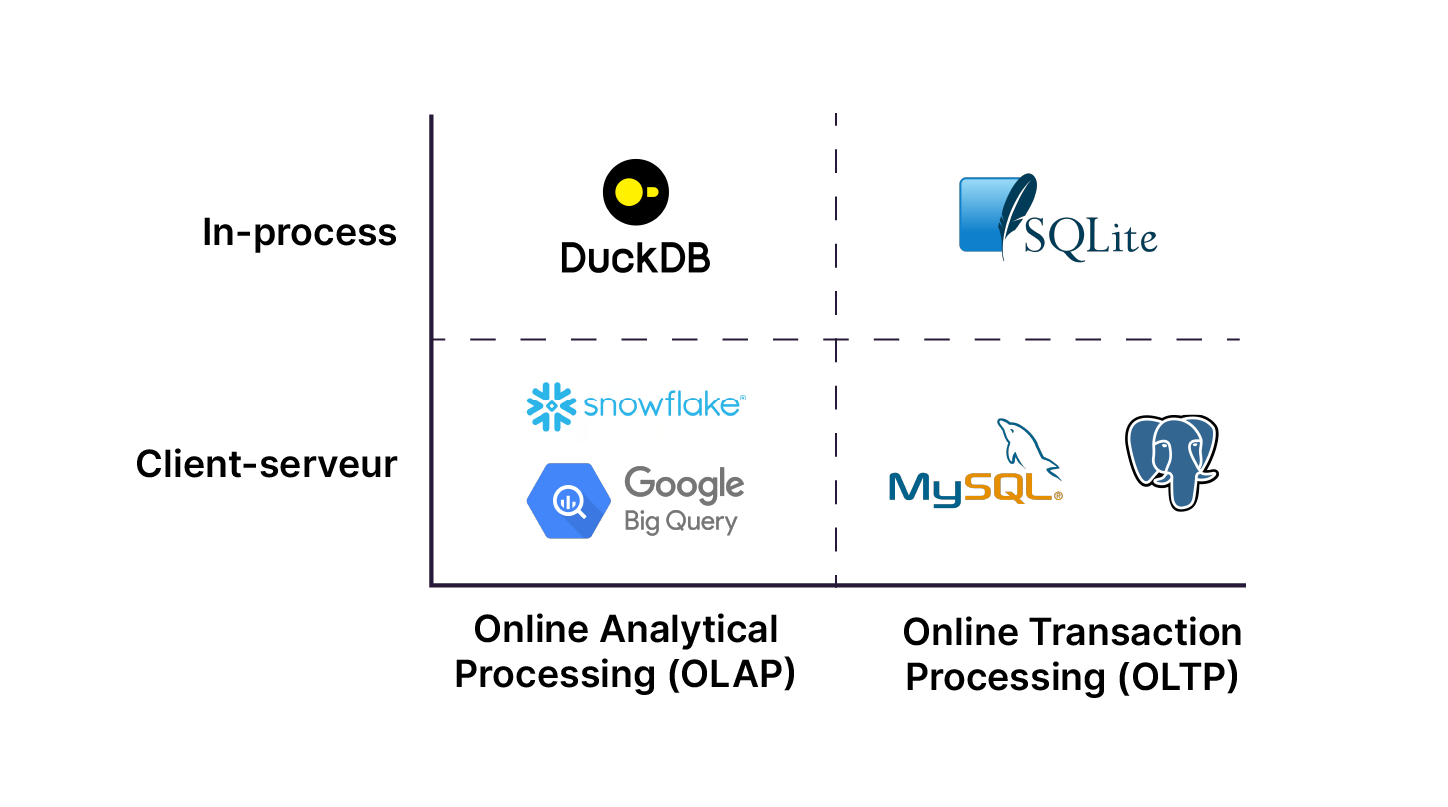
DuckDB est une base de données analytique open source relationnelle conçue pour des analyses rapides et efficaces sur des jeux de données allant de petits à grands volumes. On appelle cette base de données OLAP (Online Analytical Processing). Quelle est alors la différence entre OLAP et OLTP (Online Transactional Processing) ? Voici un schéma qui liste les principales différences entre les deux approches.
Principales différences entre OLAP et OLTP
OLAP est optimisé pour l’analyse des données, permettant de traiter de grandes quantités d’informations historiques et agrégées. Cette base de données est principalement utilisée pour la génération de rapports, l’aide à la décision et l’analyse de tendances. Les données y sont stockées en colonnes, ce qui facilite les requêtes analytiques complexes, mais avec une latence plus élevée en raison du traitement par lots. À l’inverse, OLTP est conçue pour gérer des transactions en temps réel, comme celles d’un système bancaire ou d’un site e-commerce. Elle privilégie la rapidité et la concurrence élevée, avec un stockage des données en lignes et une forte normalisation afin d’optimiser les opérations fréquentes. En résumé, la base de données OLAP est idéale pour l’analyse stratégique, tandis qu’OLTP est conçue pour la gestion rapide et efficace des transactions quotidiennes.
Question bulle : Mais les jeux de données peuvent aller jusqu’à quelle taille exactement ?
Eh bien, à ce jour, plus de 83 % des requêtes SQL sont effectuées sur des jeux de données inférieurs à 1 Tb (Terabyte ou Teraoctet en français) , selon des données partagées par AWS. Parallèlement, une tendance émerge avec l’idée que “big data is dead”, soulignant qu’avec l’évolution des ordinateurs, les systèmes complexes distribués sont souvent inutiles.
Traditionnellement, pour faire face à ces volumes massifs de données, les entreprises optent pour le scale-out, où plusieurs machines de même puissance sont ajoutées en parallèle pour effectuer les calculs. DuckDB adopte une approche différente, celle du scale-up, qui consiste simplement à utiliser une machine plus puissante. Par exemple, aujourd’hui, il est possible de louer sur AWS une machine avec 448 cœurs et 24 Gb (Gigabyte ou Gigaoctet en français) de RAM ! Le scale-up simplifie l’architecture et élimine la complexité liée aux réseaux et à la gestion distribuée des données.
Maximisez la performance avec une base de données “in-process”
DuckDB est une base de données où tout fonctionne directement dans le processus de votre application (“in-process”). Si les limites de la mémoire de la machine sont atteintes, il est possible de transformer les données et de les écrire sur un disque, ce qui permet de traiter des volumes supérieurs à la mémoire vive de l’ordinateur. Par exemple, traiter 1 Gb sur une machine avec 64 Gb de RAM est tout à fait possible ! Comme tout se passe en mémoire, DuckDB est très facile à installer et ne nécessite pas une architecture classique client-serveur. Voici un tableau qui regroupe les principales bases de données in-process et client-serveur.
Principales bases de données in-process et client-serveur
Comprenez les avantages de DuckDB
Comme mentionné précédemment, DuckDB est une base de données open source sous une licence MIT très permissive, ce qui la rend accessible. Elle n’implique aucun coût logiciel, et vous ne payez que les ressources de calcul utilisées par votre machine locale ou votre serveur.
De plus, en tant que base de données en mémoire, elle peut être installée partout, sur votre ordinateur portable, smartphone, serveur cloud, ou même fonctionner directement dans le navigateur via Wasm (WebAssembly). C’est une technologie qui permet de faire tourner du code rapide et performant dans un navigateur, comme si c’était une application native.
DuckDB est compatible avec plusieurs langages de programmation (Python, R, JavaScript, Golang, Rust, C++, etc.). Sur Python ou R, par exemple, DuckDB se présente comme une simple librairie à installer. Elle s’exécute alors dans le même processus que votre code initial.
Écrite en C++, DuckDB intègre toutes les dépendances nécessaires pour manipuler les données grâce à ses extensions natives. Elle peut lire et écrire depuis des fichiers JSON, CSV, Parquet ou Delta Lake. Elle s’intègre aussi facilement avec des services de stockage comme AWS S3 ou se connecte directement à des bases de données MySQL et PostgreSQL.
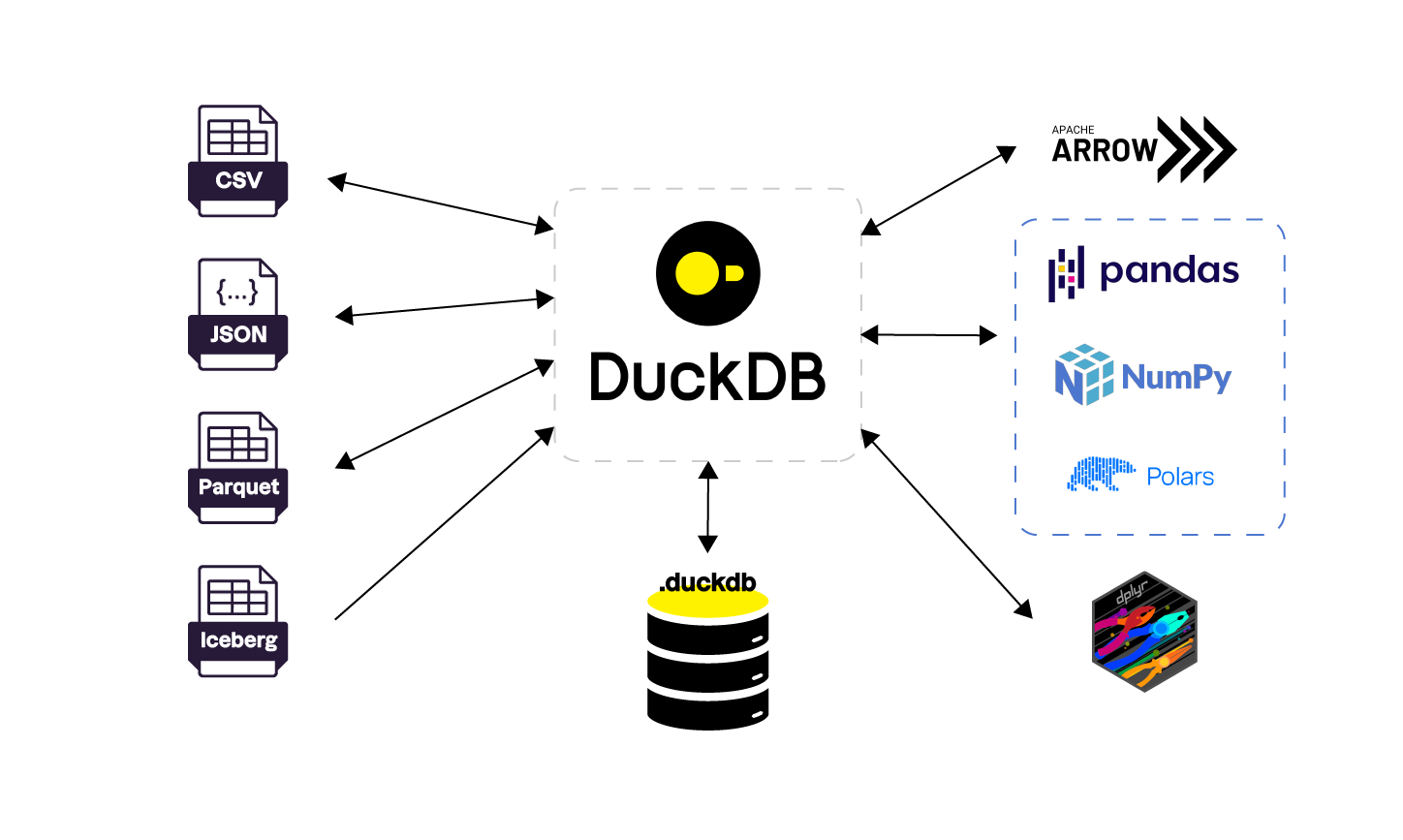
Enfin, DuckDB dispose également de son propre format de fichier interne : un fichier unique qui contient toutes les tables de données ainsi que leurs métadonnées, offrant un moyen compact, portable et optimisé pour stocker et partager des bases de données complètes sans nécessiter d’infrastructure supplémentaire. Le schéma ci-dessous illustre les formats d'entrée et de sortie pris en charge, ainsi que les interactions possibles avec diverses bibliothèques. En entrée, on peut lire et écrire des fichiers de stockage (JSON, CSV, Parquet, Iceberg), et échanger directement des données en mémoire avec des outils comme Arrow, Pandas et Polars.
Schéma intégration DuckDB
Installez DuckDB
DuckDB dispose d’un CLI (interface en ligne de commande) utilisable sous Windows, macOS et Linux. Le CLI se présente sous la forme d’un seul fichier binaire, prêt à être utilisé pour traiter vos données. Cette solution est pratique !
Dans le cadre de votre mission, vous allez installer et utiliser DuckDB via le CLI. Mais vous pouvez très bien le faire aussi avec Python ou une interface cloud (MotherDuck), qui sont les deux autres options d’interfaces les plus populaires pour interagir avec DuckDB.
Option 1 : Installez DuckDB via le CLI
Pour utiliser le CLI de DuckDB sur Linux ou macOS, vous avez deux options :
1. Utiliser un gestionnaire de paquets : Installez DuckDB directement via un gestionnaire de paquets comme brew sur macOS. Voici la commande BASH à exécuter :
brew install duckdb
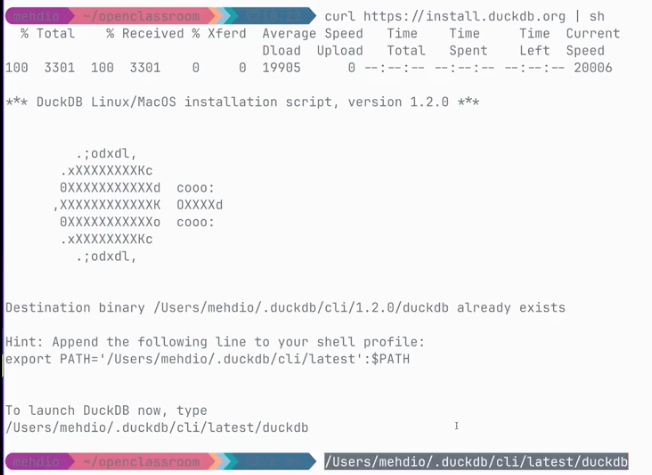
2. Exécuter le script d’installation fourni par DuckDB via votre terminal :
curl install.duckdb.org | bash
3. Une fois l’installation faite, vous pouvez lancer un processus DuckDB via duckdbet exécuter des requêtes SQL comme par exemple :
SELECT'world'asworld;
Nous allons utiliser cette première option pour notre mission. Voici à quoi l'installation devrait ressembler sur votre ordinateur :
Capture d'écran de l'installation de DuckDB
Option 2 : Installez DuckDB via Python
1. Installez la librairie DuckDB en exécutant la commande suivante dans votre terminal :
pip install duckdb
2. Pour démarrer une session DuckDB, vous pouvez utiliser :
import duckdb
conn = duckdb.connect()
L'objet conn peut maintenant être utilisé pour exécuter des requêtes SQL comme :
conn.sql('SELECT 'world' as world;')
Option 3 : Utiliser DuckDB via MotherDuck UI
Il existe une troisième option qui est MotherDuck. C’est un service cloud DuckDB qui permet d’utiliser DuckDB directement via l’interface d’utilisateur MotherDuck. Vous pouvez créer un compte gratuitement et utiliser le notebook SQL directement dans votre navigateur.
Interface de MotherDuck
À part l’installation et l’initialisation de la connexion à DuckDB, l'utilisation de l'outil repose principalement sur SQL, ce qui en standardise et simplifie l'usage. Durant l’installation, plusieurs options sont disponibles pour s’adapter à différents environnements. La liste ci-dessous en donne un aperçu :
Depuis un exécutable local :./duckdb.
Avec Python :pip install duckdb.
Dans un projet Rust :cargo add duckdb.
Pour Node.js :npm install duckdb.
D’autres méthodes d’installation existent selon les langages et environnements utilisés :
En R, DuckDB peut être installé avecinstall.packages('duckdb').
En Java, il est disponible sous la dépendanceorg.duckdb:duckdb_jdbcvia Maven ou Gradle.
Sur le web, DuckDB peut être utilisé avec WebAssembly.
Il est également compatible avec plusieurs connecteurs et langages via ODBC, ADBC, et bien d’autres.
En résumé
DuckDB est une base de données analytique open source OLAP conçue pour traiter efficacement des requêtes sur de grandes quantités de données, contrairement aux bases transactionnelles OLTP optimisées pour les mises à jour fréquentes et en temps réel.
DuckDB est facile à installer grâce à une seule bibliothèque intégrant toutes ses dépendances et fonctionne sans configuration complexe.
Contrairement aux bases de données distribuées qui adoptent une approche "scale-out", DuckDB privilégie une approche "scale-up", exploitant toute la puissance d’une seule machine pour simplifier l'architecture et améliorer les performances.
Le fonctionnement en mode "in-process", permet une exécution directement dans le processus de l'application sans nécessiter un serveur dédié, rendant son installation et son utilisation très légères et performantes.
DuckDB est compatible avec plusieurs langages de programmation (Python, R, JavaScript, C++, etc.), et peut lire et écrire divers formats de fichiers (CSV, Parquet, JSON, Delta Lake), facilitant ainsi son intégration dans différents environnements de données.
Vous pouvez installer DuckDB via trois options : le CLI (installation via un package manager ou script), Python pip install duckdb, ou MotherDuck UI, un service cloud permettant d'exécuter DuckDB directement en ligne.
Passons maintenant à l’action et faisons quelques premières requêtes.