Découvrez les origines du NoSQL
C'est quoi le NoSQL ?
En synthèse, le NoSQL (Not Only SQL) est une alternative aux bases de données relationnelles traditionnelles, qui a été conçue pour répondre aux défis de la gestion de données à grande échelle.
Limites des bases de données relationnelles
Revenons sur les limites évoquées dans la vidéo des bases de données relationnelles :
Difficultés à l'échelle : problèmes de performance et complexité accrue sur de grands volumes de données
Contraintes de schéma rigide : nécessité de définir la structure des données à l'avance, rendant difficiles les évolutions rapides
Problèmes de distribution : complexité pour partitionner et répliquer les données sur plusieurs serveurs
Performances limitées pour certains types de requêtes : notamment les jointures complexes sur de grandes tables
Inadaptation aux données non structurées ou semi-structurées : par exemple les formats JSON, XML ou des contenus multimédias
Complexité du modèle : les garanties de transactions peuvent devenir un goulot d'étranglement pour les systèmes à haute disponibilité
Inadéquation avec certains modèles de données : relations complexes ou hiérarchiques difficiles à représenter efficacement
Coûts de maintenance élevés : notamment pour les systèmes commerciaux à grande échelle
Le NoSQL assouplit les contraintes du modèle relationnel des systèmes de gestion de base de données relationnelles (SGBDR) pour dépasser ces limites et gérer de grands volumes de données.
Avant les bases de données NoSQL, les SGBDR s’attachaient à respecter un modèle de transactions qu’on appelle ACID (Atomicité, Cohérence, Isolation, Durabilité) assurant toujours l’intégrité de la base de données. Prenons l’exemple de la gestion d’un compte bancaire :
Propriétés ACID des bases de données traditionnelles | Exemple sur la gestion d’un compte bancaire : |
Atomicité : Une transaction s’effectue entièrement ou pas du tout | Lors d’un virement, la transaction doit s’accomplir intégralement ou pas du tout |
Cohérence : Le contenu d’une base doit être cohérent au début et à la fin d’une transaction | La somme virée doit correspondre au débit mémorisé dans la base |
Isolation : Les modifications d’une transaction ne sont visibles/modifiables que quand celle-ci a été validée | Deux opérations simultanées de deux personnes sur un compte commun ne sont visibles qu’après avoir été validées |
Durabilité : Une fois la transaction validée, l’état de la base est permanent | Le virement doit correspondre à un débit mémorisé dans la base |
Avec le NoSQL, un nouveau modèle de transactions de base de données appelé BASE a émergé. Regardons les différences entre ce modèle et le modèle ACID qui prédominait jusqu’à là :
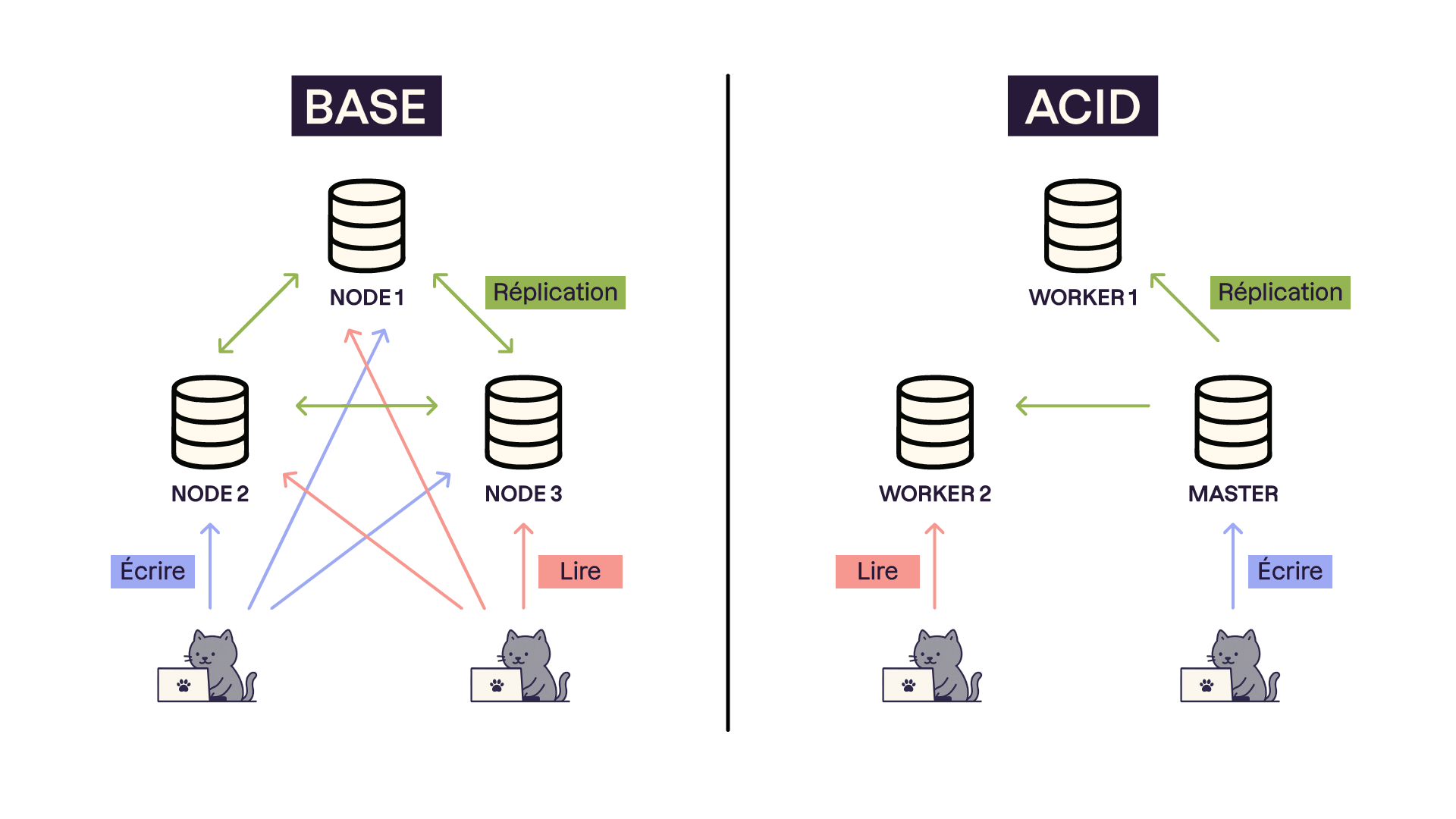
Propriétés BASE des bases de données NoSQL | Exemple sur la gestion d’un compte bancaire : |
Basically Available : quelle que soit la charge de la base de données (données/requêtes), le système garantit un taux de disponibilité de la donnée | Vous obtenez toujours une réponse immédiate lorsque vous consultez votre solde, mais celle-ci peut ne pas être à jour en raison de retards dans la synchronisation des données. |
Soft-state : La base peut changer lors des mises à jour ou lors d'ajout/suppression de serveurs. La base NoSQL n'a pas à être cohérente à tout instant | L’état de la base peut changer avec le temps, car les données ne sont pas immédiatement synchronisées. Par exemple, après un virement, deux interfaces différentes (comme une application mobile et un relevé en ligne) pourraient afficher des informations différentes pendant un court laps de temps. |
Eventually consistent : À terme, la base atteindra un état cohérent | Après un virement, le solde et les transactions peuvent ne pas être à jour instantanément, mais après un certain délai, les données seront cohérentes et reflèteront correctement le transfert. |
Le Théorème de CAP
Les bases de données NoSQL relâchent donc certaines contraintes pour gérer le passage à l’échelle dans le volume des données. Eric Brewer, ancien professeur à Berkeley et vice-président chez Google, a formulé ainsi le dit "théorème de CAP" :
Dans toute base de données, vous ne pouvez respecter au plus que 2 propriétés parmi les suivantes :
la cohérence (Consistency en anglais),
la disponibilité (Availability en anglais),
la distribution (Partition Tolerance en anglais).
Cette impossibilité d’avoir ces 3 propriétés réunies s'illustre assez facilement. Regardons ensemble avec un schéma :
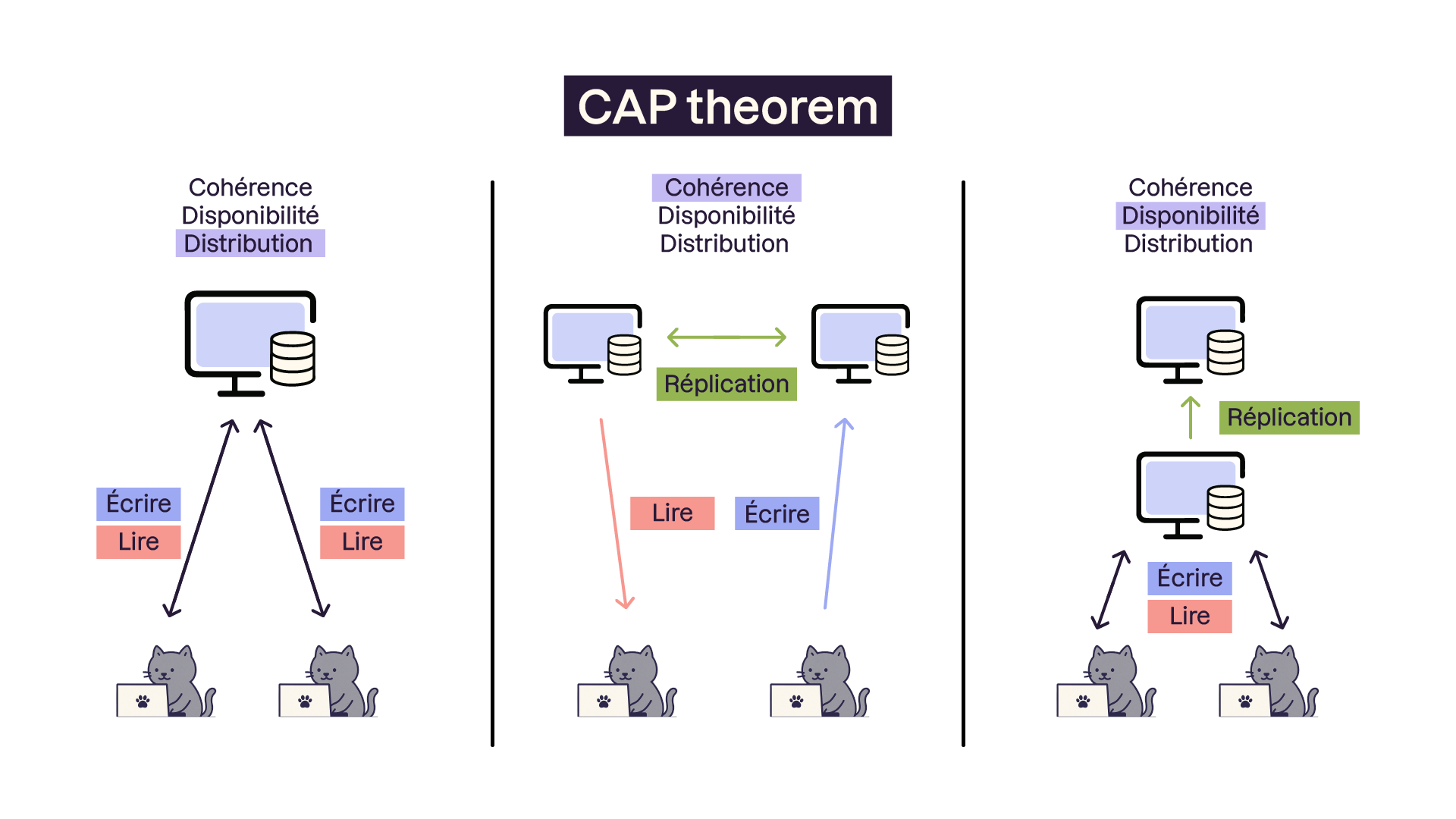
Analysons ce théorème de CAP et voyons pourquoi nous ne pouvons pas satisfaire plus que 2 propriétés à la fois avec nos bases de données :
Sur l’image à gauche nous avons favorisé les propriétés (Cohérence-Disponibilité). Les SGBDR classiques sont ici. Deux utilisateurs voient la même version de la base de données et sans délai d'attente. Par contre nous n’avons pas de distribution des données, donc si le serveur tombe en panne par exemple… et bien nous n’avons plus accès à nos données. L’absence de distribution a plusieurs autres défauts comme les limites de performances si les deux utilisateurs sont dans 2 localisations géographiques éloignées par exemple. Nous verrons cela plus tard dans ce cours en détail.
Sur l’image au centre nous avons privilégié les propriétés (Disponibilité-Distribution). Ici l’objectif est de fournir un temps de réponse ultrarapide tout en distribuant les données pour se protéger des pannes (entre autres). Les mises à jour sont asynchrones sur le réseau, et la donnée est "cohérente in fine" (c’est-à-dire qu’à la fin du cycle d’exploitation de la base de données elle sera mise à jour, mais elle ne l’est pas à tout moment, en temps réel). On est donc très rapide car on n’attend pas de synchroniser les données entre nos serveurs, mais on fait un compromis sur la cohérence.
Sur la dernière image nous avons favorisé les propriétés (Cohérence-Distribution). Nos données sont sur plusieurs serveurs pour garantir une tolérance aux pannes et nous souhaitons qu’à tout moment la réplication soit parfaitement à jour (pour ne pas perdre les données mises à jour par un utilisateur sur le premier serveur si celui-ci tombe en panne par exemple). C’est super ! Mais le point noir dans ce cas, c’est que nous devons attendre que les réplications se fassent. La gestion de cette cohérence nécessite des synchronisations, et du coup des délais de latence dans les temps de réponse (i.e. les utilisateurs attendent que la réplication soit à jour avant d’obtenir des réponses du serveur).
Voyons maintenant les différents types de bases de données NoSQL et la façon dont elles privilégient l’une ou l’autre des propriétés pour gérer les grands volumes de données.
Bases de données NoSQL
Regardons plus en détail les différents types de bases de données NoSQL.
Bases de données orientées colonnes :
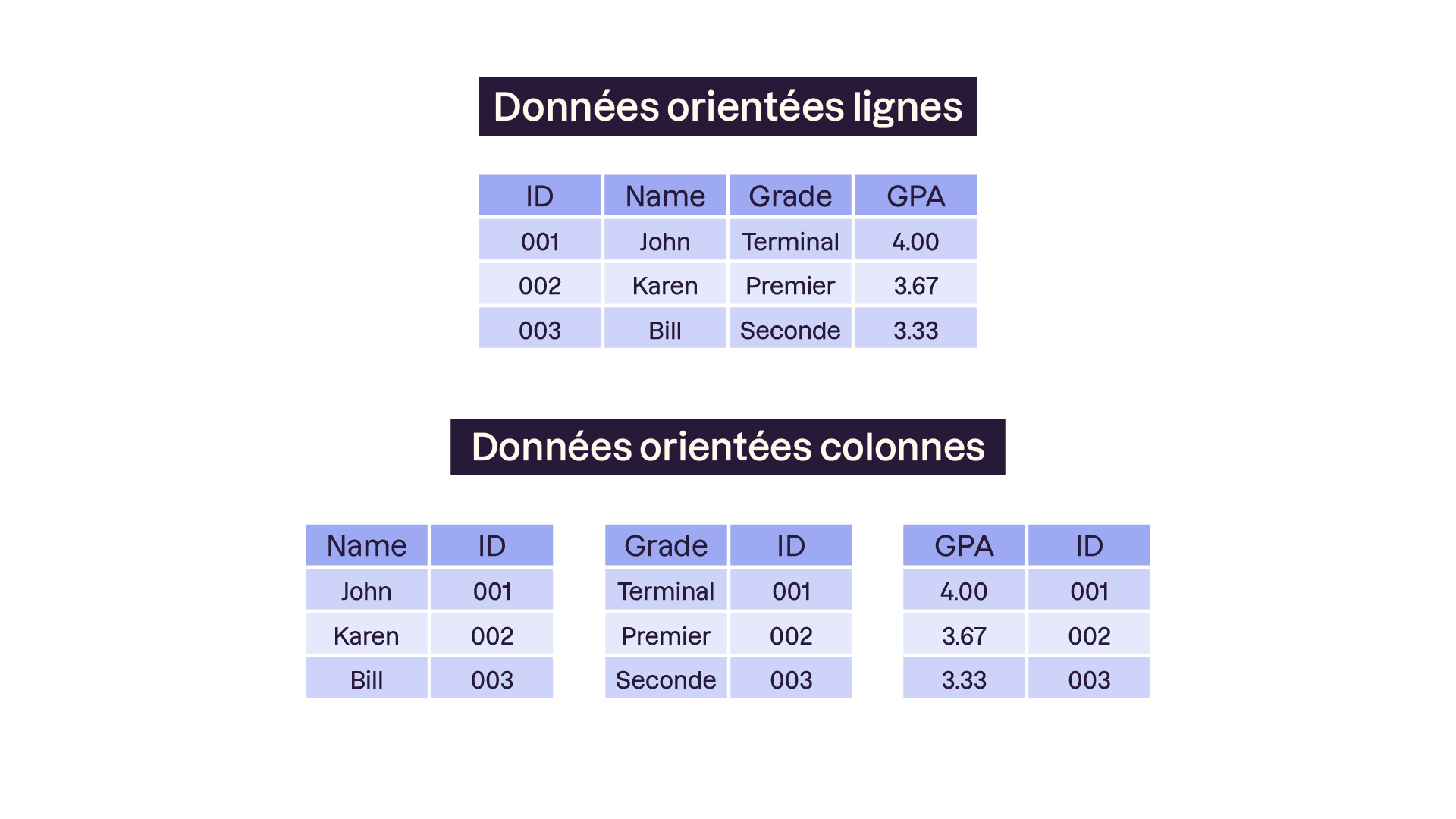
Les bases de données orientées colonnes inversent “notre logique classique” de classement des données par ligne. Sur l’image nous avons l’habitude de créer un tableau avec sur chaque ligne toutes les informations relatives à un étudiant. En divisant les colonnes en plusieurs tableaux qu’on va relier entre eux (ici par l’ID), les bases de données orientées colonnes obtiennent des performances de lecture exceptionnelles sur des données massives. Ces bases privilégient la cohérence (Consistency) et la tolérance au partitionnement (Partition tolerance).
Elles présentent les caractéristiques suivantes :
Excellentes performances pour les requêtes analytiques
Haute compression des données
Scalabilité horizontale massive
Adaptées aux données massives (Big Data)
Si vous répondez oui aux questions suivantes vous avez probablement besoin de choisir ce type de base de données :
Est-ce que je travaille sur des analyses de données à grande échelle ?
Ai-je besoin de stocker des séries temporelles ?
Exemple d’application : Google BigTable, pilier des services cloud de Google à l’échelle Planétaire
Développé en interne dès 2004, Google BigTable alimente des services critiques comme Google Analytics, Google Earth et Google Search. Conçu pour manipuler des pétaoctets de données distribuées sur des clusters globaux, ce système combine le modèle orienté colonnes avec un indexage temporel, permettant des mises à jour en temps réel sur des milliards d’entrées.
Pour l’application Google Earth, BigTable gère les tuiles cartographiques et les métadonnées associées (résolution, source d’acquisition), avec des latences inférieures à 10 ms pour 99 % des requêtes. La compression avancée des colonnes réduit l’espace de stockage de 40% comparé à une approche relationnelle avec un stockage en ligne classique.
Bases de données clés-valeurs:
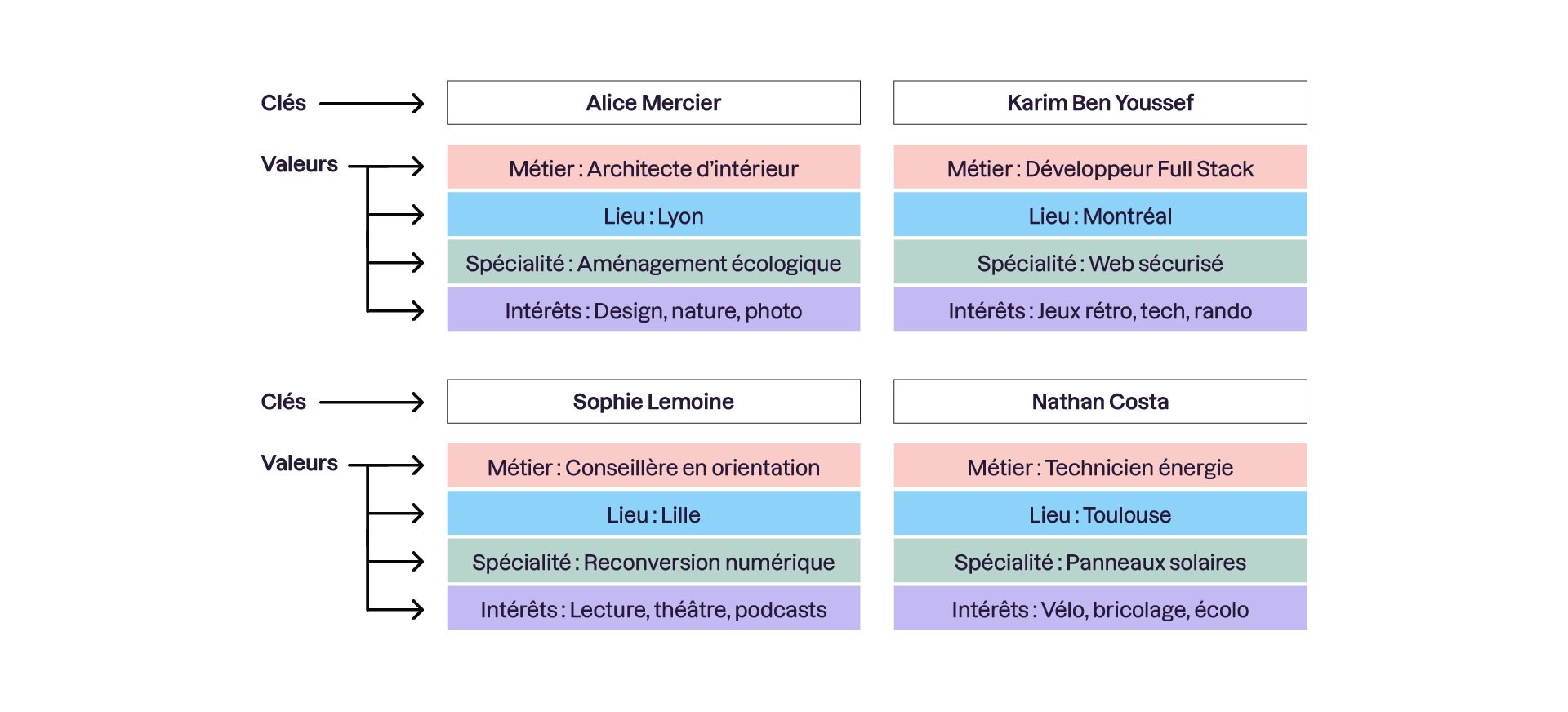
Ces bases utilisent un principe de stockage ultra-simple avec des couples clé-valeur dans un tableau de hash où chaque clé est unique.
Vous cherchez une donnée ? Renseignez sa clé et vous l'obtenez instantanément! Elles privilégient également la cohérence (Consistency) et la tolérance au partitionnement (Partition tolerance).
Elles présentent les caractéristiques suivantes :
Structure simple et performances élevées
Scalabilité horizontale excellente
Fonctionnalités de requêtage limitées
Pas de relation entre les données
Si vous répondez oui aux questions suivantes vous avez probablement besoin de choisir ce type de base de données :
La rapidité d’accès est-elle une priorité absolue ?
Mon application nécessite-t-elle principalement un système de cache ou de gestion de sessions ?
Exemple d’application : Amazon DynamoDB, au coeur des Applications Temps Réel à Échelle Globale
DynamoDB, service managé d’Amazon Web Services, alimente des applications critiques comme Amazon.com et Twitch. Conçue pour absorber plus d’un million de requêtes par seconde avec une latence inférieure à 10 ms, cette base clé-valeur gère les paniers d’achats, les sessions utilisateur et les leaderboards de jeux vidéo en temps réel.
Son architecture garantit une disponibilité de 99,999 % grâce à la réplication synchrone des données sur au moins trois centres de données. Un cas d’usage emblématique concerne les ventes flash : lors du Prime Day 2024, DynamoDB a traité 89 millions de transactions/minute tout en maintenant des coûts 40 % inférieurs à une architecture relationnelle classique.
Bases de données orientées documents :
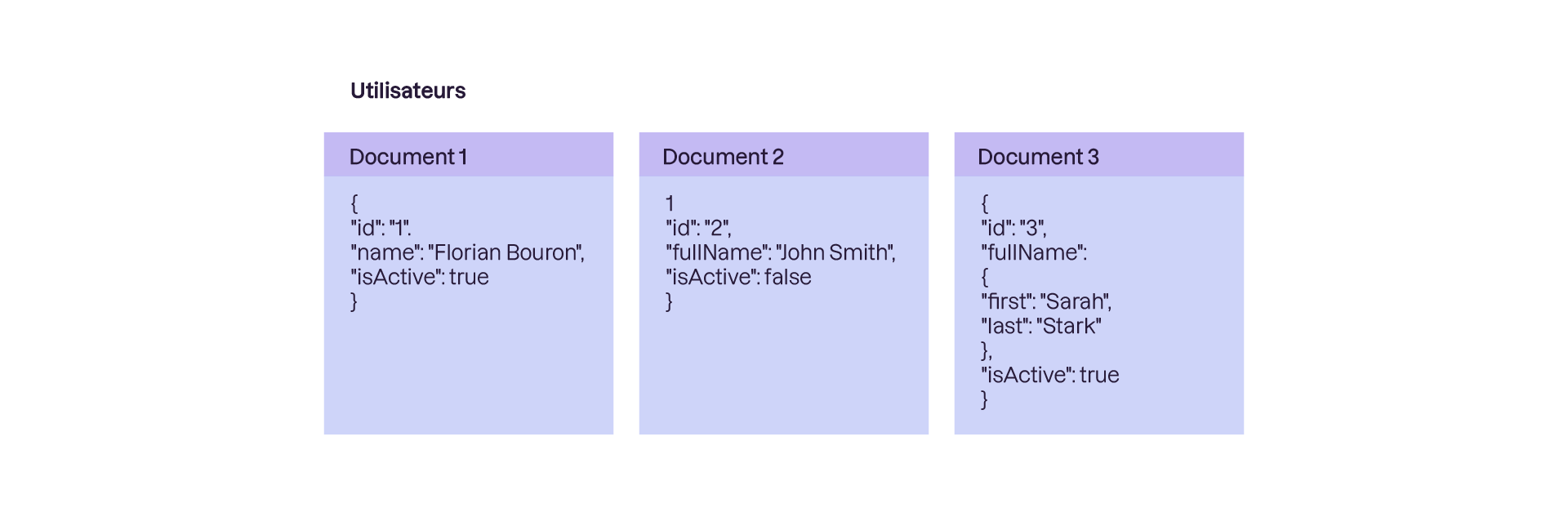
Avec les bases de données Clé/Valeur, nous avions 1 valeur pour 1 clé. Eh bien avec les bases de données documents nous stockons des “documents” à l’adresse de la clé. Comprenons bien ce qu’est un “document”, c’est généralement un JSON (voir ci-dessous) qui contient toute une série d’attributs qui peuvent être du texte, des nombres, des dates, booléens, adresses URL, images etc.
La force du JSON c’est qu’il est flexible et permet une imbrication des attributs entre eux. Sur notre image qui représente une base de données d’Utilisateurs d’un système, tous nos documents contiennent l’information du nom des utilisateurs de façons différente (flexibilité du schéma), dans le premier nous avons “name”, dans le second “fullname” et dans le troisième nous avons les attributs imbriqués dans “fullname” : “first” et “last”. Cette flexibilité est super utile sur le web quand nous avons à gérer des informations non standardisées. Nous pouvons tout stocker tout en gardant la capacité de faire des requêtes pour récupérer nos informations (exemple liste moi les valeurs de tous les attributs qui contiennent *name* dans mes documents).
MongoDB domine le segment des bases de données document, permettant des requêtes complexes sur des structures imbriquées tout en offrant une évolutivité horizontale impressionnante. Ces bases privilégient aussi la cohérence (Consistency) et la tolérance au partitionnement (Partition tolerance).
En synthèse, ces bases de données présentent les caractéristiques suivantes :
Flexibilité du schéma (modèle flexible)
Documents avec structure variable
Requêtes plus riches que les bases clé/valeur
Bonne performance pour les opérations CRUD
Si vous répondez oui aux questions suivantes vous avez probablement besoin de choisir ce type de base de données :
Mes données ont-elles une structure qui varie d’un enregistrement à l’autre ?
Le schéma de mes données est-il susceptible d’évoluer fréquemment ?
Est-ce que je développe une application web ou mobile avec des données JSON ?
Exemple d’application : Couchbase, l’unification des données clients chez Système U
Pour résoudre les incohérences entre ses canaux e-commerce, drive et physiques, Système U a déployé Couchbase comme hub de données unifié. L’architecture documentaire permet :
Un schéma flexible intégrant 32 types de données hétérogènes (profils clients, stocks, promotions)
Une synchronisation en temps réel
Des requêtes pour l’analytique cross-canaux
Résultats :
70 % de réduction des erreurs de promotions
Temps de traitement des commandes en drive réduit de 8 à 2 secondes
Coûts de maintenance divisés par 4 comparé aux trois bases SQL précédentes
Bases de données graphes :
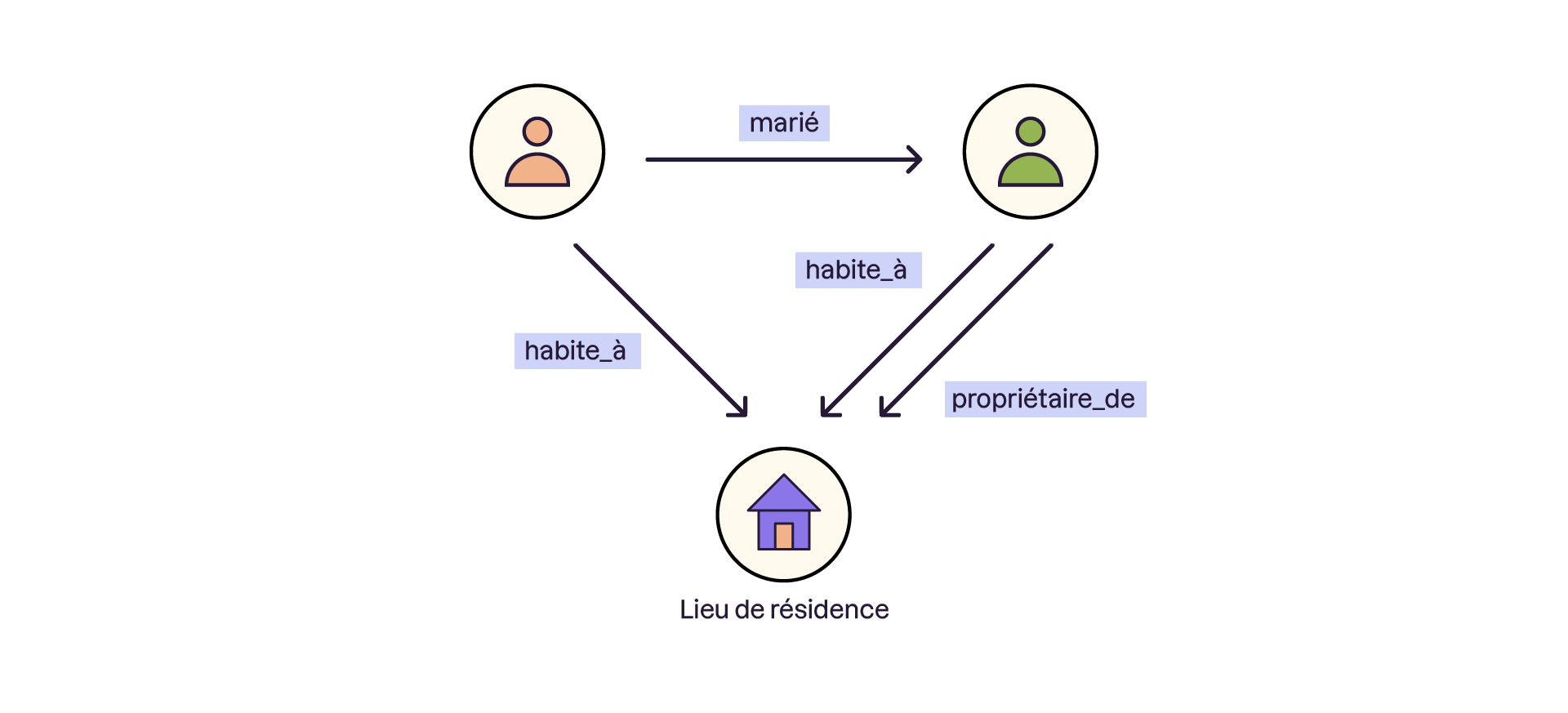
Les bases de données graphes permettent de modéliser des relations complexes entre entités. Elles transforment vos données en nœuds et relations pour des requêtes qui explorent les connexions avec une efficacité impossible à atteindre dans d'autres modèles.
Avec ces bases de données il devient facile de créer des requêtes de type :
Je voudrais compter le nombre de personnes qui sont mariées, et qui vivent à une même adresse, mais seul l’une des personnes du couple est propriétaire de cette adresse.
Ces bases de données sont très utilisées pour la recommandation, par exemple :
Mame et Alexandre aiment la chanson “One” du groupe Metallica, Mame écoute également la chanson “Chop Suey!” du groupe System of a Down, Alexandre a donc de grandes chances d'apprécier aussi cette chanson.
J’ai beaucoup travaillé avec les bases de données graphes dans le cadre d’analyses des relations de travail dans des organisations et je peux vous dire que ces requêtes sont beaucoup plus difficiles à écrire et lentes à exécuter avec les autres systèmes de bases de données.
Les bases de données graphes privilégient la disponibilité (Availability) et la cohérence (Consistency).
En synthèse, elles présentent les caractéristiques suivantes :
Performance élevée pour les requêtes impliquant des relations multiples
Modélisation intuitive de données fortement connectées
Exploration facile des relations
Scalabilité horizontale plus difficile
Si vous répondez oui aux questions suivantes vous avez probablement besoin de choisir ce type de base de données :
Mes données comportent-elles de nombreuses relations complexes entre entités ?
Dois-je représenter des réseaux sociaux ou des graphes de connaissances ?
Exemple d’application : Neo4J, personnalisation des Campagnes Marketing chez Adobe
Adobe utilise un cluster Neo4j Enterprise pour interconnecter 450 millions de profils utilisateurs avec :
27 types de relations (clic, partage, achat)
Modélisation des parcours clients sur 12 canaux
Requêtes temps réel
Résultats :
35 % d’augmentation du taux de conversion
Latence garantie sous 15 ms malgré 1,2 To de données
Architecture certifiée pour la gestion des consentements RGPD
En résumé
Les bases relationnelles traditionnelles atteignent leurs limites face aux grands volumes de données, aux schémas rigides et à la distribution.
Le NoSQL (Not Only SQL) assouplit les contraintes des bases relationnelles pour mieux gérer les données à grande échelle.
Le théorème de CAP établit qu'un système distribué ne peut garantir que deux propriétés parmi cohérence, disponibilité et tolérance aux partitions.
Quatre types principaux de bases NoSQL existent: clés-valeurs (Redis), colonnes (Cassandra), documents (MongoDB) et graphes (Neo4j).
Chaque type de base NoSQL fait différents compromis CAP selon les besoins spécifiques des applications.
Vous connaissez maintenant les concepts fondamentaux du NoSQL et ses différentes familles. Prenons maintenant le temps d’aller un peu plus loin pour comprendre comment ces systèmes relèvent concrètement le défi de la gestion de données massives et distribuées.
