Transformez les données avec des modèles dbt
Vous devez maintenant poser les premières bases du pipeline de transformation. Maintenant que dbt Cloud est prêt et que vos sources sont reconnues, il est temps de créer vos premiers modèles dbt.
Comprenez les modèles dbt
Dans cette vidéo, découvrez comment fonctionnent les modèles dbt.
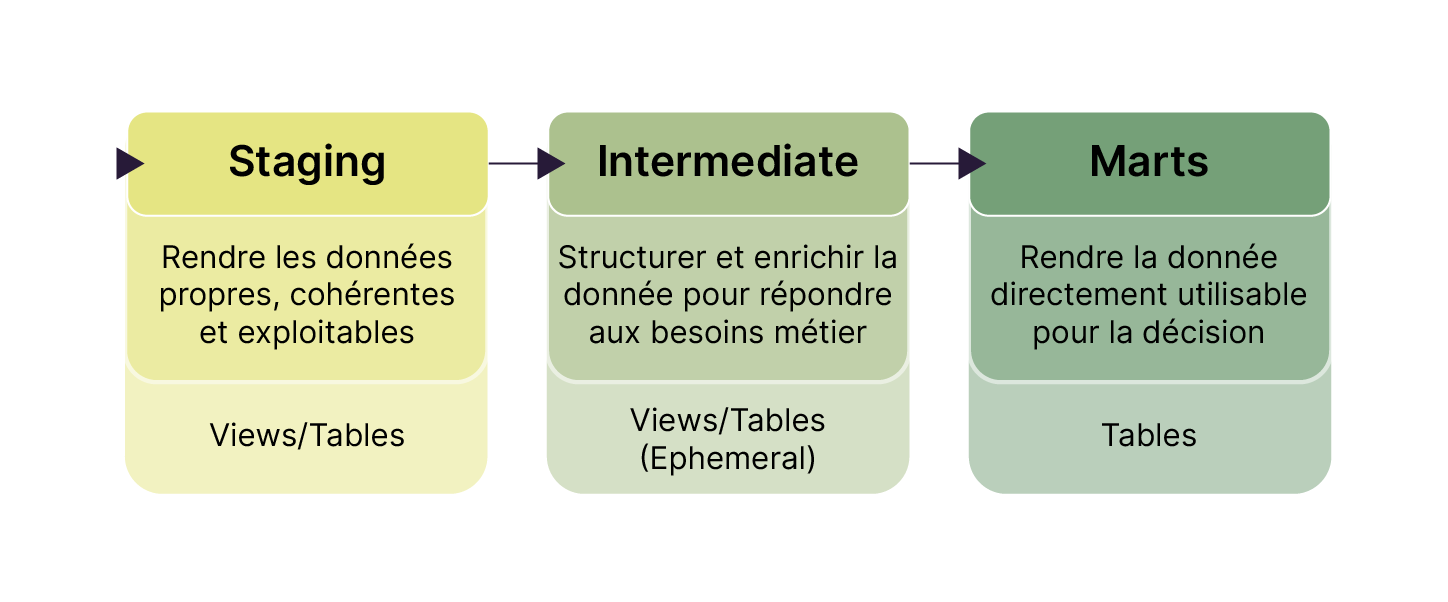
Voici une description détaillée de l'architecture Staging, Intermediate et Marts.
Couche Staging | C’est la version propre et standardisée des données brutes.
C’est le socle sur lequel repose tout le reste. |
Couche Intermediate | On commence à combiner les données, à calculer des métriques intermédiaires et à préparer des structures plus riches. Cette couche sert à rapprocher les données des besoins métier sans aller jusqu’à la restitution finale. |
Couche marts | Ce sont les modèles finaux, consommés par les équipes Marketing, Produit ou Direction. Ils seront directement utilisés par les outils de data visualization ou par les data analyst. |
En plus des couches (staging, intermediate, marts), dbt vous permet de choisir comment chaque modèle est matérialisé dans le data warehouse. C’est ce qu’on appelle la matérialisation Les trois plus courantes sont : view, table et ephemeral.
Modèle | Un modèle materialized en view crée une vue dans le data warehouse.
C’est utile pour des modèles intermédiaires légers, qui n’ont pas besoin de stocker leurs résultats. |
Modèle | Un modèle materialized en table crée une table physique dans le data warehouse.
C’est le choix le plus courant pour les modèles finaux (marts) consommés par les équipes métier. |
Modèle | Un modèle ephemeral n’est jamais créé comme vue ou table dans le warehouse.
C’est une option plus avancée, que vous utiliserez surtout pour factoriser du code lorsque votre pipeline deviendra plus complexe. |
Comment relier ces modèles à vos couches ?
Sans tout figer, on peut garder en tête quelques repères simples :
En staging, on utilise souvent des
viewou destableselon les volumes et la fréquence d’usage.En intermediate, on peut mélanger
view,tableet parfoisephemeralpour structurer la logique métier.En marts, on privilégie presque toujours des
table, pour garantir de bonnes performances aux dashboards.
Créez vos premiers modèles dans dbt Cloud
On vous a demandé de commencer à structurer le pipeline en créant un premier modèle capable d’exposer proprement les données de commandes. L’objectif est simple : vérifier que dbt lit bien les données brutes importées dans Snowflake et qu’il est capable de produire un premier objet exploitable dans le warehouse.
Dans cette vidéo, vous allez découvrir les étapes clés pour créer votre premier modèle staging. Cette étape est essentielle pour poser la première pierre du pipeline qui servira ensuite aux analyses de MadeInFrance.
Dans cette vidéo, on a :
créé un premier modèle staging à partir de la table
orders,utilisé la fonction
source()pour lire les données brutes déclarées dans votre fichier YAML.exécuté le modèle avec la commande
dbt run,analysé les logs générés par dbt et
vérifié dans Snowflake que le modèle avait bien été matérialisé dans le warehouse.
Le premier modèle est donc fonctionnel, et c’est sur celui-ci que vous allez construire les prochaines étapes de nettoyage et d’enrichissement.
Nettoyez et structurez les données
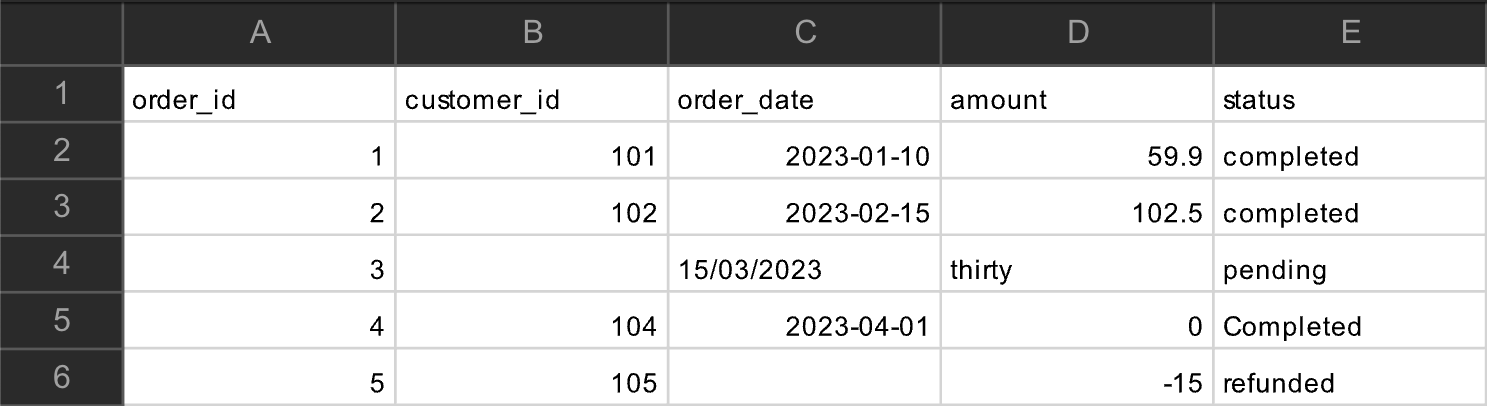
Votre premier modèle staging ( stg_orders ) est en place : dbt lit désormais les données brutes directement depuis Snowflake.
Ce qu’il faut faire et pourquoi le faire
Un bon modèle de staging doit appliquer trois types de transformations fondamentales :
1. Renommer, typer et normaliser les colonnes
Les colonnes brutes arrivent souvent avec :
des noms peu explicites,
des chaînes de caractères qui devraient être des dates,
des montants stockés sous forme de texte,
un casing incohérent.
L’objectif est simple : transformer les données en un format uniformisé et compréhensible.
2. Gérer les valeurs nulles, aberrantes ou incohérentes
Certaines lignes de la base de commandes contiennent :
des
NULLdans des champs clés,des dates absentes ou au mauvais format,
des montants impossibles (comme “free” ou “NA”).
Le staging doit repérer ces anomalies et les traiter, généralement via :
coalesce()pour remplacer des valeurs manquantes,try_to_number()outry_to_date()pour gérer les données mal typées,des filtres pour exclure les valeurs impossibles.
L’idée est d’obtenir un modèle stable, qui ne casse pas les transformations suivantes.
3. Appliquer les premières règles métiers
Même si la logique métier complète vient dans les modèles intermediate, certaines règles de base doivent être appliquées dès le staging :
exclure les montants négatifs si l’entreprise ne les considère pas comme valides,
poser un statut par défaut en cas de champ manquant,
préserver ou réécrire les statuts selon les conventions internes.
Comment le faire étape par étape
Vous devez maintenant transformer votre modèlestg_orderspour obtenir une version fiable des commandes. Voici les étapes à suivre :
Dans cette vidéo, on a :
transformé le modèle
stg_orderspour obtenir une version propre et standardisée des données brutes en :renommant et typant les colonnes,
corrigeant les formats incohérents,
gérant les valeurs nulles,
filtrant les montants aberrants et
appliqué les premières règles métiers.
Après exécution avecdbt run, on a vérifié dans Snowflake que le modèle staging était correctement matérialisé et prêt à servir de base aux prochaines étapes de transformation.
Agrégez et combinez vos extractions
L’étape suivante est de créer une vue d’ensemble plus riche, en combinant les informations issues de plusieurs sources. Chez MadeInFrance, les équipes Marketing et Produit ont exprimé un besoin fréquent :
Pouvoir mieux comprendre le comportement des clients : combien ils commandent, quand, et à quelle fréquence.
Pour répondre à ces attentes, vous allez devoir agréger les données et les combiner entre elles, notamment en reliant les commandes aux informations clients.
Créez des modèles d’enrichissement dans la couche intermediate
Lcouche intermediate repose sur trois principes clés :
1. Requêter vos modèles de staging avecref()
Les données brutes ne doivent jamais être utilisées directement dans les modèles intermédiaires.
Tout part de votre travail de nettoyage :
les modèles intermediate interrogent exclusivement les modèles staging,
cela garantit que toutes les données utilisées sont déjà cohérentes et standardisées.
Le fait de s’appuyer sur staging permet de protéger tout le pipeline : une correction apportée en staging est automatiquement répercutée dans tous les modèles qui en dépendent.
2. Combiner les données : joins, unions, filtres
La couche intermediate permet d’introduire la logique métier en combinant plusieurs tables :
les joins servent à relier différentes informations (ex. relier une commande au client correspondant),
les unions permettent de combiner des ensembles de données de structure identique (ex. commandes actuelles + commandes archivées),
les filtres sont utilisés pour appliquer les règles métier définies avec votre équipe (ex. conserver seulement les commandes valides ou finalisées).
Ces opérations ne modifient plus la “qualité” des données — elles commencent à construire une logique métier exploitable.
3. Produire des agrégations utiles aux besoins métier
Les équipes internes n’ont pas besoin de données brutes, mais d’indicateurs. La couche intermediate permet d’en produire :
total de commandes,
total dépensé par client,
date de la première ou dernière commande,
nombre de commandes sur une période, etc.
Ces agrégations ne sont pas les modèles finaux : elles servent de bloc intermédiaire pour construire des marts clairs, stables et performants.
Dans cette vidéo, on va appliquer tout cela en suivant quelques étapes clés.
Dans cette vidéo, on a :
créé un modèle intermediate qui enrichit les données de commandes avec des informations clients,
utilisant
ref()pour interroger les modèles de staging,exécutant des filtres,
ajoutant des agrégations métier et dynamisant la requête grâce à une variable Jinja,
exécuté le modèle avec
dbt runet vérifié sa matérialisation dans Snowflake.
On dispose maintenant d’une transformation modulaire et réutilisable prête à alimenter les modèles finaux.

À vous de jouer
Contexte
Vous avez désormais toutes les bases nécessaires pour construire un pipeline complet : un modèle de staging pour nettoyer les données d’entrée, puis un modèle intermediate pour enrichir ces données et les relier à d’autres sources. C’est le moment de mettre en pratique ce que vous venez d’apprendre.
Consignes
En vous appuyant sur ce que vous appris précédemment :
Créez un modèle de staging qui nettoie votre source orders.
Créez un modèle intermediate qui agrège des données métier
Exécutez vos modèles dans dbt Cloud pour vérifier qu’ils se matérialisent correctement dans Snowflake.
Livrables
À la fin de l’activité, vous devez obtenir :
un modèle de staging exécuté avec succès,
un modèle intermediate exécuté avec succès,
une exécution
dbt runsans erreur, confirmant que votre pipeline fonctionne de bout en bout.
En résumé
Un modèle dbt est un fichier SQL que dbt exécute pour créer une table ou une vue dans le data warehouse.
dbt structure les transformations en trois couches complémentaires : staging pour nettoyer les données, intermediate pour les enrichir, et marts pour les préparer à l’analyse finale.
Les modèles de staging servent à normaliser les colonnes, mettre les champs au bon format, et corriger les incohérences.
La couche intermediate permet de combiner plusieurs sources, appliquer la logique métier et produire des agrégations utiles.
La fonction
ref()permet de relier les modèles entre eux et de créer un pipeline modulaire et maintenable.Jinja peut être utilisée pour rendre les modèles dynamiques et adaptés aux besoins métier (par exemple grâce aux variables).
L’exécution de vos modèles avec
dbt runmatérialise concrètement les transformations dans le data warehouse et valide la cohérence du pipeline.
Vous avez construit un pipeline capable de transformer et d’enrichir les données brutes de manière structurée. Il est maintenant essentiel de vérifier que ces transformations produisent des données fiables : c’est l’objectif du prochain chapitre, consacré aux tests et au contrôle de qualité dans dbt.
