Avant d'aborder l'installation d'HDFS et son utilisation proprement dite, on va parler de son modèle de fonctionnement. HDFS, comme on l'a expliqué dans le chapitre précédent, est un système de fichiers distribué. Il a initialement été créé pour Hadoop, qui est un outil extrèmement populaire pour réaliser des calculs distribués et basé sur l'algorithme Map-Reduce.
HDFS est un composant qui a toute son utilité en dehors du contexte du calcul distribué, et il est tout à fait possible de l'utiliser séparément de Map-Reduce — ce que nous allons faire dans cette partie.
Du point de vue de l'utilisateur, HDFS se comporte comme un système de fichiers presque normal : il est possible de créer des fichiers, de les organiser en répertoire, de lister le contenu de ces répertoires, d'ajouter des permissions... en bref, tout ce à quoi on peut s'attendre de la part d'un système de fichiers. Cependant, l'architecture d'HDFS est fondamentalement différente du fait de sa nature distribuée.
Architecture de HDFS sous forme distribuée
Dans un cluster, où les données et les services sont stockées sur plusieurs machines différentes, HDFS fonctionne selon un principe maître/esclaves classique : les données y sont stockées sur les datanodes (esclaves) tandis que les localisations des blocs de données sont répertoriées par le namenode (maître).
Chaque fichier est décomposé en blocs de taille maximale fixe. Par défaut, cette taille est de 64 Mo. Par exemple, un fichier de 150 Mo va être décomposé en trois blocs : deux blocs de 64 Mo et un bloc de 22 Mo. Ces blocs seront répartis de manière redondante sur les différents data nodes. C'est le namenode qui sait comment sont décomposés les fichiers et sur quels datanodes sont stockés ces blocs.
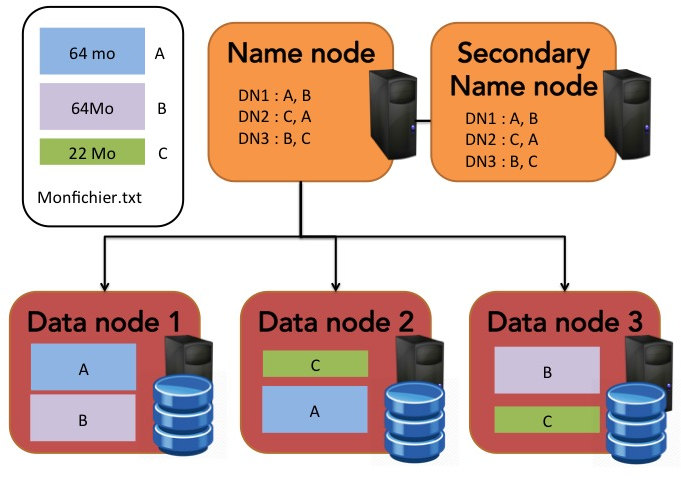
Dans le schéma ci-dessus, les blocs de données sont stockés avec un taux de réplication de 2 : en fonctionnement nominal, chaque bloc est stocké sur deux datanodes différents.
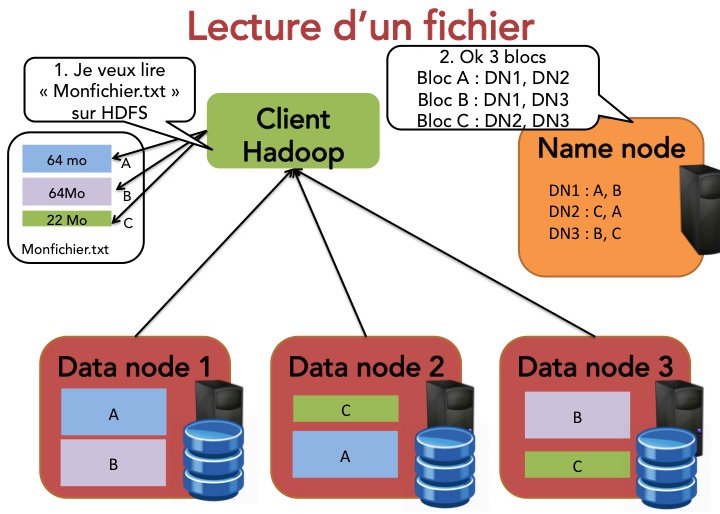
En fait, les datanodes ont très peu d'intelligence et ils ne servent qu'à stockér les données. Les adresses des blocs ainsi que les noms des fichiers sont tous stockés par le namenode, dont le rôle est critique. Pour illustrer le rôle du namenode et des datanodes, détaillons ce qui se passe lorsqu'un client (nommé Jules) veut lire un fichier stocké dans HDFS :
Jules indique au namenode qu'il souhaite lire un fichier.
Le name node indique à Jules la taille du fichier ainsi que les différents data nodes contenant les blocs qui composent ce fichier.
Jules récupère chacun des blocs sur l'un des data nodes.
Si un des datanodes est indisponible, Jules en contacte un autre.
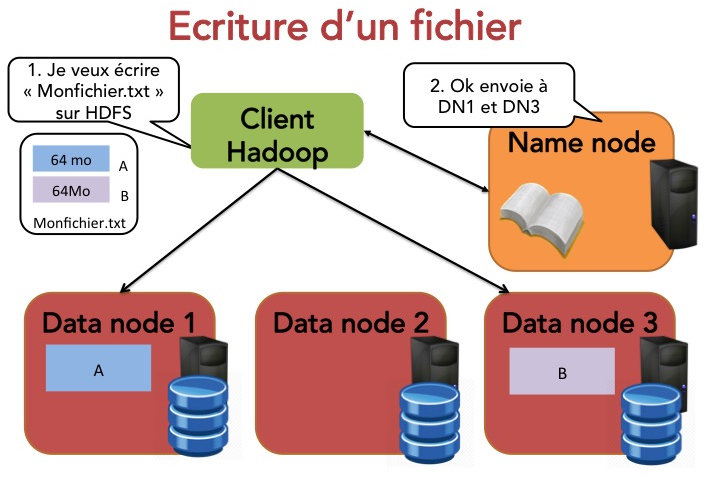
De la même manière, si un autre client (nommé Jim) veut écrire un fichier, voilà ce qui se passe :
Jim indique au namenode qu'il souhaite écrire un bloc.
Le namenode indique à Jim le datanode à contacter.
Jim envoie le bloc au datanode.
Les datanodes répliquent les blocs entre eux.
Le cycle se répète pour le bloc suivant.
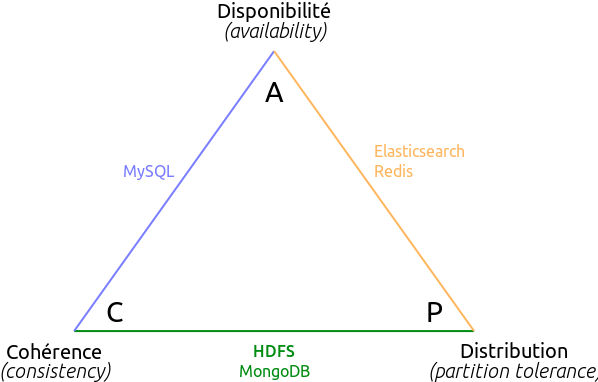
Mais alors, que se passe-t-il si Jules cherche à lire le fichier juste après qu'il a été modifié par Jim ? Est-ce que Jules va bien obtenir les données les plus récentes ? En particulier, que se passe-t-il en cas de panne d'un des datanodes ? Pour répondre à cette question, il faut comprendre comment se place HDFS sur le triangle CAP.
HDFS et le théorème CAP
Comme vous le savez peut-être, tout système de stockage de données est soumis au théorème CAP : selon ce théorème, en cas de partitionnement du réseau, un système de stockage de données ne peut assurer à la fois la cohérence et la disponibilité des données. Qu'est-ce que ça signifie pour HDFS ? Imaginons qu'un datanode devienne indisponible, pour une raison quelconque : le datanode plante par manque de RAM, le DNS est mal configuré, un météore s'écrase sur le datacenter, un stagiaire débranche un câble ethernet... Bref, le cluster devient partitionné en deux. Jim a écrit ses données juste avant que ne tombe le météore. Jules lit les données juste après. Ce que dit le théorème CAP, c'est que Jules ne peut être assuré à la fois de recevoir une réponse à sa requête, et que cette réponse contiendra les données les plus récentes. Si Jules veut absolument une réponse, il va exiger que le cluster soit disponible. Mais dans ce cas il ne pourra être certain que la réponse sera cohérente.
Au sens du théorème CAP, HDFS n'est pas un système disponible : c'est un système cohérent. Cela signifie que Jules n'est pas certain d'obtenir une réponse à sa requête, mais s'il en obtient une alors cette réponse contiendra bien les données les plus récentes. C'est une excellente nouvelle pour nous ! HDFS doit contenir notre master dataset, qui est la source de vérité pour toutes nos applications. Il est donc crucial qu'il fournisse des données cohérentes à toutes nos applications.
Encore une fois, on est restés très théoriques dans ce chapitre. Mais c'était important pour comprendre le rôle des différents composants d'un cluster HDFS. Et notamment, ce dont on s'aperçoit en étudiant l'architecture d'HDFS, c'est que le namenode constitue un point unique de défaillance (SPOF). C'est à dire que si le namenode devient indisponible, tout le cluster l'est également. Ce choix est assumé par le fait que HDFS n'est pas considéré comme un système pouvant assurer 100% de disponibilité.
Dans les chapitres suivants, on va (enfin !) voir comment lancer en pratique un cluster, l'utiliser et palier aux pannes des différents composants en production.
