Comme on a pu le voir dans le chapitre précédent, il est relativement facile de lancer un cluster HDFSsimple composé d'un seul datanode. Ce genre de cluster est bien pratique pour réaliser des tests en local. Mais avec un seul datanode, il n'y a pas de réplication des données : ça signifie qu'en cas de panne de notre unique datanode, toutes nos données vont devenir indisponibles. Dans ce chapitre, on va voir comment créer et administrer un cluster HDFS contenant plusieurs datanodes.
Lancement de datanodes supplémentaires
Par défaut, le taux de réplication dans un cluster HDFS est de trois. Ça signifie que les blocs sont répliqués sur trois serveurs différents -- à condition qu'il y ait au moins trois datanodes dans le cluster évidemment ! Dans la suite on va voir comment passer de un à trois datanodes. Si vous voulez modifier ce taux de réplication par défaut, par exemple parce que vous n'avez pas assez de serveurs, vous pouvez définir la variabledfs.replicationdanshdfs-site.xml. Par exemple :
<property>
<name>dfs.replication</name>
<value>2</value>
</property>Dans la suite on va considérer que le taux de réplication reste de trois et on va donc lancer trois datanodes pour obtenir une réplication correcte des donnés. Si vous disposez de plusieurs serveurs sur un réseau local, vous pouvez lancer un datanode en procédant exactement de la même manière que décrite dans le chapitre précédent. La seule contrainte est que les datanodes puissent communiquer entre eux sur les ports 50010 et 50020, ainsi qu'avec le namenode sur les ports 9000 et 50070.
Si vous n'avez pas la chance de disposer de plusieurs serveurs sous la main, sachez que vous pouvez également lancer plusieurs datanodes en local ; il suffit de modifier les ports sur lesquels écoutent les datanodes, ainsi que les répertoires qu'ils utilisent pour stocker leurs données. Voici par exemple les fichiers de configuration que j'ai créés pour lancer trois datanodes en local :
etc/hadoop/datanode1.xml:
<configuration>
<property>
<name>dfs.datanode.address</name>
<value>0.0.0.0:50011</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:50076</value>
</property>
<property>
<name>dfs.datanode.ipc.address</name>
<value>0.0.0.0:50021</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/regis/code/hdfs/datanode1/</value>
</property>
</configuration>etc/hadoop/datanode2.xml:
<configuration>
<property>
<name>dfs.datanode.address</name>
<value>0.0.0.0:50012</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:50077</value>
</property>
<property>
<name>dfs.datanode.ipc.address</name>
<value>0.0.0.0:50022</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/regis/code/hdfs/datanode2/</value>
</property>
</configuration>etc/hadoop/datanode3.xml:
<configuration>
<property>
<name>dfs.datanode.address</name>
<value>0.0.0.0:50013</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:50078</value>
</property>
<property>
<name>dfs.datanode.ipc.address</name>
<value>0.0.0.0:50023</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/regis/code/hdfs/datanode3/</value>
</property>
</configuration>Vous devrez également créer les répertoires qui vont contenir les données des datanodes :
$ mkdir ~/code/hdfs/datanode1 ~/code/hdfs/datanode2 ~/code/hdfs/datanode3Après avoir créé ces fichiers de configuration, vous pouvez les utiliser pour lancer les différents datanodes en exécutant les commandes suivantes :
$ ./bin/hdfs datanode -conf ./etc/hadoop/datanode1.xml
$ ./bin/hdfs datanode -conf ./etc/hadoop/datanode2.xml
$ ./bin/hdfs datanode -conf ./etc/hadoop/datanode3.xmlUne fois lancés les trois datanodes, vous pouvez contrôler l'état de votre cluster à l'aide de deux commandes fsck et dfsadmin. Par exemple, après avoir copié un peu plus de 100 Mo de données vers le cluster, voici ce que donnent ces commandes :
$ ./hadoop-2.8.1/bin/hdfs fsck /
...
Status: HEALTHY
Total size: 115640016 B
Total dirs: 6
Total files: 9490
Total symlinks: 0 (Files currently being written: 1)
Total blocks (validated): 9490 (avg. block size 12185 B) (Total open file blocks (not validated): 1)
Minimally replicated blocks: 9490 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 3.0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Number of data-nodes: 3
Number of racks: 1
FSCK ended at Thu Jul 27 15:40:23 CEST 2017 in 450 millisecondsfsckpermet d'obtenir des informations sur l'état du système de fichier, tandis quedfsadminfournit des informations détaillées sur chacun des datanodes :
$ ./hadoop-2.8.1/bin/hdfs dfsadmin -report
Configured Capacity: 986519629824 (918.77 GB)
Present Capacity: 10692092096 (9.96 GB)
DFS Remaining: 10245820416 (9.54 GB)
DFS Used: 446271680 (425.60 MB)
DFS Used%: 4.17%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Pending deletion blocks: 0
-------------------------------------------------
Live datanodes (3):
Name: 127.0.0.1:50010 (localhost)
Hostname: black
Decommission Status : Normal
Configured Capacity: 328839876608 (306.26 GB)
DFS Used: 148683322 (141.80 MB)
Non DFS Used: 309226354118 (287.99 GB)
DFS Remaining: 3415621632 (3.18 GB)
DFS Used%: 0.05%
DFS Remaining%: 1.04%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Thu Jul 27 15:41:55 CEST 2017
Name: 127.0.0.1:50011 (localhost)
Hostname: black
Decommission Status : Normal
Configured Capacity: 328839876608 (306.26 GB)
DFS Used: 148905036 (142.01 MB)
Non DFS Used: 309227176884 (287.99 GB)
DFS Remaining: 3414577152 (3.18 GB)
DFS Used%: 0.05%
DFS Remaining%: 1.04%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Thu Jul 27 15:41:56 CEST 2017
Name: 127.0.0.1:50012 (localhost)
Hostname: black
Decommission Status : Normal
Configured Capacity: 328839876608 (306.26 GB)
DFS Used: 148683322 (141.80 MB)
Non DFS Used: 309226354118 (287.99 GB)
DFS Remaining: 3415621632 (3.18 GB)
DFS Used%: 0.05%
DFS Remaining%: 1.04%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Thu Jul 27 15:41:55 CEST 2017Notez quedfsadminpermet de réaliser bien plus que des rapports sur l'état des données ; c'est également la commande qui va nous permettre de réaliser pas mal de tâches pour l'administration du cluster, comme on va le voir plus loin.
Vous devriez maintenant disposer d'un cluster HDFS complet. Prenez donc un petit moment pour vous auto-congratuler avant de passer à la suite.
Lancement d'un namenode secondaire
Comme on l'a mentionné dans les chapitres précédents, le namenode constitue un point unique de défaillance d'un cluster HDFS. Il est donc important de faire en sorte que :
les données du namenode soient préservées.
le namenode puisse être redémarré rapidement s'il venait à tomber en panne.
Ces deux fonctions sont remplies par le namenode secondaire. Contrairement à ce que son nom indique, il ne s'agit pas d'un composant pouvant remplacer le namenode en cas de panne. Pour comprendre le rôle du namenode secondaire, il faut un peu détailler le fonctionnement du namenode. Regardons un peu comment le namenode stocke ses données :
$ l ~/code/hdfs/namenode/current/
total 23M
-rw-rw-r-- 1 regis regis 22M juil. 27 17:47 edits_inprogress_0000000000000000001
-rw-rw-r-- 1 regis regis 322 juil. 27 16:52 fsimage_0000000000000000000
-rw-rw-r-- 1 regis regis 62 juil. 27 16:52 fsimage_0000000000000000000.md5
-rw-rw-r-- 1 regis regis 2 juil. 27 16:52 seen_txid
-rw-rw-r-- 1 regis regis 214 juil. 27 16:52 VERSIONLa commande ci-dessus a été exécutée après avoir copié sur le cluster environ 1.8 Go de données. Intéressons-nous aux deux fichiersedits_inprogress_0000000000000000001etfsimage_0000000000000000000. L'état du namenode peut être reconstruit à partir defsimageetedits_inprogress. À chaque redémarrage du namenode,edits_inprogressest déroulé pour être appliqué àfsimage. C'est ce qu'on appelle un checkpoint. Ce déroulage prend d'autant plus de temps que le fichieredits_inprogressest gros. Et ce fichier peut être très gros si le namenode a été exécuté pendant plusieurs jours ou plusieurs semaines sans redémarrage.
Or, vous redémarrez très rarement votre namenode, car sans lui HDFS ne fonctionne plus ! Cela vous incite d'autant plus à ne surtout jamais le redémarrer, puisque le checkpoint prendra d'autant plus longtemps... Quel dilemme ! Pour résoudre ce problème, le namenode secondaire réalise des checkpoints périodiques du namenode de manière transparente. Et la bonne nouvelle c'est qu'il est très simple de lancer un namenode secondaire :
$ ./bin/hdfs secondarynamenodePar défaut, le namenode secondaire réalisera des checkpoints toutes les heures (paramètredfs.namenode.checkpoint.period) et toutes les 10⁶ transactions (paramètredfs.namenode.checkpoint.txns). Vous pouvez forcer la réalisation d'un checkpoint en exécutant :
$ ./bin/hdfs secondarynamenode -checkpoint forceAprès avoir exécuté la commande ci-dessus, voilà l'état du répertoire contenant les données de mon namenode :
$ ls -lh hdfs/namenode/current/
total 13M
-rw-rw-r-- 1 regis regis 11M juil. 27 18:31 edits_0000000000000000001-0000000000000086694
-rw-rw-r-- 1 regis regis 1,0M juil. 27 18:31 edits_inprogress_0000000000000086695
-rw-rw-r-- 1 regis regis 322 juil. 27 17:59 fsimage_0000000000000000000
-rw-rw-r-- 1 regis regis 62 juil. 27 17:59 fsimage_0000000000000000000.md5
-rw-rw-r-- 1 regis regis 1,5M juil. 27 18:31 fsimage_0000000000000086694
-rw-rw-r-- 1 regis regis 62 juil. 27 18:31 fsimage_0000000000000086694.md5
-rw-rw-r-- 1 regis regis 6 juil. 27 18:31 seen_txid
-rw-rw-r-- 1 regis regis 213 juil. 27 17:59 VERSIONComme vous pouvez le voir, le fichier edits_inprogress a été vidé tandis qu'un second fichierfsimagea été créé, de taille plus importante que le précédent. Par ailleurs, un autre fichierfsimagede backup a été créé pour stocker l'état du namenode avant le checkpoint. Enfin, le fichieredits_représente un ensemble de transactions correspondant à un segment ; vous n'avez pas à vous en préoccuper :-)
Interface graphique d'administration
Jusqu'à présent, on a visualisé le comportement de notre cluster en ligne de commande, mais il existe une interface graphique accessible par votre navigateur. Accédez à http://localhost:50070 quand votre namenode est allumé pour la découvrir. Notez cependant que l'interface permet surtout de visualiser le cluster, mais pas vraiment d'effectuer des actions d'administration.
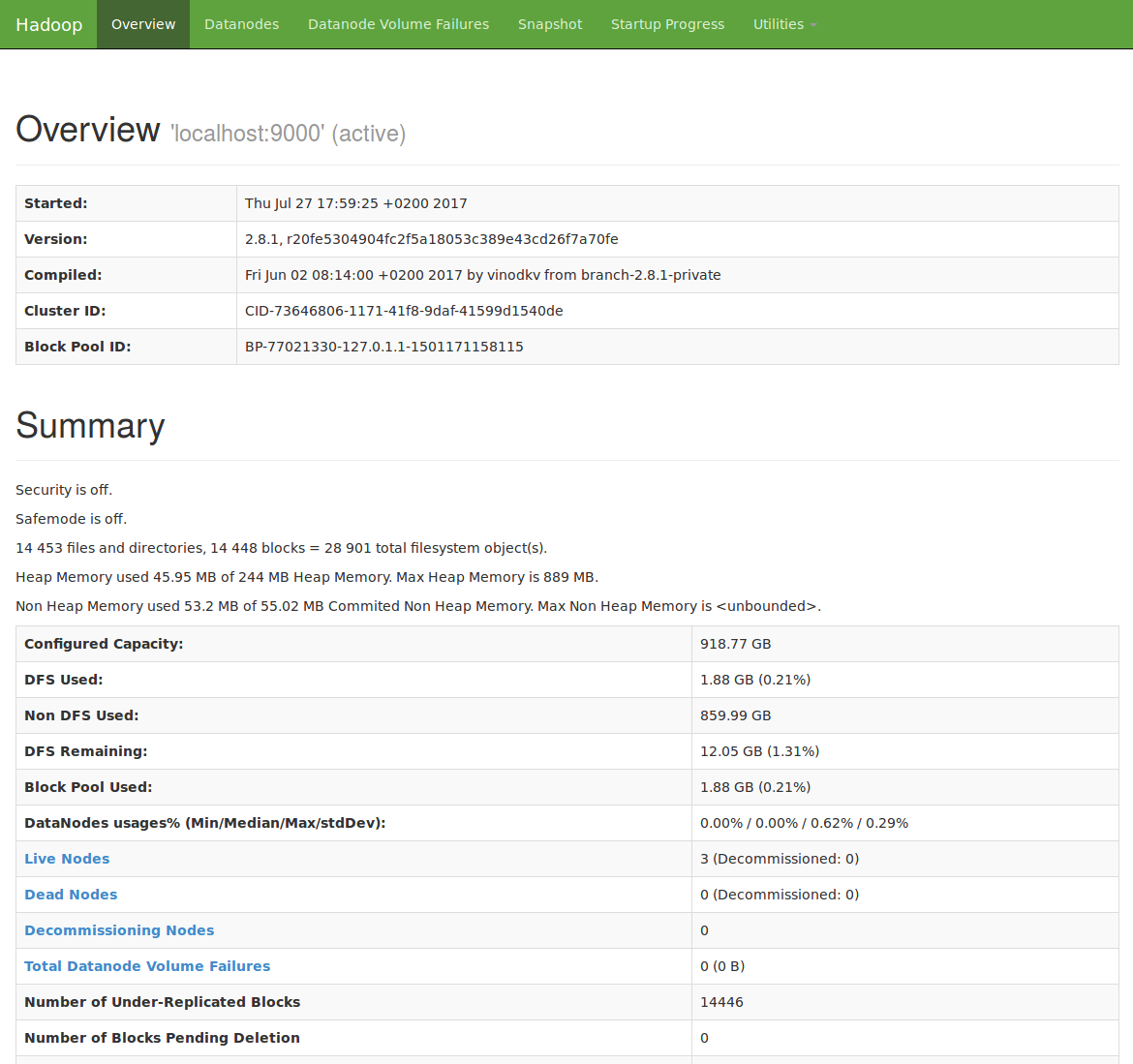
En particulier, il est très pratique de visualiser l'état des datanodes pour visualiser le nombre de blocs par datanode. La même information est disponible grâce àdfsadmin -reportmais elle est plus parlante sous forme visuelle :
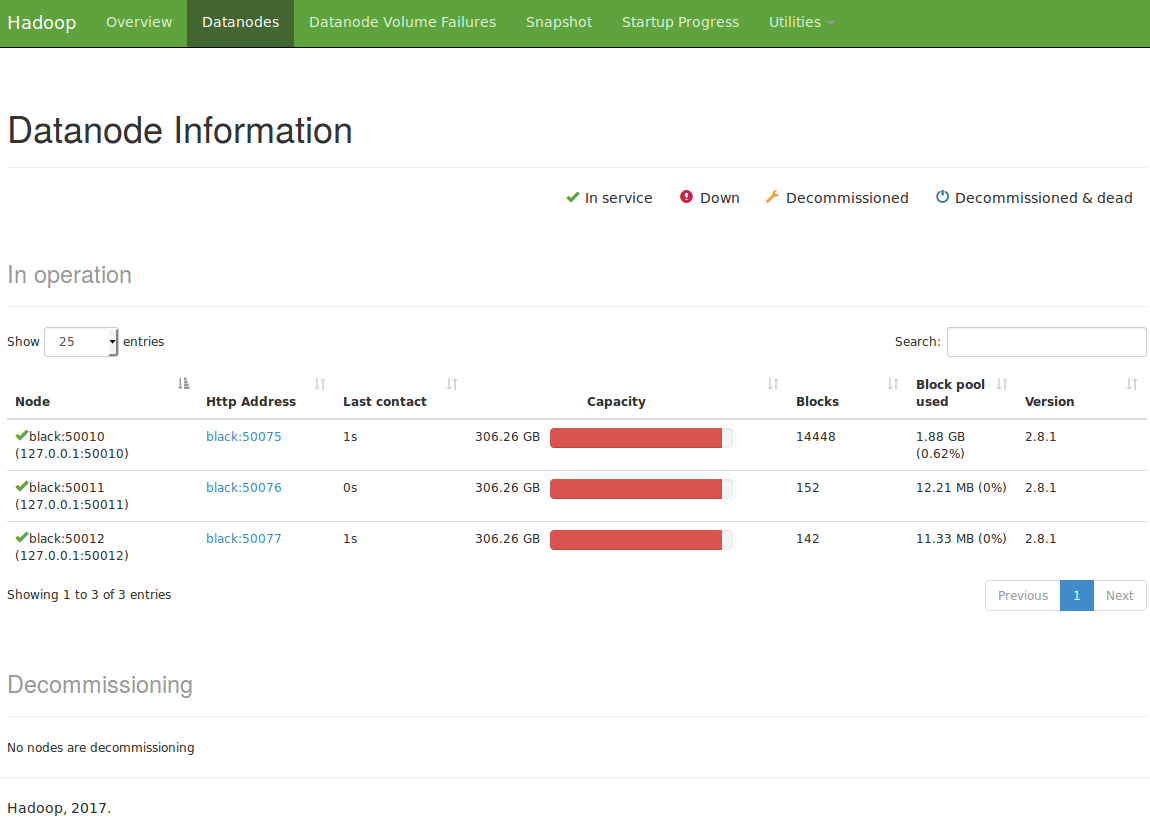
Snapshot de données
La gestion des backups de données fait également partie des tâches d'administration courantes d'un cluster. Rappelez-vous que le master dataset qui va être contenu dans HDFS est précieux : en cas d'accident, on ne peut pas se permettre de perdre ou d'altérer les données du master dataset. Pour cette raison, il est important de réaliser des snapshots des données. Un snapshot est utilisé pour savegarder l'état d'un répertoire à un instant donné. Pour pouvoir réaliser des snapshots sur un répertoire, il faut d'abord rendre ce répertoire "snapshotable". Par exemple, mes données sont contenues dans/data. Avec la commande suivante je rend possible les snapshots dans ce répertoire :
$ ./bin/hdfs dfsadmin -allowSnapshot /data
Allowing snaphot on /data/ succeededJe peux ensuite créer un snapshot :
$ ./bin/hdfs dfs -createSnapshot /data snapshot1
Created snapshot /data/.snapshot/snapshot1On voit qu'un nouveau répertoire/data/.snapshot/snapshot1a été ajouté. Il se comporte exactement comme un répertoire accessible en lecture seule et vou spouvez donc l'utiliser pour lire des versions anciennes de vos fichiers.
Je créé maintenant un nouveau fichier:
$ ./bin/hdfs dfs -touchz /data/nouveaufichier.txtPuis la commande snapshotDiff me permet maintenant de visualiser les différences avec le snapshot :
$ ./bin/hdfs snapshotDiff /data snapshot1 .
Difference between snapshot snapshot1 and current directory under directory /data:
M .
+ ./nouveaufichier.txtPour restaurer le contenu du snapshot, il suffit de copier tout ou partie des données depuis/data/.snapshot/snapshot1:
$ ./bin/hdfs dfs -cp -f /data/.snapshot/snapshot1/* /data/Il est conseillé de réaliser des snapshots périodiques des données, ce qui est possible puisque chaque snapshot n'occupe que très peu de place. Par exemple, pour réaliser un snapshot quotidien dont le nom correspond à la date, il suffit d'omettre le nom du snapshot :
$ ./bin/hdfs dfs -createSnapshot /data
Created snapshot /data/.snapshot/s20170727-191247.498Conclusion
Pfiouh ! Ca fait pas mal de choses à retenir. Mais normalement maintenant vous connaissez les bases pour administrer un cluster HDFS, ce qui va nous être utile dans la partie suivante pour créer notre master dataset.
En cas de doute, les pages de documentation suivantes sont très utiles : (c'est bien simple moi je les regarde tout le temps)
