Discover the Fundamentals of Machine Learning
The remarkable progress made in artificial intelligence is due, in particular, to advances in one of its sub-disciplines: machine learning.
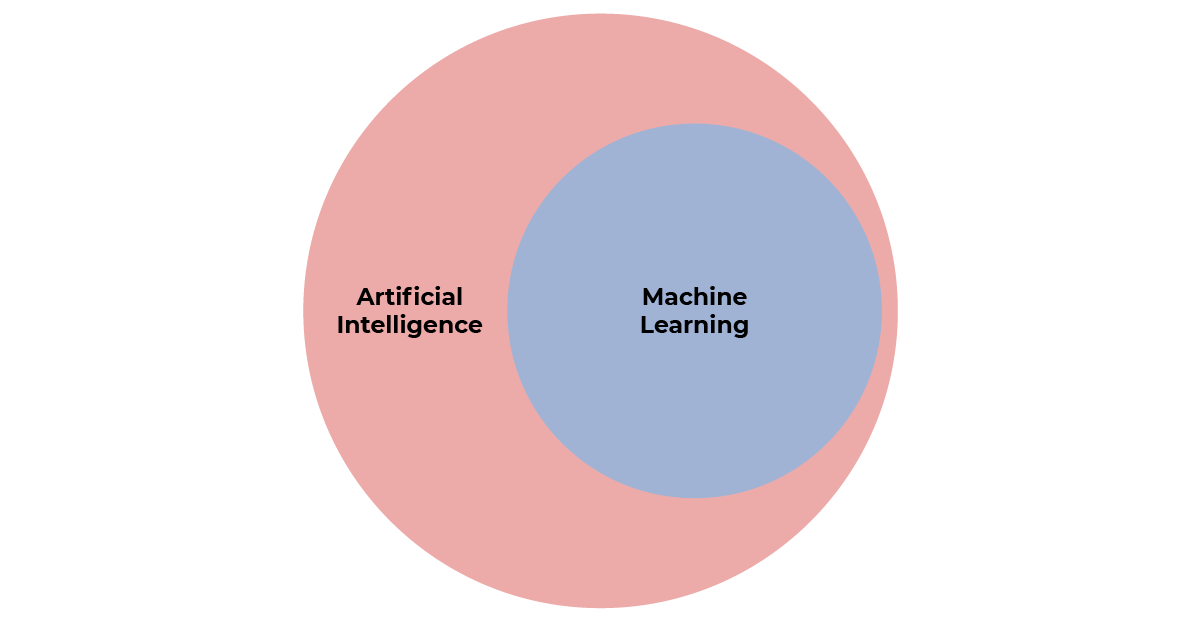
Machine learning allows you to create information systems that can learn independently, using the data you give them. What’s more, they can improve their performance over time as they acquire new data.
Does that sound a little far-fetched? Let’s unpack it!
What is a Model?
Once a problem is defined, a machine learning program needs a model it can use to solve it.
To understand this better, let’s take a common problem faced by real estate agents: how to calculate property price for a particular market. To come up with a price, agents do two things:
Gather data concerning the property’s features (geographic location, size or surface area, general condition, etc.).
Evaluate the property based on publicly available data and their own expertise.
Over time, agents continuously add to their knowledge of a target market. Using this background knowledge and the available data, they become better and better at evaluating properties. One could say that these real agents are developing their own price calculation model.
But let’s get back to real estate agents: using their models, agents could build price calculation software! To do so, they would need to incorporate all of the professional rules for calculating these prices. There are many such rules, and sometimes they aren’t explicit!
So what’s the problem? This older way of doing things is inadequate for solving very complex problems like in the previous example. A real estate agent’s knowledge is limited to the geographical area in which they work.
So how would I go about developing a method for calculating real estate prices for an entire city or country?
Good question! No, you can’t ask all the real estate agents to get together and create a model based on their individual experiences.
Machine learning to the rescue! Thanks to machine learning, you can now develop a program that can collect all of the available data related to a problem and learn from it on its own, creating a model.
The Different Ways an Algorithm Can Learn

In machine learning, the term learning may need a little clarification.
What does it mean for an algorithm to learn?
Learning (or training) is the model development phase. You give the algorithm many examples to analyze so it can learn by experience. And it has a few different ways to learn from these examples; let’s look at them in detail!
Method 1: Supervised Learning
Supervised learning is the first type.
You want the algorithm to learn to calculate the price of a home, for example. You give it many examples of houses that have sold, providing the features and sale price.
So for each example of a sold house, you have:
Features: Once it is trained, the system will use features to estimate the price of a home.
Features include size (surface area), number of rooms, whether there is a balcony, etc.
Labels: This is the target, the thing you want to predict. During training, the data is labelled so the algorithm can access this information. But once the system is ready, the goal is for the algorithm to predict prices based on the features of homes it has never seen before.
In our context, the labels represent the sale price of a particular house.
When the algorithm looks at the initial examples, it will not, at the outset, produce very good results. Then, as it incorporates new cases during its learning phase, it will adapt and transform until it is ready to calculate the prices of homes it has never observed before.
Method 2: Unsupervised Learning
As you just saw, in supervised learning, the algorithm has access to the labels, which represent the object of the prediction (in our example, a home price).
Sometimes you want to ask the algorithm to develop a model without giving it labels. In this case, you would use unsupervised learning. Here, there are no labels; you don’t know in advance what the algorithm will come up with.
For example, you could give the algorithm a list of houses and then ask it to divide them into three groups, with no supervision on your part.
Once the program forms the three groups, experts would need to figure out the label names because, although the algorithm forms the groups, it does not name them.
For example, you could end up with three groups based on geographical area: residential, student, and commercial. An agent could apply their extensive knowledge of one neighborhood to another that is similar, but has no expertise.
Method 3: Reinforcement Learning
In reinforcement learning, an agent (the algorithm) interacts with an environment (the features). The algorithm’s training dataset comes directly from the environment. Its objective is to find the optimum solution to a problem through sequential attempts (trial and error). This type of algorithm is called auto-adaptive as it is constantly learning.
Let’s consider a use-case in architecture. The idea is to create an algorithm that designs building plans. You give it the specifications, as well as your optimization goals. For instance, you want three conference rooms, each of them a specified size, with a specific number of close windows to one another. After you define the necessary parameters and specifications, the algorithm uses trial and error to come up with the ideal plan.
Can These Models Predict the Future?
During the learning phase, the program uses existing data, information that is already known. Once it has learned and been well trained (using one of the three learning methods), it can then be used for prediction.
Supervised learning model: The algorithm can calculate the price of a piece of property from the features it is given.
Unsupervised learning model: The algorithm enters a new geographical area, identifies the known area it most resembles, and applies the known area's rules to the new area.
Reinforcement learning model: The algorithm does not predict; it tries again.
Let's Recap!
A model is a mathematical representation that can be used to model rules based on data.
Data modeling has two phases: learning and prediction.
There are three methods an AI program can use to learn: supervised, unsupervised, and reinforcement.
Recently there has been a lot of buzz about a sub-discipline of automated learning known as deep learning. Deep learning can do great things in areas such as image recognition. We’ll explore this in greater detail in the next chapter.
