Utilisez les conteneurs
Après cette brève introduction à la SL et aux éléments venus du C, il est temps de se plonger dans ce qui fait la force de la bibliothèque standard, la fameuse STL.
Pour l'instant, vous ne savez pas ce que sont les templates, nous les découvrirons plus tard. Mais cela ne veut pas dire que vous n'avez pas le niveau requis ! Souvenez-vous de la classe string , vous avez appris à l'utiliser bien avant de savoir ce qu'était un objet. Il en sera de même ici, nous allons utiliser (beaucoup) de templates sans que vous ayez besoin d'en savoir plus à leur sujet.
D'ailleurs, vous en connaissez déjà un : le vector .
Dans ce premier vrai chapitre sur la bibliothèque standard, vous allez découvrir qu'il existe d'autres sortes de conteneurs pour tous les usages. La vraie difficulté sera alors de faire son choix parmi tous ces conteneurs. Mais ne vous en faites pas, je serai là pour vous guider.
Stockez des éléments
Stocker des objets dans d'autres objets est une opération très courante. Pensez par exemple aux collections hétérogènes, lorsque nous avons vu le polymorphisme.
Vous avez appris à utiliser le vector , le membre le plus connu de la STL. Voici un petit rappel :
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<int> tab(5,4); //Un tableau contenant 5 entiers dont la valeur est 4
tab.pop_back(); //On supprime la dernière case du tableau.
tab.push_back(6); //On ajoute un 6 à la fin du tableau.
for(int i(0); i<tab.size(); ++i) //On utilise size() pour connaître le nombre d'éléments dans le vector
cout << tab[i] << endl; //On utilise les crochets [] pour accéder aux éléments
return 0;
}On pourrait se dire que c'est la seule manière de ranger des objets. En tout cas, c'est comme cela que la plupart des gens rangent leur cave ou leurs étagères. Je suis sûr que vous faites de même. Cette manière de ranger des livres sur une bibliothèque est sans doute la plus simple que l'on puisse imaginer. On peut accéder directement au troisième ou au huitième livre en tendant simplement le bras.
Mais pour d'autres opérations, cette méthode de rangement n'est pas forcément la meilleure. Si vous devez ajouter un livre au milieu de la collection, vous allez devoir décaler tous ceux situés à droite. Ici, ce n'est pas un gros travail. Mais imaginez que votre bibliothèque contienne des centaines de livres, tout décaler prendra du temps. De même, ôter un livre au milieu de l'étagère sera coûteux, il va falloir à nouveau tout déplacer !
Ce ne sont pas les seules opérations difficiles à effectuer avec des livres. Trier les livres selon le nom de l'auteur est aussi quelque chose de long et difficile à réaliser. Si le tri avait été effectué au moment où les livres ont été posés pour la première fois, on n'aurait plus à le faire. Par contre, ajouter un livre dans la collection implique une réflexion préalable. Il faut, en effet, placer le livre au bon endroit pour que la collection reste triée. Inverser l'ordre des livres est aussi un long travail dans une grande bibliothèque. Bref, ranger des objets n'est pas aussi simple qu'on pourrait le penser.
Vous l'avez sûrement constaté, toutes les bibliothèques rangent leurs livres les uns à cotés des autres. Mais les informaticiens sont des gens malins. Ils ont inventé d'autres méthodes de rangement. Nous allons les découvrir à partir de maintenant.
Découvrez les conteneurs séquences et les conteneurs associatifs
Les différents conteneurs peuvent être partagés en deux catégories selon que les éléments sont classés à la suite les uns des autres ou non :
Les conteneurs séquences :
vector,deque,list,stack,queue,priority_queue;Les conteneurs associatifs :
set,multiset,map,multimap.
Vous vous dites peut-être qu'apprendre à utiliser des conteneurs différents va demander beaucoup de travail. Je vous rassure tout de suite, ils sont quand même très similaires. Après tout, ils sont tous là pour stocker des objets ! Et comme les concepteurs de la STL sont sympas, ils ont donné les mêmes noms aux méthodes communes de tous les conteneurs.
Par exemple, la méthode size() renvoie la taille d'un vector, d'une list ou d'une map.
Découvrez quelques méthodes communes
La méthode empty()
Parfois, on a simplement besoin de savoir si le conteneur est vide ou pas.
Pour cela, il existe la méthode empty() qui renvoie :
truesi le conteneur est vide ;falses'il ne l'est pas.
list<double> a; //Une liste de double
if(a.empty())
cout << "La liste est vide." << endl;
else
cout << "La liste n'est pas vide." << endl;La méthode clear()
Une autre méthode permet de vider entièrement un conteneur. Il s'agit de clear() :
set<string> a; //Un ensemble de chaînes de caractères
//Quelques actions…
a.clear(); //Et on vide le tout !La méthode swap()
Enfin, on a parfois besoin d'échanger le contenu de deux conteneurs de même type. Plutôt que de devoir copier les éléments un à un et à la main, les concepteurs de la STL ont créé la méthode swap() :
vector<double> a(8,3.14); //Un vector contenant 8 fois le nombre 3.14
vector<double> b(5,2.71); //Un autre vector contenant 5 fois le nombre 2.71
a.swap(b); //On échange le contenu des deux tableaux.
//b a maintenant une taille de 8 et a une taille de 5.Tout cela m'a donné envie d'en savoir plus sur ces conteneurs. Tournons-nous donc vers les séquences.
Utilisez les séquences et leurs adaptateurs
Commençons avec notre vieil ami, le vector .
Les vector , encore et toujours
En réalité, cette méthode est une opération commune à toutes les séquences.
Voici un petit récapitulatif des différentes méthodes :
Méthode | Description |
|---|---|
| Ajout d'un élément à la fin du tableau. |
| Suppression de la dernière case du tableau. |
| Accès à la première case du tableau. |
| Accès à la dernière case du tableau. |
| Modification du contenu d'un tableau. |
Pour l'instant, tournons-nous vers les autres types de séquences.
Les deque , ces drôles de tableaux
Les vector proposent les méthodes push_back() et pop_back() pour manipuler ce qui se trouve à la fin du tableau. Modifier ce qui se trouve au début n'est pas possible.
Les deque lèvent cette limitation en proposant des méthodes push_front() et pop_front() .
#include <deque> //Ne pas oublier !
#include <iostream>
using namespace std;
int main()
{
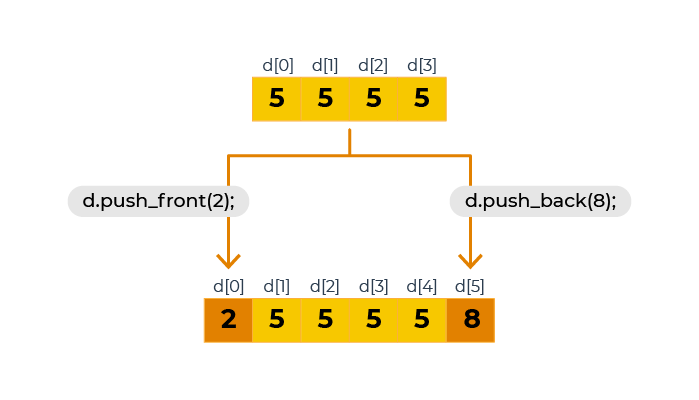
deque<int> d(4,5); //Une deque de 4 entiers valant 5
d.push_front(2); //On ajoute le nombre 2 au début
d.push_back(8); //Et le nombre 8 à la fin
for(int i(0); i<d.size(); ++i)
cout << d[i] << " "; //Affiche 2 5 5 5 5 8
return 0;
}Et pour bien comprendre le tout, je vous propose un petit schéma :
Les stack : une histoire de pile
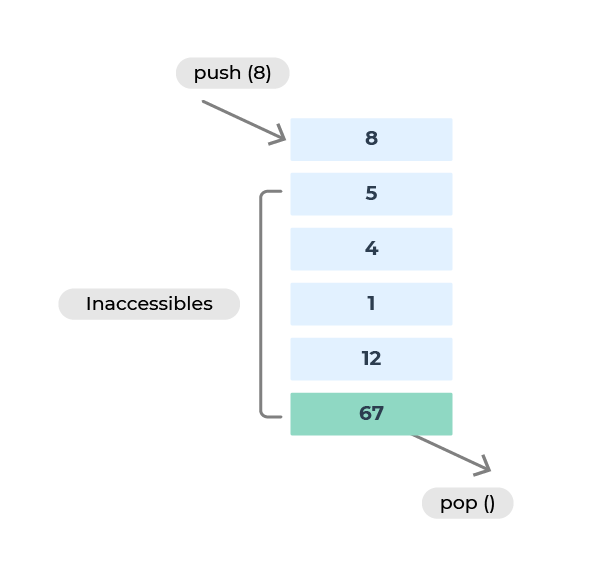
La classe stack est la première structure de données un peu spéciale que vous rencontrez. C'est un conteneur qui n'autorise l'accès qu'au dernier élément ajouté.
En fait, il n'y a que 3 opérations autorisées :
push(): ajouter un élément au début.top(): consulter le dernier élément ajouté.pop(): supprimer le dernier élément ajouté.
Je ne comprends pas bien l'intérêt d'un tel stockage !
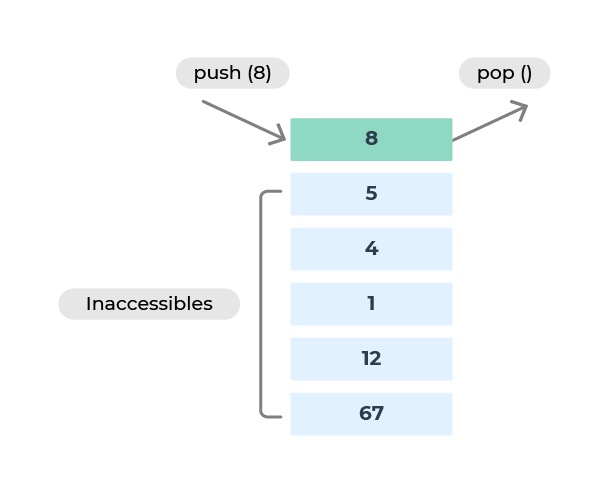
Pour reprendre notre image des assiettes : la dernière assiette sale sur la pile est la première à être lavée, alors que celle arrivée en premier (et qui est donc tout en bas de la pile) sera traitée en dernier.
Un exemple plus informatique serait la gestion d'un stock. On ajoute à la pile le nombre d'articles vendus chaque mois et, pour créer le bilan trimestriel, on consulte les trois derniers ajouts sans s'occuper du reste.
#include <stack>
#include <iostream>
using namespace std;
int main()
{
stack<int> pile; //Une pile vide
pile.push(3); //On ajoute le nombre 3 à la pile
pile.push(4);
pile.push(5);
cout << pile.top() << endl; //On consulte le sommet de la pile (le nombre 5)
pile.pop(); //On supprime le dernier élément ajouté (le nombre 5)
cout << pile.top() << endl; //On consulte le sommet de la pile (le nombre 4)
return 0;
}Peut-être aurez-vous besoin de ce genre de structure un jour. Repensez alors à ce chapitre !
Les queue : une histoire de file
C'est exactement comme dans une file de supermarché. Les gens attendent les uns derrière les autres, et la caissière traite les courses de la première personne arrivée. Quand elle a terminé, elle s'occupe de la deuxième, et ainsi de suite :
Les priority_queue : la fin de l'égalité
Les méthodes sont exactement les mêmes que dans le cas des files simples.
#include <queue> //Attention ! queue et priority_queue sont définies dans le même fichier
#include <iostream>
using namespace std;
int main()
{
priority_queue<int> file;
file.push(5);
file.push(8);
file.push(3);
cout << file.top() << endl; //Affiche le plus grand des éléments insérés (le nombre 8)
return 0;
}On utilise ce genre de structure pour gérer des évènements selon leur priorité, par exemple.
Les list (à voir plus tard)
Finalement, le dernier conteneur sous forme de séquence est la liste. Cependant, pour les utiliser de manière efficace il faut savoir manipuler les itérateurs, ce que nous apprendrons à faire au prochain chapitre. De toute façon, je crois que je vous ai assez parlé de séquences pour le moment. Il est temps de parler d'une tout autre manière de ranger des objets.
Utilisez les tables associatives
Jusqu'à maintenant, vous êtes habitué à accéder aux éléments d'un conteneur en utilisant les crochets [] .
Dans un vector ou une deque , les éléments sont accessibles via leur index, un nombre entier positif. Ce n'est pas toujours très pratique. Imaginez un dictionnaire : vous n'avez pas besoin de savoir que "banane" est le 832e mot pour accéder à sa définition.
Comme le type des indices peut varier, il faut l'indiquer lors de la déclaration de l'objet :
#include <map>
#include <string>
using namespace std;
map<string, int> a;Ce code déclare une table associative qui stocke des entiers, mais dont les indices sont des chaînes de caractères.
On peut alors accéder à un élément via les crochets [] , comme ceci :
a["salut"] = 3; //La case "salut" de la map vaut maintenant 3Si la case n'existe pas, elle est automatiquement créée.
Avec ce nouvel outil, on peut facilement compter le nombre d'occurrences d'un mot dans un fichier. Essayez par vous-même, c'est un très bon exercice. Le principe est simple. On parcourt le fichier, et pour chaque mot on incrémente la case correspondante dans la table associative.
Voici ma solution :
#include <map>
#include <string>
#include <fstream>
#include <iostream>
using namespace std;
int main()
{
ifstream fichier("texte.txt");
string mot;
map<string, int> occurrences;
while(fichier >> mot) //On lit le fichier mot par mot
{
++occurrences[mot]; //On incrémente le compteur pour le mot lu
}
cout << "Le mot 'banane' existe " << occurrences["banane"] << " fois dans le fichier" << endl;
return 0;
}Les map ont un autre gros point fort : les éléments sont triés selon leur clé.
Les autres tables associatives
Les autres tables sont des variations de la map . Le principe de fonctionnement de ces conteneurs est très similaire mais, à nouveau, il nous faut utiliser les itérateurs pour exploiter la pleine puissance de ces structures de données. Je sens que vous allez bientôt avoir envie d'en savoir plus sur ces drôles de bêtes…
En attendant, je vais quand même vous en dire plus sur ces autres structures de données :
Les
setsont utilisés pour représenter les ensembles. On peut insérer des objets dans l'ensemble et y accéder via une méthode de recherche. Par contre, il n'est pas possible d'y accéder via les crochets. En fait, c'est comme si on avait unemapoù les clés et les éléments étaient confondus.Les
multisetetmultimapsont des copies dessetetmapoù chaque clé peut exister en plusieurs exemplaires.
Choisissez le bon conteneur
La principale difficulté avec la STL est de choisir le bon conteneur !
Comme dans l'exemple de la bibliothèque de livres, faire le mauvais choix peut avoir des conséquences désastreuses en termes de performances.
Et puis, tous les conteneurs n'offrent pas les mêmes services :
Avez-vous besoin d'accéder aux éléments directement ?
Ou préférez-vous les trier et n'accéder qu'à l'élément avec la plus grande priorité ?
C'est à ce genre de questions qu'il faut répondre pour faire le bon choix. Et ce n'est pas facile !
Heureusement, je vais vous aider via un schéma. En suivant les flèches et en répondant aux questions posées dans les losanges, on tombe sur le conteneur le plus approprié :
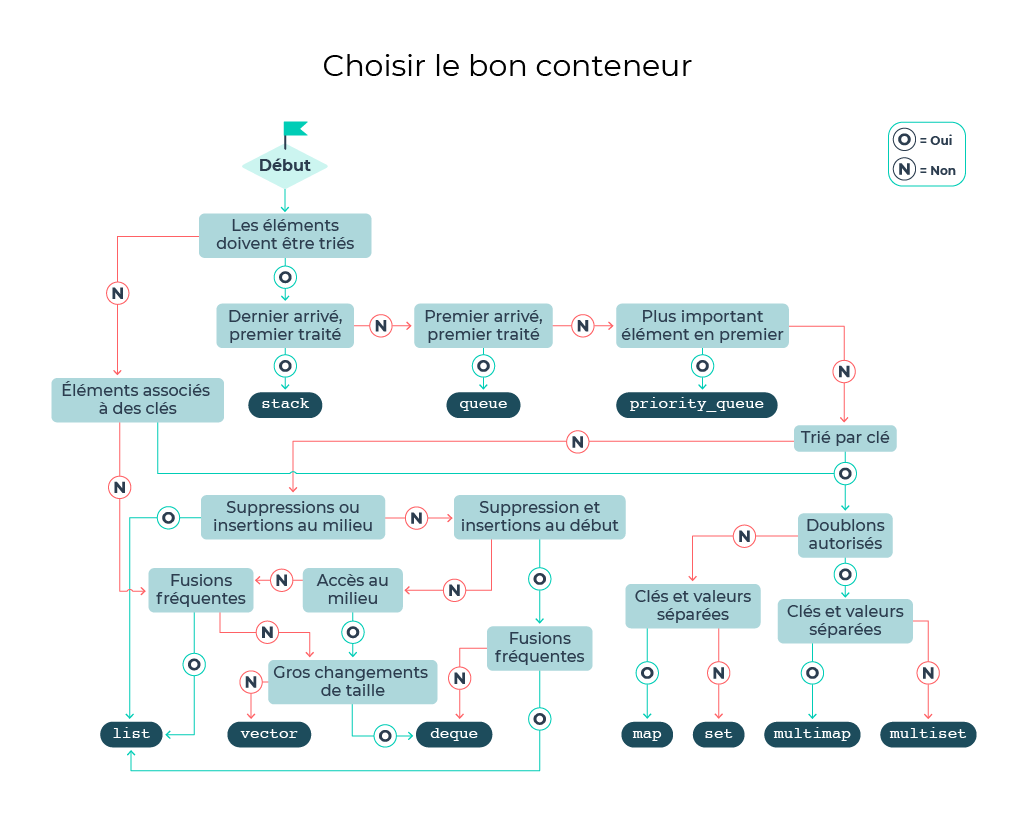
Avec cela, pas moyen de se tromper !
On utilise souvent des vector . Cet outil de base permet de résoudre bien des problèmes sans se poser trop de questions. Et on sort une map quand on a besoin d'utiliser autre chose que des entiers pour indexer les éléments.
Utiliser ce schéma, c'est le niveau supérieur, mais choisir le bon conteneur peut devenir essentiel quand on cherche à créer un programme vraiment optimisé.
En résumé
La STL propose de nombreux conteneurs. Ils sont tous optimisés pour des usages différents.
Les
dequeetvectorpermettent de stocker des objets côte à côte dans la mémoire.Les
mapetsetsont à utiliser si l'on souhaite indexer les éléments contenus avec autre chose que des entiers.Choisir le bon conteneur est une tâche difficile. Sachez que
vectorest le plus fréquemment utilisé. Vous pourrez toujours revenir sur votre décision par la suite si vous avez besoin d'un conteneur plus adapté.
Vous avez pu découvrir la magie du C++ : il est clairement plus simple de gérer les tableaux à l’aide des objets fournis par la bibliothèque standard. Dans le prochain chapitre, vous allez continuer à travailler sur les conteneurs et voir comment manipuler les éléments des conteneurs à l’aide des itérateurs. C'est parti !
