Structurez vos modélisations futures
Vous savez maintenant que le Drift est une composante inévitable du cycle de vie d’un modèle supervisé. On est donc obligé de remplacer nos modèles existants par des versions actualisées, parfois avec de nouvelles features, de nouvelles targets, ou simplement un nouveau jeu d'entraînement.
Sauf qu’il ne suffit pas d'entraîner un nouveau modèle avec de meilleures performances pour pouvoir affirmer qu’on a notre modèle V2. En effet, il faut :
Stocker le modèle dans un dossier sans écraser le précédent pour garder une traçabilité ;
S’assurer qu’on a plusieurs dossiers si on fait plusieurs types de modèles (des modèles par régions, si on reprend l’exemple du projet fil rouge) ;
Stocker les features ;
Stocker les performances du modèle ;
Stocker les jeux de données d’apprentissage et de test utilisés.
Tous ces éléments définissent notre modélisation ! Stocker le modèle sans le reste de ces éléments serait comme acheter le moteur d’une voiture, sans les roues, la carrosserie, le frein et tout le reste ! J’exagère un peu, mais vous voyez l’idée. :D
À force de tester encore et encore des nouveaux modèles, on peut rapidement passer beaucoup de temps à coder et à maintenir la logique de stockage et de chargement des features, des hyperparamètres et des modèles. Si on le fait manuellement, on peut y passer même plus de temps que les modélisations !
Découvrez l’importance de l’Experiment Tracking
En effet, tout comme pour le code avec Git, ces outils nous aident à versionner nos modèles pour garantir une traçabilité de toutes les tentatives de modélisation que nous jugeons pertinentes ! Si correctement utilisés, on ne peut plus avoir comme excuse "j’ai écrasé le chouette modèle que j’ai entraîné la semaine dernière par accident, car je n’ai pas changé l’adresse d’export de mon modèle". :(
Parmi l’ensemble de ces outils, nous allons nous intéresser à MLflow Tracking, qui a l’avantage d’être très populaire encore aujourd’hui et complètement open source. Sa logique est aussi assez proche des autres outils d’Experiment Tracking que vous pouvez trouver chez les Cloud Providers, comme Vertex AI chez GCP ou encore SageMaker Studio chez AWS.
Une fois que vous avez installé la librairie MLflow, ouvrez votre Terminal/PowerShell et lancez la commande :
```(bash)
mlflow ui
```Ceci va créer un serveur local qui pourra s’occuper de toutes les opérations de logging des modèles, features etc.
Dans le Terminal, vous verrez un lien s’afficher avec une forme similaire à celle-ci : 127.0.0.1:5000. Si vous ouvrez votre navigateur web pour aller vers ce lien, vous tomberez sur cette interface, il s’agit du MLflow UI :
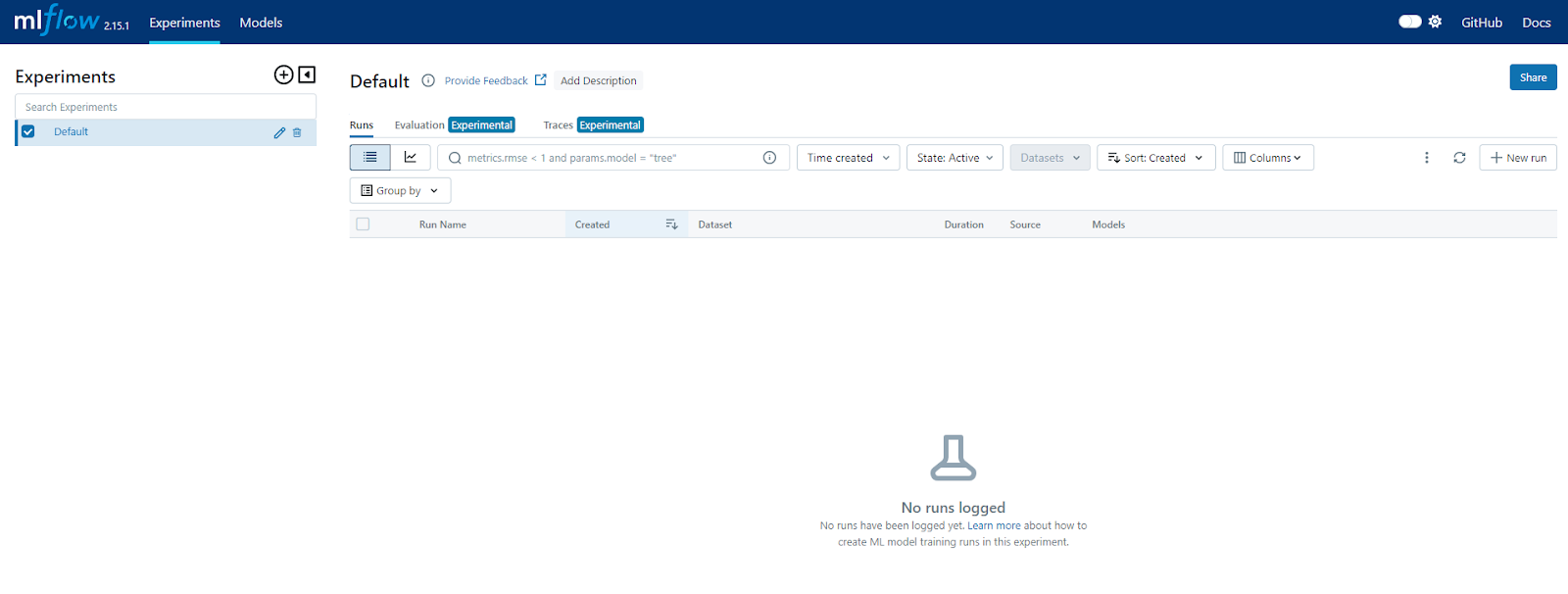
C’est avec cette interface que nous allons visualiser les résultats de nos modélisations !
Pour structurer vos élaborations de modèles. MLflow utilise les concepts suivants :
Runs : Chaque modèle que vous allez entraîner, évaluer et éventuellement stocker va constituer un run.
Experiments : Un experiment est tout simplement un ensemble de runs. Vous devez effectivement expérimenter avec plusieurs modèles pour trouver le meilleur.
Tags : Ce sont des labels que vous pouvez associer à vos experiments pour pouvoir plus facilement les organiser et les retrouver.
Parameters : Des valeurs qui définissent les conditions de votre modélisation. Comme le random state ou encore les hyperparamètres d’un modèle.
Metrics : Tout est dans le nom. ;)
Models : Idem.
Artifacts : Tous les autres fichiers à stocker, autres que le modèle. Les features, les jeux de données d'entraînement et de test, des captures d'écran de matrice de confusion, etc.
Une démonstration de tous ces concepts s’impose ! Lors de ce screencast, nous allons reprendre la donnée du projet fil rouge, réaliser des modèles de classification pour trois régions de notre dataset et comparer pour chacune trois types de modèles :
Réalisez des modèles de classification
Visualisez les experiments
Il n’y a pas de méthode universelle pour structurer votre tracking ! Tout dépend du contexte métier de votre projet et de ses contraintes. Au lieu d’un découpage par régions, on pouvait également imaginer un découpage en un experiment de régression et un autre de classification. Si notre projet fil rouge avait vocation à être utilisé par d’autres pays, on aurait pu imaginer un découpage d’experiments par pays etc.
Avant de clôturer cette introduction à l’Experiment Tracking, voici quelques conseils et astuces qui peuvent vous aider :
Vous êtes loin d’être la première personne à implémenter une régression ou une classification. C’est pour cela que MLflow a construit des templates d’experiments prêt à l’emploi afin de vous faire gagner du temps ! Vous pouvez aller les consulter sur la page MLflow Recipes. Elles sont particulièrement utiles quand votre projet ML ne nécessite pas une évaluation, un cleaning ou un choix de modélisation atypique. Dans le cas contraire, nous vous conseillons de créer à la main vos experiments et vos runs, comme vous l’avez vu pendant le screencast.
Réfléchissez bien à comment vous allez définir vos tags avant d’aller loin dans l’implémentation de vos différents runs ! Il vaut mieux structurer sur le papier les différents éléments que vous souhaitez suivre dans le temps dès le début. Sinon, vous allez devoir rétroactivement tagger des experiments que vous avez déjà faites, ce qui est souvent source d’erreurs.
MLflow s’intègre bien avec les autres librairies que nous avons vues dans cette partie du cours :
Vous pouvez sauvegarder et versionner des objets Explainer de la librairie SHAP si vous avez besoin d’inclure une partie black box opening dans vos experiments.
BentoML peut charger et conteneuriser des modèles versionnés avec MLflow, plutôt que d’utiliser son propre système natif de versioning.
BentoML peut loger des métriques de drift calculées par Evidently, vous pouvez voir ce notebook (en anglais) à titre d’exemple.
Dans cette section, nous avons créé tous nos experiments et versionné tous nos résultats en local sur notre ordinateur. Il est tout à fait possible d’héberger nos experiments et de les requêter dans une plateforme Cloud ou via un format BDD, vous pouvez en savoir plus sur le site de MLflow. Ceci dit, les outils d’Experiment Tracking des Cloud Providers sont conçus pour bien s’intégrer avec leurs autres services propriétaires.
Comprenez les différentes stratégies de deploiement
Grâce à MLflow, nous savons désormais comment travailler méthodiquement pour sécuriser une version améliorée d’un modèle.
Il suffit de conteneuriser et de déployer cette nouvelle version pour remplacer l’ancienne, alors, non ?
C’est en effet la solution vers laquelle on pourrait intuitivement se précipiter, mais elle est rarement la plus pertinente ! Il y a en réalité plusieurs stratégies pour déployer une nouvelle version d’un modèle. Nous allons expliquer celles qui sont le plus utilisées dans le projet ML.
À titre d’illustration, prenons un cas d’usage de notre projet filé :
Nos clients sont des agences immobilières et sont intéressés par des évaluations automatiques des prix de leurs transactions potentielles.
En effet, leurs agents immobiliers examinent manuellement les dossiers de transactions potentielles et nos clients souhaitent réduire leur charge de travail en réorientant le volume des dossiers vers notre modèle.
Notre modèle fournit une prédiction directement au client de l’agent immobilier (c’est-à-dire l’acheteur potentiel du bien), sans passer par ce dernier.
Nous avons déjà déployé une première version du modèle, mais nous avons des retours mitigés. Certains clients de certains départements sont très contents, d’autres voient le potentiel, mais sont réticents. Enfin, certains refusent de l’utiliser, car les prédictions sont trop peu fiables.
Comment déployer un modèle qui satisfasse les trois types de clients que nous avons ?
Commençons par la stratégie dite Shadow Deployment. Il s’agit en réalité d’un faux déploiement du modèle, dans la mesure où notre nouveau modèle partira en production pour réaliser des prédictions, mais celles-ci n’iront jamais vers des acheteurs potentiels d’un bien. Elles resteront “en chambre”.
Pourquoi faire alors ?
Ce type de déploiement serait particulièrement utile pour notre 3ᵉ type de clients, les agences qui refusent d’utiliser le modèle. On peut par exemple missionner certains de leurs agents immobiliers d’examiner à la main les prédictions du nouveau modèle pendant un certain temps afin d’en vérifier la pertinence, sans prendre le risque de décevoir davantage d’acheteurs potentiels avec de mauvaises estimations. Une fois les prédictions validées et l’agence rassurée, nous procédons alors au déploiement “réel” du modèle.
Passons ensuite à ce que l’on appelle le Canary Deployment. L’idée derrière cette stratégie est de garder l’ancienne version du modèle déployée et en première ligne sur la grande majorité des prédictions (par exemple 95% des prédictions sur les nouvelles données entrantes) tout en déployant la nouvelle version du modèle sur un petit trafic de prédiction (les 5% restants) que l’on appelle le périmètre Canary.
Contrairement au Shadow Deployment, cette stratégie permet au nouveau modèle dès le départ de créer de la valeur en envoyant des prédictions aux acheteurs potentiels. En revanche, il faut maîtriser le risque d’avoir une mauvaise expérience client. Pour ce faire, il faut choisir un périmètre Canary relativement peu critique d’un point de vue métier. On pourrait choisir comme exemple de périmètre :
Un département avec relativement peu de transactions ;
La 2ᵉ catégorie d’agences immobilières citée tout à l’heure : les personnes réticentes à l’adopter ;
Un échantillon de transactions de toutes les agences immobilières depuis l’année dernière.
Une fois que l’on est confiant que le nouveau modèle est fiable sur le périmètre Canary, nous pouvons graduellement réorienter le trafic de l’ancien modèle vers le nouveau, avant d’archiver l’ancien modèle.
Enfin, parlons de l'AB Test Deployment. Comme le nom l’indique, cette technique se base sur de l’AB Testing, méthode très connue dans l’e-Commerce et le Marketing Digital pour tester de nouvelles fonctionnalités d’un software. Le chapitre Améliorez la conversion grâce à des tests A/B d’un autre cours d’OpenClassrooms vous explique en détail comment cela fonctionne. ;) Mais en bref :
Scindez votre trafic entrant de données en deux groupes étanches et avec des caractéristiques identiques ;
Toute la nouvelle donnée du premier groupe (groupe A) arrive vers le nouveau modèle ;
Toute la nouvelle donnée du groupe B arrive vers l’ancien modèle ;
Après une certaine durée, nous réalisons un test statistique pour évaluer si le nouveau modèle est meilleur, sans coïncidences, que l’ancien ;
En fonction du résultat, nous choisissons de remplacer ou non l’ancien modèle par le nouveau.
Cette stratégie fonctionnerait pour 1ᵉʳ groupe d’agences immobilières qu’on a défini : ceux qui sont déjà satisfaits du modèle. En effet, nous n’avons pas envie de prendre le risque de dégrader les performances de l’ancien modèle par accident ! De plus, ils ont assez confiance en nous pour accepter d'expérimenter à une échelle plus grande qu'un Canary avec un nouveau modèle.
Comme vous pouvez vous en douter, il n’y a qu’une seule réponse à la question “Quelle stratégie de déploiement adopter ?” Et cette réponse est, “Ça dépend”.
Voici quelques questions que vous pouvez vous poser pour alimenter votre réflexion sur le choix de votre stratégie :
Quelle est la nature et le degré de l’intervention humaine concernant les résultats de mon modèle ? Si vous êtes dans un contexte à 100% B2C, où il n’y a pas d’humain dans la boucle entre la décision du modèle et le client, un Shadow Deployment serait moins intéressant, car la seule façon d’avoir un retour sur la qualité de votre modèle… est de le déployer.
Combien de temps puis-je me permettre de maintenir deux modèles en parallèle ? Toutes les approches citées précédemment supposent la coexistence de deux modèles en simultané. Ceci a un coût technique et métier.
Technique, parce que vous n'avez pas simplement deux algorithmes, mais deux infrastructures complexes en production à maintenir (des images Docker, des pipelines de création de features, des machines virtuelles dans le Cloud, des scripts d’évaluation de performances etc.). Sur la durée, le coût d'infrastructure peut devenir onéreux, sans compter le temps et de l’effort nécessaire pour mettre en place et maintenir les deux infrastructures ;
Métier, car si votre premier modèle est nul, vous ne pouvez pas vous permettre de faire un Shadow, Canary ou AB Test Deployment pendant 6 mois pour être sûr que votre 2ᵉ modèle est assez bon pour le remplacer. D’ici là vous aurez déjà perdu la confiance de vos clients !
À quel point suis-je capable de créer deux groupes identiques de données pour la comparaison ? En cas de Canary ou d’AB Test Deployment, si les deux périmètres de données sont très différents (en termes de features) les uns des autres, alors cela biaisera la comparaison des deux modèles. L’un réalisera des prédictions sur des choux, l’autre sur des carottes. En pratique, il n'est pas toujours facile de façonner nos deux groupes pour qu’ils soient similaires.
D’un point de vue technique, la majorité des plateformes de déploiement de modèles (Vertex AI, Azure Machine Learning, AWS SageMaker etc.) vous proposent des outils pour mettre en place ces différentes stratégies. Vous pouvez en savoir dans cet article sur les meilleurs outils pour le déploiement de modèles de ML (en anglais).
Schématisez le cycle de vie d’un modèle d’apprentissage
Comme promis, nous allons enfin revenir vers le schéma complet du déroulé d’un apprentissage supervisé, tel que nous l’avions présenté au tout premier chapitre de cours !
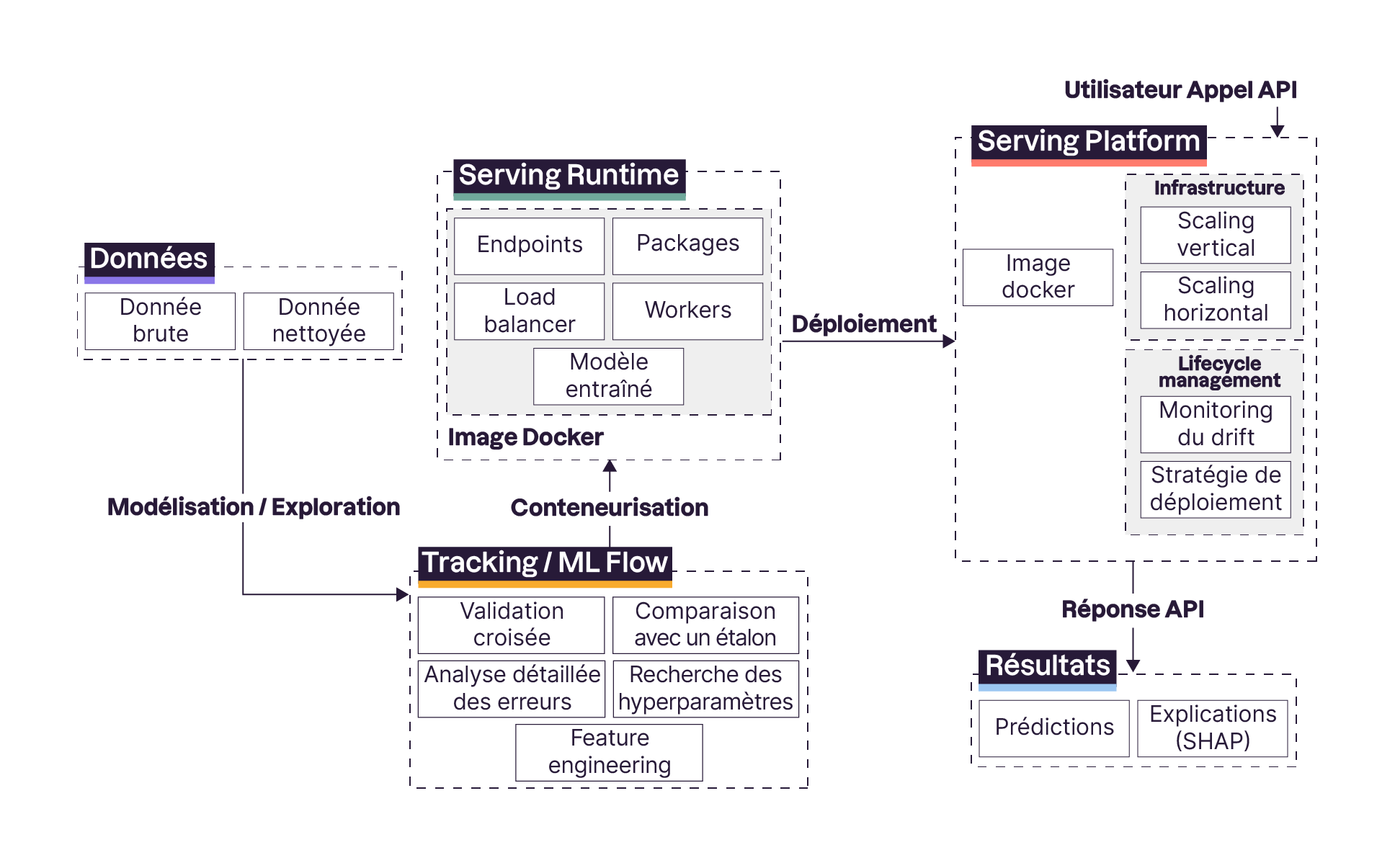
Non seulement vous l’avez déjà vu quelques fois depuis, mais en plus, vous avez toutes les clés en main pour le comprendre dans sa totalité. Décomposons-le ensemble.
La partie Feature Engineering a été délibérément déplacée vers une nouvelle section liée à l’Experiment Tracking avec MLflow. C’est effectivement tout l'intérêt de l’Experiment Tracking, nous améliorons notre modélisation de manière itérative en testant plusieurs nouvelles pistes, qu’elles soient des modèles, des features et nous versionnons le tout avec un outil comme MLflow. Tous nos choix techniques pour évaluer le modèle (validation croisée, métriques et graphiques d’analyse avancée des erreurs) définissent les Runs de nos Experiments au sein de MLflow.
Une fois que nous avons sécurisé un bon modèle, nous allons nous préparer à le déployer. Avec BentoML ou le service d’un Cloud Provider, il faudra conteneuriser notre projet ML afin que notre modélisation soit reproductible dans une autre machine. Il s’agit de la partie Serving Runtime.
Dans une Serving Platform, nous mettons à disposition une infrastructure en ressource physique (une ou plusieurs machines) pour héberger notre projet conteneurisé, c’est ce qui finalise le déploiement de notre modèle. Ces Serving Platforms nous proposent souvent les stratégies de déploiement que nous avons vu lors de ce cours, voire d’autres. On peut également implémenter toute sorte de monitoring personnalisé via des scripts Python, en utilisant par exemple Evidently. Toutes ces tâches constituent la gestion du cycle de vie d’un modèle de ML (ou ML Lifecycle Management), qui elle-même fait partie du vaste domaine qu’est le MLOps.
Enfin, via une API ou non, le cœur de tout ce système reste notre algorithme de ML, qui produit des prédictions. Nous pouvons également passer par des outils de XAI (comme SHAP) pour fournir des explications de ces prédictions.
🥳 Vous voici arrivé au bout de ce cours sur l'apprentissage supervisé ! Félicitations ! Vous l'avez compris, la compétence incontournable dans la Data est la curiosité. Mon conseil final est alors de rester curieux et à jour avec les nouvelles tendances du domaine. Je vous souhaite beaucoup de réussite dans vos projets ML futurs !
À vous de jouer !
Comme expliqué au début du screencast, nous avons simulé une évolution de notre donnée et de notre modélisation en créant deux périmètres :
Le 1ᵉʳ couvre la période pré-covid (avant 2020) et se limite à quelques features ;
Le 2ᵉ couvre la période covid (2020 et 2021) et bénéficie de features supplémentaires.
Nous avons créé des experiments et des runs concernant le 1ᵉʳ périmètre, mais nous laissons le 2ᵉ à votre charge !
Limitez-vous à la région Nouvelle-Acquitaine et créez un nouveau run avec MLflow. Ensuite, utilisez la fonctionnalité search_experiments pour comparer les performances de votre run avec celles du 1ᵉʳ périmètre.
Vous pouvez partir de ce notebook template.
Une fois que vous avez fini, vous avez ce corrigé à disposition.
En résumé
Le drift est un phénomène inévitable dans le cycle de vie d’un modèle ML, nécessitant parfois de remplacer les modèles existants par des versions actualisées avec de nouvelles données, features ou targets.
L’Experiment Tracking est essentiel pour versionner vos modèles, les features, et les jeux de données utilisés. Des outils comme MLflow facilitent ce processus en stockant et organisant tous les éléments essentiels liés à vos expériences de modélisation.
La gestion des nouvelles versions de modèles nécessite une stratégie de déploiement réfléchie. Des approches comme le Shadow Deployment, le Canary Deployment ou l’A/B Test Deployment permettent d’introduire progressivement un nouveau modèle tout en minimisant les risques.
La traçabilité et la planification du déploiement doivent être prises en compte dès le début d’un projet de modélisation. Des outils comme MLflow pour le tracking, et BentoML ou des services Cloud pour le déploiement, s'intègrent dans ce cycle de vie du modèle.
Le cycle de vie d'un modèle inclut la modélisation, le déploiement, la gestion des versions, et le suivi de performance pour assurer sa robustesse et sa pertinence sur le long terme.
Maintenant que vous êtes prêt à structurer vos futures modélisations, il est temps de tester vos connaissances avec un dernier quiz !
