Découvrez les concepts clés
Visualisez l’apprentissage supervisé en schéma
À ce stade, vous savez qu’on ne peut pas construire de modèle de Machine Learning sans données. Plus spécifiquement, par “données”, on entend un fichier avec :
Une colonne cible (dénommée conventionnellement
y) que le modèle va tenter de prédire pendant son apprentissage.yUn ensemble de colonnes et de lignes (dénommé conventionnellement
X) qui représentent les variables et les échantillons dont le modèle va se servir comme ingrédients pour son apprentissage.X
Ainsi, si on voulait esquisser le schéma le plus terre à terre possible d’une modélisation supervisée, on pourrait se restreindre aux blocs suivants.
Données —> Modèle —> Predictions
On ne peut pas faire plus simple ! Au fur et à mesure que l’on avance dans le cours, nous allons reprendre le schéma pour le complexifier petit à petit jusqu’à arriver à ce schéma final.
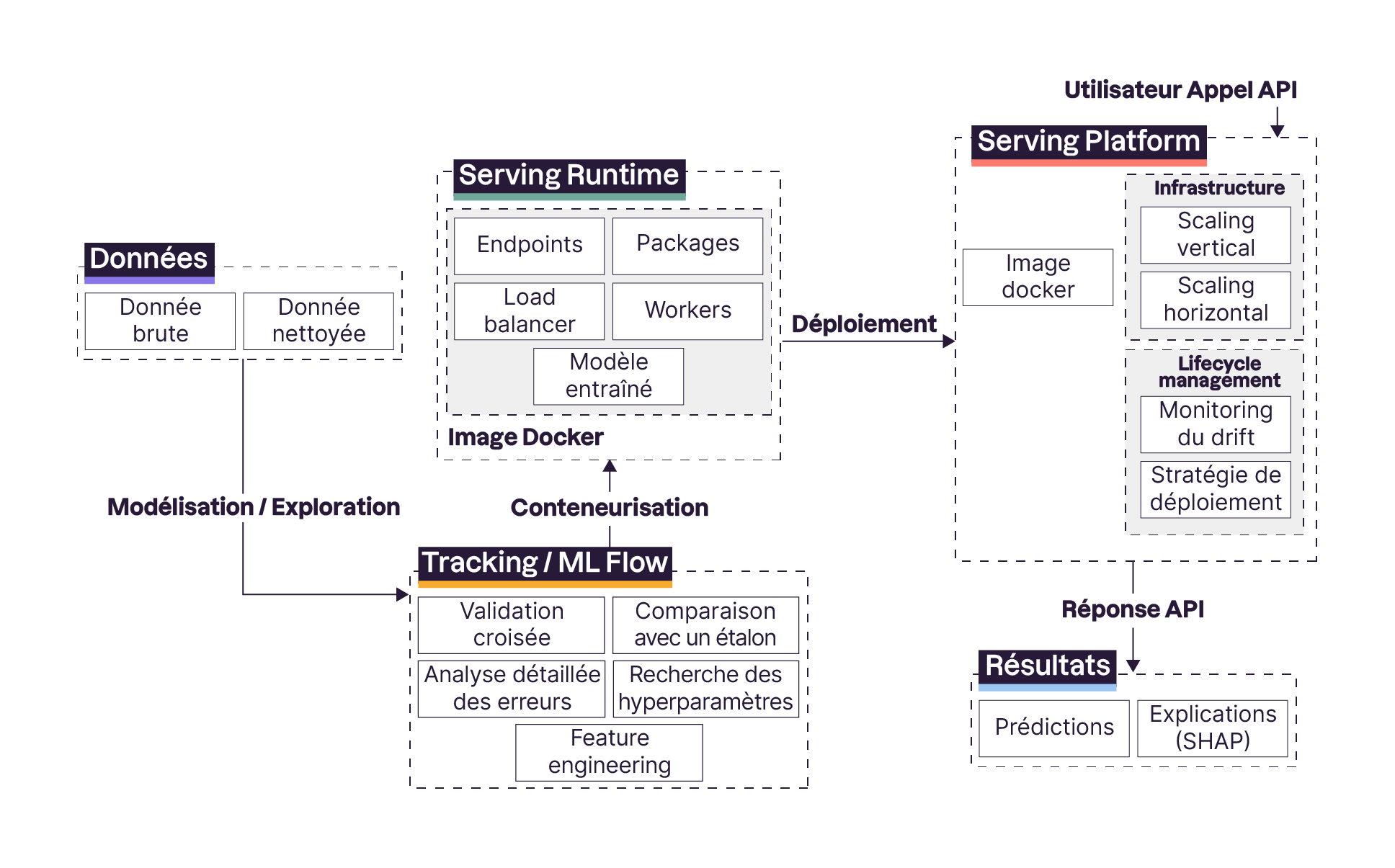
Ouf ! Ça pique aux yeux ! Mais ne vous en faites pas, d'ici à la fin de ce cours, vous aurez parfaitement compris ce schéma et comment les briques interagissent les unes avec les autres. ;)
Découvrez l’approche de régression la plus simple
Quand on parle de modèles de régression en Machine Learning, on ne peut pas faire plus simple que la régression linéaire ! Ce chapitre du cours d’initiation explique en détail le fonctionnement de l’algorithme. Mais en une phrase, la régression linéaire dit : “Je suis capable d’expliquer la target en trouvant la meilleure moyenne pondérée de mes features.”
En effet, quand on entraîne le modèle, la régression linéaire va tester sous le capot plusieurs pondérations (ou coefficients) possibles et déterminer celle qui se rapproche le plus de la target.
Une façon plus schématique de dire la même chose : Si on ne travaille qu’avec une feature et la target, la régression linéaire essaye de trouver, pendant son apprentissage, la droite qui colle le mieux au nuage de points formés par la feature dans l’axe X et la target dans l’axe Y. Ci-dessous un exemple avec notre jeu de données des transactions immobilières.
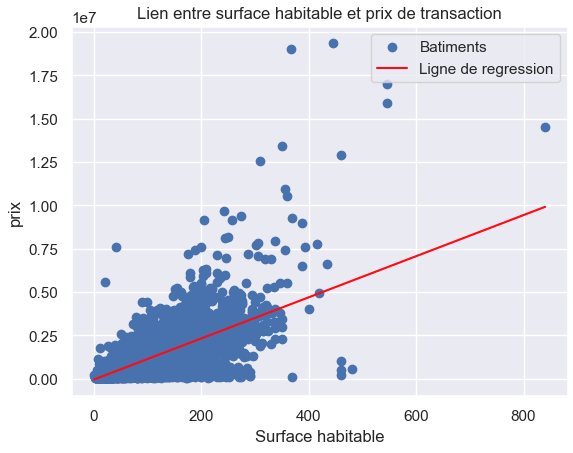
C’est pour cela qu’on appelle ce modèle “linéaire” ! C’est littéralement une ligne qui est utilisée pour approximer la target.
Dans l’exemple de la capture d'écran précédente la moyenne pondérée est : Prix de la transaction = 11871 * Surface Habitable + 53605 . Ce qui signifie que pour un bien de 100 m2, la valeur estimée du bien sera de 1 240 705 €, et si le bien fait 10 m2 de surface habitable de plus (suite à des travaux par exemple), alors la valeur du bien estimée par la régression linéaire augmenterait de 118 710 €. Le raisonnement reste identique quand on a plusieurs features !
REGRESSION_TARGET = "prix"
from sklearn.linear_model import LinearRegression
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
import polars as pl
"""
On se restreint au périmètre de la capture d'écran;
Ici nous utilisons la syntaxe de Polars. Mais un équivalent Pandas serait
transactions_regression_2D = transacations[
(transactions["departement"] == 75)
& (transactions[REGRESSION_TARGET] >= transactions[REGRESSION_TARGET].quantile(0.1))
][["surface_habitable", REGRESSION_TARGET]]
"""
transactions_regression_2D = transactions.filter(
pl.col("departement") == 75,
pl.col(REGRESSION_TARGET) >= pl.quantile(REGRESSION_TARGET, 0.1),
).select(["surface_habitable", REGRESSION_TARGET])
# On crée un modèle de régression linéaire qui essaie d'expliquer la target à partir de la feature choisie
linear_regressor_2D = LinearRegression()
"""
A l'heure d'écriture de ce code, Scikit-learn ne supporte pas les Polars DataFrame directement.
Il faut alors réaliser une conversion en numpy array, le format au coeur de la majorité des opération Scikit-learn aujourd'hui
"""
linear_regressor_2D.fit(
transactions_regression_2D["surface_habitable"].to_numpy().reshape(-1, 1),
transactions_regression_2D[REGRESSION_TARGET].to_numpy(),
)
# On trace un nuage de points classique des batiments
plt.scatter(
transactions_regression_2D["surface_habitable"],
transactions_regression_2D[REGRESSION_TARGET],
label="Batiments",
)
# Simulation de points factices, simplement pour générer la droite
surface_habitable_range = np.linspace(
transactions_regression_2D["surface_habitable"].min(),
transactions_regression_2D["surface_habitable"].max(),
100,
).reshape(-1, 1)
predictions = linear_regressor_2D.predict(surface_habitable_range)
# Ajout de la ligne de regression
plt.plot(surface_habitable_range, predictions, color="red", label="Ligne de regression")
plt.xlabel("Surface habitable")
plt.ylabel(REGRESSION_TARGET)
plt.title("Lien entre surface habitable et prix de transaction")
plt.legend()
plt.show()Parlons maintenant des avantages et des inconvénients de cet algorithme !
Les deux principaux avantages de la régression linéaire sont les suivants :
C’est un modèle extrêmement simple à présenter à des interlocuteurs peu techniques. En effet, un chef de projet impliqué dans un projet de Machine Learning utilisant une régression linéaire peut rapidement comprendre, avec un niveau basique en statistiques, comment le modèle fonctionne et comment ses features l’influencent. Il n’aura pas à vous inviter régulièrement à des réunions pour expliquer à d’autres interlocuteurs pourquoi votre modèle marche aussi bien :p. Très agréable, n’est-ce pas ?
C’est un modèle très léger en comparaison aux autres qu’on verra plus tard, son entraînement ne demande pas de puissance de calcul énorme. On peut donc facilement le ré-entraîner, le tester sur d’autres données, etc.
En revanche, la régression linéaire ne manque pas de défauts :
Rares sont les jeux de données “linéaires”, c’est-à-dire les jeux de données où il existe réellement une moyenne pondérée des features qui colle bien à une cible.
Par rapport aux autres modèles de ML, la régression linéaire est particulièrement sensible aux outliers : Si vous avez des valeurs aberrantes ou extrêmes dans vos features ou vos cibles, ils vont empêcher la “ligne droite” de coller aux observations “normales” et donc fausser votre modèle. La capture d'écran de tout à l’heure illustre un peu ce phénomène : les outliers avec une surface habitable de 370 et 450 m2 tirent vers le bas la ligne qui devrait suivre plus la tendance vers le haut de la donnée et si vous supprimez les filtres appliqués sur la donnée en amont, cela devient clairement visible.
La régression linéaire est très sensible à l’ordre de grandeur de vos features. En cas de grande disparité entre les ordres de grandeurs, les features avec une petite échelle de valeurs (comme par exemple les features catégorielles encodées avec un OneHotEncoder, dont vous trouverez un rappel dans le chapitre Transformez les variables) vont être complètement ignorées par la régression pendant son apprentissage ! Dans cette situation, vous devez réaliser, avant d'entraîner votre régression linéaire, un scaling de vos variables quantitatives. Nous verrons cela avec plus de détails lors du chapitre suivant.
La régression linéaire ne peut être fiable qu’après avoir suivi une démarche de préparation de la donnée plus rigoureuse que pour d’autres modèles. En effet, cet algorithme n’est fiable que sous certaines hypothèses très contraignantes… Nous n’allons pas les expliciter ici.
Découvrez l’approche de classification la plus simple
Passons à la classification maintenant !
L’algorithme le plus simple ici est la régression logistique. Je vous mets ici comme rappel le lien vers le chapitre Classifiez les données avec la régression logistique du cours d'initiation, qui explique en détail le fonctionnement de cet algorithme, y compris pourquoi on appelle cet algorithme “régression” alors qu’il ne fait pas de la régression. ;)
Mais en une phrase, la régression logistique dit : “Je suis capable de classifier une observation, en trouvant la meilleure version possible de la fonction logistique (aussi appelée sigmoïde) appliquée aux features.”
La régression logistique emploie comme moyen la fonction sigmoïde, car elle est spécifiquement conçue pour calculer des probabilités à partir de features, tout en étant une fonction relativement simple. Ainsi, entraîner une régression logistique revient à tester sous le capot plusieurs “formes” de fonctions sigmoïdes. Chaque forme étant définie par des coefficients ou des pondérations sur les features !
Eh oui ! On trouve aussi une moyenne pondérée dans la régression logistique, sauf qu’elle est indirecte. La formule mathématique le démontre :
fonction_sigmoide(observation) = 1/ 1 + e(coeff_1*feature_1 + coeff_2*feature_2 etc.) On va parler de ces coefficients dans un instant. D’abord, citons les qualités de la régression logistique :
Tout comme la régression linéaire, il s’agit d’un algorithme très léger en termes de puissance de calcul.
Contrairement à la régression linéaire, il n’y a pas de démarche rigoureuse spécifique à suivre pour préparer la donnée avant l'entraînement. On peut donc plus rapidement mettre en place une modélisation avec cet algorithme !
En revanche, quand il s’agit des inconvénients :
Les “coefficients” ou “pondérations” ne sont pas si simples à interpréter. En effet, vu que la moyenne pondérée est cachée dans la fonction sigmoïde, il serait alors faux d’employer le même raisonnement que celui présenté plus haut pour la régression linéaire. C’est un autre raisonnement, plus indirect, qui rentre en jeu en utilisant ce qu’on appelle les log-odds. Ce n’est pas un des concepts les plus utilisés dans des projets ML, donc nous vous renvoyons à cet article sur Towards Data Science (en anglais) comme lecture d’approfondissement pour les plus curieux d’entre vous ;). Mais en résumé, l’argument “linéaire = plus simple à expliquer à un interlocuteur peu technique” est clairement moins fort ici que pour la régression linéaire.
Comme il s’agit également d’un modèle linéaire, la régression logistique n’est pas très utilisable dans la majorité des jeux de données avec des features et des targets complexes.
Mais si la régression logistique est aussi un modèle linéaire, alors à quel moment cet algorithme essaie de coller une ligne droite entre une feature et la cible, comme dans l’exemple de la régression linéaire ?
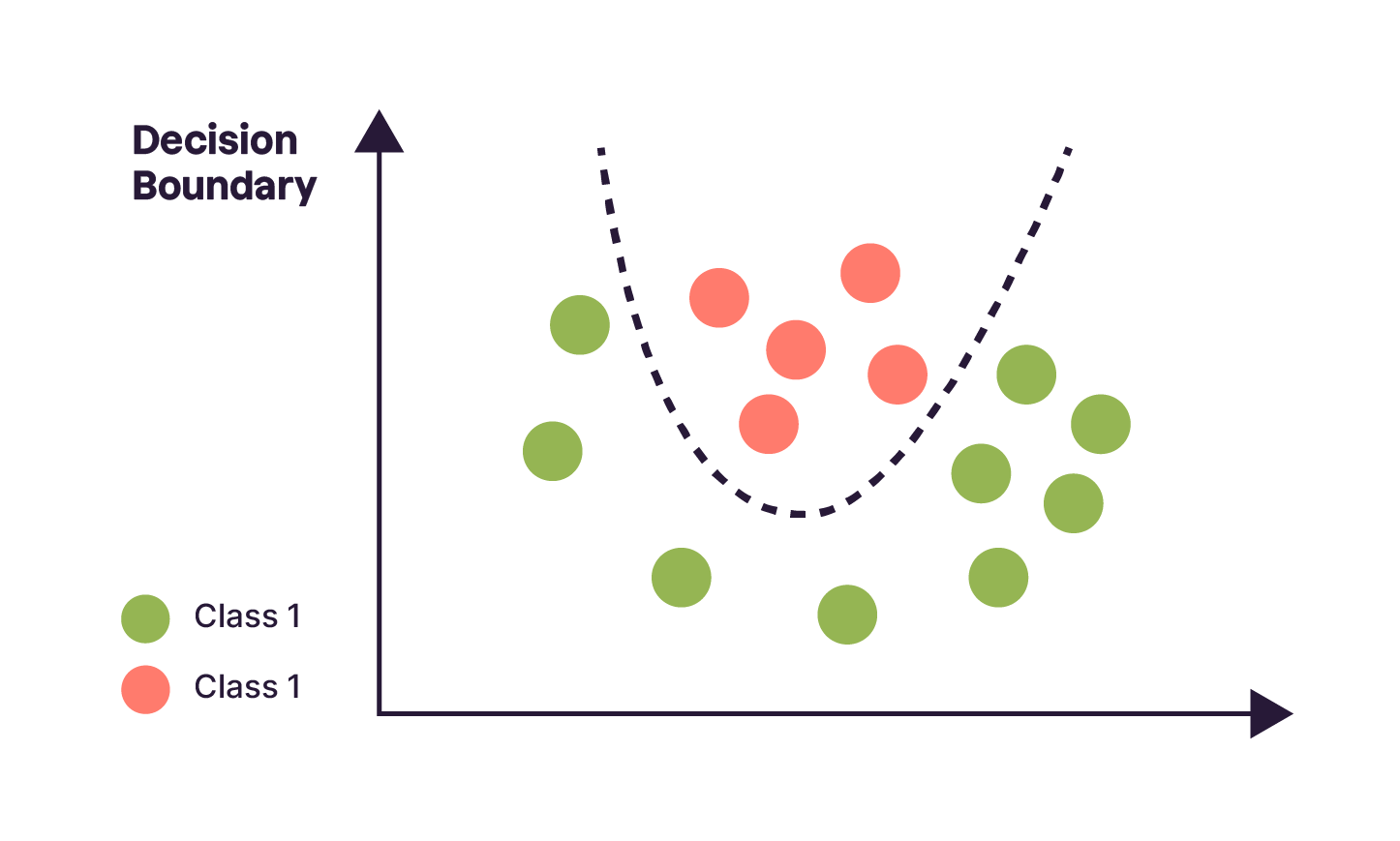
Excellente question ! Mais avant de pouvoir y répondre, il faut d’abord qu’on explique ce qu’est le concept de decision boundary (ou frontière de décision en français).
Quand un modèle de Machine Learning apprend à classifier des données, il apprend à tracer des courbes pour séparer les observations appartenant à des classes différentes (comme de vraies frontières entre des pays). Le graphique ci-dessous montre deux exemples de decision boundaries que deux algorithmes différents ont tracées suite à leur entraînement sur un jeu de données à base de 2 features !
Reprenons notre jeu de données sur l’immobilier. Nous allons cette fois-ci entraîner une régression logistique en utilisant deux features et la target. Voici à quoi ressemble la frontière de décision du modèle quand on la trace :
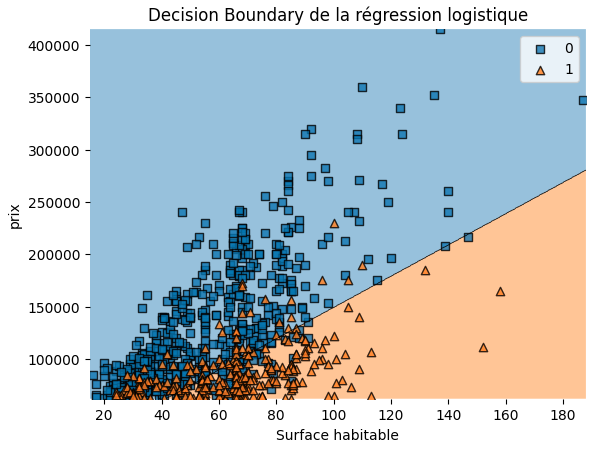
Comme on peut le voir, c’est au niveau de la decision boundary que l’on retrouve le côté linéaire de la régression logistique ! Puisque le modèle n’est pas parfait, on voit par exemple que certains bâtiments de la classe 1 (classe des bâtiments significativement en dessous de la moyenne des prix de transaction de la ville) ont été placés à tort par le modèle dans la zone bleue des bâtiments de la classe opposée.
Voici le code utilisé :
CLASSIFICATION_TARGET = "en_dessous_du_marche"
from mlxtend.plotting import plot_decision_regions
from sklearn.linear_model import LogisticRegression
# Nous choissons ces 2 features uniquement pour illustrer le concept !
transactions_classification_3D = transactions.filter(
pl.col("departement") == 4,
pl.col(REGRESSION_TARGET) >= pl.quantile(REGRESSION_TARGET, 0.1),
).select(["surface_habitable", REGRESSION_TARGET, CLASSIFICATION_TARGET])
# On entraine notre regression logistique
logistic_regressor = LogisticRegression()
X = transactions_classification_3D.select(["surface_habitable", "prix"]).to_numpy()
y = transactions_classification_3D[CLASSIFICATION_TARGET].to_numpy()
logistic_regressor.fit(X, y)
# Nous faisons appel à cette librairie pour tracer la frontière de décision
plot_decision_regions(X, y, clf=logistic_regressor, legend=2)
plt.xlabel("Surface habitable")
plt.ylabel(REGRESSION_TARGET)
plt.title("Decision Boundary de la régression logistique")
plt.legend()
plt.show()Reconnaissez les modèles linéaires vs non-linéaires
Dans la majorité des projets de ML supervisés à succès, on y trouve derrière un modèle non-linéaire. Ils sont naturellement plus adaptés, étant donné qu’une target a rarement un lien linéaire avec ces features.
On sacrifie donc l’interprétabilité des modèles linéaires pour chercher de la performance. En effet, avoir des modèles simples à comprendre, c’est bien, mais s’ils ne sont pas fiables après leur entrainement, ils ne servent à rien !
En reprenant la donnée du projet fil rouge, voici à quoi ressemble la décision boundary d’un modèle linéaire de type Random Forest.
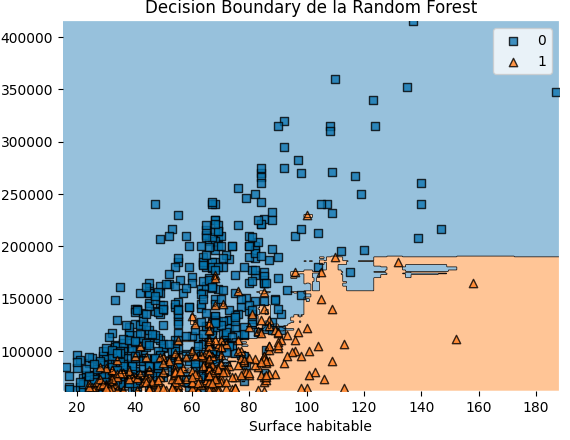
On a un modèle qui est beaucoup plus sophistiqué dans sa classification des points. Les deux exemples les plus parlants dans la capture d'écran sont :
Les trois bâtiments bleus valant 200k euros avec une surface de 120m2. On voit comment le modèle a contourné ces trois points pour ne pas les classifier à tort dans la zone orange, alors qu’il existe un bâtiment orange juste à côté du bâtiment bleu le plus à gauche.
Le bâtiment orange isolé valant à peu près 225k euros avec une surface habitable d’un peu plus de 100m2. En regardant de près, vous verrez que le modèle a créé une micro-zone orange au sein de la zone bleue afin de classifier correctement ce bâtiment ! Impressionnant n’est-ce pas ? ;)
D’un point de vue code, on reprend exactement le même script que pour la régression logistique, sauf qu’on va importer de Scikit-learn le modèle Random Forest :
from sklearn.ensemble import RandomForestClassifier
# On entraine notre Random Forest
rf_classifier = RandomForestClassifier()
rf_classifier .fit(X, y)
# Nous faisons appel à cette librairie pour tracer la frontière de décision
plot_decision_regions(X, y, clf=rf_classifier , legend=2)
plt.xlabel("Surface habitable")
plt.ylabel(REGRESSION_TARGET)
plt.title("Decision Boundary de la Random Forest")
plt.legend()
plt.show()Alors le risque inévitable qui vient avec des modèles non-linéaires, c’est que leur puissance peut facilement résulter en un overfit (concept avec lequel vous devez être à l’aise après avoir lu le chapitre Améliorez le modèle du cours d’initiation), si votre jeu de données est trop "simple", ou alors si vous choisissez certains hyperparamètres du modèle. Nous allons évoquer dans les deux prochains chapitres quelques pistes connues pour combattre l’overfit.
Nous avons montré un exemple avec de la classification, mais le raisonnement reste le même avec la régression : les modèles ne vont pas essayer de faire coller une ligne à la donnée, mais une courbe, ou alors un ensemble de zones au sein desquelles une valeur est prédite et ainsi de suite… Dans le chapitre Augmentez la robustesse de vos modèles du cours d’initiation, vous avez un exemple visuel de modèle non-linéaire de régression utilisant l’algorithme de régression polynomial.
Dois-je connaître dans le détail les différences entre le fonctionnement des algorithmes ?
Ça ne ferait de mal à personne, mais ce ne serait pas le meilleur usage de votre temps. On explique pourquoi dans la toute première section du chapitre qui suit. ;) Mais en attendant, je peux vous conseiller, une fois que vous avez fini ce cours, d’aller comprendre dans le détail :
le fonctionnement d’un arbre de décision CART ;
le fonctionnement du concept de bagging ;
le fonctionnement du concept de boosting ;
le fonctionnement d’une rétro-propagation en Deep Learning.
Nous avons présenté ici un modèle de type Random Forest (extrêmement répandu, et qui se base sur le principe du bagging justement) de la librairie Sklearn. Mais la démarche d’utilisation dans un projet de ML est quasiment identique pour la plupart des autres modèles.
Pendant ce cours, nous allons majoritairement utiliser Scikit-Learn, mais nous allons également montrer de temps en temps quelques autres frameworks. D’ailleurs, dans l’exercice qui suit, vous allez vous servir du package statsmodels, qui vous donne des informations beaucoup plus riches sur l’utilisation de la régression linéaire.
À vous de jouer !

Réalisez votre première régression linéaire multiple en suivant l'approche de "backwards élimination" (mentionné dans l’article de ML mind cité tout à l’heure) que seule la régression linéaire exige.
Commencez par compléter le template de code pré-rempli dans le GitHub.
Ici, on se fiche de la performance du modèle et de la qualité de notre préparation de la donnée. L'exercice a deux objectifs :
Vous familiariser avec le processus d'élimination backwards de la régression linéaire en utilisant statsmodels (malheureusement, scikit-learn n'est pas très fort là-dessus).
Prendre plus d'aisance avec l'interprétation des coefficients des features après avoir entraîné une régression linéaire.
Une fois que vous avez fini, vous avez le corrigé à disposition.
En résumé
L'apprentissage supervisé utilise des données comprenant des features (X) et une target (y) pour entraîner un modèle à réaliser des prédictions.
La régression linéaire est un modèle simple qui ajuste une ligne pour prédire la target en fonction des features, mais il est sensible aux outliers et peut nécessiter un scaling approprié des variables.
La régression logistique, bien qu'elle porte le terme "régression", est utilisée pour la classification. Elle estime la probabilité qu'une observation appartienne à une classe spécifique, en utilisant la fonction sigmoïde pour calculer ces probabilités.
Les modèles non-linéaires sont plus performants et adaptatifs que les modèles linéaires, mais ils présentent certains risques s'ils ne sont pas bien régulés.
Maintenant que vous avez exploré les concepts essentiels, il est temps de commencer à préparer vos données !
