Mettez en place des procédures et fonctions stockées
Après avoir facilité l'accès aux données grâce aux vues, Sofia et Rodolphe se tournent désormais vers l'automatisation de certaines tâches répétitives. Sofia souhaite que l'équipe se concentre sur des analyses stratégiques plutôt que de perdre du temps à exécuter des requêtes manuellement tous les jours.
Vous trouvez un message de Rodolphe dans Slack :
Salut,
J’ai une nouvelle mission pour toi ! On va devoir mettre en place des procédures stockées et des fonctions personnalisées (UDF) pour automatiser et centraliser certaines des opérations clés dans la base DVD Rental. Cela nous aidera à réutiliser plus facilement des logiques complexes et à assurer la cohérence des calculs dans toute la base.
En plus, tu vas voir comment déclencher ces procédures automatiquement, ce qui devrait réduire les erreurs humaines. On compte sur toi pour optimiser tout ça !
Merci !
Définissez une fonction personnalisée
Voici quelques cas d’usages d’une UDF :
Réutilisation : Une UDF peut être appelée dans plusieurs requêtes, évitant de répéter le même code.
Facilité de maintenance : Si une modification est nécessaire, elle est effectuée au niveau de la fonction et sera automatiquement appliquée à toutes les requêtes qui l'utilisent.
Centralisation : Plutôt que de disperser la logique dans plusieurs requêtes SQL, vous pouvez la regrouper au sein d'une UDF, assurant ainsi une plus grande cohérence dans l'application des règles métier.
Voyons à présent la sémantique d’une UDF et ses paramètres associés.
Des paramètres ? C’est-à-dire ?
Une UDF est définie avec un ou plusieurs paramètres, permettant de passer des valeurs en entrée pour traiter des calculs ou manipulations spécifiques. En PostgreSQL, une UDF peut retourner un seul résultat ou une table entière, selon sa définition.
La syntaxe d’une UDF est la suivante :
CREATE [or REPLACE] FUNCTION function_name(param_list)
RETURNS return_type
LANGUAGE plpgsql
as
$$
DECLARE
-- déclaration des variables
BEGIN
-- logique de code
END;
$$;Explication :
CREATE [or REPLACE] FUNCTION function_name(param_list): Cette commande crée une nouvelle fonction avec le nomfunction_name. L'option or replace permet de remplacer une fonction existante avec le même nom.param_list: La liste des paramètres que la fonction prend en entrée. Chaque paramètre est défini avec un nom et un type de données.RETURNS return_type: Définit le type de données que la fonction retourne. Cela peut être un type simple (comme integer, text) ou composite (comme table).LANGUAGE plpgsql: Indique que la fonction est écrite en PL/pgSQL, le langage procédural de PostgreSQL.DECLARE: Section optionnelle où l’on peut déclarer des variables locales à utiliser dans la fonction.BEGIN ... END: Contient la logique de la fonction, où vous pouvez écrire des instructions SQL et PL/pgSQL (boucles, conditions, etc.). C'est ici que le traitement est effectué.$$: Délimiteur pour définir le bloc de code PL/pgSQL.
Maintenant qu’on a vu la syntaxe, appliquons-le à un exemple concret ! Apparemment Rodolphe a une petite idée derrière la tête.
Mettez à disposition des UDFs
Rodolphe vous écrit à nouveau sur Slack :
Salut, J'aurais besoin de deux petites fonctions pour simplifier nos opérations récurrentes :
calculate_late_fee: Une fonction qui calculerait les frais de retard pour les films. Le client a 3 jours pour rendre le film, et s'il dépasse ce délai, on applique une pénalité de 1,5 € par jour de retard. La fonction prendra en paramètres la date de location et la date de retour.
anonymize_email: Une autre fonction pour anonymiser les adresses email. Il faudrait qu’elle ne montre que les trois premières lettres, puis des *** pour le reste, afin de protéger la confidentialité de nos clients.Ces fonctions nous simplifieraient vraiment la vie ! Merci !
En réponse à la demande de Rodolphe, nous allons d’abord créer la fonction pour calculer les frais de retard.
CREATE FUNCTION calculate_late_fee(rental_date TIMESTAMP, return_date TIMESTAMP)
RETURNS NUMERIC AS $$
DECLARE
late_fee NUMERIC;
days_late INTEGER;
BEGIN
IF return_date > rental_date + INTERVAL '3 days' THEN
days_late := EXTRACT(DAY FROM (return_date - rental_date - INTERVAL '3 days'));
late_fee := days_late * 1.5; -- 1,5 € par jour de retard
ELSE
late_fee := 0;
END IF;
RETURN late_fee;
END;
$$ LANGUAGE plpgsql;Explication :
La fonction prend en paramètres la date de location (rental_date) et la date de retour réelle (return_date).
Si le film est rendu plus de 3 jours après la date de location, elle calcule le nombre de jours de retard et applique une pénalité de 1,5 € par jour.
Sinon, aucuns frais de retard ne sont appliqués.
Définissons maintenant celle associée à l’anonymisation des emails :
CREATE FUNCTION anonymize_email(email VARCHAR)
RETURNS VARCHAR AS $$
BEGIN
RETURN SUBSTRING(email FROM 1 FOR 3) || '***';
END;
$$ LANGUAGE plpgsql;Explication :
La fonction prend en paramètre une adresse email.
Elle retourne une version anonymisée, ne montrant que les trois premiers caractères suivis de ***.
Super ! Et je peux accéder aux fonctions directement dans ma clauseSELECT?
Exactement ! Maintenant que nos fonctionscalculate_late_feeetanonymize_emailsont prêtes, nous allons les intégrer directement dans nos requêtes SQL. Cela nous permettra de calculer les frais de retard automatiquement et d'anonymiser les emails des clients, tout en simplifiant nos requêtes et en centralisant la logique métier.
Examinons d'abord le résultat de la fonctioncalculate_late_feeen utilisant les transactions de notre table rental :
SELECT
r.rental_id,
c.first_name,
c.last_name,
calculate_late_fee(r.rental_date, r.return_date) AS late_fee
FROM
rental r
JOIN
customer c ON r.customer_id = c.customer_id
WHERE
r.return_date IS NOT NULL
ORDER BY
rental_id;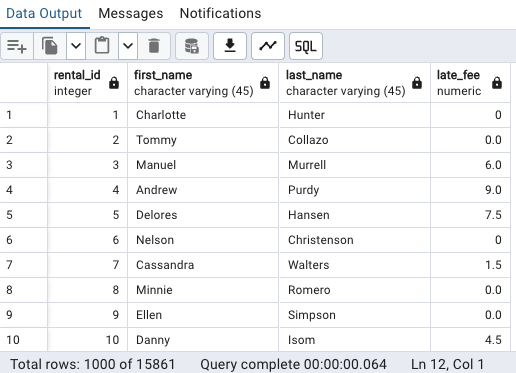
Examinons ensuite le résultat de la fonctionanonymize_emailen retournant des informations associées à nos clients :
SELECT
c.customer_id,
c.first_name,
c.last_name,
anonymize_email(c.email) AS email_anonymized
FROM
customer c
ORDER BY
customer_id;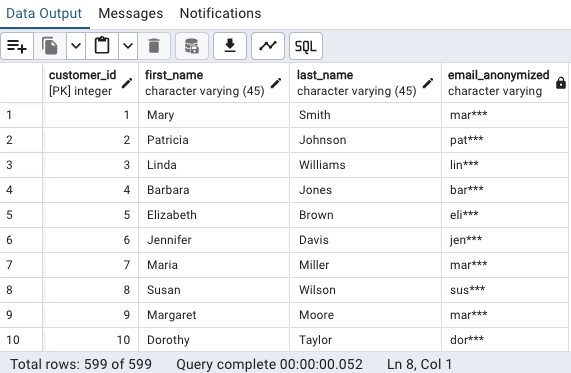
Après avoir vu comment créer et utiliser des fonctions personnalisées pour automatiser certains calculs, passons maintenant à un autre outil : les procédures stockées. Celles-ci permettent d'exécuter des opérations plus complexes et d'automatiser des tâches répétitives tout en encapsulant la logique métier.
Définissez une procédure stockée et déclenchez son appel
Rodolphe vous répond sur Slack :
Merci pour les UDFs, les utilisateurs sont très contents ! Elles leur font gagner du temps et évitent qu'ils se trompent sur les frais de retard.
J'aurais maintenant une nouvelle demande pour automatiser encore plus nos processus. On a remarqué que certaines tâches répétitives, comme l'archivage des anciennes locations, prennent du temps et pourraient être automatisées. Peux-tu mettre en place une procédure stockée qui archive automatiquement les locations retournées depuis plus d'un an ? Cela nous permettrait de garder la base de données plus légère et mieux organisée.
Merci d'avance pour ton aide !
Après ce message, il devient évident que certaines tâches répétitives peuvent être automatisées pour améliorer l'efficacité et la gestion des données. C'est ici que les procédures stockées (ou stored procedures) entrent en jeu.
Comprenez les procédures stockées
Les procédures stockées sont des blocs de code SQL qui peuvent encapsuler plusieurs opérations, comme des mises à jour, insertions, suppressions ou vérifications complexes. Contrairement aux fonctions (UDFs), qui retournent généralement une valeur, les procédures stockées peuvent ne pas retourner de valeur, mais plutôt exécuter des actions complexes sur les données.
Pourquoi utiliser des procédures stockées ?
Automatisation : Elles permettent d'automatiser des tâches répétitives sans intervention manuelle.
Centralisation de la logique métier : Les règles et traitements complexes sont centralisés au sein de la procédure, facilitant la maintenance.
Sécurité et performance : En encapsulant des processus dans une procédure stockée, vous limitez les risques d'erreurs humaines et optimisez les performances car les procédures stockées sont précompilées.
Création d'une procédure stockée
La création d'une procédure stockée suit une syntaxe similaire à celle d'une fonction, mais sans le besoin de retourner une valeur. Voici la syntaxe de base pour créer une procédure stockée :
CREATE PROCEDURE procedure_name(param_list)
LANGUAGE plpgsql
AS $$
BEGIN
-- logique de la procédure
END;
$$;Explication :
CREATE PROCEDURE procedure_name(param_list): Crée une nouvelle procédure nomméeprocedure_nameavec une liste de paramètres (optionnelle).LANGUAGE plpgsql: Indique que la procédure est écrite en PL/pgSQL, le langage procédural de PostgreSQL.BEGIN ... END: C’est ici que la logique de la procédure est définie. Vous pouvez y inclure plusieurs instructions SQL.
Maintenant que nous avons vu la syntaxe, nous allons pouvoir créer la procédure stockée demandée par Rodolphe.
Sauvegardez et déclenchez des procédures stockées
Après avoir défini vos premières procédures stockées, il est essentiel de savoir comment les sauvegarder et les déclencher efficacement. Cela vous permettra d'automatiser vos tâches et de garantir la cohérence des opérations dans la base de données DVD Rental, tout en minimisant l'intervention manuelle.
Création d'une procédure pour archiver les anciennes locations
Pour répondre à la demande de Rodolphe, nous allons créer une procédure stockée qui archive automatiquement les locations retournées depuis plus d’un an dans une table dédiée (rental_archive), puis supprime ces enregistrements de la table des locations actives (rental) :
CREATE PROCEDURE archive_old_rentals()
LANGUAGE plpgsql
AS $$
BEGIN
-- Archiver les locations dans une table d'archive
INSERT INTO rental_archive (rental_id, customer_id, rental_date, return_date)
SELECT rental_id, customer_id, rental_date, return_date
FROM rental
WHERE return_date < NOW() - INTERVAL '1 year';
-- Mettre à jour la table payment pour assigner une valeur au lieu de NULL
UPDATE payment
SET rental_id = -1 -- ou une autre valeur spéciale
WHERE
rental_id IN (
SELECT rental_id
FROM rental
WHERE return_date < NOW() - INTERVAL '1 year'
);
-- Supprimer les locations archivées de la table rental
DELETE FROM rental
WHERE return_date < NOW() - INTERVAL '1 year';
END;
$$;Explication :
INSERT INTO rental_archive: Cette partie de la procédure stocke dans une table d'archive toutes les locations terminées depuis plus d'un an.DELETE FROM rental: Après avoir archivé les données, on supprime les enregistrements correspondants de la table des locations actives (rental).
Grâce à cette procédure, l'archivage des locations anciennes devient un processus automatisé, évitant ainsi une gestion manuelle chronophage.
Exécution de la procédure stockée
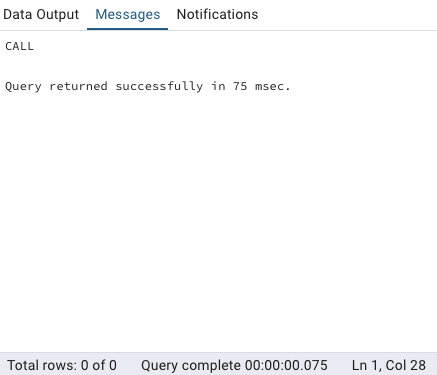
Pour exécuter une procédure stockée, il suffit d'utiliser la commandeCALL:
CALL archive_old_rentals();Pour éviter cela, vous pouvez soit, supprimer les lignes correspondant à la suppression des données dans la tablerental, soit de ne pas exécuter cette procédure sur la base de données dvdrental fournie. Si vous le faites par erreur, vous devrez soit restaurer la base de données à son état initial, soit la supprimer et la recharger depuis le fichier d'origine.
Lorsque vous exécutez cette commande, PostgreSQL exécute toutes les opérations définies dans la procédure, archivant et supprimant les données de manière automatique.
Après avoir appris à sauvegarder et exécuter manuellement des procédures stockées, voyons maintenant comment déclencher automatiquement ces procédures à l’aide de triggers, afin d’automatiser davantage vos processus et optimiser la gestion des données.
Déclenchez de manière automatique une procédure stockée
En utilisant des triggers, vous pouvez automatiser certaines actions lorsque ces événements se produisent, sans intervention manuelle.
PostgreSQL offre deux principaux types de triggers :
Row-level triggers : Le trigger est déclenché pour chaque ligne affectée par l'événement.
Statement-level triggers : Le trigger est déclenché une seule fois, quel que soit le nombre de lignes affectées.
Mise en place d’un trigger pour archiver les locations anciennes
Pour automatiser encore davantage l'archivage des locations terminées, vous pouvez associer un row-level trigger à la table rental. Ce trigger appellera automatiquement la procédure archive_old_rentals chaque fois qu'une modification est faite sur la date de retour d'une location. Si la location a plus d'un an, elle sera archivée automatiquement.
Voici comment vous pouvez créer ce trigger :
CREATE TRIGGER archive_trigger_rental
AFTER UPDATE ON rental
FOR EACH ROW
WHEN (NEW.return_date IS NOT NULL AND NEW.return_date < NOW() - INTERVAL '1 year')
EXECUTE PROCEDURE archive_old_rentals();Explication :
AFTER UPDATE ON rental: Le trigger sera déclenché après chaque mise à jour sur la table rental.FOR EACH ROW: C’est un row-level trigger, donc il sera déclenché pour chaque ligne modifiée.WHEN (NEW.return_date IS NOT NULL AND NEW.return_date < NOW() - INTERVAL '1 year'): La condition vérifie que la nouvelle date de retour (NEW.return_date) n’est pas nulle et que la location date de plus d’un an.EXECUTE PROCEDURE archive_old_rentals(): Si la condition est remplie, la procédure archive_old_rentals est exécutée, archivant automatiquement les locations concernées.
Les triggers sont un excellent moyen d'automatiser des processus critiques, tels que l'archivage ou la validation de données, sans nécessiter d'intervention manuelle.
À vous de jouer

Contexte
Rodolphe, le DBA de DVD Rental, a remarqué que certains clients saisissent des adresses email dans un format incorrect, ce qui crée des erreurs dans la gestion des contacts. Il souhaite que vous mettiez en place une procédure stockée pour vérifier que l'adresse email respecte le format standard avant d'insérer un nouveau client dans la table customer.
Votre mission consiste à créer une procédure stockée pour vérifier que l'adresse email est bien au format valide (par exemple, aa@.fr ou aa@.com) avant l'insertion des données, ainsi qu'un trigger pour automatiser cette validation lors de l'ajout d'un client.
Consignes
1/ Créez une procédure stockée nommée validate_email_format qui prend en paramètre l'adresse email d'un client.
2/ Créez un trigger qui appellera automatiquement la procédurevalidate_email_formatavant chaque insertion dans la table customer.
3/ Testez cette procédure et le trigger en essayant d'insérer un nouveau client avec une adresse email mal formatée.
En résumé
Vous avez appris à créer des fonctions personnalisées (UDF) pour automatiser des calculs répétitifs, comme les frais de retard ou l’anonymisation d'emails.
Vous avez découvert comment appeler ces fonctions dans des requêtes SQL pour centraliser et simplifier la logique métier.
Vous avez défini des procédures stockées pour automatiser des tâches complexes, comme l'archivage des anciennes locations.
Vous avez vu comment déclencher automatiquement des procédures à l’aide de triggers pour rendre les opérations plus fluides et sécurisées.
Après avoir automatisé certaines tâches avec les procédures et fonctions stockées, il est temps d'explorer un nouvel outil puissant : les fenêtres (windows functions).
