Pratiquez les fonctions avancées de merge de table
Sofia, la CEO de DVD Rental, vous contacte avec une nouvelle mission. L’entreprise a récemment récupéré des archives contenant des données historiques sur les films et les clients. Elle souhaite utiliser ces informations pour mener des analyses globales et comparer les anciens catalogues avec les bases de données actuelles. Votre rôle est de fusionner ces ensembles de données tout en vous assurant que les informations sont correctement combinées et traitées de manière optimale.
Découvrez les ensembles
Avant de vous lancer dans le vif du sujet, rappelons ce qu'est un "ensemble" en SQL. Un ensemble représente un groupe de résultats provenant de différentes requêtes que vous pouvez combiner pour obtenir une seule vue globale. Grâce à cela, vous pouvez comparer, fusionner ou filtrer les données de manière efficace.
Pour vous préparer à répondre aux demandes de Sofia et Rodolphe, vous devrez importer le fichier CSV d’archive et l’intégrer dans votre base de données PostgreSQL. Vous découvrirez comment faire cela dans la vidéo suivante :
Dans cette vidéo, vous avez vu :
Comment créer une table
film_archivepour stocker les données d'archive des films.Comment utiliser la commande
COPYpour charger les données à partir du fichier CSV.Comment vérifier l'intégrité des données après l'importation avec des requêtes SQL simples.
Après avoir clarifié les concepts fondamentaux des ensembles, passons à la combinaison des résultats de plusieurs requêtes en un ensemble unique de lignes.
Combinez les résultats de deux ou plusieurs requêtes et retournez un ensemble unique de lignes
Quelques jours plus tard, Rodolphe, le DBA de DVD Rental, vous envoie un message Slack :
Salut,
Sofia a récupéré des données d'archives et elle aimerait qu'on les intègre dans nos analyses. Peux-tu combiner nos tables actuelles de films avec celles des archives ? Dans certains cas, il faudra supprimer les duplicatas, mais garde les également dans une version alternative pour des besoins futurs.
Envoie-moi directement les deux requêtes SQL.
Merci !
Dans ce contexte, deux opérations sont cruciales :
UNION: Cet opérateur fusionne les résultats de deux ou plusieurs requêtes en supprimant les duplicatas.UNION ALL: Contrairement àUNION, cet opérateur combine les résultats de requêtes sans éliminer les duplicatas.
Vous souhaitez combiner les films de la tablefilmde DVD Rental et ceux de la nouvelle tablefilm_archive. Voici comment vous pourriez utiliserUNIONetUNION ALL:
-- Combiner les tables film et film_archive avec UNION
SELECT title, release_year, language_id FROM film
UNION
SELECT title, release_year, language_id FROM film_archive;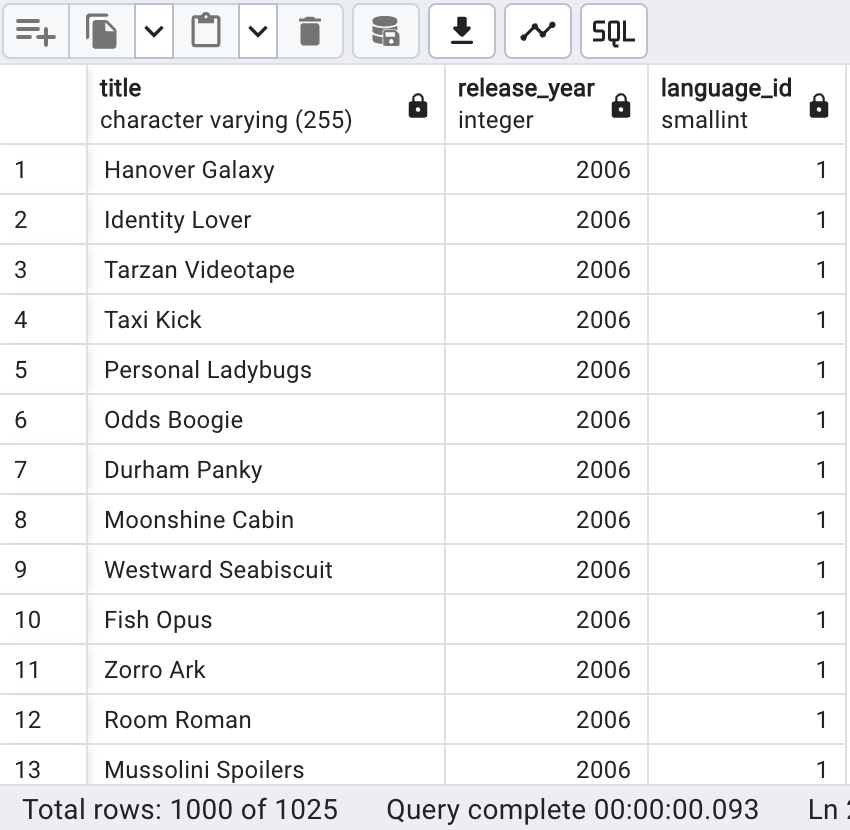
-- Combiner les tables film et film_archive avec UNION ALL (garder les duplicatas)
SELECT title, release_year, language_id FROM film
UNION ALL
SELECT title, release_year, language_id FROM film_archive;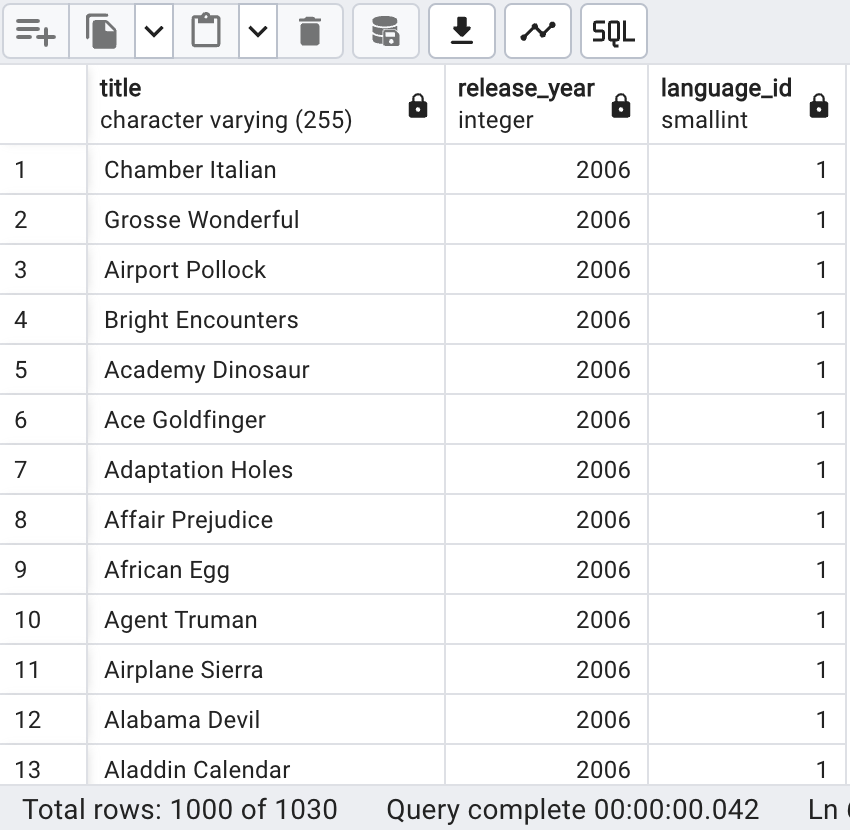
Le premier résultat révèle unUNIONqui élimine les doublons, donnant 1025, tandis que le deuxième résultat, qui inclut les doublons, affiche 1030. Ainsi, on constate qu'il y a 5 films en commun, correspondant aux doublons. Nous allons maintenant voir comment obtenir ces valeurs communes et les isoler.
Obtenez les valeurs communes entre plusieurs ensembles de résultats
Si vous souhaitez trouver les éléments communs entre plusieurs ensembles de résultats, vous pouvez utiliser l’opérateurINTERSECT. Cet opérateur renvoie uniquement les lignes présentes dans les deux requêtes.
Dans notre cas, la colonne description n’est pas exactement identique entre la table film et la tablefilm_archive. Cela signifie que si vous incluez cette colonne dans la requêteINTERSECT, vous ne trouverez aucun film commun, même si les titres sont les mêmes.
Si vous souhaitez uniquement comparer les titres des films et leurs années présents dans les deux tables sans inclure la colonne description, voici comment utiliserINTERSECTpour identifier les titres communs :
SELECT title, release_year FROM film
INTERSECT
SELECT title, release_year FROM film_archive;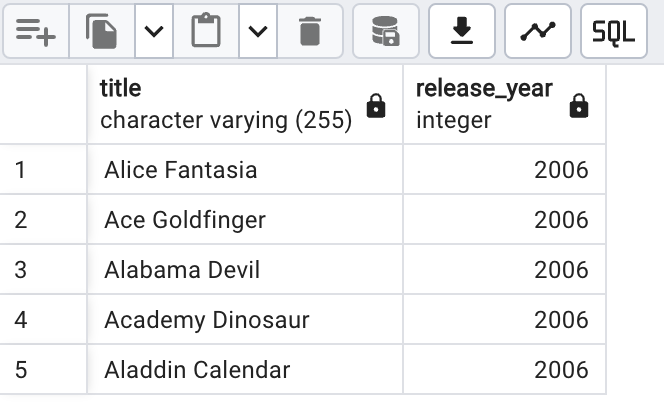
Cela retournera uniquement les films dont les titres sont exactement identiques entre les deux tables.
Maintenant que vous avez identifié les films communs, il peut être utile de comprendre quelles données existent dansfilm_archivemais qui sont absentes de la tablefilm actuelle. Pour ce faire, nous allons utiliser l’opérateurEXCEPT.
Effectuez une différence entre deux ensembles de résultats
SiINTERSECTest l’opérateur communEXCEPTdoit sûrement être l’opérateur de différenciation ?
Exactement, l’opérateurEXCEPTest utile lorsque vous voulez voir les lignes qui existent dans un premier ensemble de résultats mais pas dans le second. Il est souvent utilisé pour des vérifications ou des analyses de divergence entre deux tables similaires.
Rodolphe souhaite maintenant savoir quels films sont encore dans la base principale de DVD Rental (film) mais qui ne se trouvent pas dans l’archive (film_archive). Pour cela, il vous demande de réaliser une requête qui identifie ces films.
Voici comment utiliserEXCEPTpour retourner les films qui existent dans la tablefilmmais qui n’ont pas encore été archivés dansfilm_archive:
SELECT title FROM film
EXCEPT
SELECT title FROM film_archive ORDER BY title;
Cela retournera tous les titres qui sont présents dansfilmmais pas dansfilm_archive, ce qui aidera Rodolphe à identifier les films encore actifs dans la base de DVD Rental.
Pour compléter cette analyse, vous pouvez également exécuter la requête inverse pour identifier les films qui se trouvent uniquement dans l’archive et non dans la base actuelle. Cela peut être utile pour savoir quels films ont été archivés mais ne sont plus disponibles dans la base active.
SELECT title FROM film_archive
EXCEPT
SELECT title FROM film ORDER BY title;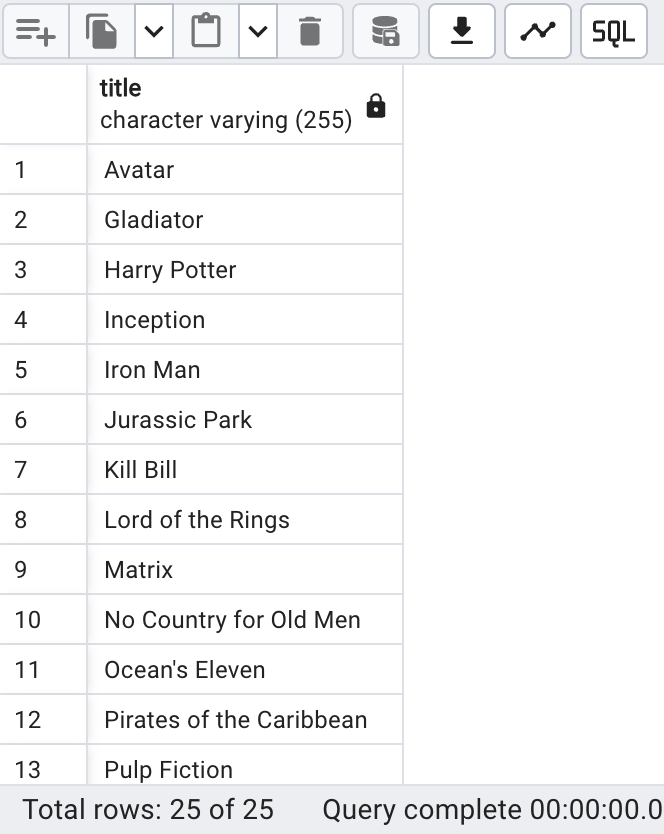
Cela aidera Rodolphe à comprendre quels films ont été archivés mais qui ne figurent plus dans l’inventaire principal.
À vous de jouer

Contexte
La compagnie DVD Rental vient d'acquérir une nouvelle entreprise, et avec cette acquisition, un nouveau fichier d'archive a été reçu,film_new_acquisition. Vous devez charger ces données dans une nouvelle table PostgreSQL. Une fois les trois tables en place (film,film_archive, etfilm_new_acquisition), vous devrez faire des comparaisons entre les films de ces différentes tables pour répondre aux demandes de Sofia et Rodolphe.
Consignes
Importez les données du fichier CSV dans une nouvelle table
film_new_acquisition.Trouvez les films en commun entre les trois tables
film,film_archive, etfilm_new_acquisition.Combinez toutes les données des trois tables en une seule, sans duplication (utilisation de
UNION)Recherchez les films présents dans deux ensembles mais pas dans le troisième (ex. films présents dans
filmetfilm_archive, mais pas dansfilm_new_acquisition).
En résumé
Vous avez appris à utiliser les
UNIONetUNION ALLpour combiner plusieurs ensembles de résultats en supprimant ou en conservant les doublons.Vous avez découvert comment utiliser
EXCEPTpour trouver les lignes présentes dans un ensemble mais absentes dans un autre.Vous avez exploré l'opérateur
INTERSECTpour identifier les lignes communes entre deux ensembles de résultats.
Félicitations pour avoir suivi ce cours jusqu'à la fin ! Vous avez parcouru une multitude de concepts avancés de SQL sur PostgreSQL, de l'optimisation des requêtes avec les jointures complexes jusqu'à l'usage des procédures stockées et des Windows Functions. Grâce à ces compétences, vous êtes désormais capable de concevoir des bases de données plus robustes, de répondre à des problématiques d'analyse poussée et d'optimiser les performances de vos systèmes. Continuez à pratiquer et à approfondir vos connaissances, et vous serez prêt à relever tous les défis que vous rencontrerez dans vos futures missions. Bravo et bon courage pour la suite !
