Comprenez le rôle de Node.js dans une application web

Avant de coder notre première API ou d'installer des outils complexes, il est indispensable de comprendre sur quelles fondations nous allons bâtir notre application. Vous avez peut-être déjà utilisé JavaScript pour animer des éléments sur une page web, mais comment ce même langage peut-il faire fonctionner tout un serveur ? C'est ce que nous allons découvrir ensemble.
Découvrez ce qu'est Node.js
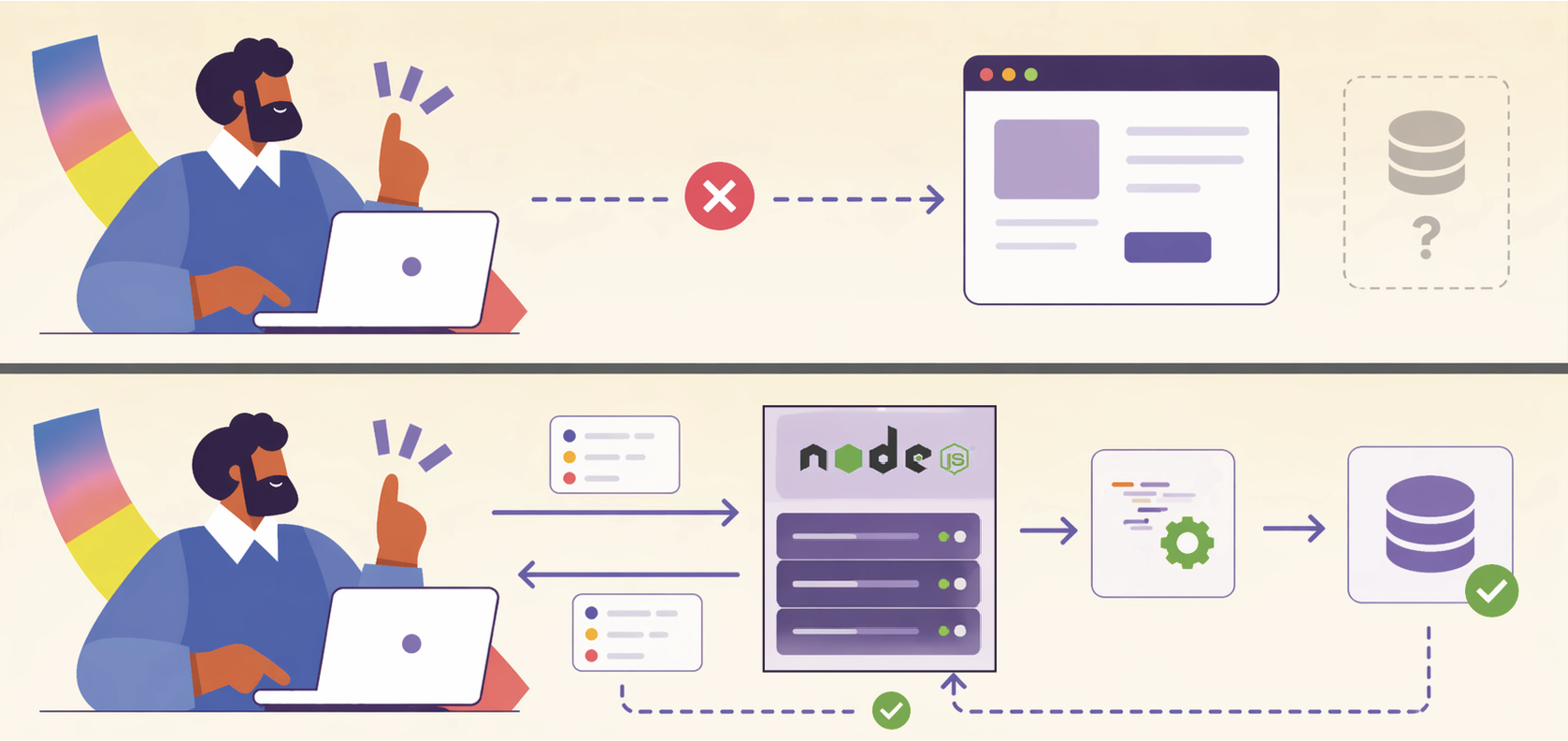
Imaginons que vous développiez une application de gestion de tâches. Jusqu'à présent, vous avez écrit du code JavaScript pour que l'utilisateur puisse cliquer sur un bouton et ajouter une tâche à l'écran. C'est ce que l'on appelle le développement front-end, qui s'exécute directement dans le navigateur de votre utilisateur. Mais que se passe-t-il lorsque cet utilisateur ferme son onglet ? Si vous ne sauvegardez pas ces données quelque part de sécurisé, tout est perdu. Vous avez donc besoin d'un serveur pour recevoir ces données, les traiter et les stocker dans une base de données. Traditionnellement, ce travail côté serveur (le back-end) nécessitait d'apprendre un tout autre langage, comme PHP, Ruby ou Java.
C'est là que Node.js a complètement changé la donne. Node.js est un environnement d'exécution JavaScript côté serveur, fondé sur le puissant moteur V8 développé par Google pour le navigateur Chrome. Concrètement, Node.js extrait le moteur qui lit le JavaScript dans le navigateur et l'installe directement sur le système d'exploitation de votre serveur.
Mais pourquoi utiliser le même langage côté serveur et côté client ?
Le grand avantage est de pouvoir utiliser un seul et unique langage, le JavaScript, pour développer à la fois le front-end et le back-end. Cela simplifie énormément le travail en équipe, permet de partager de la logique entre les deux côtés, et facilite la vie des développeurs dits "full-stack". De très grandes entreprises technologiques, comme Netflix ou LinkedIn, utilisent Node.js en production pour sa rapidité et son efficacité.
Dans ce contexte, Node.js va nous permettre de créer une API (Application Programming Interface). Voyez l'API comme un contrat strict entre le front-end et le back-end. Le navigateur web (front-end) envoie une demande selon des règles précises, et notre serveur Node.js (back-end) s'engage à traiter cette demande et à renvoyer une réponse exploitable. Vous savez maintenant à quoi sert cet outil, voyons à présent comment il fonctionne techniquement.
Découvrez l'architecture de NodeJS
Maintenant que nous avons défini l'utilité de Node.js, regardons sous le capot. La grande force de Node.js réside dans son architecture très particulière : il fonctionne de manière asynchrone et non-bloquante, grâce à un mécanisme appelé la boucle d'événements (event loop).
Pour bien comprendre cette différence entre un système bloquant et un système non-bloquant, on peut faire le parallèle avec le service dans un restaurant. Dans un modèle "bloquant" classique, un serveur prend la commande de la table 1, l'apporte en cuisine, et attend les bras croisés que le plat soit prêt avant de le servir à la table 1. Pendant ce temps, la table 2 attend de pouvoir commander. C'est un processus lourd et lent. Dans le modèle asynchrone et non-bloquant de Node.js (opérations I/O non-bloquantes), le serveur prend la commande de la table 1, la transmet à la cuisine, puis va immédiatement prendre la commande de la table 2 pendant que la cuisine prépare le premier plat. Dès qu'un plat est prêt, la cuisine prévient le serveur (c'est l'événement), qui l'apporte à la bonne table.
Grâce à cette boucle d'événements, Node.js est capable de gérer des dizaines de milliers de requêtes simultanées de manière extrêmement fluide, sans jamais gaspiller de ressources en attendant qu'une opération se termine.
Pour vous prouver qu'il n'y a pas de magie, regardons à quoi ressemble un serveur HTTP natif en Node.js, écrit en seulement quelques lignes :
const http = require('http');
const server = http.createServer((req, res) => {
res.statusCode = 200;
res.setHeader('Content-Type', 'text/plain');
res.end('Bonjour depuis Node.js !');
});
server.listen(3000, () => {
console.log('Le serveur tourne sur le port 3000');
});Ce petit bout de code fait appel au module natifhttpde Node.js. Il crée un serveur qui écoute toutes les requêtes arrivant sur le port 3000 de notre machine. Lorsqu'une requête arrive, il définit un code de statut de réussite (200) et renvoie un simple texte. L'objectif ici est de comprendre que Node.js est parfaitement capable de répondre à des requêtes HTTP sans l'aide d'aucun outil supplémentaire. Cependant, nous verrons par la suite que gérer une application complexe de cette manière deviendrait très vite fastidieux, ce qui justifiera l'utilisation de frameworks.
Situez Node.js dans une architecture web moderne
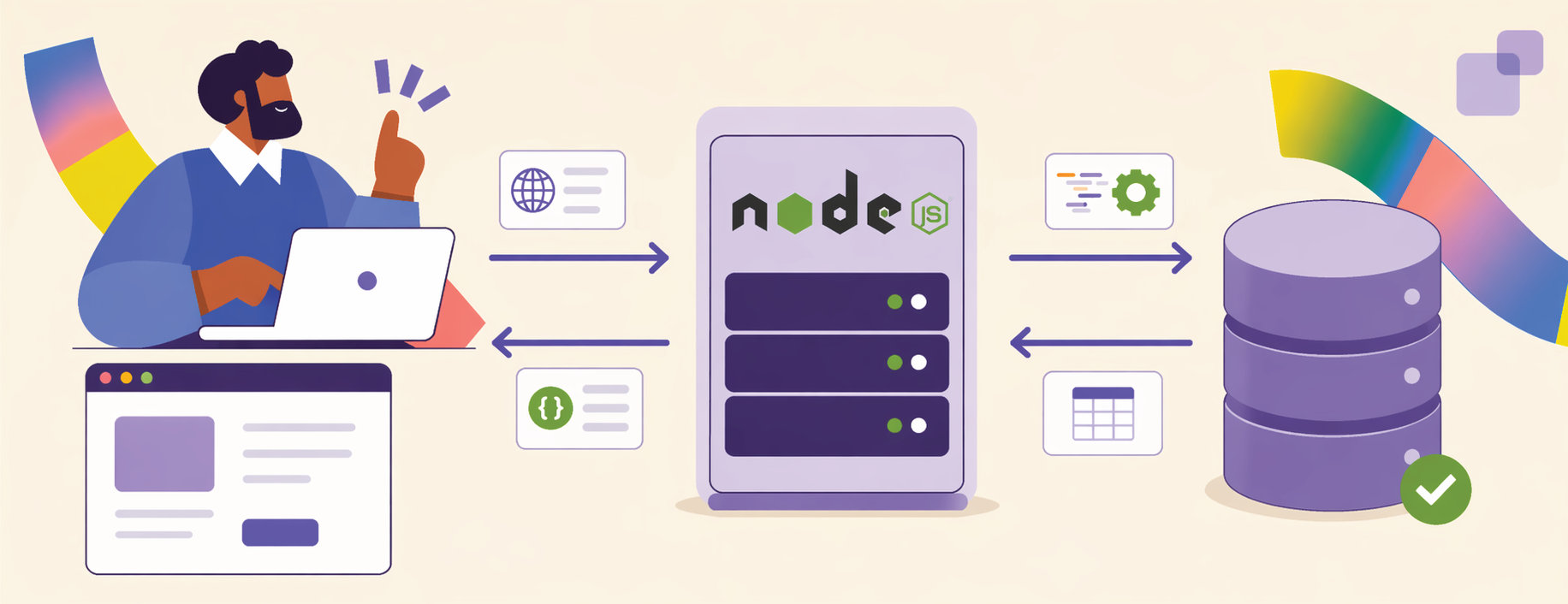
Concrètement, où se place notre serveur Node.js quand un utilisateur navigue sur notre site web ?
Replaçons Node.js dans le contexte global d'une architecture client-serveur.
Le parcours typique d'une information commence du côté du client (souvent un navigateur web, ou une application mobile). Le front-end envoie ce que l'on appelle des requêtes HTTP à travers le réseau internet. Notre serveur Node.js, qui écoute en permanence, reçoit ces requêtes. Son rôle est alors de traiter la logique métier de notre application : vérifier si l'utilisateur a le droit d'accéder à cette ressource, valider des formulaires, ou encore effectuer des calculs. Très souvent, Node.js va ensuite interroger une base de données pour sauvegarder ou récupérer des informations. Enfin, une fois le traitement terminé, Node.js renvoie une réponse au client. Dans les architectures modernes, cette réponse n'est pas une page web visuelle, mais des données brutes formatées en JSON, que le navigateur se chargera d'afficher joliment.
Pour vous aider à construire ces architectures solides, Node.js s'appuie sur un écosystème extrêmement riche. Le composant central de cet écosystème estnpm(Node Package Manager), un gigantesque librairie gratuit écrit par d'autres développeurs, que nous pourrons utiliser dans nos projets.
Bien que nous ayons vu dans la section précédente qu'il est possible de créer un serveur HTTP avec le code natif de Node.js, personne ne fait cela de A à Z pour une grosse application professionnelle. On utilise des frameworks, qui sont des boîtes à outils simplifiant la création du serveur. Vous entendrez souvent parler d'Express, qui est très minimaliste et laisse une grande liberté au développeur, ou encore de Fastify.
À vous de jouer !

Félicitations, la startup qui développe notre fameuse application de gestion de tâches vient de vous recruter. Votre tech lead, qui sait que l'équipe doit faire un choix d'architecture backend, vous demande de reproduire un code minimal avec Node.js de votre côté. L'objectif de cet exercice est de prouver que vous maîtrisez les concepts fondamentaux de Node.js et de rédiger une brève note technique expliquant ce que fait le code, en vous aidant des apprentissages de ce chapitre.
Consignes
Créez un fichier local nommé
serveur.jssur votre machine.Écrivez le code d'un serveur HTTP natif en Node.js (sans utiliser aucun framework) qui renvoie le message "Bienvenue sur le nouveau backend !".
En résumé
Node.js est un environnement d'exécution JavaScript côté serveur, fondé sur le très performant moteur V8 de Google Chrome.
Son fonctionnement asynchrone, non-bloquant et événementiel le rend particulièrement adapté et efficace pour construire des API web modernes.
Un serveur conçu avec Node.js a pour rôle de recevoir les requêtes HTTP, de traiter la logique métier, et de renvoyer des réponses généralement formatées en JSON.
Node.js ne fonctionne pas seul : il s'appuie sur un vaste écosystème comprenant le gestionnaire de dépendances npm et des frameworks avancés comme NestJS pour structurer le code.
Maîtriser le fonctionnement brut de Node.js est essentiel, car il constitue le socle fondamental sur lequel reposent tous les autres outils de notre architecture.
Vous comprenez maintenant le rôle crucial de Node.js dans une infrastructure web moderne et son fonctionnement non-bloquant. Dans le prochain chapitre, nous allons franchir une nouvelle étape en installant notre environnement de travail complet pour commencer à manipuler ces outils par nous-mêmes.
