Découvrez les approches modernes des lakehouse

Après avoir structuré son Data Lake et déployé des environnements sous AWS S3 et MinIO, GreenFarm entre dans une nouvelle phase. Marc, le directeur technique, convoque son équipe lors d’une réunion stratégique. Objectif : faire évoluer l’architecture de données pour répondre à des besoins d’analyse toujours plus complexes. Les agronomes veulent des analyses prédictives sur les rendements à venir, les équipes marketing souhaitent des rapports en temps réel sur les ventes et la satisfaction client, tandis que les data scientists ont besoin d’un accès fiable et partagé aux données pour entraîner leurs modèles de machine learning.
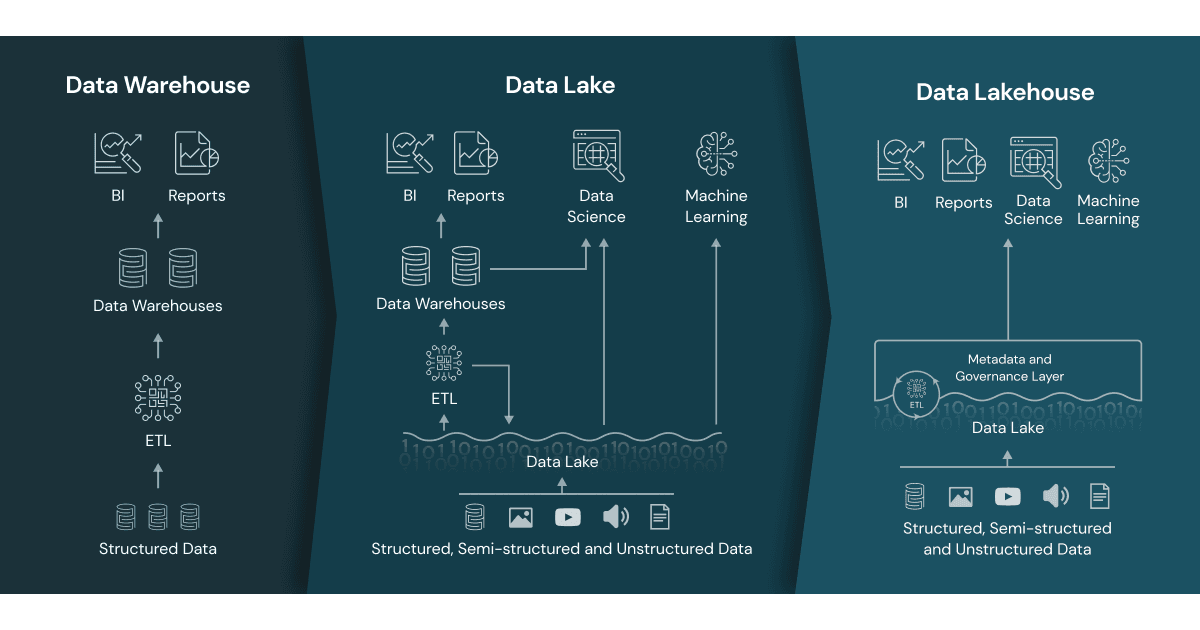
Jusqu’ici, GreenFarm utilisait un Data Warehouse pour l’analyse structurée et un Data Lake pour le stockage des données brutes. Mais la coexistence des deux mondes montre ses limites : duplication des données, coûts élevés, latences et complexité opérationnelle.
Marc pose alors la question :
Et si nous pouvions combiner la flexibilité du Data Lake et la fiabilité du Data Warehouse ?
C’est précisément ce que propose l’architecture Lakehouse.
Découvrez l'importance d'une architecture Lakehouse
Comprenez les limitations des Data Lakes traditionnels
Le Data Lake traditionnel a révolutionné la manière dont les entreprises stockent leurs données : il est flexible, scalable et peu coûteux. Mais cette flexibilité a un revers.
Chez GreenFarm, les capteurs IoT, les drones, les données météo et les ventes génèrent des volumes massifs de données hétérogènes. Rapidement, l’équipe constate plusieurs limites :
Limitation | Description |
Pas de transactions ACID | Manque de fiabilité transactionnelle : plusieurs équipes écrivent ou modifient les mêmes fichiers simultanément, créant des incohérences. |
Absence de schéma strict | le “schema-on-read” permet de lire les données à la volée, mais complique la gouvernance et la qualité. |
Pas de gestion de versions | Impossible de revenir à un état antérieur d’un dataset sans sauvegardes “manuelles” effectuées. |
Performance limitée | Requêtes lentes et coûteuses : sans index ni mécanismes d’optimisation, les analyses prennent du temps. |
Multiplication des copies | Chaque service crée sa propre version des données. |
Gouvernance manuelle | Aucune gestion centralisée des métadonnées ni des accès. |
Risques de “Data Swamp” | Sans gestion stricte, le Data Lake devient un espace désordonné et difficile à exploiter. |
En résumé : un Data Lake seul stocke très bien, mais analyse très mal. C’est une excellente fondation, mais elle doit évoluer vers une architecture plus intelligente et fiable — le Lakehouse.
La “Dual-Tier Architecture” : une étape intermédiaire
Face aux limites des Data Lakes traditionnels, de nombreuses entreprises — dont GreenFarm — ont adopté ce qu’on appelle une architecture à deux niveaux, ou Dual-Tier Data Architecture.
L’idée était simple :
conserver le Data Lake pour le stockage brut et les traitements massifs,
et connecter un Data Warehouse pour l’analyse structurée, la BI et la visualisation.
Ce modèle offrait le meilleur des deux mondes… en apparence. Dans la pratique, il entraînait de nouveaux problèmes :
duplication des données entre les deux environnements,
latence entre ingestion et exploitation,
coûts de synchronisation élevés,
et une gouvernance éclatée entre plusieurs systèmes.
Chez GreenFarm, cela signifiait par exemple maintenir deux pipelines : un pour alimenter les données brutes dans S3, et un autre pour les charger ensuite dans Redshift ou Snowflake pour les analyses.
Résultat : des données parfois divergentes et une perte de temps précieuse. C’est précisément pour résoudre ces inefficacités qu’est apparue la nouvelle génération d’architectures unifiées : le Lakehouse.
Le Lakehouse : l’évolution naturelle du Data Lake
Le Lakehouse combine la flexibilité du Data Lake avec la fiabilité et la performance du Data Warehouse.
Selon Databricks:
Le Lakehouse est une architecture ouverte de gestion des données qui combine la flexibilité, le faible coût, l’efficacité et la capacité de passage à l’échelle d’un Data Lake avec la gestion des données, l’application des schémas et les transactions ACID d’un Data Warehouse traditionnel.
En d’autres termes : Le Lakehouse conserve la liberté du Data Lake, tout en y ajoutant la rigueur d’un Data Warehouse. Voici les piliers du Lakehouse:
Stockage ouvert et unique : Toutes les données — structurées, semi-structurées ou non structurées — sont centralisées dans un stockage objet (S3, ADLS, GCS, MinIO). Pas de silos, pas de duplication.
Transactions ACID : Les formats comme Delta Lake, Iceberg et Hudi garantissent cohérence et fiabilité, même en cas d’écriture simultanée.
Performance analytique : Grâce à la gestion de métadonnées, aux statistiques et à l’indexation, les requêtes SQL deviennent rapides et précises.
Gouvernance unifiée : Des catalogues comme Unity Catalog, Glue ou Purview assurent le contrôle des accès et la traçabilité.
Intégration ML & Streaming : Le Lakehouse supporte aussi bien les traitements batch que temps réel — un vrai plus pour GreenFarm, qui croise désormais les données IoT en direct avec les historiques météo pour ajuster ses prévisions de récolte.
Maîtrisez les concepts clés de l'architecture moderne
Séparer le compute du stockage
L’un des principes fondateurs du Lakehouse est la séparation entre le stockage et la puissance de calcul.
Contrairement aux systèmes traditionnels où ces deux éléments sont étroitement liés, le Lakehouse adopte une approche dite “decoupled architecture” : les données sont conservées de manière durable dans un stockage objet (comme Amazon S3, Azure Data Lake Storage, Google Cloud Storage ou MinIO), tandis que les traitements sont effectués par des moteurs de calcul indépendants (Spark, Dremio, Trino, BigQuery, Synapse, etc.). Cette séparation présente trois avantages majeurs :
Flexibilité — chaque équipe peut choisir le moteur de calcul le plus adapté à son usage :
Spark pour les traitements massifs, Dremio pour les requêtes SQL interactives, ou encore Databricks pour le machine learning.Scalabilité — il devient possible d’ajuster dynamiquement la puissance de calcul sans toucher au stockage.
Chez GreenFarm, cela permet d’augmenter temporairement les ressources pendant les campagnes de récolte, lorsque les volumes de données IoT explosent, puis de réduire les coûts en période creuse.Optimisation économique — en ne payant que pour le compute utilisé, GreenFarm maîtrise son budget tout en conservant des performances élevées.
Mais cette flexibilité pose un défi : comment garantir que toutes ces données, dispersées et continuellement mises à jour, restent cohérentes et exploitables ? C’est là qu’intervient une autre innovation clé du Lakehouse : l’architecture en médaillon.
Le modèle en médaillon : fiabilité et traçabilité
L’architecture en médaillon est un modèle de conception qui organise logiquement les données selon leur niveau de qualité et de maturité. Plutôt que de transformer les données d’un bloc, elle favorise une approche incrémentale : chaque couche affine les données, améliore leur qualité et accroît leur valeur analytique. On distingue trois niveaux complémentaires :
La couche Bronze, ou couche des données brutes, est le point d’entrée du Lakehouse.
Elle contient les données telles qu’elles arrivent des sources — capteurs IoT, API météo, fichiers CSV, logs ou exports applicatifs.
Chez GreenFarm, cette couche regroupe par exemple les relevés de capteurs de température et d’humidité, les images aériennes des drones et les flux météo en temps réel.
La couche Silver regroupe les données nettoyées, validées et enrichies.
C’est ici qu’interviennent les règles de qualité et les logiques métiers : on supprime les doublons, on gère les valeurs manquantes, on homogénéise les unités et on applique un schéma structuré.
GreenFarm y consolide ses données issues de multiples fermes et capteurs, offrant une vision harmonisée et exploitable de ses activités agricoles.
La couche Gold contient les données prêtes à la consommation métier.
Elles sont modélisées pour l’analyse (souvent en schéma en étoile), agrégées par indicateurs clés et validées par les équipes métiers.
C’est ici que GreenFarm calcule ses rendements moyens, anticipe ses récoltes et suit ses indicateurs de durabilité.
Cette organisation progressive permet plusieurs bénéfices :
une traçabilité complète des transformations ;
une clarté dans la gouvernance (qui écrit où, qui lit quoi) ;
et une valeur croissante des données au fil des couches.
En structurant ainsi son Lakehouse, GreenFarm crée un écosystème de données vivant, où les ingénieurs, analystes et métiers collaborent sur un flux commun mais adapté à leurs besoins respectifs.
La donnée devient un produit évolutif, dont la fiabilité augmente à chaque étape du parcours.
Les formats ouverts : Delta Lake, Iceberg, Hudi
Si le Data Lake est une immense bibliothèque de fichiers, le Lakehouse en est la version organisée, cataloguée, et fiable.
Qu'est-ce qui rend cela possible ?
Les formats d’open table — tels que Delta Lake, Apache Iceberg et Apache Hudi (tous trois open source).
Ces formats ne sont pas de simples structures de fichiers : ils ajoutent une couche d’intelligence et de gestion transactionnelle au-dessus du stockage objet (S3, ADLS, GCS, MinIO…). Autrement dit, ce sont eux qui transforment un lac de données en un système transactionnel cohérent et fiable. Sans eux, un Data Lake n’a pas de garantie de cohérence :
deux processus peuvent écraser les mêmes fichiers,
une requête peut lire des données partiellement écrites,
et il est impossible de revenir à un état antérieur d’un dataset.
Grâce à ces formats, le Lakehouse devient ACID : les opérations sont atomiques, cohérentes, isolées et durables.
Chez GreenFarm, cette fiabilité change tout : les données de certification biologique, les relevés de capteurs IoT et les ventes en ligne peuvent être mises à jour ou corrigées sans risquer d’incohérence.
Les équipes travaillent ainsi sur une même version maîtrisée de la donnée, sans duplication.
Format | Atouts clés | Atouts clés |
Créé par Databricks, très intégré à Spark | Transactions ACID, Time Travel, intégration Spark et MLflow. | |
Conçu chez Netflix, format très répandu. | Partitionnement flexible, schéma évolutif, prise en charge multi-moteur. | |
Axé sur l’ingestion en temps réel. | Support des opérations upsert/delete, intégration Kafka/Spark. |
Choisissez votre stack Lakehouse : stockage, format et moteur de calcul
Mettre en œuvre une architecture Lakehouse, c’est avant tout assembler intelligemment plusieurs briques technologiques. Le principe n’est pas de choisir “un produit magique”, mais de composer une stack cohérente autour de trois éléments indissociables :
Un stockage objet : la fondation du système.
Que ce soit Amazon S3, Azure Data Lake Storage, Google Cloud Storage ou même MinIO en open source, ce composant sert de base universelle au Lakehouse.Un format de table ouvert : le cœur du système.
C’est cette couche qui transforme le simple stockage en un Lakehouse capable de gérer les transactions et les métadonnées.
Dans la pratique, il en existe trois grands standards :Delta Lake (Databricks),
Apache Iceberg (Netflix, Snowflake, Dremio),
Apache Hudi (Uber).
Un moteur de calcul (compute) : la partie dynamique.
Ce composant exécute les transformations et les analyses.
Il peut s’agir de Spark, Dremio, Trino, Databricks, Synapse, BigQuery, ou encore Athena, selon les besoins et le cloud utilisé.
Chez GreenFarm, cette réflexion est cruciale : le choix d’une stack déterminera la façon dont les données circuleront (streaming ou batch), la rapidité d’analyse, et la souplesse d’évolution de l’écosystème.
Une entreprise peut par exemple :
déployer un Lakehouse open source avec MinIO, Iceberg et Dremio ;
ou opter pour un modèle intégré cloud avec AWS S3 + Glue + Athena ;
voire choisir une approche tout-en-un comme Databricks avec Delta Lake et Photon.
Exemples de stacks Lakehouse typiques:
Stack | Stockage | Format de table | Moteur de calcul | Particularité |
Open Source | MinIO | Iceberg / Delta Lake | Dremio / Trino | 100 % open source, flexible, sans dépendance cloud |
S3 / ADLS / GCS | Delta Lake | Spark / Photon | Plateforme intégrée avec gouvernance et ML natif | |
Amazon S3 | Iceberg | Athena / Redshift / Glue | Forte intégration cloud et sécurité centralisée | |
ADLS Gen2 / OneLake | Delta Lake | Synapse / Fabric | Gouvernance complète (Purview), BI intégrée | |
Google Cloud Storage | Iceberg | BigQuery / Spark | Simplicité d’usage et intégration Vertex AI |
De nouveaux acteurs viennent également bousculer le paysage Lakehouse. Des solutions comme MotherDuck (une plateforme cloud qui étend DuckDB, le moteur analytique open source embarqué) ou ClickHouse proposent des approches plus légères et centrées sur la performance. Elles s’intègrent aux formats ouverts comme Parquet ou Iceberg, et permettent d’exécuter des analyses à grande vitesse sans infrastructure complexe.
En résumé
L'architecture Lakehouse révolutionne la gestion des données en combinant les avantages économiques des Data Lakes avec la fiabilité des Data Warehouses. Elle répond aux limitations des architectures traditionnelles en offrant transactions ACID, performances optimisées et gouvernance unifiée.
La séparation compute/stockage et l'architecture médaillon (Bronze-Silver-Gold) structurent efficacement vos flux de données agricoles tout en maintenant la flexibilité nécessaire à l'évolution de vos besoins métier.
Les formats de tables ouverts (Delta Lake, Iceberg) transforment votre stockage simple en une plateforme de données transactionnelle, fiable et performante. Cette évolution technologique élimine les silos entre équipes et unifie vos cas d'usage analytiques.
Le choix entre Databricks, Dremio ou les solutions cloud natives dépend de vos priorités : intégration ML avancée, performance SQL, ou écosystème cloud existant. Tous offrent les avantages fondamentaux du Lakehouse tout en réduisant les coûts et la complexité opérationnelle.
Chez GreenFarm, cette architecture moderne permettra d'unifier vos équipes data, d'accélérer vos analyses agricoles et de soutenir efficacement votre stratégie de croissance durable.
Vous comprenez désormais pourquoi le Lakehouse est devenu l’architecture de référence pour unifier stockage, gouvernance et analyse. Dans le chapitre suivant, nous allons plonger dans la mise en pratique : vous verrez comment ces concepts prennent vie à travers les outils et formats concrets utilisés dans un Lakehouse moderne.
