Distribuez vos données à l'échelle

La distribution de données et le sharding
La distribution de données consiste à répartir les informations entre plusieurs serveurs ou nœuds, souvent situés dans différents endroits géographiques. Nous avons vu que les objectifs de cette démarche étaient les suivants :
Réduction des goulots d’étranglement : En répartissant la charge de travail, chaque nœud traite une fraction des requêtes, améliorant ainsi les performances.
Haute disponibilité : Même en cas de panne d’un nœud, les autres peuvent prendre le relais pour garantir l’accès aux données.
Extensibilité : La capacité totale du système peut être augmentée simplement en ajoutant des nœuds, répondant ainsi aux besoins croissants des utilisateurs.
Découvrons maintenant en détail 2 concepts clés pour expliquer comment est organisée cette distribution de façon moderne avec les concepts d’élasticité et du “sharding”.
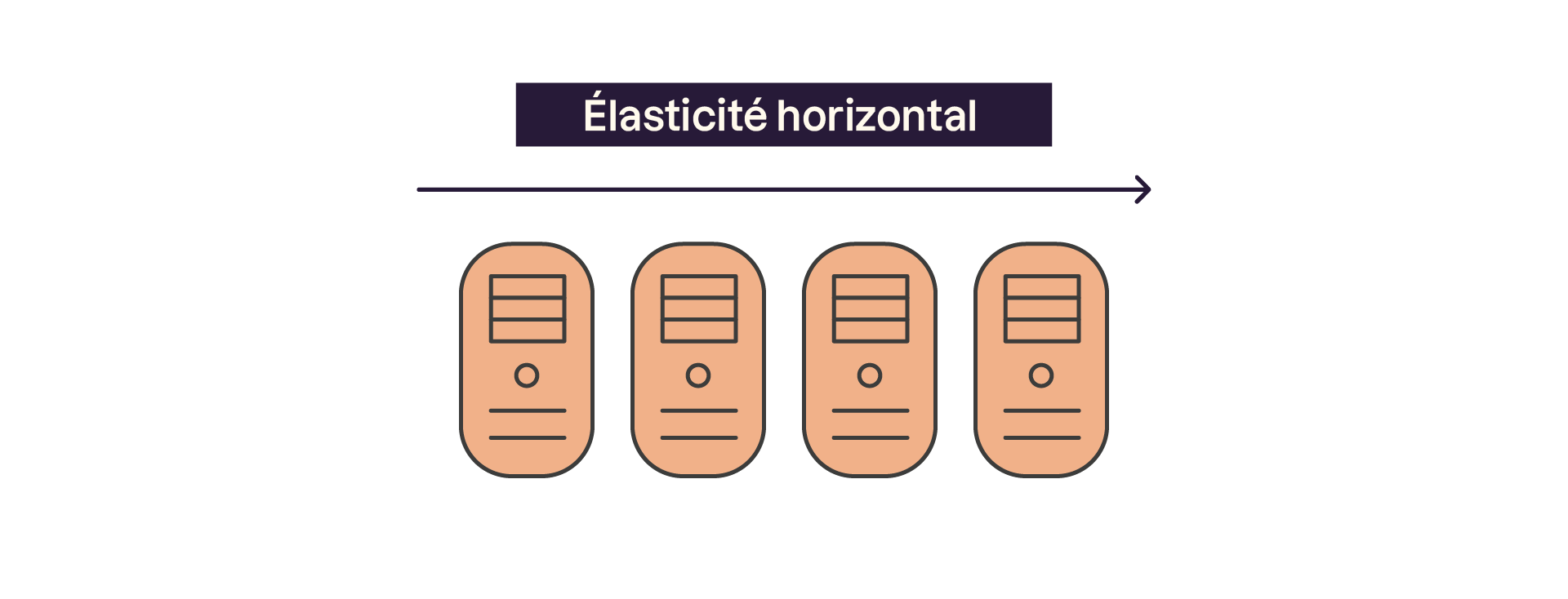
Elasticité :
L'élasticité des ressources fait référence à la capacité d'adapter dynamiquement l'infrastructure en fonction des besoins en charge ou en données. Cela se traduit par l'ajout ou le retrait de nœuds (serveurs) au sein du réseau.
Par exemple, lors de périodes de forte activité, comme un pic de trafic sur une boutique en ligne, des nœuds supplémentaires peuvent être ajoutés pour répartir la charge et maintenir de bonnes performances. Inversement, pendant les périodes de faible activité, des nœuds peuvent être supprimés pour réduire les coûts liés à l'infrastructure. Cette élasticité repose souvent sur des technologies de gestion automatique, telles que le déploiement dans le cloud, où les ressources peuvent être ajustées presque instantanément. Elle garantit une utilisation optimale des ressources tout en offrant une expérience utilisateur fluide, quel que soit le niveau de charge.
Sharding :
Le sharding est l’une des approches les plus populaires pour mettre en œuvre la distribution de données. Ce terme fait référence à la segmentation horizontale des bases de données : les données sont divisées en fragments appelés "shards", et chaque shard étant stocké sur un serveur différent.
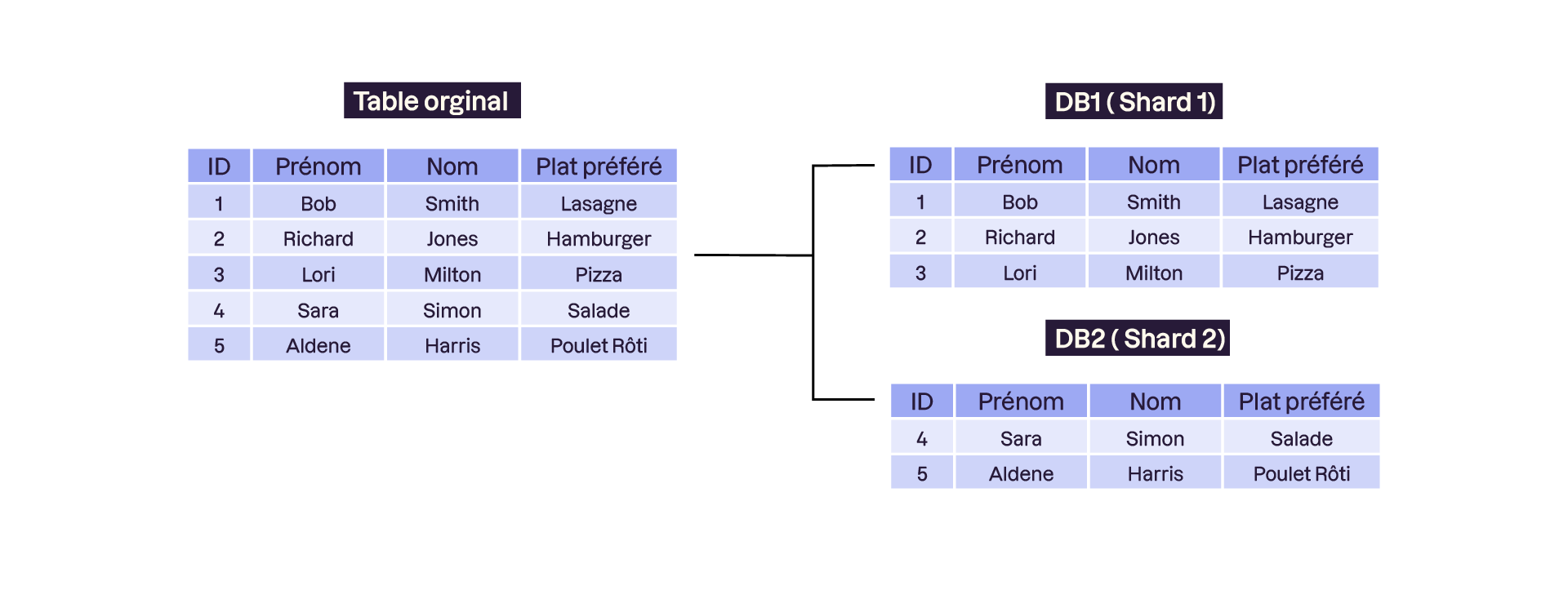
Fonctionnement du Sharding
L’idée principale du sharding est de répartir les données selon une clé spécifique, par exemple :
Par identifiant utilisateur (chaque shard contient les données des utilisateurs dont les identifiants sont compris dans une certaine plage).
Par géolocalisation (les données des utilisateurs d'une région spécifique sont regroupées sur le même shard).
Par type de données (chaque shard contient des données spécifiques, comme les historiques de transactions ou les profils utilisateurs).
Les Bénéfices du Sharding
Performance accrue : En divisant la base de données, chaque serveur manipule un sous-ensemble de données, réduisant les délais de réponse.
Extensibilité : Il est facile d'ajouter de nouveaux shards pour gérer des volumes de données croissants.
Résilience : Si un shard devient inaccessible, cela n’affecte pas nécessairement les autres shards.
Technologies de sharding
Comprendre comment le sharding de vos données est organisé est important car cela influence directement la performance, la scalabilité et la fiabilité de votre système, tout en permettant de mieux gérer la répartition des charges et la cohérence des données.
Regardons ensemble quelques méthodes de sharding parmi les plus courantes.
Sharding basé sur les plages
Les données sont réparties dans des shards selon des plages définies de valeurs. Par exemple, les IDs de 1 à 1000 iront dans le shard A, tandis que les IDs de 1001 à 2000 iront dans le shard B et ceux de 2001 à 3000 iront dans le shard C.
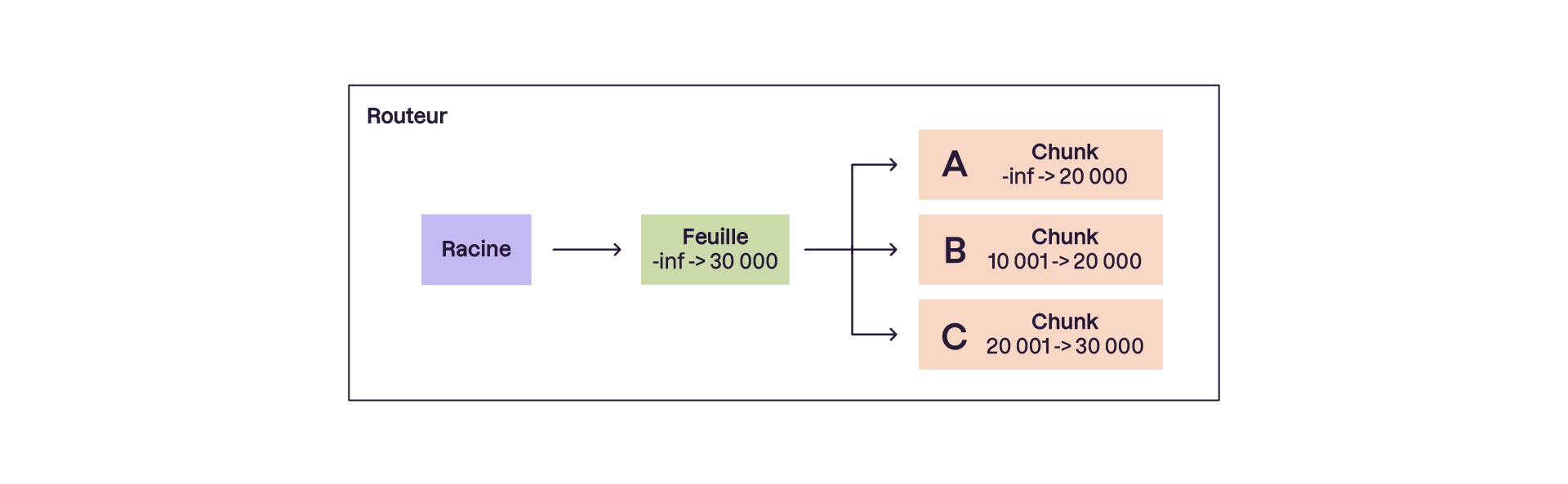
Avantage :
Rassembler les données ayant des valeurs similaires (tri), et de fait toute opération sur ces données rassemblées (regroupement/reduce) car le fait qu’elles soient ensemble réduit les allers-retours entre les nœuds et améliore la performance.
Limite :
Risque de surchage des shards si une plage contient beaucoup plus de données que les autres.
Sharding géographique
Dans cette approche, les données sont réparties selon leur origine géographique. Cela est particulièrement utile pour les applications avec des utilisateurs répartis sur plusieurs régions.
Avantage :
Réduction de la latence pour les utilisateurs grâce à une proximité géographique.
Limite :
Risque de surcharge dans une région plus active.
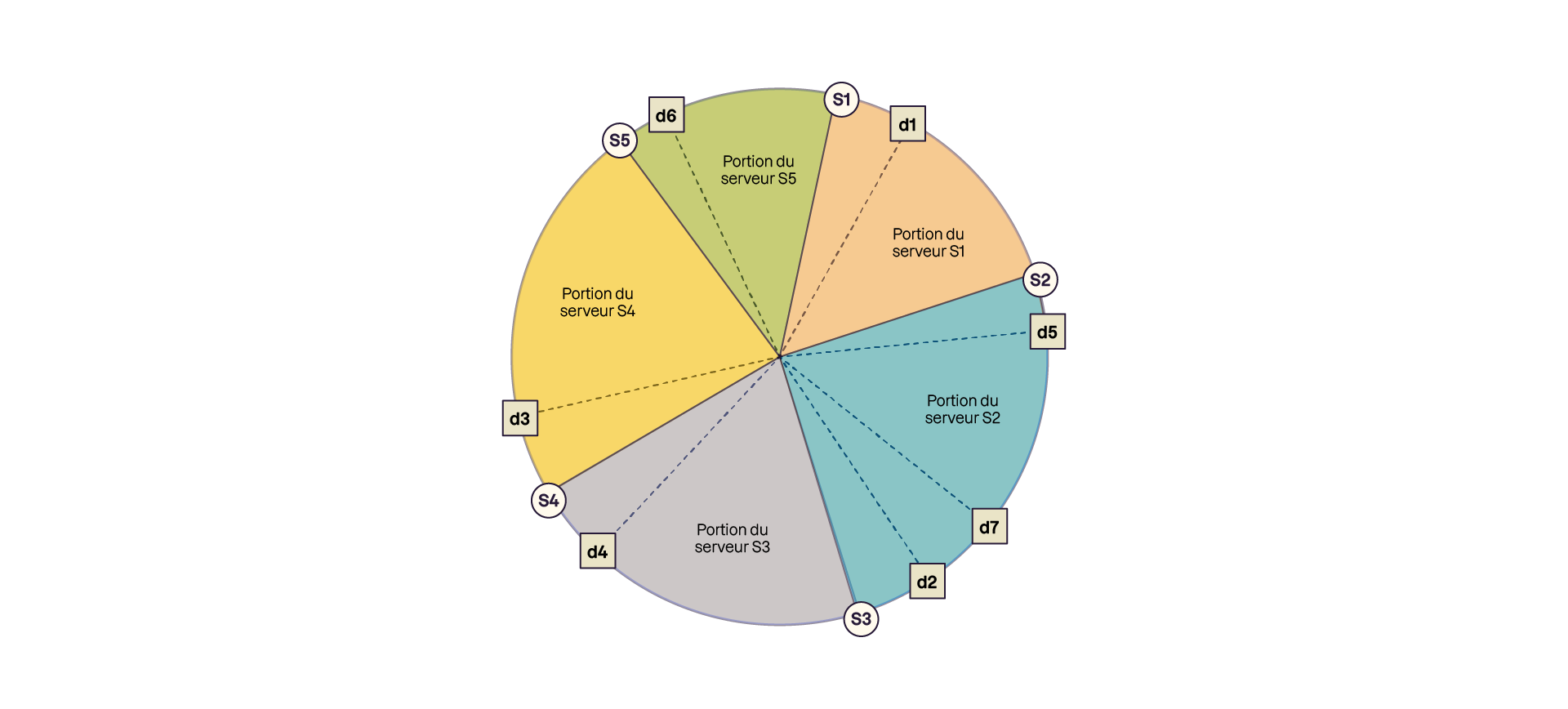
Consistent Hashing (Hachage cohérent)
Contrairement au sharding par plages, où les données sont réparties selon des intervalles définis d’un attribut (comme vu plus haut avec un identifiant par exemple), le consistent hashing repose sur une transformation préalable : chaque donnée est d’abord convertie en une valeur de hash, à l’aide d’une algorithme de hachage. C’est cette valeur de hash qui est ensuite utilisée pour distribuer nos données.
Le gros point positif ici, c’est que si nos données ne sont pas distribuées uniformément, par exemple on a beaucoup de données dans les ID entre 0 et 1000, et on en a beaucoup moins entre 1001 et 2000, avec l’attribution d’adresses avec le hash, nos données seront uniformément distribuées selon le hash. C’est une des propriétés de l’algorithme de hashing, deux valeurs proches (même successives) peuvent avoir des hash totalement différents. On ne se retrouve donc pas avec des nœuds surchargés et d’autres moins sollicités à cause de nos données de base.
Sur l’image ci-après on représente le consistent hashing comme produisant un anneau logique sur lequel toutes les adresses possibles (les clés de hash) sont mappées à l'anneau. On attribue un nœud à un angle de cet anneau, un peu comme une part de gâteau.
Cet anneau est virtuel et chaque serveur physique est placé sur cet anneau et prend en charge la portion du cercle allant jusqu’au prochain serveur physique. Comme on peut le voir sur la figure, les 5 serveurs se partagent le gâteau.
Un autre point positif de cette approche est son côté dynamique, avec l’arrivée de nouvelles données dans notre base, de nouveaux serveurs seront ajoutés pour redécouper “la part de gâteau” qui est surchargée avec une trop grande quantité de données.
Avantages :
Flexibilité pour l'ajout ou le retrait de nœuds.
Répartition uniforme des données.
Limites :
Nécessite une infrastructure plus complexe.
Peut être difficile à implémenter pour les systèmes simples.
🎧 Derrière l’écran
Alexandre est un expert de la Data, il occupe le rôle de Head of Data & AI Engineer chez Data Galaxy. Sa perspective est précieuse sur les défis rencontrés en entreprise, les solutions adoptées et les avantages qui en ont découlé. Dans l’entretien à suivre, il nous partage son expérience concrète pour mieux comprendre ses choix sur la distribution des données dans ses projets de développement et leurs implications pratiques.
En résumé
La distribution des données consiste à répartir les informations sur plusieurs nœuds dans un système, ce qui améliore la scalabilité, la disponibilité et les performances des applications.
Le sharding (ou partitionnement horizontal) est une technique de distribution des données qui les divise en sous-ensembles (shards) stockés sur différents serveurs
Les données peuvent être réparties selon divers critères, comme des clés uniques (sharding basé sur les clés), des plages de valeurs (sharding basé sur les plages) ou des segments géographiques.
Écrivez ici une phrase de transition pour présenter le prochain chapitre !
