Validez vos modèles temporels correctement avec Scikit-Learn
En machine learning il est courant de “mixer” les données entre elles avant de les splitter.
train_test_split(X, y, test_size=0.2, shuffle=True)Imaginez un instant faire un “shuffle” sur des données temporelles, et que des données de 2022 se trouvent en train et des données de 2020 se retrouvent en test. Vous entraînez le modèle sur des données du futur pour prédire le passé. C’est tout l’inverse que ce que l’on cherche à faire.
Identifiez les fuites de données (data leakage) les plus courantes
Certaines fuites de données sont parfois plus subtiles qu’un shuffle.
Vous vous rappelez dans le chapitre Préparez des données temporelles fiables avec Pandas, nous avions vu comment réaliser une moyenne mobile et je vous avais indiqué qu'elles pouvaient introduire un fuite temporelle.
Voyons en détails comment : reprenons notre moyenne mobile sur 12 jour en changeant un paramètre.
features_daily["ma_12d"] = features_daily["y"].rolling(window=12, center=True).mean()
display(features_daily[["y","ma_12d"]].head(12))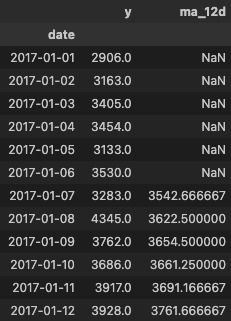
Cette fois-ci, la valeur de la moyenne mobile à une date donnée correspond à la moyenne des 6 jours précédents, du jour même et des 5 jours suivants. Si nous prenons la date d’aujourd’hui, sa moyenne mobile serait composée de la valeur des 6 jours précédents et des 5 prochains jours.
Pourquoi c’est grave ? Parce qu’un modèle entraîné avec ce type de variable “voit le futur”. Il aura l’air très performant sur un jeu de test mélangé… mais échouera dès que vous essayerez de prédire “pour de vrai” à une date donnée.
Pour les séries temporelles, vos features doivent être calculées avec une logique “causale” (uniquement passé → présent). Concrètement : pas decenter=Truepour une moyenne mobile destinée à la prédiction.
Pour éviter ces pièges et garantir la fiabilité de vos résultats, vous devez maîtriser les bonnes pratiques de validation en série temporelle.
La première chose que vous pouvez faire c’est de mettre en place une séparation chronologique simple entre un ensemble d'entraînement (train) et un ensemble de test, en respectant scrupuleusement l'ordre temporel des observations.
Vous l’avez déjà vu dans le chapitre Construisez des prévisions statistiques avec Holt-Winters et ARIMA, et cette fois ci nous allons nous attarder plus longuement sur cette séparation :
import pandas as pd
weekly = pd.read_csv("../../data/epidemioscope_clean_weekly.csv", parse_dates=["date"])
weekly = weekly.set_index("date")["ili_consultations"].sort_index()
h = 94
train, test = weekly.iloc[:-h], weekly.iloc[-h:]La séparation en train et test doit se faire de manière chronologique en partant de la fin. Leshdernières valeurs seront utilisées comme test. Cela permet de respecter la logique de relation temporelle entre les données.
Nous pouvons maintenant visualiser le résultat :
import plotly.express as px
df_split = pd.concat([
train.rename("train"),
test.rename("test"),
], axis=1).reset_index().melt(id_vars="date", var_name="serie", value_name="valeur")
fig = px.line(
df_split,
x="date",
y="valeur",
color="serie",
title="Split temporel (train/test)",
color_discrete_map={"train": "#1f77b4", "test": "#111111"},
)
fig.update_layout(template="plotly_white", legend_title_text="Série")
fig.show()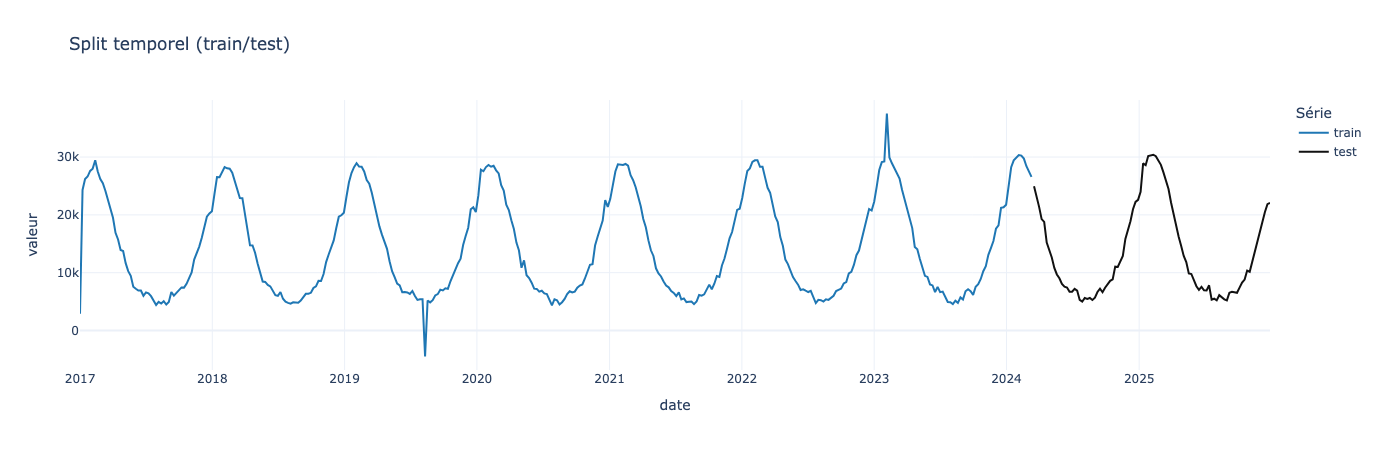
Visuellement nous pouvons valider que les données de tests sont postérieures aux données de train.
Mais du coup, peut-être que notre modèle fonctionne bien sur ce futur précis là mais pas sur d’autres ? Comment vérifier ça ?
Pour que vos métriques reflètent vraiment les performances du modèle, commencez par analyser le type et la répartition de ses erreurs.
Utilisez une validation adaptée : Time Series Split
La logique est plutôt simple, vous divisez votre jeu de données en partant du début et en augmenter la taille du split à chaque fois :
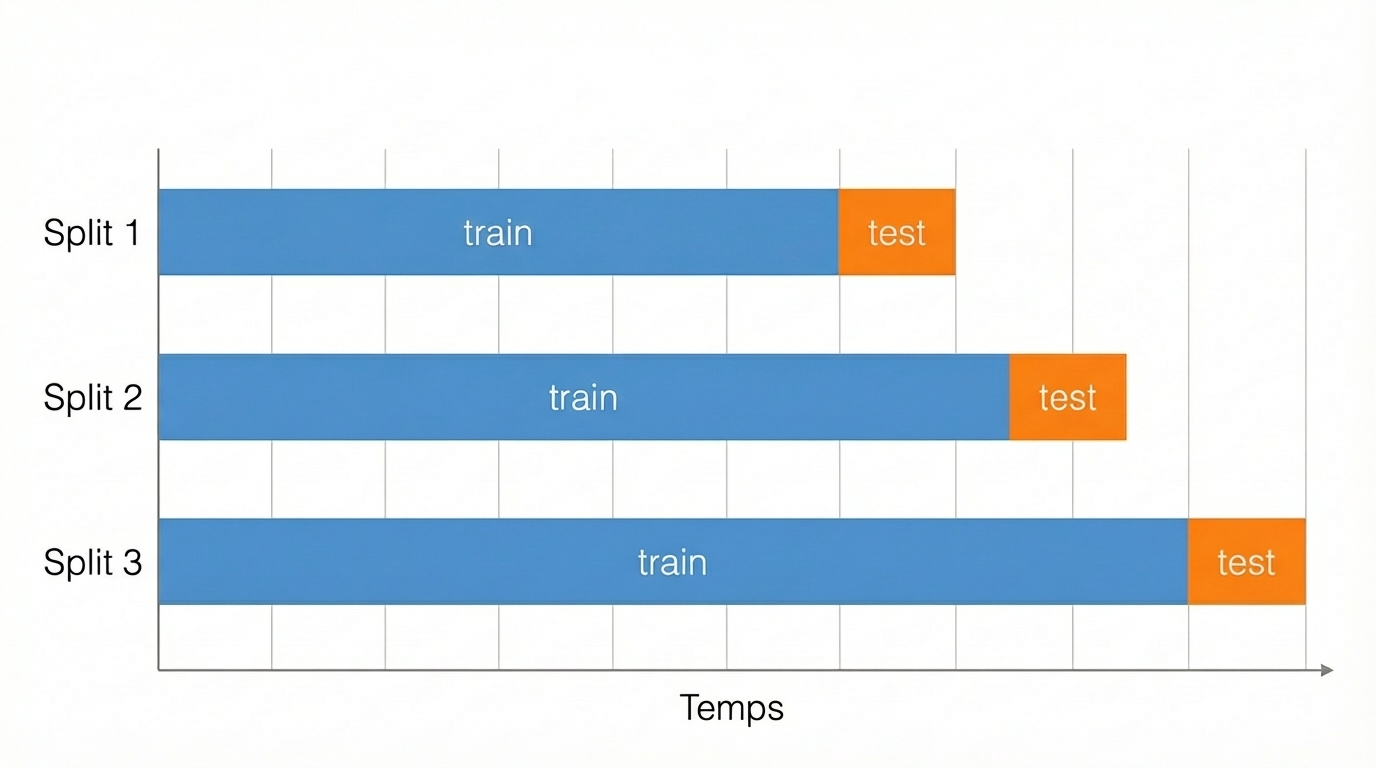
Cela permet de rendre votre modèle plus fiable et robuste.
Mettons en pratique cela avec une méthode nous provenant de Scikit-Learn :
Récapitulons ce que nous venons de voir :
import pandas as pd
import numpy as np
import plotly.express as px
from sklearn.model_selection import TimeSeriesSplit
from sklearn.metrics import (
mean_absolute_error,
root_mean_squared_error,
mean_absolute_percentage_error
)
from statsmodels.tsa.statespace.sarimax import SARIMAX
weekly = weekly.asfreq("W-SUN")
tscv = TimeSeriesSplit(n_splits=5)
all_data = []
mae_scores = []
rmse_scores = []
mape_scores = []
for i, (train_index, test_index) in enumerate(tscv.split(weekly)):
train = weekly.iloc[train_index]
test = weekly.iloc[test_index]
model = SARIMAX(
train,
order=(0,0,0),
seasonal_order=(0,1,1,52)
)
results = model.fit(disp=False)
forecast = results.forecast(steps=len(test))
mae = mean_absolute_error(test, forecast)
rmse = root_mean_squared_error(test, forecast)
mape = mean_absolute_percentage_error(test, forecast)
mae_scores.append(mae)
rmse_scores.append(rmse)
mape_scores.append(mape)
df_train = pd.DataFrame({
"date": train.index,
"value": train.values,
"type": "Train",
"split": f"Split {i+1} - MAE={mae:.2f} - RMSE={rmse:.2f} - MAPE={mape:.2f}"
})
df_test = pd.DataFrame({
"date": test.index,
"value": test.values,
"type": "Test",
"split": f"Split {i+1} - MAE={mae:.2f} - RMSE={rmse:.2f} - MAPE={mape:.2f}"
})
df_forecast = pd.DataFrame({
"date": test.index,
"value": forecast.values,
"type": "Forecast",
"split": f"Split {i+1} - MAE={mae:.2f} - RMSE={rmse:.2f} - MAPE={mape:.2f}"
})
all_data.append(pd.concat([df_train, df_test, df_forecast]))
plot_df = pd.concat(all_data)
fig = px.line(
plot_df,
x="date",
y="value",
color="type",
facet_row="split",
height=1800
)
fig.update_layout(
title="TimeSeries Split avec SARIMA",
legend_title=""
)
for ann in fig.layout.annotations:
ann.update(
textangle=0,
x=0,
xanchor="left",
y=ann.y + 0.07
)
fig.show()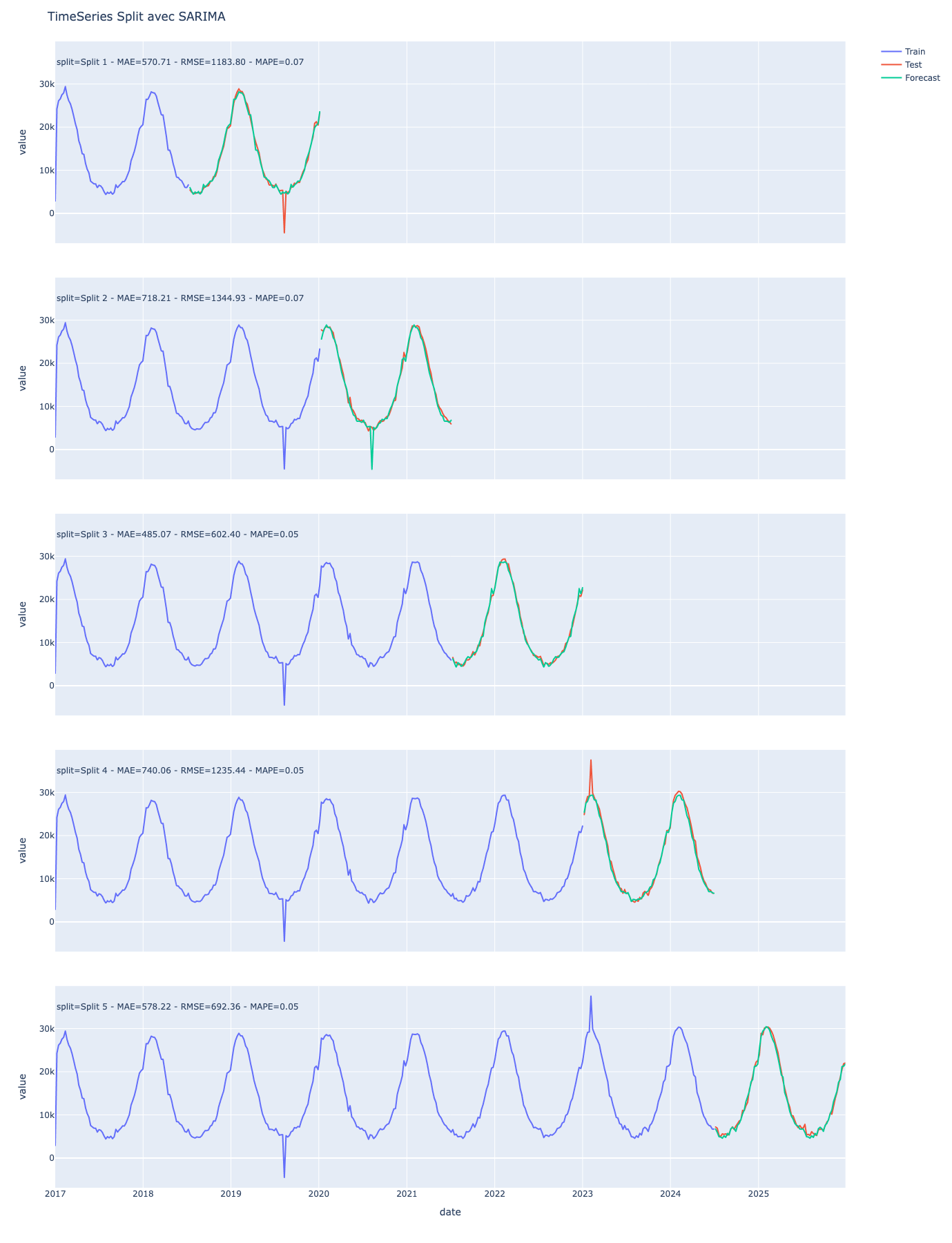
Avec un seul split, la robustesse du modèle peut être questionnable. En utilisant la méthode du walk-forward, nous pouvons affirmer avec plus de confiance que le modèle que nous avons produit est plus robuste.
Nous pouvons l’affirmer notamment grâce à la MAE.
Choisissez des métriques compréhensibles en entreprise
La MAE
Sur le dernier graphique de la partie précédente, la MAE est de 578, cela signifie que “En moyenne la prédiction se trompe de 578 consultations”.
En comparant le split 5 et le split 4, la MAE passe de 578 à 740, alors que le forecast suit bien visuellement la courbe de test à une exception près. Dans le split 4, il y a un pic dans les données de tests (valeur exceptionnelle), si nous voulons pénaliser notre modèle car il n’a pas vu ce pic, nous allons utiliser une autre mesure appelée RMSE.
La RMSE
Maintenant que vous avez compris l’intérêt de la MAE et de la RMSE, reprenons l’écart de 578 consultations du split 5. 578 peut paraître beaucoup, mais il faut le comparer à l’ordre de grandeur de nos données. Et c’est exactement ce que fait la MAPE.
La MAPE
Voyons maintenant comment cette métrique se positionne concrètement par rapport aux autres. Plutôt que d’annoncer simplement “En moyenne la prédiction se trompe de 578 consultations.” nous pouvons plutôt dire “En moyenne la prédiction se trompe de 5%”.
Résumons :
MAE | RMSE | MAPE |
Erreur moyenne en unité réelle | Erreur pénalisant les gros écarts | Erreur moyenne en % |
Reporting opérationnel : La MAE est idéale pour suivre les écarts quotidiens dans un contexte où les unités sont parlantes. Exemples : • Un responsable de stock qui veut savoir "de combien d'unités je me trompe en moyenne" • Un directeur commercial qui suit "combien de ventes j'ai raté en moyenne". C'est concret, facile à comprendre et à communiquer aux équipes terrain. | Gestion du risque : La RMSE est particulièrement utile quand les grosses erreurs coûtent cher ou ont des conséquences graves. Exemples : • Quand on essaie de prévoir la demande en électricité, si on ne prévoit pas assez de consommation lors d’un pic, le réseau peut ne pas produire ou acheminer assez d’électricité, et cela peut entraîner une coupure. • En finance, une grosse erreur de prévision de trésorerie peut créer un découvert. La RMSE permet d'identifier et de pénaliser ces situations critiques. | Pilotage stratégique : La MAPE est parfaite pour comparer des performances entre différents produits, régions ou périodes, car elle est indépendante de l'échelle. Par exemple, comparer l'erreur de prévision entre un produit vendu à 10 unités/jour et un autre à 10 000 unités/jour. Elle permet aussi de fixer des objectifs business type "notre taux d'erreur ne doit pas dépasser 5%". |
Analysez les résidus pour détecter un modèle incomplet
Maintenant que nous avons appris à mesurer les erreurs, nous devons vérifiez si ces erreurs sont le fruit du hasard (aléatoires) ou si c’est un problème de modélisation (structurées).
import pandas as pd
import plotly.express as px
from sklearn.model_selection import TimeSeriesSplit
from statsmodels.tsa.statespace.sarimax import SARIMAX
# Assure la fréquence hebdo
weekly = weekly.asfreq("W-SUN")
tscv = TimeSeriesSplit(n_splits=5)
all_residuals = []
for i, (train_index, test_index) in enumerate(tscv.split(weekly)):
train = weekly.iloc[train_index]
test = weekly.iloc[test_index]
model = SARIMAX(
train,
order=(0,0,0),
seasonal_order=(0,1,1,52)
)
results = model.fit(disp=False)
forecast = results.forecast(steps=len(test))
residuals = test - forecast
df_res = residuals.reset_index()
df_res.columns = ["date", "residuals"]
df_res["split"] = f"Split {i+1}"
all_residuals.append(df_res)
plot_res = pd.concat(all_residuals)
# Plot avec points
fig = px.scatter(
plot_res,
x="date",
y="residuals",
facet_row="split",
height=1800,
title="Résidus du modèle SARIMA par split"
)
# Mise en forme des titres de facet
for ann in fig.layout.annotations:
ann.update(textangle=0, x=0, xanchor="left", y=ann.y + 0.03)
fig.show()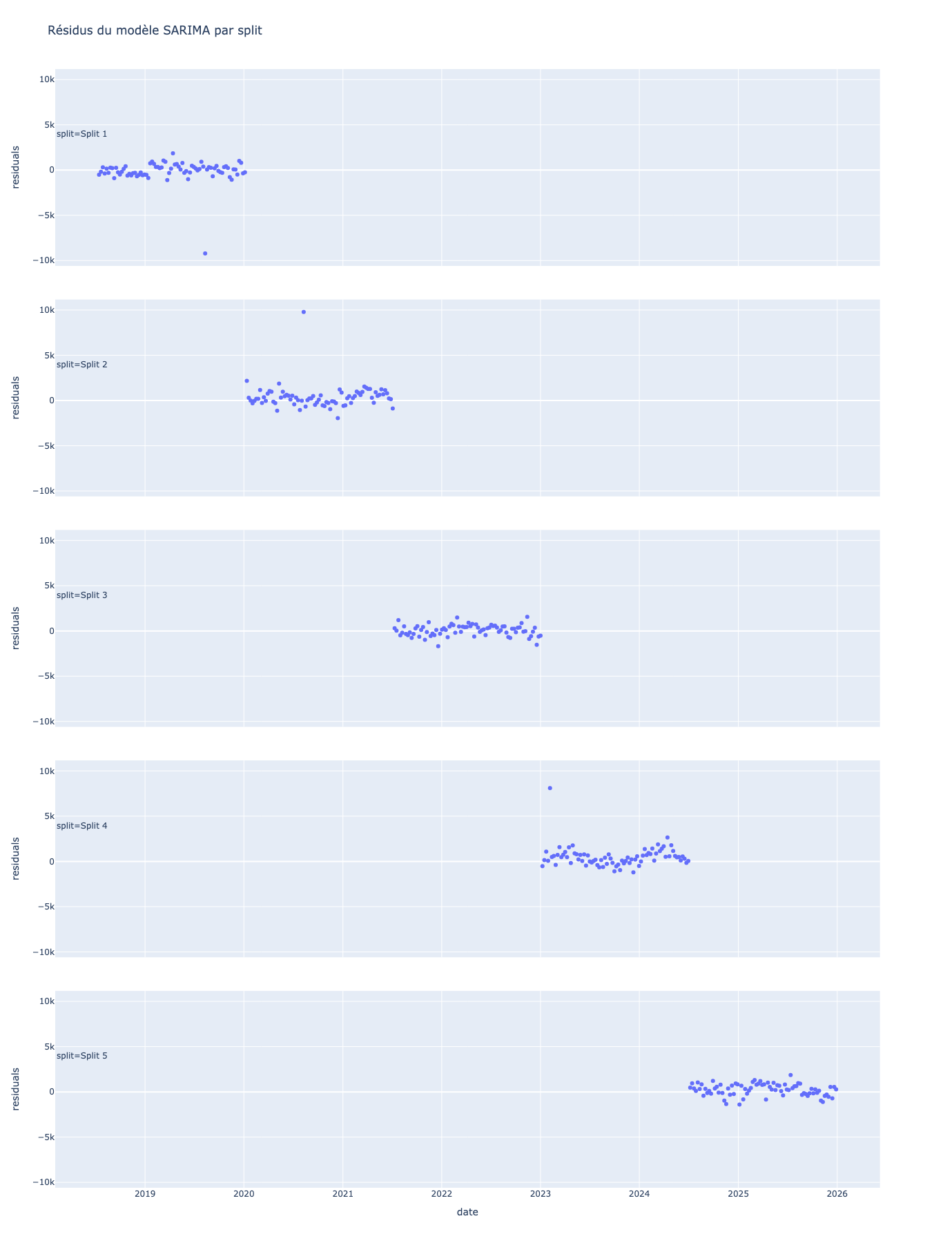
Les erreurs de prédictions (résidus) sont visiblement bien centrées autour de 0 (centrage) et aucune tendance claire ni saisonnalité n’est observée (structure). A part quelques valeurs extrêmes, les points sont aussi bien répartis (variance) de manière homogène.
Si vous avez bien suivi, vous vous demandez peut-être :
Comment savoir si ces résultats sont vraiment fiables ?
C'est exactement ce que nous allons vérifier maintenant, en passant des observations visuelles à une validation statistique rigoureuse.
Nous avons observé visuellement plusieurs éléments :
Le centrage se trouve autour de 0
La variance est constante
L’absence d’autocorrélation est marquée
Il est temps de valider ces observations avec des outils mathématiques.
Le centrage
Concernant le centrage, nous allons tester l’hypothèse que la moyenne des résidus soit égale à 0 à l’aide du T-Test :
from scipy import stats
results_t_test= stats.ttest_1samp(plot_res["residuals"], 0)
print(results_t_test.pvalue)La moyenne des résidus étant à 180 et lapvalueétant inférieure à0,05, l’hypothèse est rejetée, ce qui contredit notre observation visuelle du départ. En pratique, avec des valeurs oscillant entre 5000 et 30000, un écart de 180, peut être considéré comme négligeable.
Penchons nous maintenant sur la constance de la variance.
La constance de la variance
Concrètement, après avoir entraîné un modèle, on regarde ses résidus (résidu = réel - prédit). Si le résidu est positif → le modèle a sous‑prédit (il a prédit trop bas). Si le résidu est négatif → le modèle a sur‑prédit (il a prédit trop haut).
La question est la suivante : est-ce que l’ampleur de ces erreurs reste à peu près la même tout au long du temps ?
Si oui, on parle d’homoscédasticité.
Si non (par exemple des erreurs petites au début puis beaucoup plus grandes ensuite, ou des “paquets” de volatilité), on parle d’hétéroscédasticité.
Pour objectiver ce diagnostic, on peut utiliser des tests statistiques. Ils ne “réparent” pas le problème, mais ils permettent de détecter si la variance des résidus semble dépendre du temps.
Le test de Breusch-Pagan est le plus utilisé pour tester l’hypothèse de l’homoscédasticité (variance constante). Mais nous allons utiliser un autre test, plus spécifique aux séries temporelles, le test ARCH :
from statsmodels.stats.diagnostic import het_arch
resultats_ARCH = het_arch(plot_res["residuals"])
print(resultats_ARCH[1])
Avec unpvalue>0.05l’hypothèse nulle n’est pas rejetée, ce qui signifie bien que la variance résidus est indépendante du temps.
L’autocorrélation
Enfin concernant l’autocorrélation, nous allons utiliser un test de Ljung-Box pour tester l’hypothèse qu’il y a une autocorrélation significative entre les résidus, et donc qu’il y a une “structure” :
from statsmodels.stats.diagnostic import acorr_ljungbox
acorr_ljungbox(plot_res["residuals"], lags=[10, 20, 52], return_df=True)Encore une fois avec unepvalue<0.05l’hypothèse nulle est rejetée, ce qui signifie que qu’il existe une structure dans les résidus et que ce ne sont pas simplement que du “bruit”.
À vous de jouer !

Consigne :
Maintenant que vous avez vu comment qualifier mathématiquement les résidus d’un modèle SARIMA, vous allez tester des changements de paramètres pour essayer d’enlever l’autocorrélation de vos résidus au lag 10.
Corrigé :
import pandas as pd
from sklearn.model_selection import TimeSeriesSplit
from statsmodels.tsa.statespace.sarimax import SARIMAX
from statsmodels.stats.diagnostic import acorr_ljungbox
# Chargement des données
weekly = pd.read_csv(
"data/epidemioscope_clean_weekly.csv",
parse_dates=["date"]
)
weekly = (
weekly
.set_index("date")["ili_consultations"]
.sort_index()
.asfreq("W-SUN")
)
# Validation temporelle
tscv = TimeSeriesSplit(n_splits=5)
# Paramètres testés
parametres = [
{"order": (0, 0, 0), "seasonal_order": (0, 1, 1, 52)},
{"order": (1, 0, 0), "seasonal_order": (0, 1, 1, 52)},
{"order": (0, 0, 1), "seasonal_order": (0, 1, 1, 52)},
{"order": (1, 0, 1), "seasonal_order": (0, 1, 1, 52)},
]
for params in parametres:
print(f"Test du modèle SARIMA{params['order']}{params['seasonal_order']}")
all_residuals = []
for i, (train_index, test_index) in enumerate(tscv.split(weekly)):
train = weekly.iloc[train_index]
test = weekly.iloc[test_index]
model = SARIMAX(
train,
order=params["order"],
seasonal_order=params["seasonal_order"]
)
results = model.fit(disp=False)
forecast = results.forecast(steps=len(test))
residuals = test - forecast
all_residuals.extend(residuals)
# Test de Ljung-Box au lag 10
lb_test = acorr_ljungbox(all_residuals, lags=[10], return_df=True)
print(lb_test)
print("-" * 50)En résumé
Ne mélangez jamais le passé et le futur, car une validation correcte respecte l’ordre chronologique des données.
Réalisez toujours un split temporel clair, en entraînant le modèle sur le passé et en évaluant sur des périodes futures.
Utilisez une validation walk-forward avec
TimeSeriesSplitpour tester le modèle sur plusieurs “futurs” successifs.Choisissez des métriques adaptées à votre contexte et faciles à expliquer, comme la MAE, la RMSE et la MAPE.
Analysez systématiquement les résidus pour vérifier si les erreurs sont aléatoires, et ajustez le modèle si une structure persiste.
Maintenant que vous avez bien saisie la théorie des modèles de prédiction de séries temporelles telle que SARIMA, nous allons voir comment passer d’un outil académique comme SARIMA à un outil pragmatique que Prophet.
