Les algorithmes et modèles de machine learning utilisent des entrées numériques, puisque nous travaillons avec des espaces topologiques voire métriques la plupart du temps.
Alors comment faire pour représenter du texte.. ?
Lorsqu’on traite des données brutes à grande dimensions comme des images ou du spectre audio, on utilise directement des vecteurs de coefficients associées aux intensité de pixel dans le premier cas ou les coefficients de densité spectrales dans le second cas.
Le problème avec un texte, c’est que l’on va traiter les mots et groupes de mots comme des entités symboliques non porteuses de sens, c’est à dire indépendantes les unes des autres.

Dans les chapitre précédents, nous avons vu une première manière de représenter nos documents comme des bag-of-words ou bag-of-ngrams, essentiellement des méthodes de comptage direct (fréquence ou tf-idf). On a donc techniquement représenté chaque document par un vecteur de fréquences du dictionnaire de mots que l’on avait à disposition. Nous sommes amené à traiter des données lacunaires ou creuses (en anglais sparse). Même avec TF-IDF, on considère des comptages déterministes comme représentatifs de nos données, en l’occurrence la fréquence du mot et la fréquence inverse du document.
Une récente famille de techniques (circa 2013) a permi de repenser ce modèle avec une représentation des mots dans un espace avec une forme de similarité entre eux (c'est-à-dire probabiliste), dans lesquels le sens des mots les rapproche dans cet espace, en terme de distances statistiques. C’est un plongement dans un espace de dimension inférieur autour de 20-100 dimensions généralement. Son petit nom : word2vec.

Mais comment trouver le sens des mots ? C’est un peu vague comme concept, non ?
Effectivement. L’hypothèse principale de ces méthodes étant de prendre en compte le “contexte” dans lequel le mot a été trouvé, c’est à dire les mots avec lesquels il est souvent utilisé. On appelle cette hypothèse distributional hypothesis.
Et ce qui est intéressant, c’est que ce contexte permet de créer un espace qui rapproche des mots qui ne se sont pas forcément trouvés à côté les uns des autres dans un corpus ! Ces méthodes de représentation vectorielles ont aussi permis d’entraîner des modèles de représentation des mots sur des corpus beaucoup plus grands (des centaines de milliards de mots par exemple...)
Ces représentations possèdent des capacités surprenantes. Par exemple, on peut retrouver beaucoup de régularités linguistiques simplement en effectuant des translation linéaires dans cet espace de représentation. Par exemple le résultat de vec(“Madrid”) - vec(“Spain”) + vec(“France”) donne une position dont le vecteur le plus proche est vec(“Paris”) !

Afin de calculer les vecteurs qui représentent les mots, les méthodes word2vec utilisent des perceptrons linéaires simples avec une seule couche cachée. L’idée est de compresser notre corpus vers un dictionnaire de vecteurs denses de dimension bien inférieure choisie.
Je n’ai pas l’impression que le contexte a été pris en compte, si ?
On ne va pas détailler les méthodes d’entraînement en détails, mais il faut savoir qu’il en existe deux principales. La première appelée « Continuous Bag of Words » (CBOW), qui entraîne le réseau de neurones pour prédire un mot en fonction de son contexte, c’est à dire les mots avant/après dans une phrase. Dans la seconde méthode, on essaie de prédire le contexte en fonction du mot. C’est la technique du « skip-gram ».
En d’autres termes, l’entrée du réseau de neurones dans le cadre du CBOW prend une fenêtre autour du mot et essaie de prédire le mot en sortie. Dans le cadre du skip-gram on essaie de faire l’inverse, c’est-à-dire prédire les mots autour sur une fenêtre déterminée à l’avance à l’aide du mot étudié en entrée.
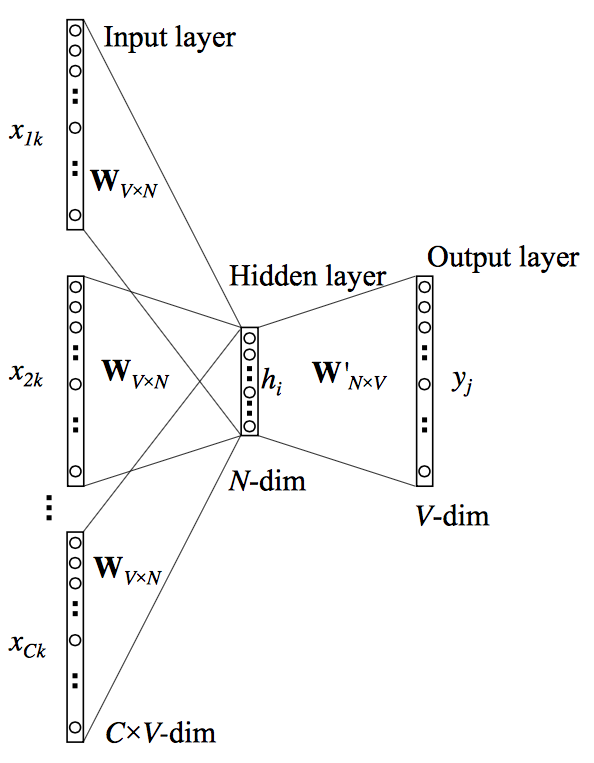
Et c’est cette hypothèse - le fait que les mots soient caractérisés par les mots les entourants - qui permet de créer cette compression. Des mots davantage associés aux mêmes mots seront proches dans l’espace d’arrivée.
Utiliser un modèle de langage
Avoir cette représentation vectorielle des mots permet d’utiliser ces vecteurs comme des features dans un grand nombre de tâches de base de traitement du langage. On peut ainsi alimenter des algorithmes classiques tels qu’un SVM ou un réseau de neurones avec nos vecteurs caractéristiques des mots.
Pour récapituler, on peut transformer un texte en ses features soit :
En utilisant une représentation de comptage creuse - fréquence d’apparition du mot dans un document, ou vecteur tf-idf d’un document, etc.
En utilisant une représentation type word2vec dense - dans laquelle le mot possède une représentation dans un espace qui le positionne en fonction des mots adjacents
Nous verrons dans les prochains chapitres comment utiliser ces représentations de documents dans nos algorithmes afin de pouvoir effectuer différentes tâches de classification, modélisations non supervisées et autres manipulations propres au traitement de langage.
Alternatives à word2vec
En pratique, on peut utiliser d’autres types de représentations denses des mots, au-delà du choix de l’algorithme (CBOW, skipgram) et de la dimension. Il existe notamment d’autres méthodes de plongement (word embeddings) tels que gloVe et FastText.
Certains favorisent même l’utilisation d’une simple décomposition SVD sur une matrice PMI (pointwise mutual information) qui donneraient des performances largement suffisante pour la plupart des applications industrielles.
L’idée fondamentale reste la même : compresser de manière non supervisée la représentation d’un mot à partir d’un gros corpus de texte représentatif de votre langage, afin d’obtenir un vecteur dense qui permet de visualiser et de fournir à nos algorithmes des features plus intéressantes.
Entraîner son propre embedding
Il existe plusieurs plongements disponibles directement en ligne (surtout en anglais) qui ont été entrainés avec les méthodes évoquées plus haut. C’est utile pour avoir un modèle de représentation très général de votre vocabulaire sur une langue en particulier. Cependant vous êtes limité au registre du corpus utilisé. Par exemple si l’embedding a été réalisé sur Wikipédia, vous allez avoir un registre relativement soutenu. Cela biaise un peu la modélisation et surtout rend moins précis votre plongement vis à vis du problème rencontré. Cela a aussi pour effet de dissiper des différences entre vecteurs qui pourraient être utiles pour votre problème en faveur des grandes disparités (comme l’exemple masculin / féminin ou capitale / pays).
L’avantage d’entraîner son propre embedding est donc d’avoir un plongement spécifique à notre corpus et donc plus performant concernant la problématique que l’on veut traiter. Vous pouvez ensuite comparer cet embedding à une baseline utilisant un embedding général.
Conclusion
Les plongements de mots sont les représentations les plus utilisées actuellement dans les dernières méthodes de traitement du langage. C'est devenu un outil incontournable à tester lors de vos manipulations de texte. Si vous avez le temps et les ressources nécessaires, n'hésitez pas à entraîner votre propre embedding spécialisé sur votre problématique.
