Discover the Power of Word Embeddings
In Part 2, you learned that text vectorization is vital for any subsequent classification task. You also learned that the bag-of-words approach, with tf-idf, is a simple and quite efficient method, but it has several shortcomings:
Context and meaning are lost.
The document-term matrix is large and sparse.
Vectorization is relative to the corpus (similar words will have different vectors on another corpus).
In Part 3, we will look at another text vectorization system called word embeddings that will help overcome these shortcomings.
Identify the Benefits of Word Embeddings
In 2013, a new text vectorizing method called embeddings took NLP by storm. An embedding technique called word2vec was born, soon to be followed by GloVe and fastText.
Not only did these new vectorization methods solve the inherent shortcomings of tf-idf, but they also brought something amazing. Each word now possessed a universal numerical representation associated with its own definition. It became possible to represent each word by a unique vector independent of the text under consideration. And working with vectors gave the possibility to calculate distance between words, a similarity score between word pairs. This score is called semantic similarity or semantic distance.
Let’s explore the benefits of word embeddings further:
1. They Retain Semantic Similarity
One of the most remarkable properties of word embeddings is their ability to capture the semantic relationship between words. For example:
A hammer and pliers are both tools. Since they are related or similar in meaning, their vectors will be near one another. Similar to the words apple and pear or truck and vehicle.
When visualizing word vectors in a 2D space, similar words are grouped in the same regions. The figure below shows the five most similar words: Paris, London, Moscow, Twitter, Facebook, pizza, fish, train, and car, according to word2vec embeddings.
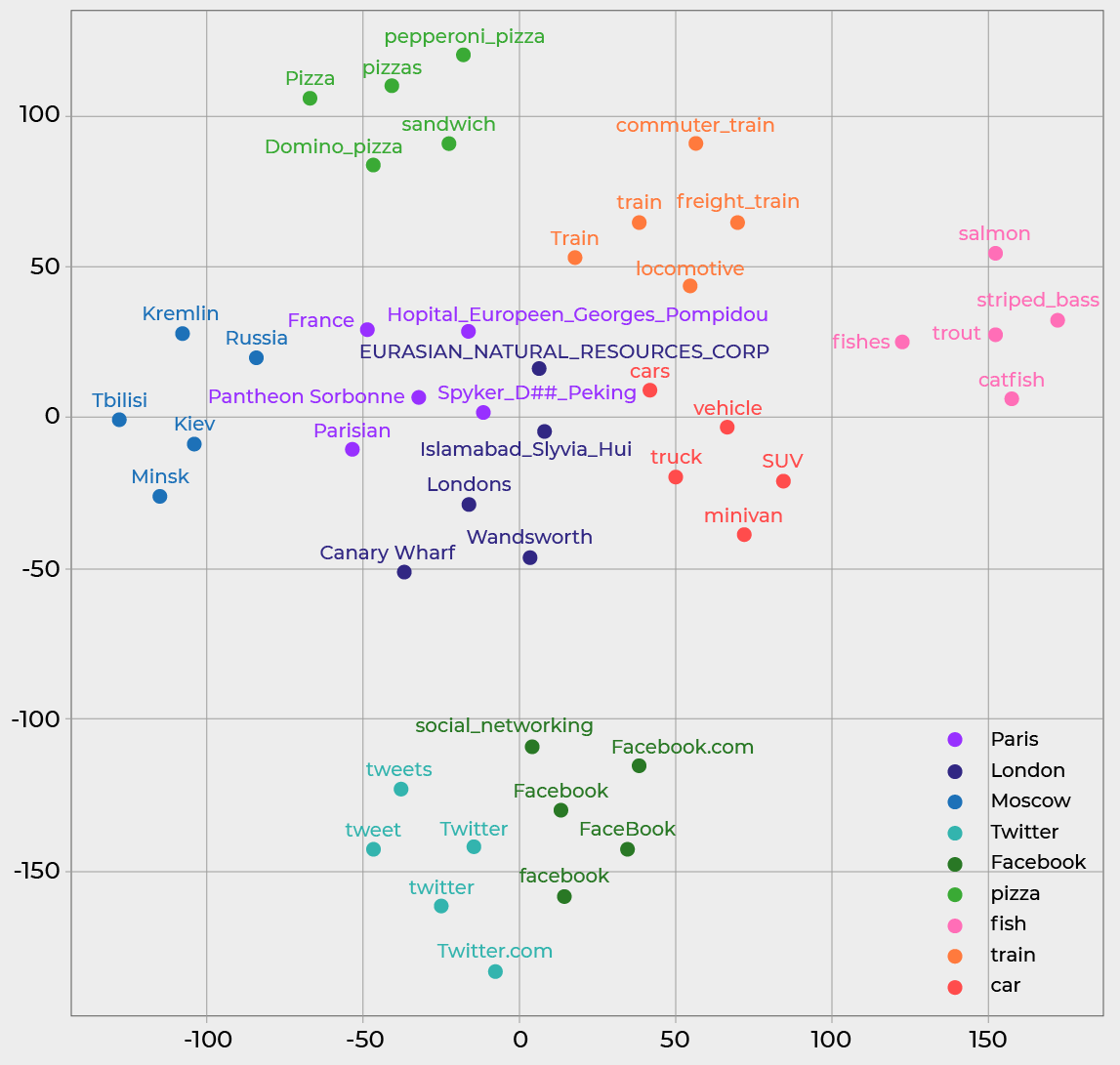
As you can see, similar words are closer together. Truly amazing!
Another neat feature of word embeddings is the ability to capture analogies between words. For example, a woman is to a queen what a man is to a king; Paris is to France what Berlin is to Germany. You can basically add and subtract words, as you would with vectors.
In this case, the distance between the respective vectors for woman and queen is close to the distance between the vectors for man and king.
But semantic similarity is not the only advantage of word embeddings. Let’s take a look at more.
2. Word Embeddings Have Dense Vectors
Whereas tf-idf vectors were mostly filled with zeros, word embeddings are dense vectors. Furthermore, all the elements of a word embedding vector are non-zero, except for the occasional element. Thus, more information is available for the subsequent models to work with, which improves performance.
3. They Have a Constant Vector Size
With word embeddings, the vector size is no longer dependent on the number of documents in your corpus. Instead, it is a parameter of the model. You decide beforehand what vector size you need to represent each word. Pre-trained embeddings usually come in dimensions 50, 100, and 300.
4. Their Vector Representations Are Absolute
Word embeddings are trained on gigantic datasets. For instance, word2vec was trained on a Google News dataset of 100 billion words, GloVe on a dataset of 6 billion words, and fastText on 16 billion tokens. As a direct consequence, these models have extensive vector representations. For example, word2vec has 3 million vectors, GloVe has 400,000, and fastText has 1 million.
5. They Have Multiple Embedding Models
Last but not least, you can download pre-trained models and use the word vectors directly. No need to generate them for each new corpus! 🙂
There are multiple types of pre-trained embedding models available online. A list is available on the gensim-data repository. spaCy also provides multiple sets of word embeddings out of the box.
The main differences between available sets of word embeddings are:
The creation process: word2vec, GloVe, and fastText are trained in different ways (we will explore this further in the next chapter).
The different vector sizes: These are arbitrarily set before training the model.
The nature of their training data and the vocabulary it holds.
Now that you understand the power of word embeddings, let’s take a closer look at some of the pre-trained models from the Gensim data repository!
The Functionalities of Gensim
Gensim and spaCy are two major Python libraries that work with pre-trained word embeddings. Since we have already explored spaCy in previous chapters, let’s experiment with Gensim.
Gensim can be installed with:
pip:
pip install --upgrade gensimconda:
conda install -c conda-forge gensim
Gensim documentation is less appealing than NLTK or spaCy, but it is a fundamental component of NLP.
Gensim allows you to work directly with the several types of embeddings mentioned earlier. However, in this chapter, we will focus on the original 1.7 Gb word2vec model: word2vec-google-news-300.
Load it in Gensim with:
import gensim.downloader as api
model = api.load("word2vec-google-news-300")Let’s start with three Gensim functions:
model[word]to get the actual word vector.most_similarfor a list of words that are most similar to a given word.similaryto compute a similarity score between two words.
For example:
model['book'] returns a vector with 300 elements:
import gensim.downloader as api
model = api.load("word2vec-google-news-300")
print(model['book'])Returns:
> array([ 0.11279297, -0.02612305, -0.04492188, 0.06982422, 0.140625, 0.03039551, -0.04370117, 0.24511719, 0.08740234, -0.05053711])The most_similar() function returns the 10 most similar words and their similarity scores:
model.most_similar("book")> [('tome', 0.7485830783843994),
('books', 0.7379178404808044),
('memoir', 0.7302927374839783),
('paperback_edition', 0.6868364810943604),
('autobiography', 0.6741527915000916),
('memoirs', 0.6505153179168701),
('Book', 0.6479282379150391),
('paperback', 0.6471226811408997),
('novels', 0.6341458559036255),
('hardback', 0.6283079385757446)]And:
model.most_similar("apple")> [('apples', 0.7203598022460938),
('pear', 0.6450696587562561),
('fruit', 0.6410146355628967),
('berry', 0.6302294731140137),
('pears', 0.6133961081504822),
('strawberry', 0.6058261394500732),
('peach', 0.6025873422622681),
('potato', 0.596093475818634),
('grape', 0.5935864448547363),
('blueberry', 0.5866668224334717)]The similarity() function calculates the cosine similarity score between two words:
model.similarity("apple", "banana")
> 0.5318406
model.similarity("apple", "dog")
> 0.21969718
model.similarity("cat", "dog")
> 0.76094574According to word2vec, a cat is more similar to a dog than an apple (makes sense)!
The word2vec Vocabulary
You can explore examples of the word2vec vocabulary with model.vocab, which returns a dictionary of tokens. The words are the dictionary keys, and their values are the index of the word in the Gensim model. You can randomly sample five tokens from the model's vocabulary with the following:
import numpy as np
vocab = model.vocab.keys()
np.random.choice(list(vocab), 5)Execute these lines a few times. You get tokens such as:
['Vancouver_Canucks_goaltender', 'eSound', 'DLLs', '&A;', 'Rawdha'] ['Hodeidah', 'Cheatum', 'Mbanderu', 'common_equityholders', 'microfabricated'] ['Dataflow', 'Ty_Ballou', 'Scott_RUFFRAGE','prawn_dish', 'offering']
The word2vec vocabulary is not only composed of regular words. It also contains:
Bigrams and trigrams: common_equityholders , prawn_dish, Vancouver_Canucks_goaltender
Proper nouns: Scott_RUFFRAGE or Ty_Ballou
Specific character sequences: &A
Take it Further: Calculate Similarity Between Words
Remember how we talked about the similarity between words? Are you curious about how it’s calculated? Let’s explore.
You calculate the similarity between words using a metric called cosine similarity.
Without getting into too intense mathematical notations, the idea behind cosine similarity is to calculate the distance between two vectors. For example, picture the distance between two points on a sheet of paper. This is the same, but instead of having vectors of dimension 2 (x, y coordinates), you calculate the distance between vectors of dimension N, the word embeddings. Check out this page to see the exact math equations..
Cosine similarity is not the only metric you can use to calculate the similarity between words. However, it is the most common one when working with word embeddings.
The Shortcomings of Word Embeddings
As mentioned before, these models depend on the data they were trained on. This carries two significant side effects: cultural bias and out-of-vocabulary (OOV) issues.
Cultural Bias
The word2vec model was trained on a massive U.S. Google News corpus. It learned the relationships between words on the news as seen by Google in the U.S. There’s nothing inherently biased about news in the U.S. versus some other corpus from another part of the world, but training on such a dataset means that the model inherits a certain dose of cultural bias.
One funny example happens to be my name, Alexis. In the U.S., it is feminine, whereas, in the rest of the world (as far as I know), it’s a masculine name. You can see the U.S. bias by looking at words most similar to Alexis, according to word2vec:
model.most_similar('Alexis')
> ('Nicole', 0.7480324506759644),
('Erica', 0.745315432548523),
('Marissa', 0.7406104207038879),
('Alicia', 0.7322115898132324),
('Jessica', 0.7315416932106018),
....There are mostly feminine names. It is a good illustration of the inherent cultural learnings of the word2vec model. For more critical issues, you should be aware that these models are not universal or neutral but directly influenced by the corpus they were trained on.
Out-of-Vocabulary Words (OOV)
Another issue with GloVe and word2vec is the finite nature of the model’s vocabulary.
You have seen that the word2vec list of known tokens is heterogeneous and complex. But even with over 3 million entries, there are certain words it can’t identify, words for which there is no associated vector. These are called out-of-vocabulary words (OOV). For example:
Covid (in all its cases and with or without "-19").
word2vec (yes, word2vec does not know about its own existence). 🙂
There are different strategies for handling out-of-vocabulary words. The simplest one is to return a vector of zeros for unknown words.
try:
return model[word]
except:
return numpy.zeros(N)Update the Embeddings
Another possibility is to use the pre-trained word2vec model and your own dataset to continue training the model. Out-of-vocabulary words in your dataset will end up with their own vector representations. The process is called fine-tuning or transfer learning and is particularly helpful when working on a domain-specific corpus (healthcare, biomedical, law, or astronomy).
Let’s Recap!
There are three classic word embedding approaches: word2vec, GloVe, and fastText.
Word embeddings help overcome the inherent shortcomings of the bag-of-words approach:
They capture the semantic relationship between words.
They are dense vectors, meaning that all their values are non-zero. More information is made available.
The vector size is constant and independent of the number of documents in your corpus.
Vector representations are also independent of the nature and content of the corpus.
You can download pre-trained models from the gensim-data repository.
Word embeddings have their own set of shortcomings:
They carry cultural bias from the training dataset.
There are certain words that they cannot identify. These are called out-of-vocabulary words.
In the next chapter, we will dive deeper into the inner workings of word2vec, GloVe, and fastText!
