Optimize Alert Relevance and Process Efficiency
You have implemented a detection process and dealt with several incidents. But cyberattacks are rapidly changing—and so is your organization!
Therefore, your third task is to contribute to the development of the SOC and its ongoing improvement.
In this section, we’ll look at how to integrate the feedback obtained at the end of the incidents, as covered in the previous section.
Let’s start with looking at how you can save time by improving your processes.
Understand the Challenges of Continuous Improvement in a SOC
Why is continuous improvement important? If the SOC is well designed, there’s no need to change it, right?
Even in a mature SOC, there are always going to be problems to correct.
The IS you are trying to protect is constantly evolving as new solutions, machines, services, and more are being deployed. All of these solutions need to be monitored by the security processes and potentially integrated into the security perimeter monitored by the SOC.
The attack surface, in particular, is constantly evolving. Not only does your security perimeter evolve, but also new vulnerabilities are introduced over time that attackers can exploit.
What’s more, attackers are also evolving and constantly developing new techniques. It’s up to you to monitor and adapt to these trends!
Your detection and response processes must never stop evolving even when the context changes. Inevitably, there will be mistakes to avoid and false positives being triggered all the time.
These can be difficult to manage if the SOC doesn’t adapt.
In fact, continuous improvement is one of your main tasks. It’s by being proactive in improving the SOC that you’ll avoid becoming discouraged.
Reduce the Number of False Positives
The first problem to address is the number of false positives.
False positives can zap the SOC’s energy, with literally no benefit. Therefore, they are the first to be blamed for alert fatigue.
They need to be detected and processed.
Detect and process, aren't these the goals of the SOC?
Yes, exactly. This is why improving detection must be a continuous process in the incident response cycle!
In the previous section, we explained that there were three possible classification outcomes:
The alert is a false positive.
The alert must be investigated.
The alert has already been investigated.
In fact, we can add another option for when the investigation that is launched responds either to an incident or to a need to improve detection.
At this point, the alert follows a similar response pattern to that of an incident:
An investigation is created in the SOAR.
The causes of this detection failure are investigated.
An action plan is defined in the SIRP or SOAR.
If necessary, SIRP is used to communicate with the relevant teams.
We take action to remedy this detection failure.
We then close the tickets and the investigation, and we debrief.
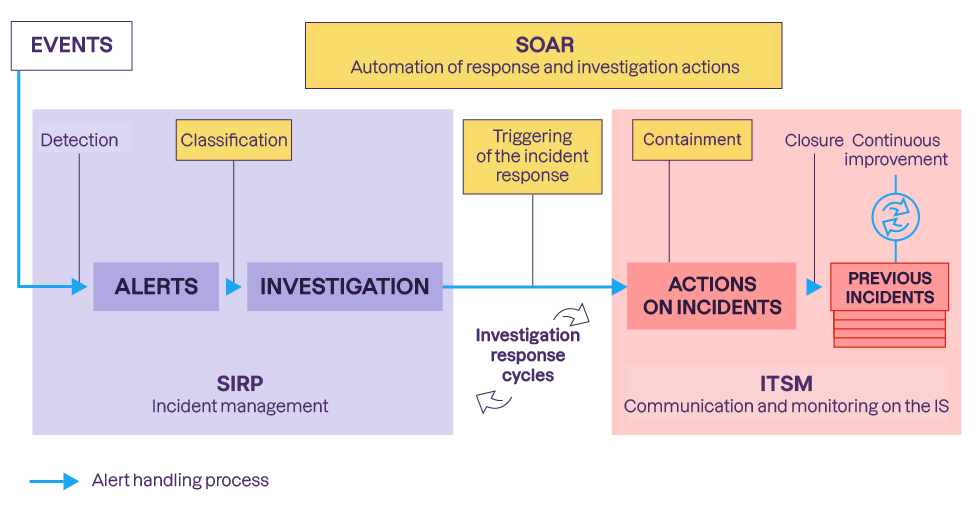
In practice, actions to improve detection must be assigned to a manager, while also being monitored and communicated to the relevant business teams. The difference with an incident is that this process is not constrained by emergency requirements, and there is no containment step.
This allows you to eliminate false positives and monitor the improvement process.
Document Your Operating Procedures
In addition to detection, you can also improve incident response.
When you’re faced with a critical incident that urgently needs to be contained, don’t waste time on asking yourself too many questions. Especially if the answers already exist in the SOC!
For this, you can prepare cheat sheets to help you respond to different situations. For example:
Phishing emails: We receive phishing emails all the time. No one has time to run through all the questions with every single email! Establishing a clear procedure will save you time (if it’s not automated!). You need to delete the email, check if other employees have received similar emails, identify who the recipients are, possibly force them to change their password, or investigate their machines if the phishing email contained malicious attachments. Last but not least, you need to record all the actions taken.
Compromised machine: If a workstation is compromised, either you deal with it or the attacker deals with it in their own way. So once again, there’s no time to spend thinking about what to do. You need to disconnect the machine and possibly investigate it or retrieve the data, while also recording all the actions you take.
Compromised application server or database: If the machine is compromised, it must be quarantined. But some servers may have a specific procedure to follow, depending on the criticality of their function or data. Preparing for these events and having a clear procedure will allow you to know immediately which assets need to be treated differently.
Ransomware attack: When dealing with confirmed ransomware propagation, every second counts! At a minimum, you must have an emergency button to immediately disconnect what has been compromised. You don’t have time to go searching for the button!
That’s why it’s so important to prepare in advance and provide these cheat sheets ahead of time.
Automate Your Processes as Much as Possible
You can even go a step further to save time during investigations by automating any repetitive steps in your procedures.
For example, the procedure for phishing emails always involves the same actions. This is something that can be automated with custom scripts!
Here is where the SOAR comes in. As a reminder, this stands for Security Orchestration, Automation, and Response, so there’s definitely an automation component! The advantage of centralizing automation in the SOAR, which is the SOC’s central work platform, is that you automate as many processing tasks as possible.
The most common SOAR tools include TheHive, Cortex, Splunk, and Shuffle.
You can also use orchestration and automation tools which aren’t reserved for just security, such as N8N, Tines, or Node-RED.
For example, you can automate:
the incident’s creation in SIRP as soon as the investigation’s status changes to “confirmed incident.” This allows you to automatically assign investigations.
the automatic enrichment of alerts. For example, you can automatically add the country of the identified IP addresses to the alert or investigation.
the quarantining of a machine, which you can trigger as soon as the investigation confirms that the machine has been compromised.
the blocking of a subnet, which you can trigger if a large-scale attack (e.g., ransomware) is in progress.
It’s best to define automation modules, sometimes called “playbooks” or “responders.”They can either be called manually, or you can define a trigger, such as “Create an investigation” or “Change the investigation to incident mode.”
This will save you valuable time in frequently occurring situations and even emergencies!
Be Ready to Use Appropriate Tools
To save time in these emergency situations, you also need to be prepared to face them. That means having the right tools, ready to be used!
In the feedback from the post-incident review, you may have identified that some tools were missing that would allow you to automate certain investigations, automate response actions, search for relevant information, or communicate with the right people.
In the previous sections, the most important tool for responding to crisis situations is the EDR. It acts as your “control tower” and allows you to investigate and quickly respond on a large number of machines.
If your organization is already equipped with an EDR, be prepared to rapidly deploy it on a new security perimeter in response to an emergency situation. If that’s not possible, there are other appropriate tools that can be used for EDR, such as Velociraptor, Google Rapid Response (GRR), or DFIR ORC (created by ANSSI).
Let’s Recap!
The ultimate goal of the SOC is continuous improvement.
A SOC that does not implement a continuous improvement process risks becoming discouraged when faced with endless alerts, adaptable attackers, and an evolving IS. This is known as “alert fatigue.”
The first area for improvement is to reduce the number of false positives. This is one of the most common problems for the SOC, as these false positives unnecessarily consume resources and lead to exhaustion within teams!
Maximize the use of your SOAR (Security Orchestration, Automation, and Response) to centralize incident response automation. It allows you to automate the repetitive classification and investigation steps, while saving time on technical actions when in an emergency situation.
EDRs provide you with essential incident management capabilities. Be prepared to deploy an appropriate EDR tool, such as Velociraptor, GRR, or DFIR ORC, on machines that don’t have one installed.
To improve your capabilities, you also need to focus your efforts on the most likely threats. We’ll be looking into this in the next chapter!
