Comprenez le fonctionnement de l’IA générative
1. Découvrez les notions préliminaires
Avant d’entrer dans le détail du fonctionnement de l’IA générative, posons quelques concepts fondamentaux qui aideront à comprendre les mécanismes derrière ces modèles puissants.
Réseaux de neurones
Les systèmes d’IA modernes s’appuient sur des modèles complexes, appelés réseaux de neurones, capables d’apprendre automatiquement des motifs à partir de grandes quantités de données. Un réseau de neurones est un modèle d’intelligence artificielle inspiré du cerveau humain : il est constitué de neurones qui traitent l’information et la transmettent à travers le réseau. Comme notre cerveau !
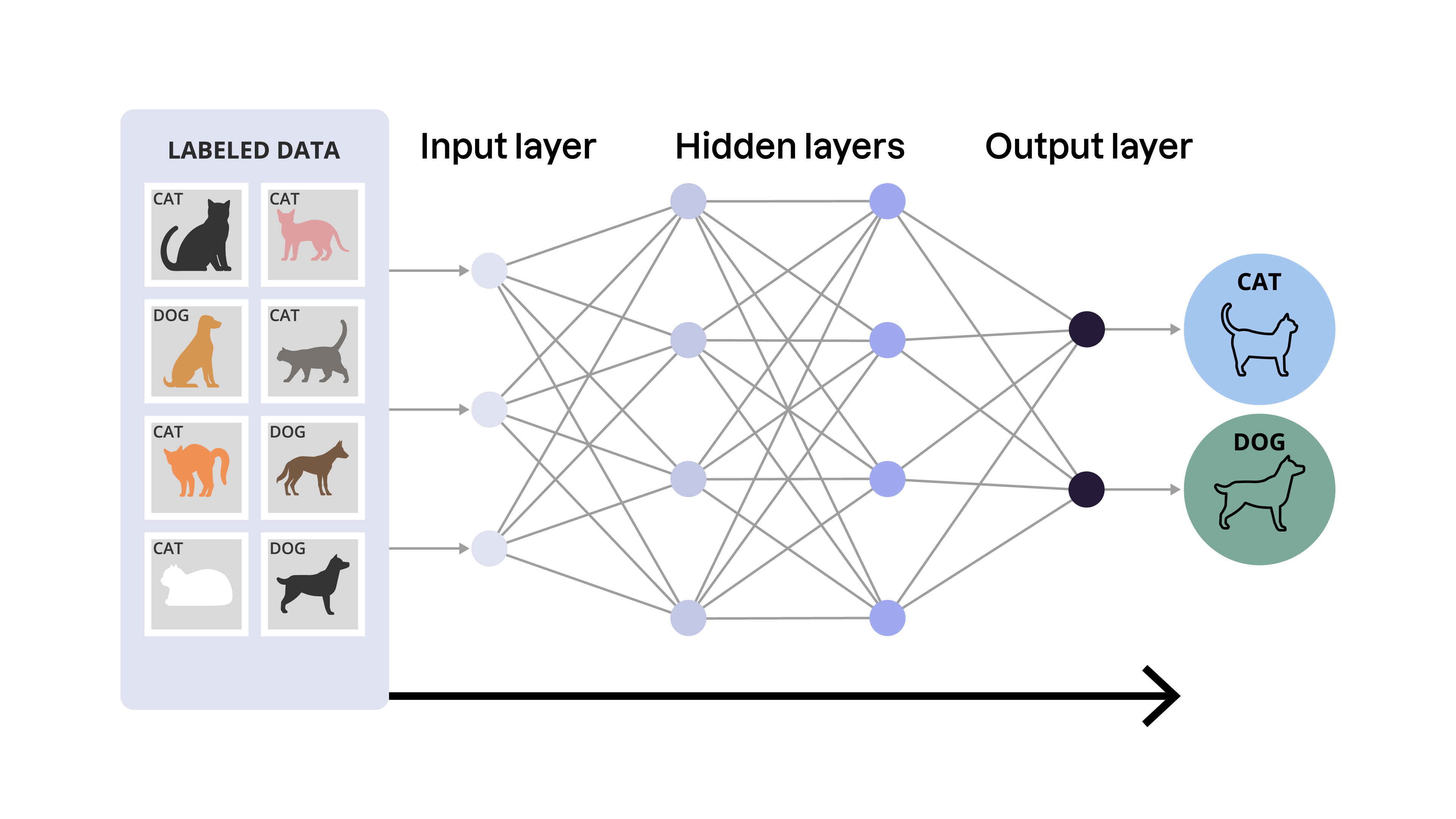
Les neurones sont organisés en trois couches principales :
couche d’entrée : reçoit les données brutes, par exemple un texte ou une image ;
couches cachées : traitent les données et en extraient des motifs ;
couche de sortie : produit le résultat final, par exemple une phrase ou une image nouvellement générée.
Chaque neurone applique une fonction mathématique, appelée fonction d’activation, aux informations qu’il reçoit, puis transmet le résultat à la couche suivante.
Deep Learning
Pour des problèmes difficiles (comme la compréhension du langage naturel), un réseau simple ne suffit pas. On a besoin d’un réseau profond (Deep Learning), composé de multiples couches cachées qui permettent au modèle de reconnaître des motifs et des représentations complexes.
Rétropropagation
Nous avons maintenant un réseau de neurones profond, mais comment apprend-il à résoudre des problèmes ? Dans la section précédente, nous avons vu qu’un système d’IA a besoin d’une phase d’entraînement, où il observe de nombreux exemples de problèmes et leurs solutions correctes.
L’entraînement d’un réseau de neurones repose sur la même idée générale, grâce à une technique appelée rétropropagation. Voici comment cela fonctionne :
le modèle reçoit une entrée, la traite et produit une sortie ;
la sortie est comparée à la bonne réponse, ce qui permet de mesurer l’erreur ;
le modèle ajuste ses paramètres pour réduire cette erreur. Ces paramètres, appelés poids, déterminent la force des connexions entre neurones ;
ce processus est répété jusqu’à atteindre un bon niveau de performance.
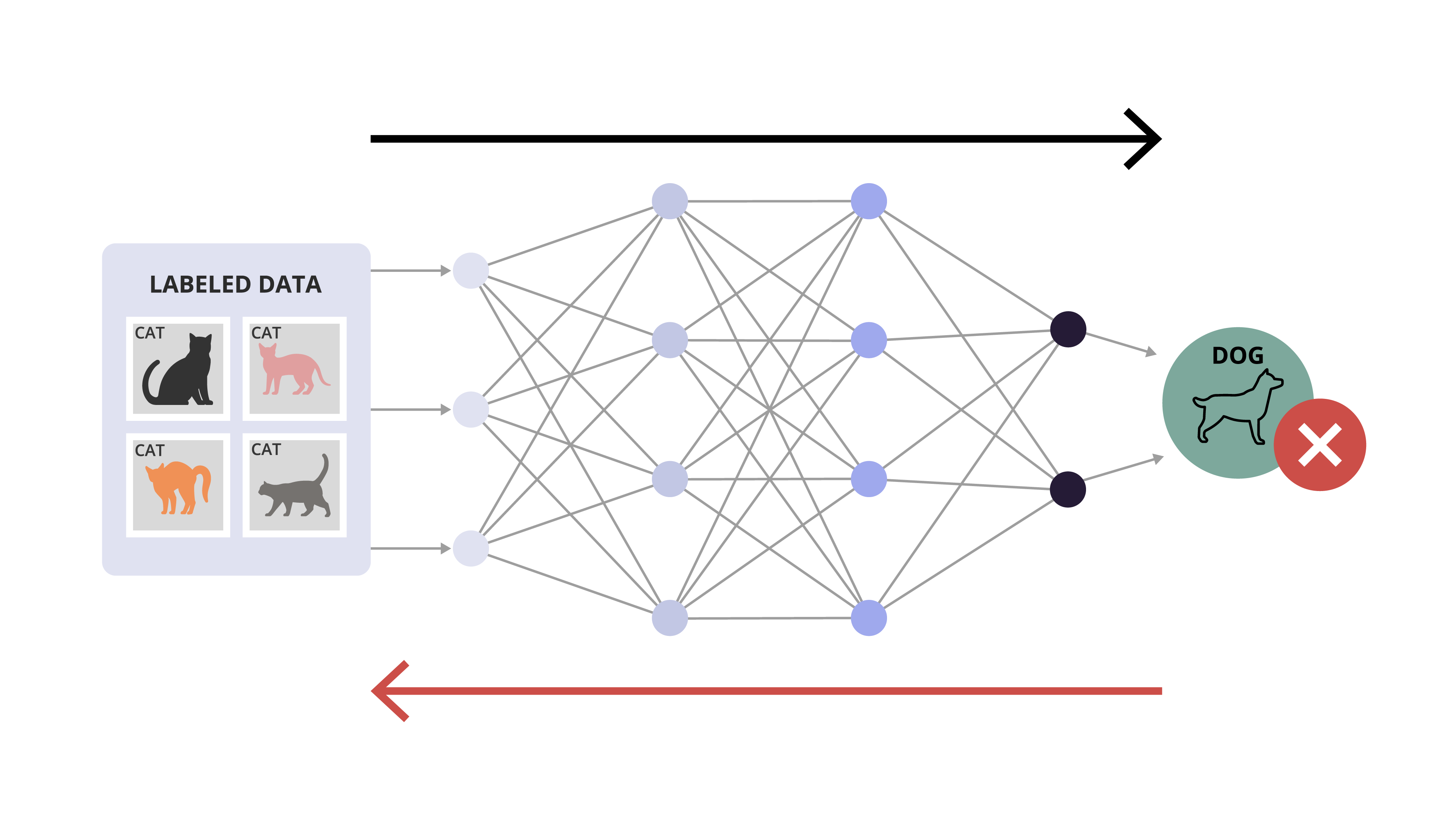
La rétropropagation permet à un réseau de s’améliorer en continu, en apprenant de ses erreurs passées et en affinant ses sorties en conséquence.
Maintenant que nous comprenons comment les modèles d’IA sont structurés et apprennent, voyons comment ils traitent et encodent les données en commençant par le texte, fondation des modèles d’IA générative modernes.
2. Découvrez l'encodage des données
Qu'est-ce que c'est ?
Contrairement aux humains, l’IA ne lit pas des mots : elle travaille avec des nombres. Cette section décrit les étapes qui transforment un texte brut en une forme exploitable par un réseau de neurones : l’encodage des données.
Tokenisation
D’abord, le texte doit être découpé en unités plus petites, appelées jetons. Selon le modèle, les jetons peuvent être :
mots : « Le chien dort » → [« Le », « chien », « dort »]
sous-mots : « malheureux » → [« mal », « heureux »]
caractères : « bonjour » → [« b », « o », « n », « j », « o », « u », « r »]
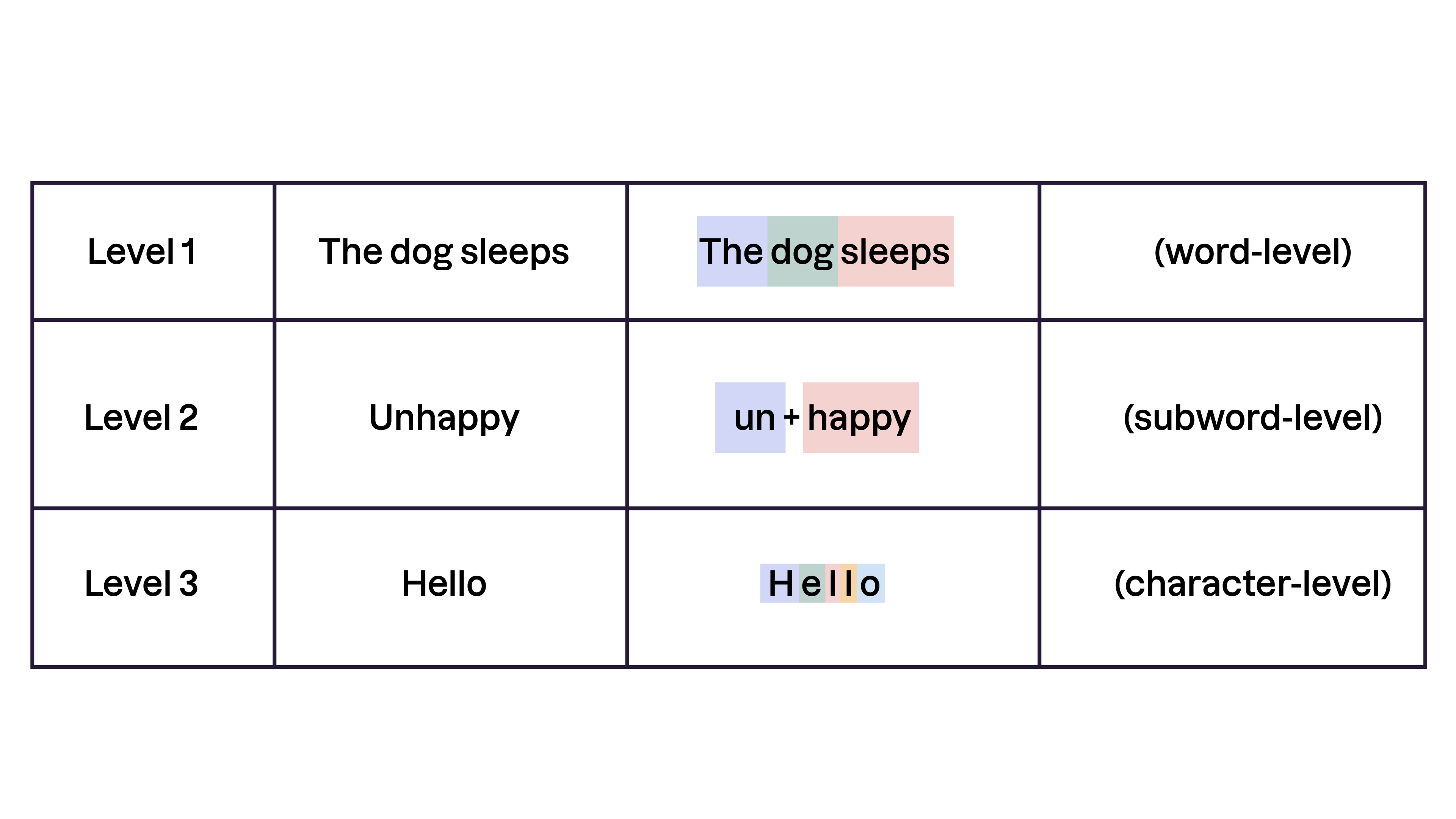
La plupart des modèles modernes utilisent la tokenisation en sous-mots car elle équilibre efficacité et flexibilité. Elle gère les mots nouveaux en les décomposant en parties plus petites et signifiantes plutôt que de les marquer comme inconnus.
Une fois le texte découpé en “tokens”, il faut les représenter numériquement pour que le modèle puisse les traiter. C’est le rôle des représentations vectorielles.
Représentations (embeddings)
L’IA ne peut pas travailler directement avec des mots — elle a besoin de nombres. Après la tokenisation, chaque jeton est associé à une représentation numérique appelée représentation vectorielle.
Une représentation vectorielle est une liste de nombres qui encode le sens d’un mot de telle sorte que des mots similaires aient des représentations proches.
Par exemple :
king → [0.2, 1.3, -0.7, 0.8]
queen → [0.3, 1.2, -0.6, 0.9]
apple → [-1.2, 0.3, 2.1, -0.8]
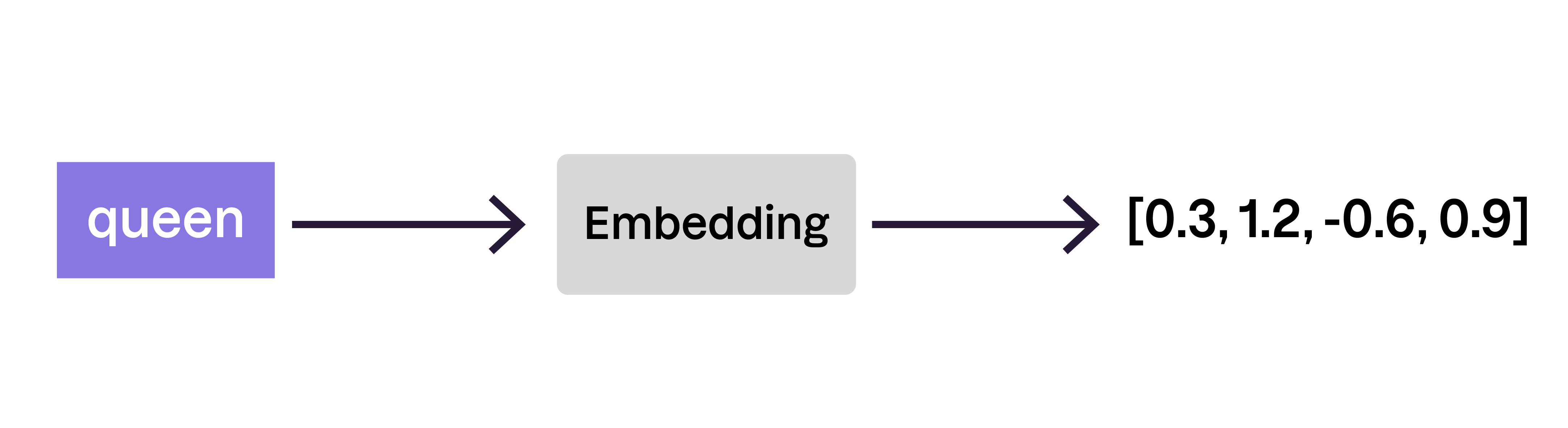
Une fois les mots représentés par des nombres, un défi subsiste : tous les mots d’une phrase n’ont pas la même importance. C’est là qu’intervient le mécanisme d’attention.
Attention
Maintenant que l’IA peut traiter le texte sous forme numérique, elle doit déterminer quels mots comptent le plus dans une phrase. L’attention permet au modèle de pondérer l’importance des mots au lieu de les traiter tous de manière identique.
Par exemple, considérons la phrase :
Le chat s’est assis sur le tapis parce qu’il était fatigué.
Pour nous, il est facile de comprendre à quoi renvoie « il » ; pour un modèle d’IA, c’est moins évident. L’attention aide le modèle à se focaliser sur « chat » comme mot le plus pertinent.
Ainsi, l’attention permet au modèle de parcourir tous les mots d’une phrase et de décider lesquels sont les plus importants pour saisir le contexte. Cette technique est la base de modèles puissants comme les transformeurs.
3. Découvrez les Transformeurs
Maintenant que nous savons comment l’IA encode le texte, examinons l’architecture puissante qui sous-tend l’IA générative moderne : les transformeurs.
À quoi servent-ils ?
Les transformeurs sont un type de réseau de neurones conçu pour traiter efficacement des séquences (comme le texte). Contrairement à d’anciens modèles qui lisaient un mot à la fois — lents et peu efficaces sur de longs textes — les transformeurs peuvent analyser des phrases entières en parallèle grâce au mécanisme d’attention.
Pour comprendre comment les transformeurs génèrent du texte, regardons leur structure fondamentale : l’architecture encodeur – décodeur.
Les transformeurs utilisent souvent une architecture encodeur – décodeur, composée de deux parties :
l’encodeur : traite l’entrée (p. ex. une phrase) et produit une représentation numérique ;
le décodeur : utilise cette représentation pour générer du contenu (par exemple, une traduction ou une réponse), en prédisant un mot après l’autre.
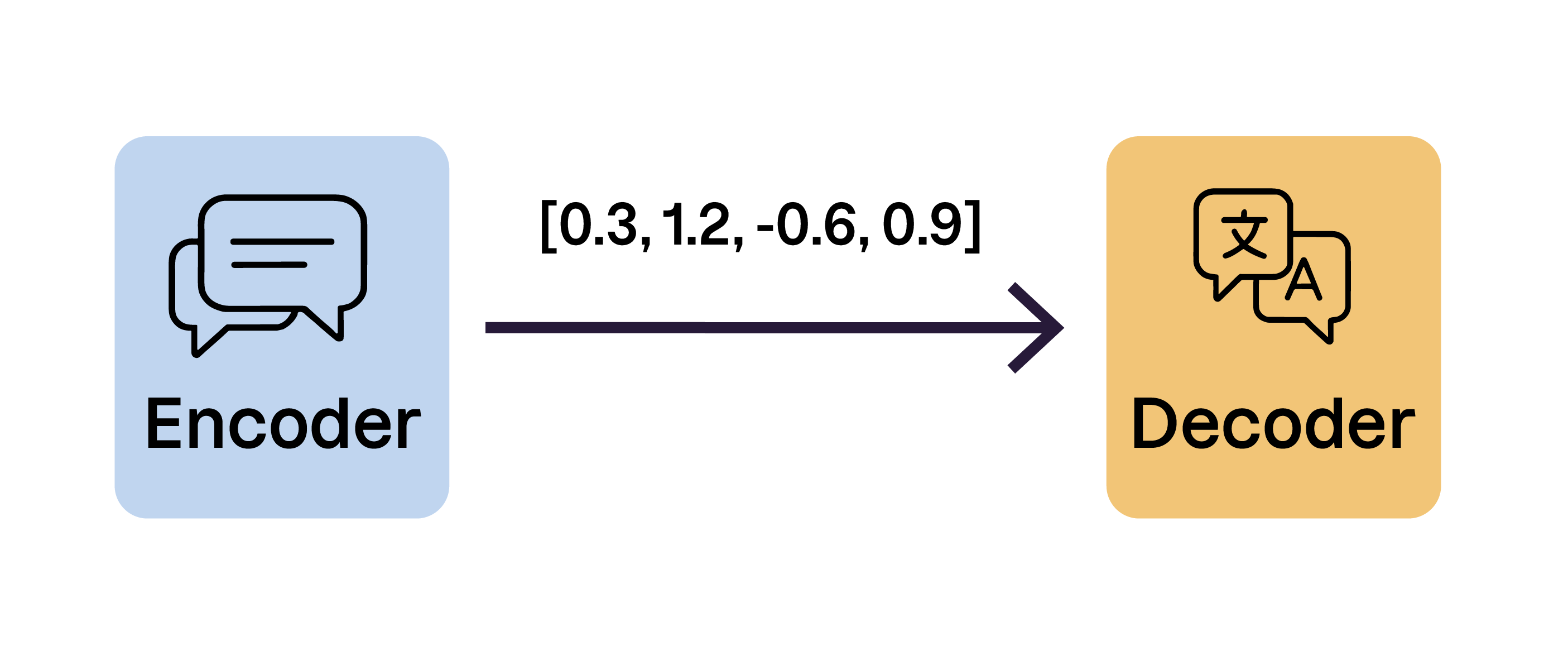
Certains transformeurs n’utilisent qu’une partie de cette architecture :
BERT (Bidirectional Encoder Representations from Transformers) : encodeur uniquement, pour des tâches comme la classification de texte ;
GPT (Generative Pre-trained Transformer) : décodeur uniquement, pour générer du texte.
Les transformeurs constituent l’épine dorsale des modèles d’IA modernes. Mais les entraîner depuis zéro coûte cher. À la place, les chercheurs utilisent des modèles de fondation de grands transformeurs pré-entraînés qui peuvent être adaptés à différentes tâches.
Modèles de fondation
Qu'est-ce que c'est ?
Un modèle de fondation est un grand modèle d’IA basé sur des transformeurs, pré-entraîné sur d’immenses volumes de données. Ce pré-entraînement lui permet d’apprendre et de généraliser la structure et la composition du langage naturel afin de les reproduire efficacement.
Ces modèles de fondation peuvent ensuite être adaptés à diverses tâches (répondre à des questions, résumer un texte, générer un dialogue). Ce processus s’appelle l’affinage (ou fine-tuning). Imaginez un modèle de fondation comme une personne très instruite en culture générale ; l’affinage revient à lui donner une formation spécialisée pour devenir juriste, médecin ou développeur.
À vous de jouer

Contexte
Nadia vous demande une note claire et actionnable pour le comité de direction d’Atelier Novalis qui n’est “pas technique”.
Consigne
Rédigez et testez, dans ChatGPT, un prompt qui génère une note pédagogique (200 – 250 mots) expliquant Tokenisation/Embeddings, Attention et Transformer, avec un mini-exemple en français.
En résumé
Les réseaux de neurones profonds permettent aux systèmes d’IA d’apprendre automatiquement des motifs complexes à partir de données massives en ajustant leurs paramètres grâce à la rétropropagation.
Le texte est transformé en unités appelées tokens, puis représenté numériquement par des embeddings qui capturent le sens et les relations entre les mots.
Le mécanisme d’attention permet au modèle d’identifier les mots les plus pertinents d’une phrase afin de mieux comprendre le contexte.
Les transformers, fondés sur une architecture encodeur-décodeur, traitent les séquences entières en parallèle et servent de base aux modèles modernes comme BERT et GPT.
Les modèles de fondation, pré-entraînés sur de vastes corpus, sont ensuite affinés pour accomplir des tâches spécialisées telles que la traduction, le résumé ou la conversation.
Maintenant que vous en savez plus sur le fonctionnement de l'IA générative, voyons dans le prochain chapitre les différents outils à disposition pour produire du texte, de l'audio et de la vidéo.
