Administrez Nagios via son interface
À ce stade, vous possédez les premières bases de la configuration Nagios. Vous avez même ajouté un équipement et un service à superviser. Il est temps de se pencher un peu plus dans le détail sur l’interface d’administration Nagios. Dans ce chapitre, je vous présente les différentes fonctionnalités de base de l’interface, avec les vues détaillées des équipements et des services supervisés. J’aborderai aussi les actions que peut effectuer l’administrateur via cette interface. Enfin, vous verrez les onglets plus orientés « système » mis à disposition par Nagios sur les pages de ce site.
L’interface d’administration de Nagios est pratique, mais elle reste le point faible de la solution Nagios Core. « Même s’il y a des technologies récentes telles Bootstrap et AngularJS, développer cette interface n’est pas la priorité des équipes Nagios. Nagios XI, version payante sous licence, comble parfaitement ce manque : la beauté de son interface est impressionnante, mais le prix du logiciel l’est aussi !
Vous pourrez trouver des informations sur l’interface de Nagios XI en suivant ce lien.
Voici un exemple :
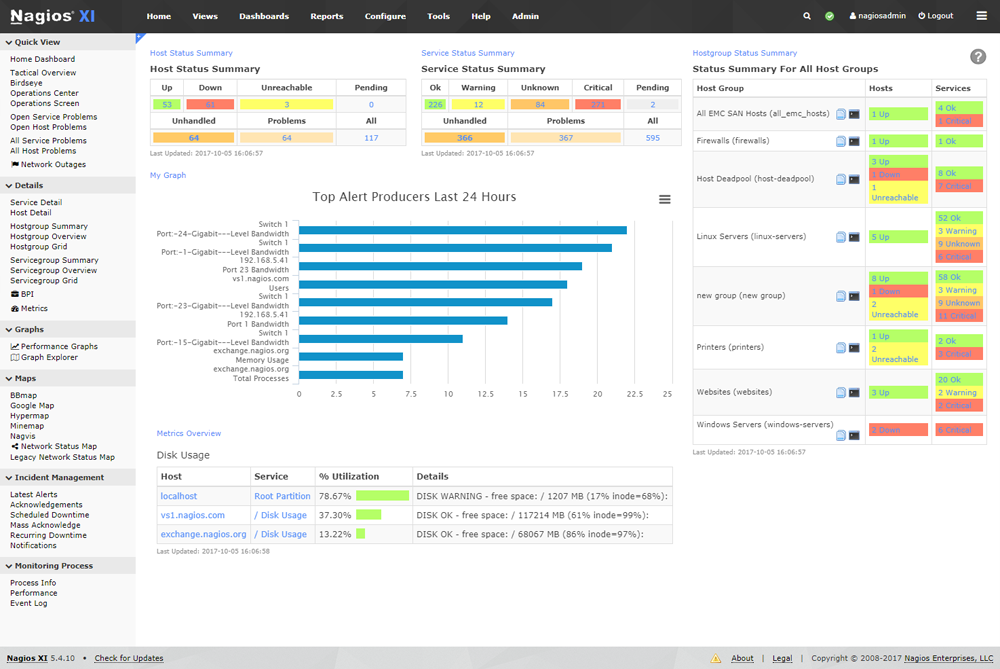
Faites le tour du propriétaire
Lorsque vous accédez à l’interface d’administration, la page d’accueil vous présente les menus de navigation sur la gauche, et le contenu principal de la page sur la droite :

Menu « General »
Le menu « General » contient deux sous-menus :
« Home », qui vous ramène à la page d’accueil, et
« Documentation », qui vous amène sur la page officielle de la documentation Nagios Core.
Menu « Current Status »
Ce menu se concentre sur les données de supervision des équipements et des services. Le sous-menu « Tactical Overview » offre une vue globale des objets supervisés, et vous donne accès à quelques options de configuration.
Le sous-menu « Map » vous permet d’obtenir une vue en fonction de la topologie définie dans les objets Nagios. Attention : elle ne reflète pas votre topologie réelle, sauf si vous la configurez intégralement dans Nagios.
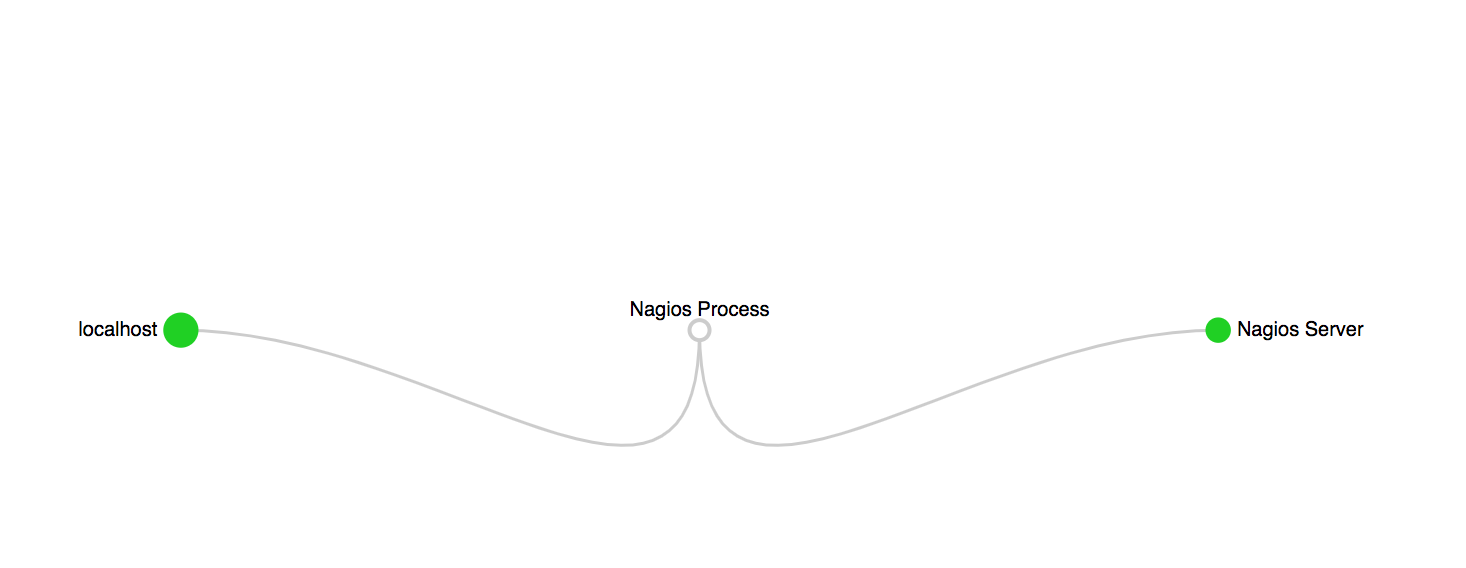
Par défaut, les objets supervisés seront rattachés directement à votre serveur Nagios. C’est notamment le cas de votre host Nagios Server, qui se trouve au même niveau que le hostlocalhost (qui est le même !). La topologie Nagios peut être configurée avec la directiveparents, au niveau des objets hosts. Il est possible d’indiquer plusieurs hosts dans cette directive, et souvent ce sont des équipements d’interconnexion comme des switchs, des routers, des firewalls, etc.
C’est une directive très importante car, si Nagios détecte qu’un de ces équipements ne répond plus, il va passer tous les hosts et les services dont il est le parent en statut « UNREACHABLE » ou « UNKNOWN », statuts qui ne déclenchent pas de notification.
Le schéma suivant est disponible sur la documentation de Nagios.
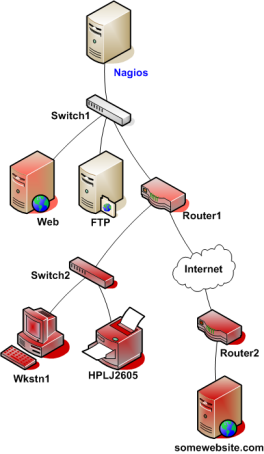
On observe que le Router1 est déclaré « parent » du Switch2 et du Router2. Lorsque le Router1 n’est plus joignable (le plugin « check_ping » renvoie CRITICAL par exemple), Nagios va passer en UNREACHABLE le statut de Switch2, de Router2, mais également de tous les équipements qui en dépendent (c’est-à-dire ici : Workstation1, HPLJ2605, et somesiteweb.com). Seuls les contacts associés à Router1 recevront une alerte
Pour la pratique, vous allez définir le host localhost en tant que parent du host Nagios Server. Pour cela, modifiez le fichier /usr/local/nagios/opencr_conf/nagios-server.cfg et ajoutez la directive « parents » dans l’objet host Nagios Server :
define host {
host_name Nagios Server
address localhost
check_command check-ping-localhost
max_check_attempts 3
parents localhost
}Vérifiez la configuration et relancez le service avec les commandes suivantes :
testNagios
restartNagiosCliquez sur le sous-menu « Map » pour vérifier que cette topologie a bien été prise en compte :
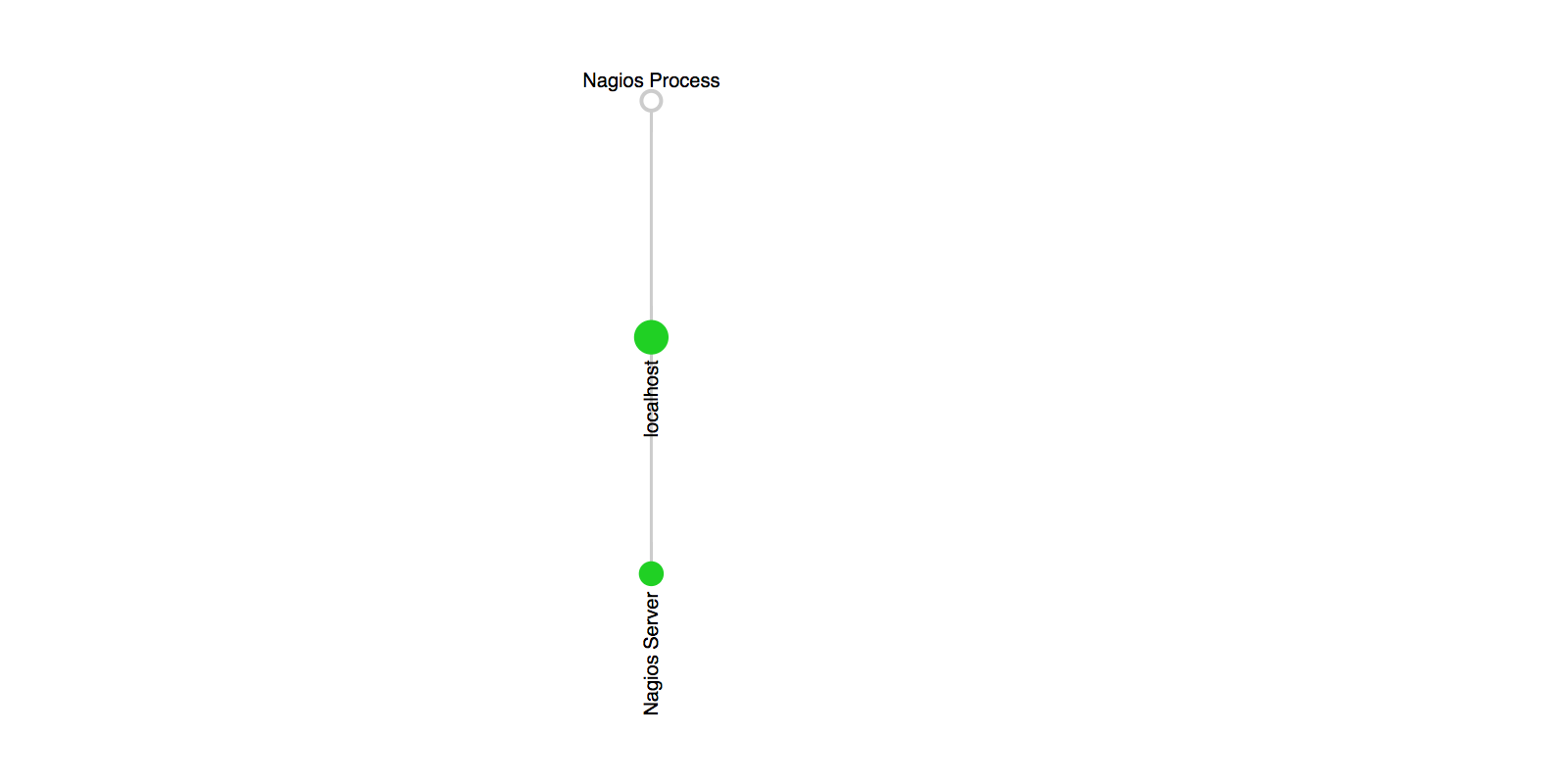
Vous pouvez constater que localhost est maintenant le parent de Nagios Server.
Le menu « Hosts »
Le menu « Hosts » vous propose une vue d’ensemble des objets host supervisés par votre serveur Nagios.
Les colonnes présentées affichent les informations suivantes :
Host : le nom de l’objet, tel qu’il a été défini dans le fichier de configuration ;
Status : l’état courant du host ;
Last Check : la date de dernière exécution de la commande définie par la directive
check_commanddu host ;Duration : le temps cumulé de supervision du host, et
Status Information : les informations renvoyées par le plugin lors de sa dernière exécution.
En cliquant sur le lien affiché sous le nom du host, vous obtenez un affichage détaillé de l’objet :
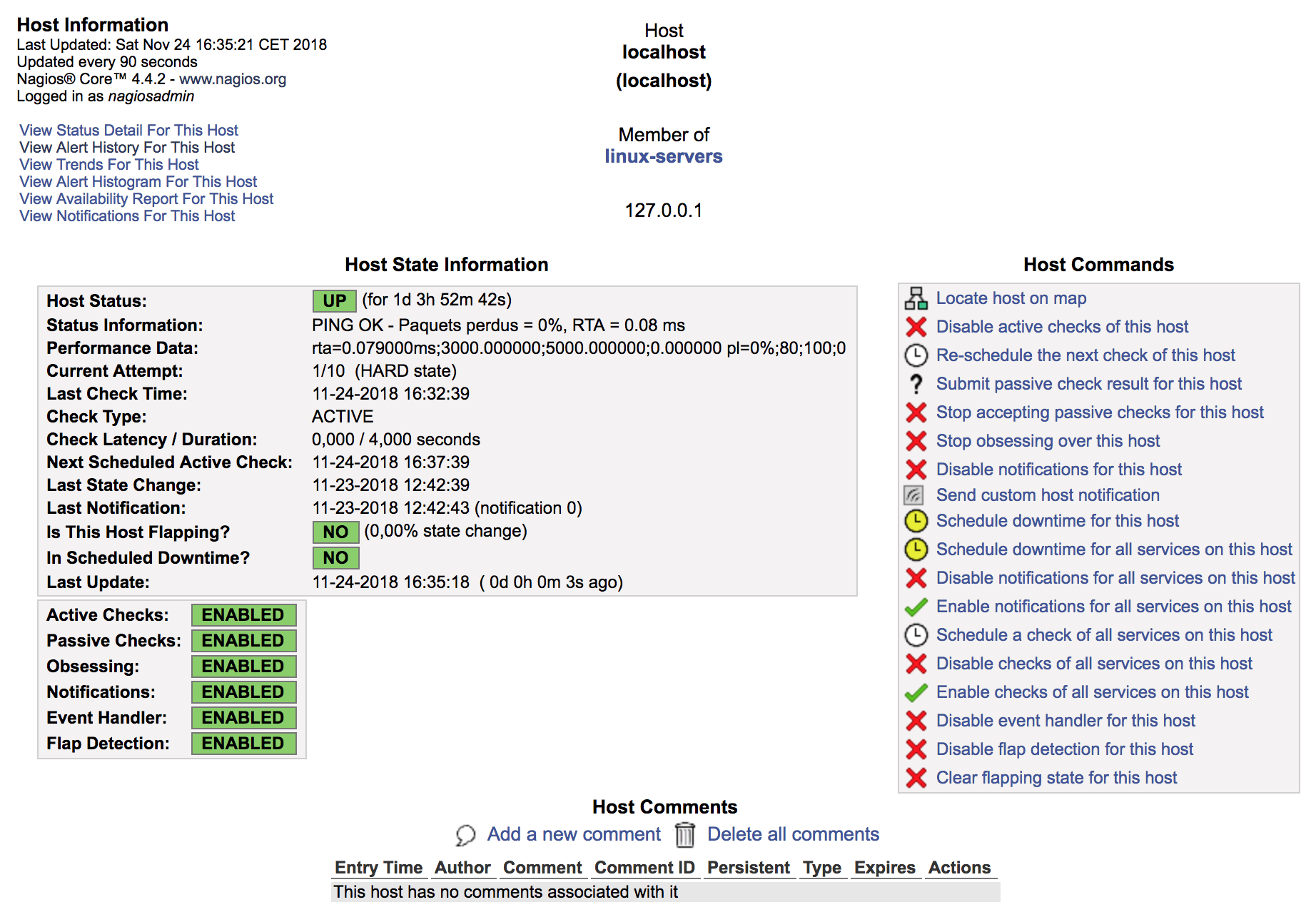
Le pavé « Host State Information » reprend les données de l’écran précédent et y ajoute quelques informations, dont :
Performance Data : ces données sont renvoyées de manière normalisée par le plugin et peuvent être interprétées par des moteurs de rendu graphique ;
Next Scheduled Active Check : indique le moment où l’objet sera à nouveau supervisé via sa commande
check_commandet le plugin associé, etLast State Change : indique le moment où l’objet a changé de statut pour la dernière fois.
Le pavé « Hosts Commands » permet d’interagir avec l’objet directement depuis l’interface d’administration via des commandes externes (comme nous l’avons vu dans le chapitre 3, avec le pipe FIFO de Nagios).
Un peu de pratique : vous allez maintenant demander à Nagios de ne pas attendre le prochain check de cet objet, mais de l’effectuer immédiatement. Pour cela, cliquez sur « Re-schedule the next check of this host » :
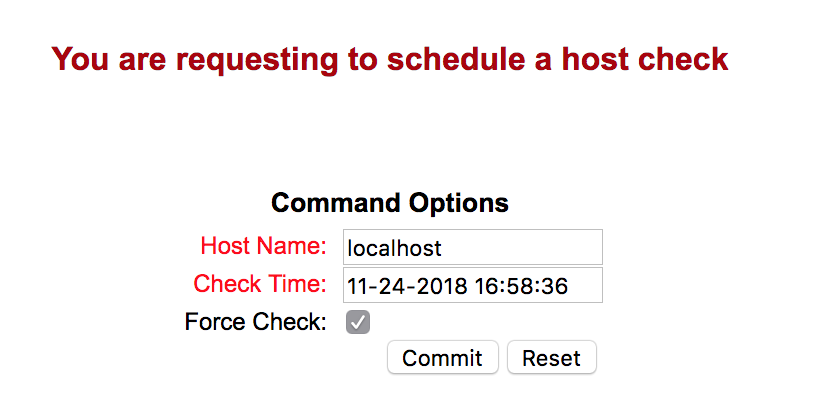
Vous pouvez décider du moment du prochain check. Par défaut, il vous sera proposé de faire un prochain check immédiatement. Il vous suffit simplement de cliquer sur le bouton commit pour exécuter le check. Si tout s’est bien passé, vous devez obtenir un message de confirmation.
En cliquant sur le lien « Done », vous revenez à la vue détaillée de la supervision de ce host. Et vous pouvez constater l’exécution de votre commande externe en observant la nouvelle valeur du champ Last Check Time.
Pour continuer avec ces histoires de commandes externes, répétez exactement la même opération depuis l’interface, mais en ajoutant une commande dans le terminal afin d’écouter sur le fichier de traces de Nagios en temps réel.
Dans un premier temps, exécutez la commande suivante :
nagios@NagiosDebian:~$ tail -f /usr/local/nagios/var/nagios.log Puis, depuis le pavé de commandes de l’interface d’administration, relancez un check immédiat sur le host localhost. Vous devriez voir apparaître la ligne suivante :
[1543075682] EXTERNAL COMMAND: SCHEDULE_FORCED_HOST_CHECK;localhost;1543075681
Que vous dit cette ligne ? Vous pouvez observer, dans le premier champ entre crochets, le nombre de secondes écoulées depuis le 1er janvier 1970 à minuit : c’est le fameux timestamp des informaticiens. Au timestamp indiqué, Nagios a exécuté une commande externe nomméeschedule_force_host_check , en prenant pour paramètre le host localhost et un nouveau timestamp indiquant le moment souhaité du check.
À croire que cliquer sur le lien depuis le navigateur a envoyé cette commande à Nagios (et c’est effectivement ce qui s’est passé !).Comment votre navigateur a-t-il envoyé cette commande à Nagios ? Vous l’aurez compris : en passant par le pipe FIFO de Nagios (d’où l’intérêt d’ajouter le compte www-data dans le groupe nagcmd lors de l’installation de Nagios).
En résumé, le clic sur « Re-schedule the next check of this host » correspond à l’écriture, dans le pipe FIFO, de la commande :[TIMESTAMP] SCHEDULE_FORCED_HOST_CHECK;localhost;TIMESTAMP
Vous pouvez vérifier vous-même cet état en exécutant la commande suivante (sur la même ligne !) :
nagios@NagiosDebian:~$ DATE=`date +%s`;echo "[$DATE] SCHEDULE_FORCED_HOST_CHECK;"Nagios Server";$DATE" > /usr/local/nagios/var/rw/nagios.cmd Dans le fichier de traces de Nagios, vérifiez l’exécution de votre commande externe avec :
nagios@NagiosDebian:~$ tail /usr/local/nagios/var/nagios.log
[1543073348] Warning: Service 'SSH sur Nagios Server' on host 'Nagios Server' has no check time period defined!
[1543073348] Warning: Service 'SSH sur Nagios Server' on host 'Nagios Server' has no notification time period defined!
[1543073348] Warning: Host 'Nagios Server' has no default contacts or contactgroups defined!
[1543073348] Successfully launched command file worker with pid 29007
[1543075211] EXTERNAL COMMAND: SCHEDULE_FORCED_HOST_CHECK;localhost;1543075116
[1543075223] EXTERNAL COMMAND: SCHEDULE_FORCED_HOST_CHECK;localhost;1543075222
[1543075300] EXTERNAL COMMAND: SCHEDULE_FORCED_HOST_CHECK;localhost;1543075299
[1543075682] EXTERNAL COMMAND: SCHEDULE_FORCED_HOST_CHECK;localhost;1543075681
[1543076216] EXTERNAL COMMAND: SCHEDULE_FORCED_HOST_CHECK;localhost;1543076216
[1543076289] EXTERNAL COMMAND: SCHEDULE_FORCED_HOST_CHECK;Nagios Server;1543076289La dernière ligne correspond à votre commande pour le host Nagios Server !
Vous avez désormais compris comment fonctionnait l’interface entre l’interface Web d’administration de Nagios et le service Nagios. Toutes les commandes externes que vous allez rencontrer fonctionnent sur le même principe.
Le menu « Services »
Le menu « Services » vous offre une vue d’ensemble des objets services supervisés par votre serveur Nagios. Cet écran fonctionne sur le même principe que celui des hosts.
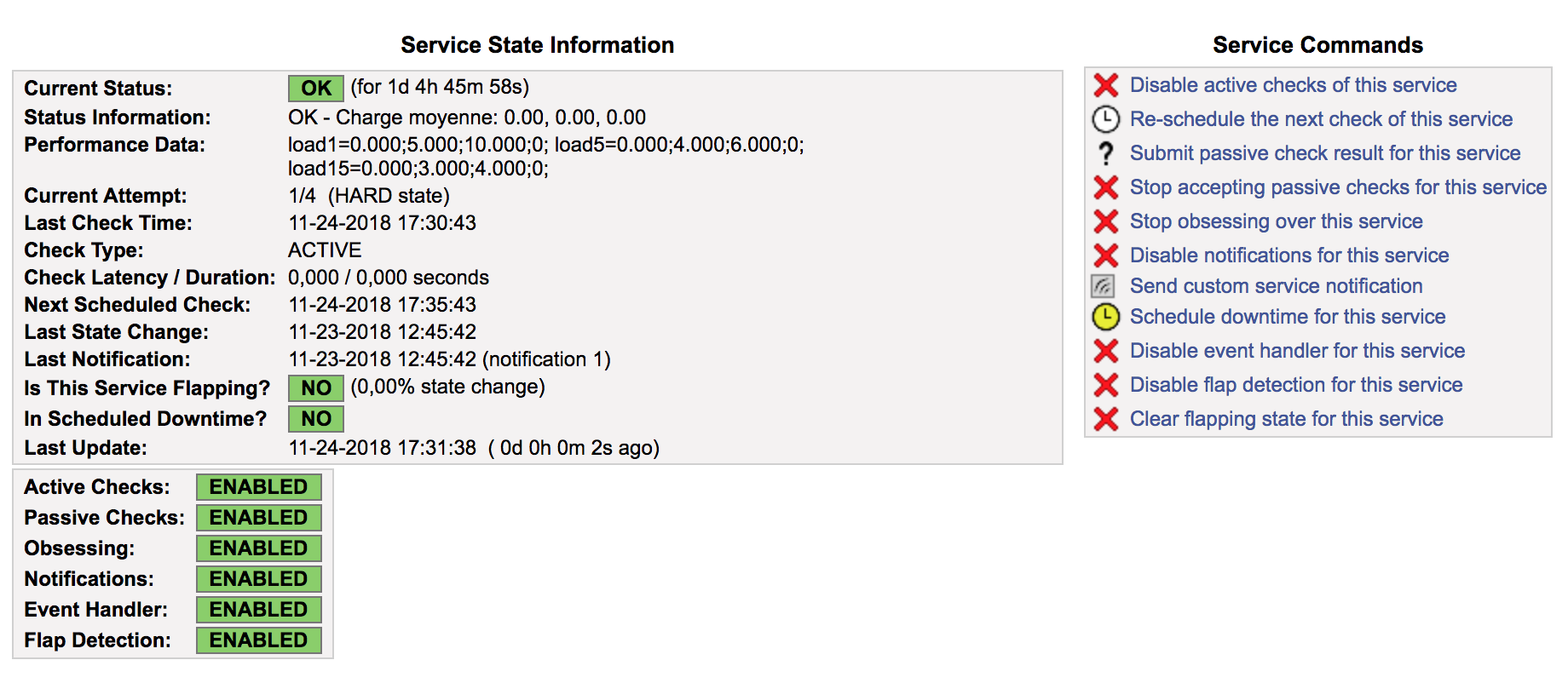
Vous aurez l’occasion de découvrir les autres sous-menus :
« Hosts Groups », qui vous permet de visualiser la supervision des objets de type host par groupe. Les groupes se définissent aussi par des objets spécifiques.
« Service Groups », qui fait la même chose pour les objets de type services.
Je reviendrai sur ces notions de groupe dans la troisième partie de ce cours, et enfin
« Problems », qui vous permet de recenser, sur le même écran, les alertes en cours relevées par Nagios.
Exploitez les outils système de l’interface d’administration
L’interface d’administration de Nagios propose également quelques fonctionnalités système à l’utilisateur.
Le menu « Reports »
Le menu « Reports » propose de construire des rapports en fonction des compteurs stockés par le moteur Nagios.
Le sous-menu « Availability » permet d’établir des rapports montrant les pourcentages de temps sur les états pour les objets de type hosts ou services :
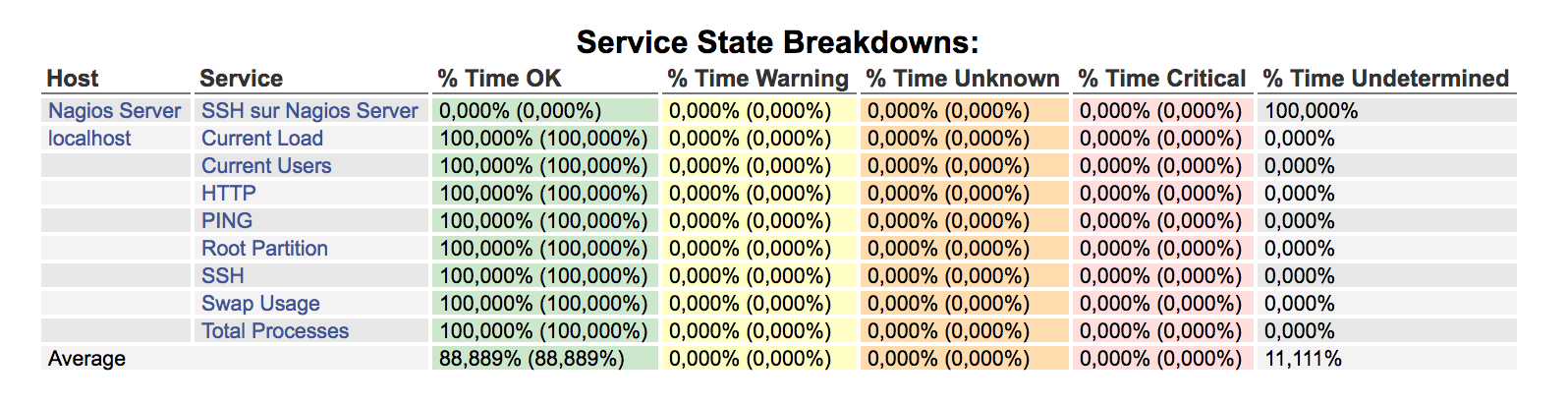
Le sous-menu « Trends » permet de construire des rapports concernant l’historique d’évolution de l’état d’un objet host ou service.
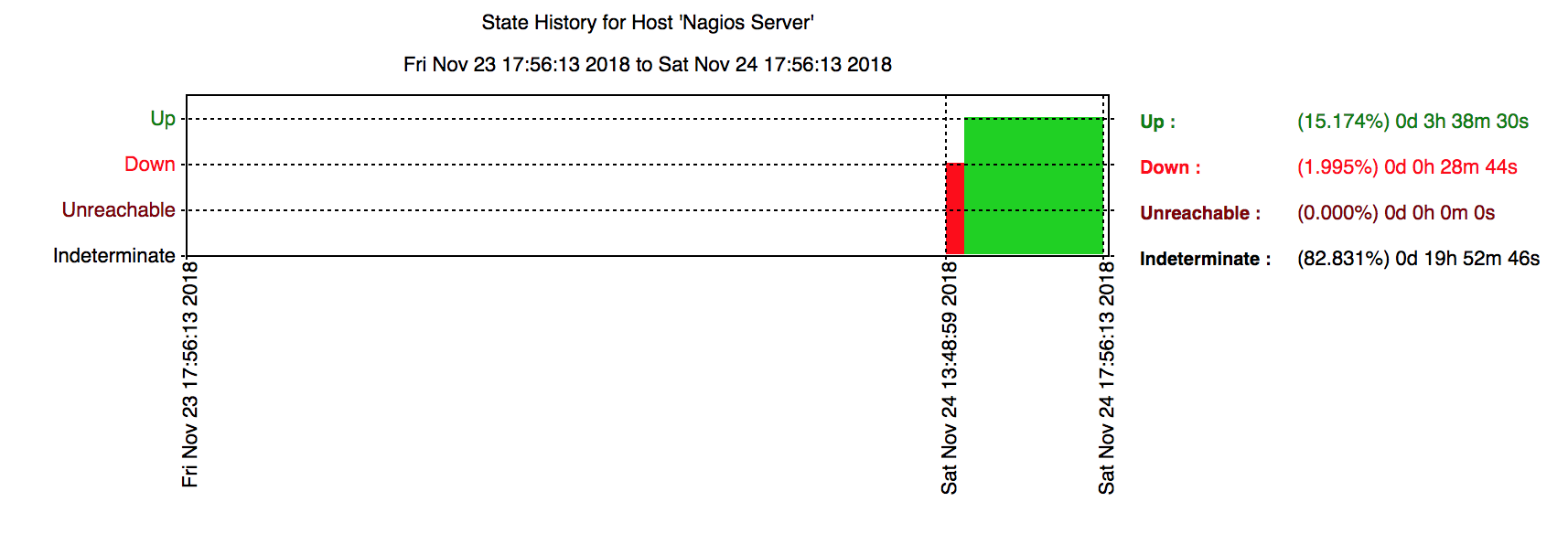
Le sous-menu « Alerts » affiche un condensé horodaté de tous les évènements survenus aux objets services et hosts supervisé.

Le sous-menu « Notifications » affiche un résumé des différentes notifications générées par Nagios.
Enfin, le sous-menu « Event Log » affiche, tout simplement, tout le contenu du fichier de traces de Nagios /usr/local/nagios/var/nagios.log :

Le menu « System »
Le menu « System » est un menu important qui fournit beaucoup d’informations sur le comportement du serveur Nagios.
Le sous-menu « Comments » recense tous les commentaires des utilisateurs de l’interface d’administration concernant les évènements survenus aux objets supervisés.
Le lien « Downtime » offre la possibilité de définir une période de temps pendant laquelle Nagios ne tiendra pas compte des résultats des plugins pour les notifications normales, seules les notifications indiquant le départ et l’arrêt de ces périodes seront envoyées.
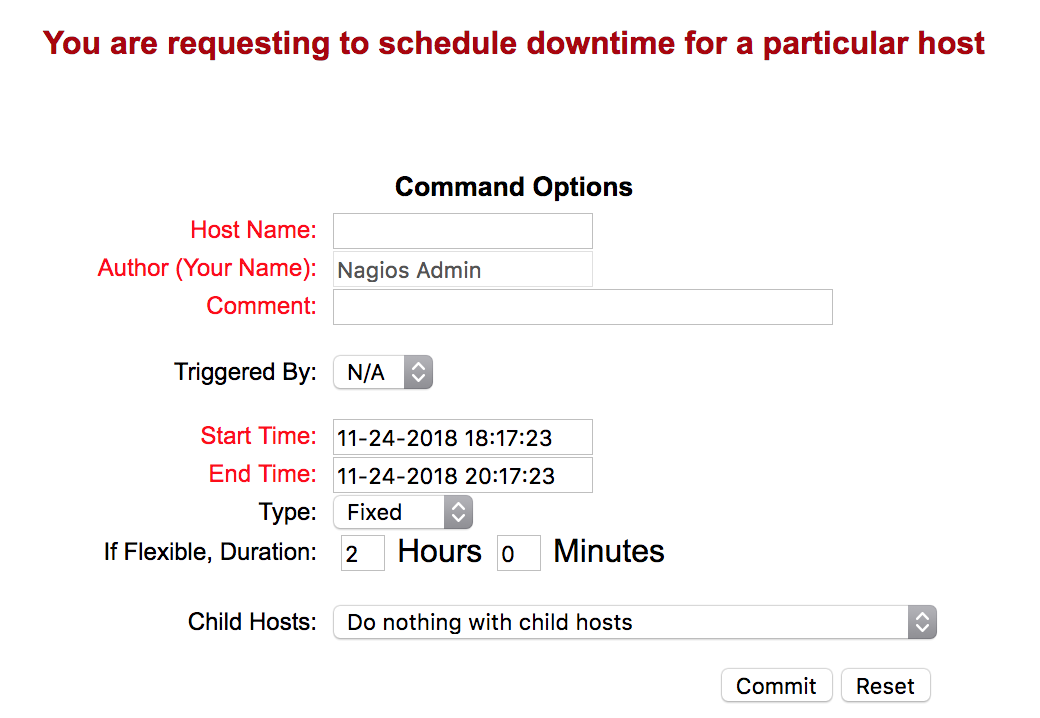
Le sous-menu « Process info » permet d’obtenir des statistiques sur le fonctionnement de Nagios :
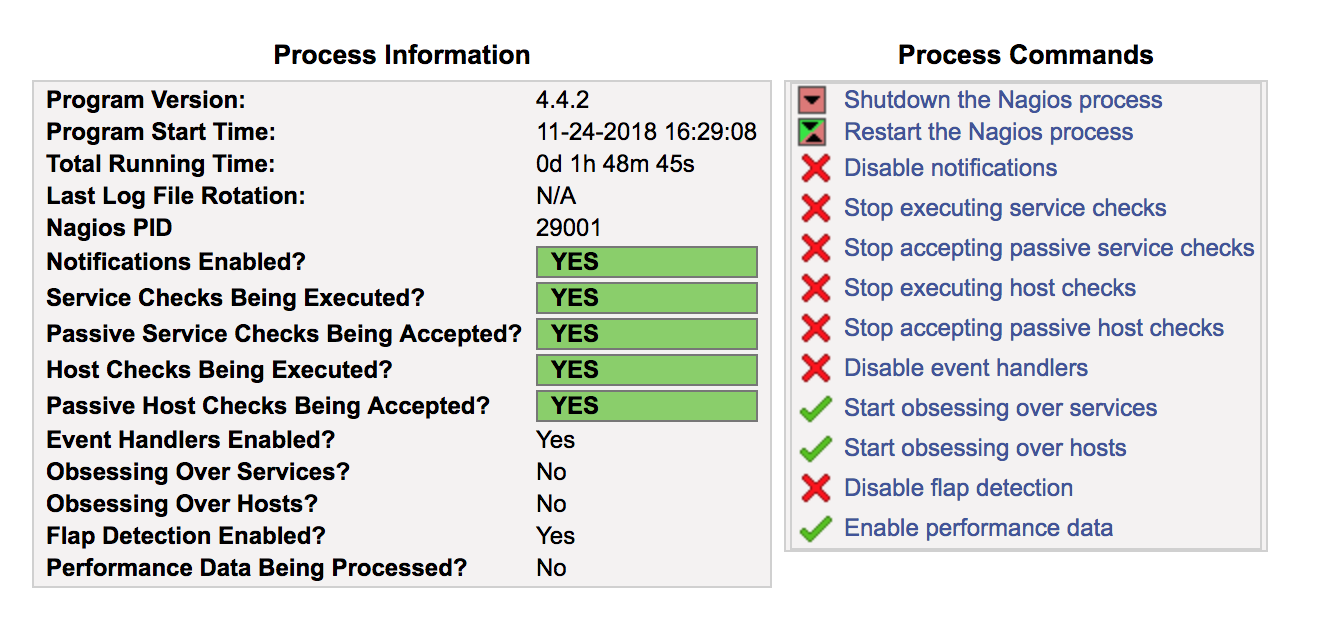
Vous constaterez que cette page contient un panel de « Process Commands », qui fonctionne exactement comme les « Host Commands » et les « Service Commands ». En d’autres termes, un clic sur ces liens se traduit par une commande externe envoyée sur le pipe FIFO de Nagios.
Notez qu’il est possible, entre autres, de :
arrêter ou redémarrer le service Nagios ;
stopper toutes les sondes pour les objets de type host ;
stopper toutes les sondes pour les objets de type services. Le sous-menu « Performance Info » affiche les informations de performance :
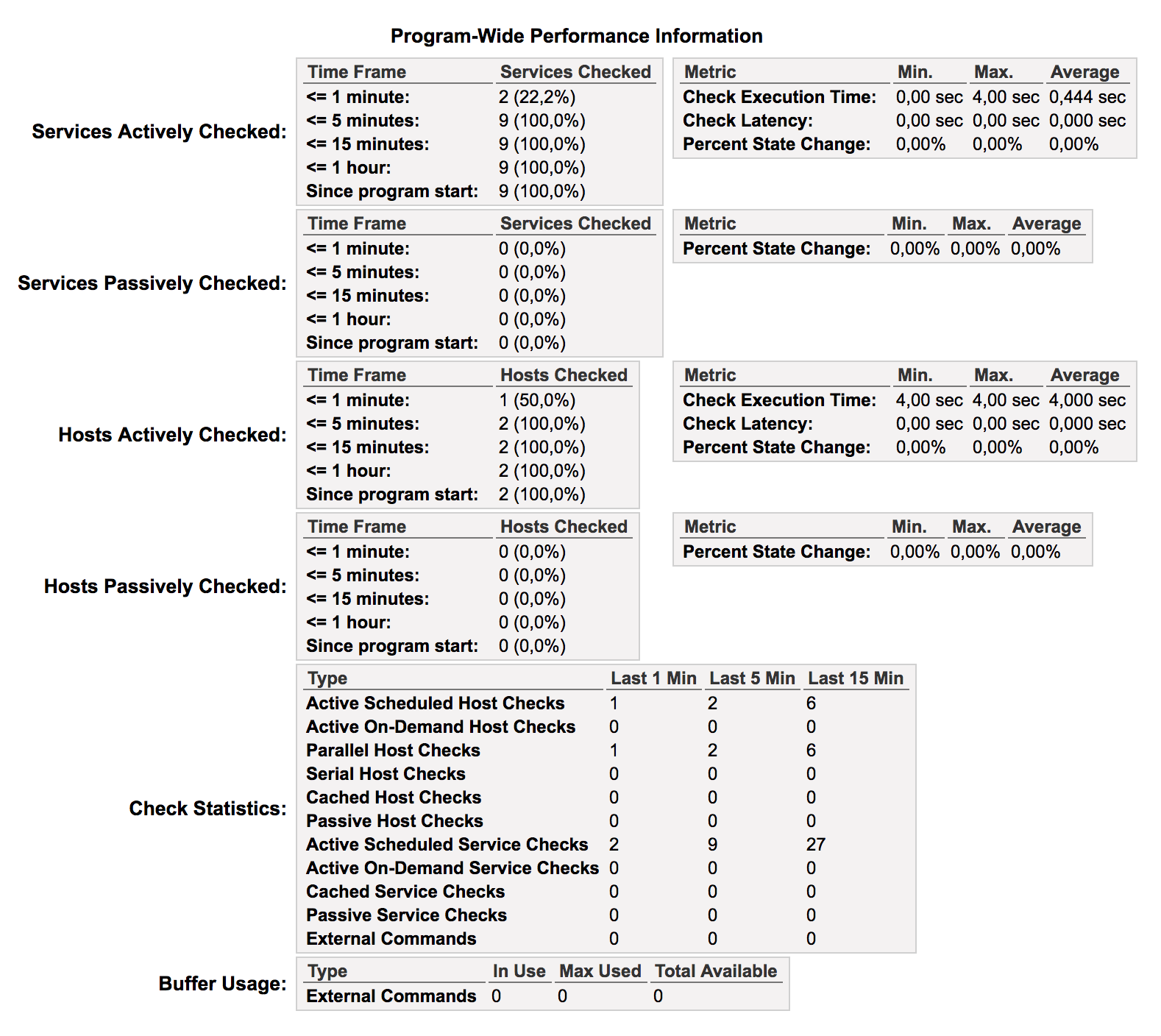
Cet écran est très important car il donne des indicateurs concernant « l’état de santé » du serveur Nagios, parmi lesquels :
le nombre de checks actifs pour les hosts par minute ;
le nombre de checks actifs pour les services par minute ;
le temps d’exécution maximum pour les checks hosts et services.
Vous pouvez constater que, sur cette page, le check d’un host prend 4 secondes ! C’est beaucoup étant donné que, pour l’instant, vous surveillez uniquement le serveur Nagios.
Comment faire pour identifier le check du host qui prend autant de temps ?
C’est simple ! Lancez la commande suivante :
nagios@NagiosDebian:~$ grep -n check_execution_time /usr/local/nagios/var/status.dat Observez le résultat de cette commande :
68: check_execution_time=4.094 123: check_execution_time=4.103 179: check_execution_time=0.007 236: check_execution_time=0.002 293: check_execution_time=0.001 350: check_execution_time=0.001 407: check_execution_time=4.095 464: check_execution_time=0.001 521: check_execution_time=0.005 578: check_execution_time=0.001 635: check_execution_time=0.008
Vous pouvez constater que trois sondes mettent plus de 4 secondes à s’exécuter. Consultez désormais ce fichier à partir du premier numéro de ligne renvoyé par la commande (ici, 68) :
56 hoststatus {
57 host_name=Nagios Server
58 modified_attributes=0
59 check_command=check-ping-localhost
60 check_period=
61 notification_period=
62 importance=0
63 check_interval=5.000000
64 retry_interval=1.000000
65 event_handler=
66 has_been_checked=1
67 should_be_scheduled=1
68 check_execution_time=4.094Vous constatez alors que la sonde de votre équipement « Nagios Server » met 4 secondes, alors qu’elle est exécutée à partir de ce même équipement !
Pour vérifier ce temps d’exécution, relancez à la main le plugin check_ping que vous avez configuré dans le fichier /usr/local/nagios/opencr_conf/nagios-server.cfg et ajoutez devant la commande time permettant de relever le temps d’exécution telle que :
nagios@NagiosDebian:~$ time /usr/local/nagios/libexec/check_ping -H localhost -w 40,40% -c 60,60%
PING OK - Paquets perdus = 0%, RTA = 0.04 ms|rta=0.041000ms;40.000000;60.000000;0.000000 pl=0%;40;60;0
real 0m4,104s
user 0m0,000s
sys 0m0,000sEffectivement, le ping du localhost prend 4 secondes !
Relancez le plugin avec son option -help pour comprendre ce phénomène et intéressez-vous notamment à l’option -p :
nagios@NagiosDebian:~$ /usr/local/nagios/libexec/check_ping -help Ci-dessous, le texte décrivant l’option -p :
-p, --packets=INTEGER nombre de paquets ICMP à envoyer (Défaut: 5)
Et voilà ! La sonde met 4 secondes car elle envoie cinq paquets ! Un check sur la même machine ne sera pas forcément probant. On pourrait descendre le nombre de paquets à 1, mais dans ce cas, les seuils concernant le pourcentage de paquets perdus ne seraient plus probants. Encore une fois, pour un check local, ce n’est pas grave.
Relancez la commande :
nagios@NagiosDebian:~$ time /usr/local/nagios/libexec/check_ping -H localhost -w 40,40% -c 60,60% -p 1
PING OK - Paquets perdus = 0%, RTA = 0.03 ms|rta=0.027000ms;40.000000;60.000000;0.000000 pl=0%;40;60;0
real 0m0,004s
user 0m0,000s
sys 0m0,000sBingo, la sonde est bien plus rapide !
Il reste un dernier sous-menu, nommé « Configuration », que je vais volontairement omettre de détailler ici. Pour comprendre son fonctionnement, rendez-vous dans la partie 3 où l’on mettra en place une sonde HTTP.
Vous aurez remarqué qu’il n’est pas possible d’ajouter un objet à superviser directement depuis l’interface d’administration de Nagios Core. C’est le grand défaut de l’interface, que la communauté a essayé de combler avec des interfaces spécifiques, qui ne sont plus vraiment maintenues à ce jour. Je pense notamment à NCONF, qui a connu sa période de succès, ou encore à Centreon, qui s’est bien implanté sur le marché français grâce à une interface de configuration complète !
Quelques outils offrent une interface complète, comme Eyes Of Network, que l’on peut trouver dans quelques institutions publiques françaises. Eyes of Network (produit sous licence GPL2), intègre des outils intéressants, comme CACTI.
Mais, comme je l’indiquais en introduction de ce chapitre, la nouvelle interface Web d’administration de Nagios XI est sa grande. À mon sens, il s’agit de l’interface de configuration la plus aboutie. Mais c’est un investissement…
En résumé
Voilà, le petit tour du propriétaire de l’interface d’administration Nagios est terminé. Vous avez compris comment fonctionne cette interface, vous avez saisi la notion de commande externe via le pipe FIFO de Nagios. Vous savez également où trouver les informations importantes sur cette interface et vérifier les performances de vos sondes.
Il est maintenant temps de quitter le champ local de Nagios et de s’intéresser à la supervision d’un host distant et à celle de ses services. Je vous attends donc dans la troisième partie de ce cours, où nous superviserons un serveur Web !
