Build Your First Word Cloud

Before getting into the technique, let’s take a moment to discuss natural language processing as a whole.
What Is Natural Language Processing?
Language is everywhere. It’s how I am communicating with you right now! There is even a whole scientific discipline called linguistics, dedicated to the study of human language, including syntax, morphology, and phonetics, whose goal is to uncover the psychological and societal working of language. Ambitious, right?
Okay...but how does this relate to computer science?
Well, in the late 1950s, classic linguistics gave birth to computational linguistics by adding statistics and computers into the mix. The goal then became to build automated processes that could understand the text.
Today, natural language processing(NLP) is a direct evolution of computational linguistics, which leverages artificial intelligence and machine learning.
To deepen your understanding, let’s look at some real-world applications of NLP in everyday life. You will recognize a few!
Discover Real-Life Use Cases of NLP
Automatic Translation
This may be the most obvious and useful application of NLP. The quality of automated translation has improved a thousand fold in the past few years. Moreover, it is no longer limited to dedicated platforms such as Google Translate but is now integrated into many applications with an impressive list of default languages.
Speech-to-Text Conversion
Have you ever used the dictation tool on your phone or spoken to Siri or Alexa? NLP helps convert spoken words into a digital representation, which computers can understand and process.
Text Classification
This type of NLP is typically referred to as text tagging, assigning a specific sentence or word to an appropriate category such as positive or negative, spam (or not). It can help with spam filtering, sentiment analysis, topic inference, and even hate speech detection!
For example, in digital marketing, a brand’s social media account may have hundreds of daily comments. These comments bring valuable insights about the company’s products but can be tedious to sift through (for a human). NLP helps identify positive or negative aspects of customers’ comments, and it does so much faster than a person ever could by manually sifting through comments!
Text Generation
Google’s Smart Compose, which helps write emails, is also a good example. But text generation goes beyond email composition. Recent models (OpenAI’s GTP-3, Nvidia’s MT-NLG, etc.) can write coherent stories across multiple paragraphs, paving the way for automated news content creation.
Information Extraction
Information extraction identifies a specific piece of information from a block of text, such as a name, a location, or a hashtag.
For example, natural language processing in human resources can help match the right candidate with the right job. Imagine that you have a bank of thousands of CVs. That’s thousands and thousands of words. The ability to extract a specific job title from all those words makes job matching a lot more efficient.
NLP is evolving at breathtaking speed. Recent large language models (LLMs) can write text indistinguishable from human prose; automatic translation has become commonplace, and conversational chatbots are increasingly efficient. This course will guide you through the foundations of creating an NLP model. Consider this the first step before going on to making the world’s next new speech detection technology. 🙂
Let’s kick things off with some hands-on practice. The goal is to give you a taste of what it’s like to build a natural language processing model. You will also learn about stopwords, which will come in handy in the coming chapters!
Visualize Text With a Word Cloud
Let’s start by creating a word cloud. You have probably seen one before, but if not, here’s a pretty one I found:

A word cloud is a snapshot of a text meant to help you explore it at a glance. It is a word image where each word's size is proportional to its importance (more frequent words appear larger). A word cloud can be particularly useful during a presentation to help engage your audience and draw attention to the main themes! 🙂
So, how do I make one?
Set Up Your Environment
This course will work with the latest Python version (3.10 at the time of writing) and the Anaconda Python distribution. Check out the Anaconda site to install a Conda-managed Python environment on your local machine.
Install the Word Cloud Library
To generate word clouds in Python, use the word cloud library. You can read more about it on this Python Package Index (PyPI) page. Install it by running:
In a terminal:
pip install wordcloudorconda install -c conda-forge wordcloudIn a Google Colab notebook:
!pip install wordcloud
Import the Text Material
For this example, we will use content from a Wikipedia page, which you can download as raw text in a few lines of code without the inherent markup. Copy-paste the code below to get started. We will reuse the wikipedia_page() function later in the course.
Since we're all earthlings, we will use the article on planet Earth, but I strongly encourage you to experiment with other topics and content as you follow along, such as Harry Potter, dogs, Star Trek, or coffee.
import requests
def wikipedia_page(title):
'''
This function returns the raw text of a wikipedia page
given a wikipedia page title
'''
params = {
'action': 'query',
'format': 'json', # request json formatted content
'titles': title, # title of the wikipedia page
'prop': 'extracts',
'explaintext': True
}
# send a request to the wikipedia api
response = requests.get(
'https://en.wikipedia.org/w/api.php',
params= params
).json()
# Parse the result
page = next(iter(response['query']['pages'].values()))
# return the page content
if 'extract' in page.keys():
return page['extract']
else:
return "Page not found"
# first get the text from the wikipedia page withIf Wikipedia isn’t your thing, you can also go classic with Project Gutenberg. It is a library that holds thousands of free public domain texts that you can download in three lines of code:
import requests
# this is the url for Alice in Wonderland
result = requests.get('http://www.gutenberg.org/files/11/11-0.txt')
print(result.text)Create the Word Cloud
Let’s create a word cloud. Remember, the goal is to understand better what Wikipedia’s Earth page is about without reading it.
from wordcloud import WordCloud
# Instantiate / create a new wordcloud.
wordcloud = WordCloud(
random_state = 8,
normalize_plurals = False,
width = 600,
height= 300,
max_words = 300,
stopwords = []
)
# Apply the wordcloud to the text.
wordcloud.generate(text)Then use matplotlib to display the word cloud as an image:
# Import matplotlib
import matplotlib.pyplot as plt
# create a figure
fig, ax = plt.subplots(1,1, figsize = (9,6))
# add interpolation = bilinear to smooth things out
plt.imshow(wordcloud, interpolation='bilinear')
# and remove the axis
plt.axis("off")Ta-da! Your first word cloud! 😯
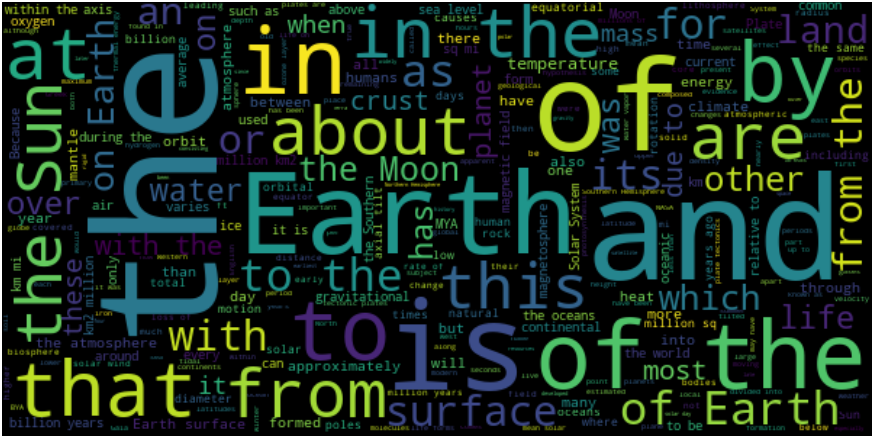
What strikes you about this word cloud?
The word cloud tells you that the page is about the Earth, Moon, and Sun. Cool, well, you knew that already.
However, notice that most of the words do not provide information about the text’s content. There are a lot of common words that are not very meaningful (the, of, is, are, and, that, from, etc.)
These words, called stopwords, are not particularly relevant to the article’s subject, and the word cloud would probably be more insightful if removed, right?
Stopwords are words that do not provide helpful information to infer the content or nature of a text. It may be either because they aren’t meaningful (prepositions, conjunctions, etc.) or too frequent.
Eliminating stopwords is the first step when preprocessing raw text. You will see how to remove them in the next chapter. Then we will come back to this word cloud and redo it.
Let’s Recap!
Natural language processing (NLP) lies at the intersection between linguistics and computer science. Its purpose is to create computer fluency through digital transformation and model building.
Some common NLP use cases include text classification, question answering, document summarization, text generation, sentence completion, translation, and many others.
A word cloud is a snapshot of a text. It helps you explore and understand text at a glance.
To generate word clouds in Python, use the word cloud library. You can read more about it in the project description of the word cloud Python package.
Stopwords do not provide any helpful information when interpreting a text. They are prepositions and conjunctions (the, of, and, that, from, etc.), or non-meaningful words that occur too frequently (is, are, have, will, etc..).
All the scripts in the course are available as Jupyter Notebooks in this GitHub repo.
In the next chapter, we’ll start an NLP project preprocessing phase by removing stopwords.
