Create a Unique Word Form With spaCy

The Issue With Multiple Word Forms
In the previous chapters, we tokenized the Earth text and removed stopwords from the original text, which improved the word cloud visualization. We then looked deeper into the notion of tokenization and explored the NLTK library to preprocess text data.
But there’s more! Much more!
Words can take multiple forms in a text.
For instance, the verb “to be” is usually conjugated throughout the text with forms such as: is, am, are, was, etc. Likewise, tooth and teeth, person and people are different forms of their respective singular root ( tooth, person).
When tokenizing, each one of these word forms are counted as separate tokens, although they should be represented by a single root token: the verb’s infinitive, the noun’s singular form, etc.
In addition to conjugations, other word forms include:
Singular and plurals: language and languages, word and words, etc.
Gerunds (present participles): giving, parsing, learning, etc.
Adverbs: often ending in ly: bad: badly; rough: roughly.
Participle: given, taken, etc.

But … Why do you need a single-word form for each meaningful word in the text?
You can reduce a word’s variant to a unique form using two different methods: stemming or lemmatization.
Stem Words (Remove the Suffix of a Word)
Stemming is the process of removing the suffix of a word based on the assumption that different word forms (i.e., lightning, lightly, lighting) consist of a stem (light) and an ending (+ning, + ly, + ing).
Although words may contain prefixes and suffixes, stemming removes suffixes. And it does so rather brutally!
Let’s look at examples with the words change and study. You only keep the roots: “chang” and “studi,” and drop the endings for every variation.
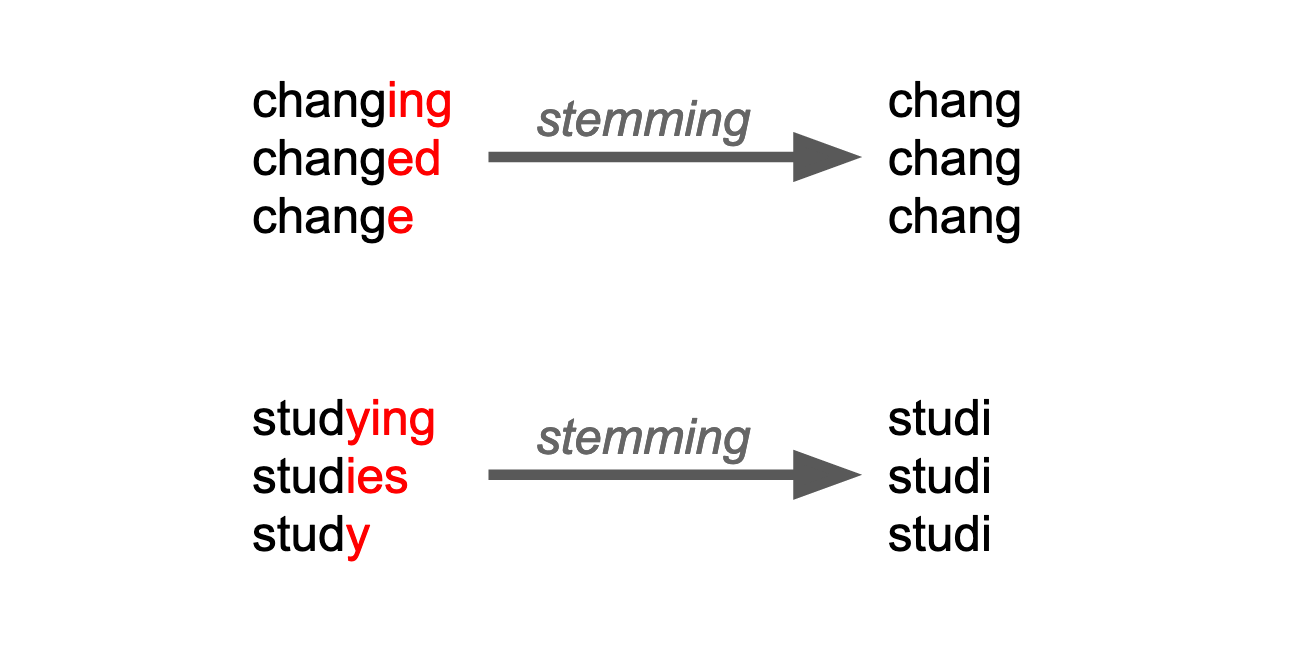
Stemming does not care if the root is a real word or not (i.e., “studi”), which sometimes makes it difficult to interpret the NLP task results.
Let’s see how to apply stemming to Wikipedia’s Earth page. First, tokenize the text, and extract the stem of the word for each token.
# Import tokenizer, stemmer and stopwords
from nltk.tokenize WordPunctTokenizer
from nltk.stem import PorterStemmer
from nltk.corpus import stopwords
# Get the text from the Wikipedia Earth page
# (see chap 1 for the wikipedia_page() function)
text = wikipedia_page('Earth').lower()
# Tokenize as usual
tokens = WordPunctTokenizer().tokenize(text)
# Filter out stopwords
tokens = [tk for tk in tokens if tk not in stopwords.words('english')]
# Now, instantiate a stemmer
ps = PorterStemmer()
# and stem the tokens
stems = [ps.stem(tk) for tk in tokens ]Let’s inspect what kind of stems were generated by picking a random sample from the list:
import numpy as np
np.random.choice(stems, size = 10)If you chose a different sample, your results would be different than mine. Here are my results:
> ['subtrop', 'dure', 'electr', 'eurasian', 'univers', 'cover', 'between','from', 'that', 'earth'] > ['in', 'interior', 'roughli', 'holocen', 'veloc', 'impact', 'in', 'point', 'the', 'come'] > ['caus', 'proxim', 'migrat', 'lithospher', 'as', 'on', 'are', 'earth', 'low', 'also']
So among whole words such as Earth, low, or point, you also have truncated words: subtrop, electr, roughli, caus, and proxim.
As you can see from that example, stemming is a one-way process. It isn’t easy to understand the original word: electr. Was it electronic, electrical, electricity, or electrons? Is the stem univers related to universities or the universe? It’s impossible to tell.
Stemming is a bit crude, and you want more than just the rough root of the word. For that, you use lemmatization.
Lemmatize Words (Reduce Words to a Canonical Form)
Lemmatization is similar to stemming but smarter as it results in understandable root forms.
A lemma is the word form you would find in a dictionary. For example, the word universities is under university, while universe is under universe—no room for misinterpretation. A lemma is also called the canonical form of a word.
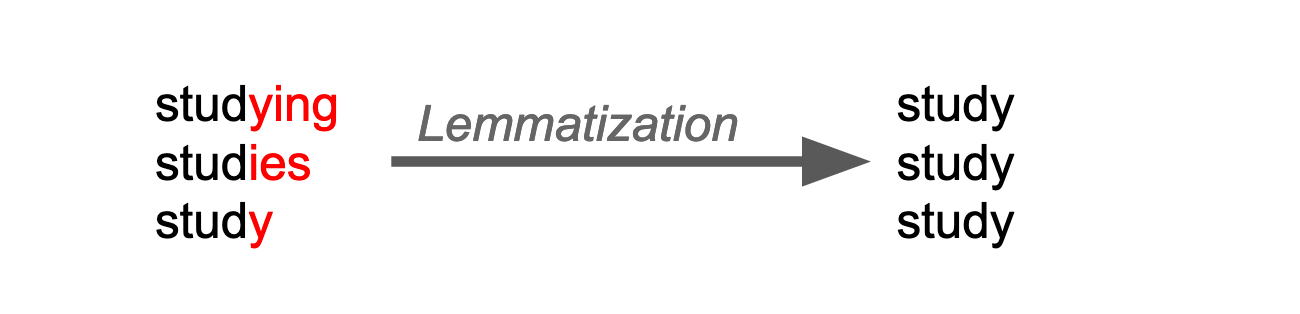
For stemming, we used a stemmer; for lemmatization, we use a … lemmatizer.
A lemmatizer looks at the grammatical role of a word in a sentence to find its canonical form. For instance:

In this last example, the word meeting is lemmatized as meeting when it is a noun and as meet when it is a verb. In both examples, the words was and am were lemmatized into the infinitive form be.
NLTK has a lemmatizer based on WordNet, an extensive lexical database for the English language. You can access that database on the nltk.stem package documentation page. However, my lemmatizer of choice is the one from the spacy.io library.
Tokenize and Lemmatize With spaCy
The spacy.io library is a must-have for all NLP practitioners. The library covers several low-level tasks, such as tokenization, lemmatization, and part-of-speech (POS) tagging. It also offers named entity recognition (NER) and embeddings for dozens of languages.
You can install spaCy with conda or pip . Once you install the library, you need to download the model that fits your needs. The spaCy models are language-dependent and vary in size. Follow the instructions on the install page and download the small English model en_core_web_sm .
Using spaCy on a text involves three steps in Python:
import spacyLoad the model
nlp = spacy.load("en_core_web_sm")Apply the model to the text:
doc = nlp("This is a sentence.")
The nlp model does all the hard work on the text. When nlp is applied to a text (line 3), it parses it and creates a doc object. This doc object contains all the information extracted from the text. It is an iterable object over which you can loop.
Tokenize With spaCy
import spacy
# Load the Spacy model
nlp = spacy.load("en_core_web_sm")
# And parse the sentence (taken from which movie?)
doc = nlp("Roads? Where we're going we don't need roads!")
# print the tokens
for token in doc:
print(token)This generates the following list of tokens:
[Roads, ?, Where, we, ’re, going, we, do, n’t, need, roads, !]
You can see that the tokenization properly handled the punctuation signs: ? and !. But there’s plenty more to see!
Each element of the doc object holds information on the nature and style of the token:
is_space: is a space token.
is_punct: is a punctuation sign token.
is_upper: is an all uppercase token.
is_digit: is a number token.
is_stop: is a stopword token.
# Import and load the model
import spacy
nlp = spacy.load("en_core_web_sm")
# parse the text
doc = nlp("All aboard! \t Train NXH123 departs from platform 22 at 3:16 sharp.")
# extract information on each token
for token in doc:
print(token, token.is_space, token.is_punct, token.is_upper, token.is_digit)This gives in the following output:
token space? punct? upper? digit? All False False False False aboard False False False False ! False True False False <tab> True False False False Train False False False False NXH123 False False True False departs False False False False from False False False False platform False False False False 22 False False False True at False False False False 3:16 False False False False sharp False False False False ! False True False False
Note that:
The tab
\t <tab>element in the sentence has been tagged by theis_spacefunction.NXH123 has been tagged as being all uppercase characters by the
is_upperfunction.The number and punctuations are also properly tagged.
Lemmatize With spaCy
You can also handle lemmatization with spaCy by using token.lemma_ .
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("I came in and met with her teammates at the meeting.")
# print the lemma of each token
for token in doc:
print(f"{token.text:>10}\t {token.lemma_} ")This gives:
token lemma -------------------- I I came come in in and and met meet with with her her teammates teammate at at the the meeting meeting . .
You can see that spaCy properly lemmatized the verbs and the plurals. However, it didn’t provide the lemma for I and her, which would have been the same word in this case. Instead, it tagged it as a pronoun with the tag “-PRON-.”
Let’s Recap!
Words come in many forms, and you need to reduce the overall vocabulary size by finding a common form for all the word variations.
Stemming drops the end of the word to retain a stable root. It is fast, but sometimes the results are difficult to interpret.
Lemmatization is smarter and takes into account the meaning of the word.
Use spaCy to work with language-dependent models of various sizes and complexity.
Use spaCy to handle tokenization out of the box and offers:
Token analysis: punctuation, lowercase, stopwords, etc.
Lemmatization.
And much more!
You can find the code of this chapter in this Jupyter Notebook.
In the next chapter, we’re going to explore spaCy further and introduce two classic tasks of NLP: part-of-speech tagging and named entity recognition.
