Découvrez la scalabilité

Explorez le concept de la scalabilité
Étudions maintenant plus en détail le concept de scalabilité (scalability).
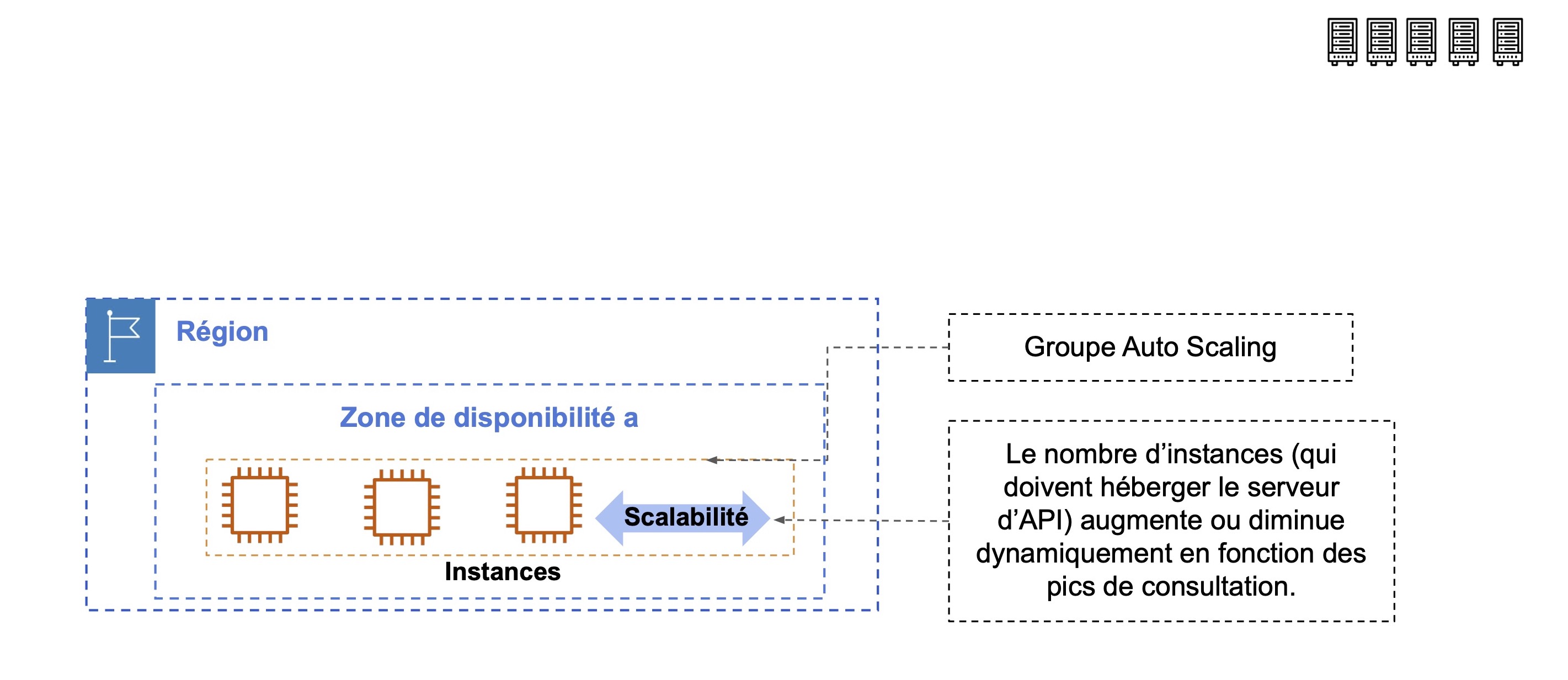
Nous avons la scalabilité verticale et horizontale. C’est cette dernière (voir ci-dessous) qui permettra de nous prémunir contre d’éventuels ralentissements. La scalabilité horizontale consiste à augmenter ou diminuer le nombre d'instances pour une application en fonction de la demande, selon des métriques que nous configurerons. Ces instances font partie d’un même groupe appelé groupe Auto Scaling.
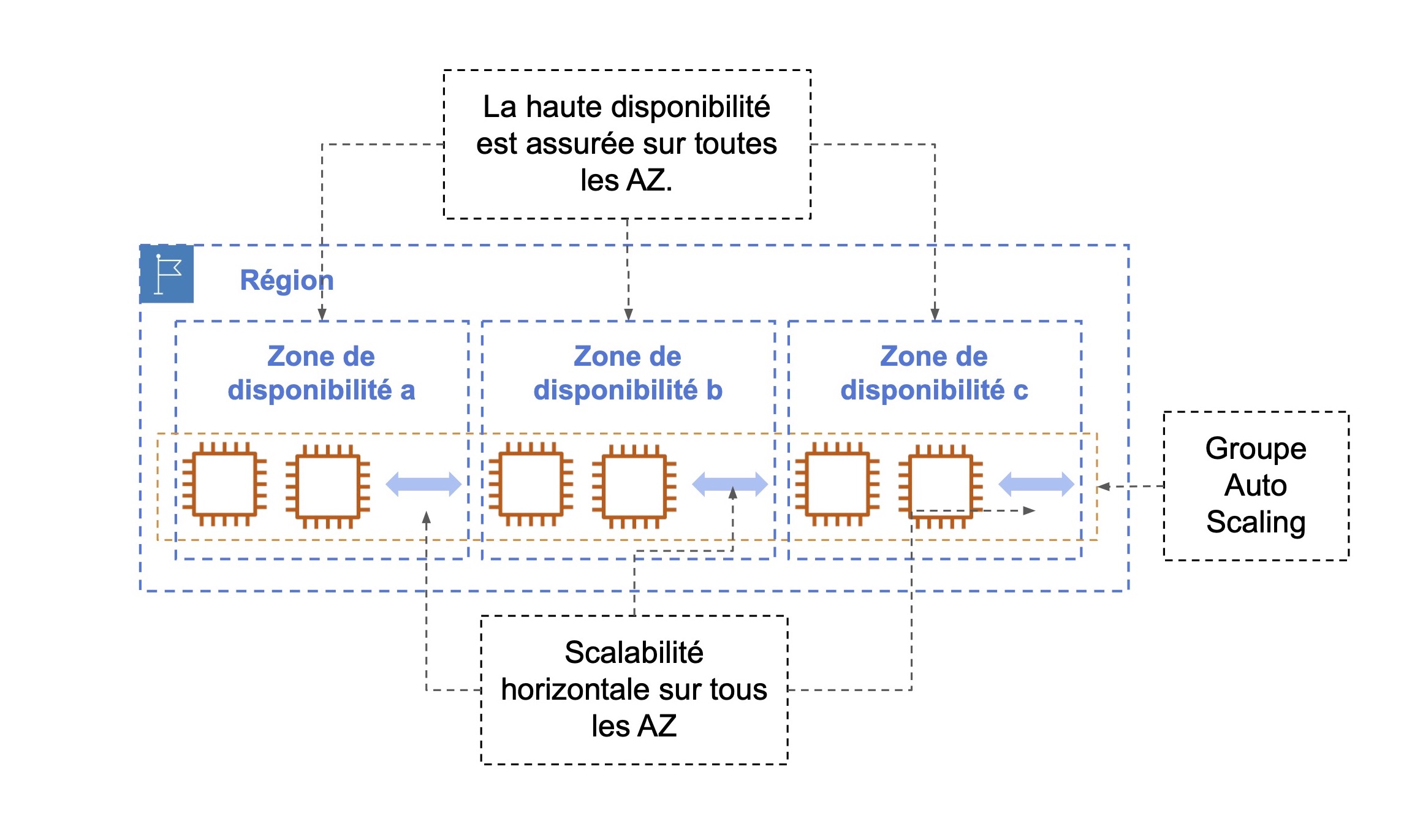
La scalabilité et la haute disponibilité sont complémentaires et s’utilisent en même temps comme indiqué dans le schéma ci-dessous :
Mettez en place de la scalabilité
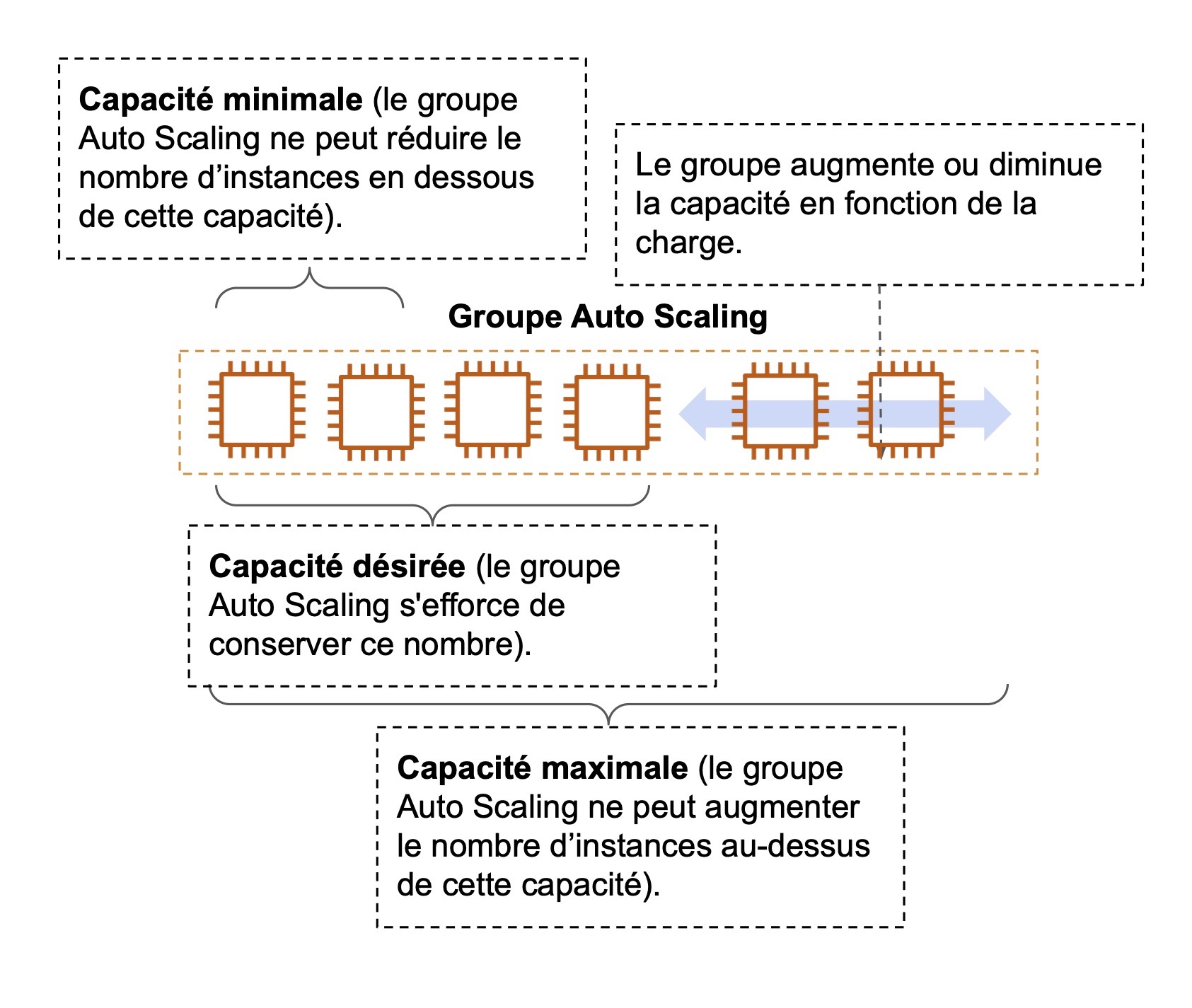
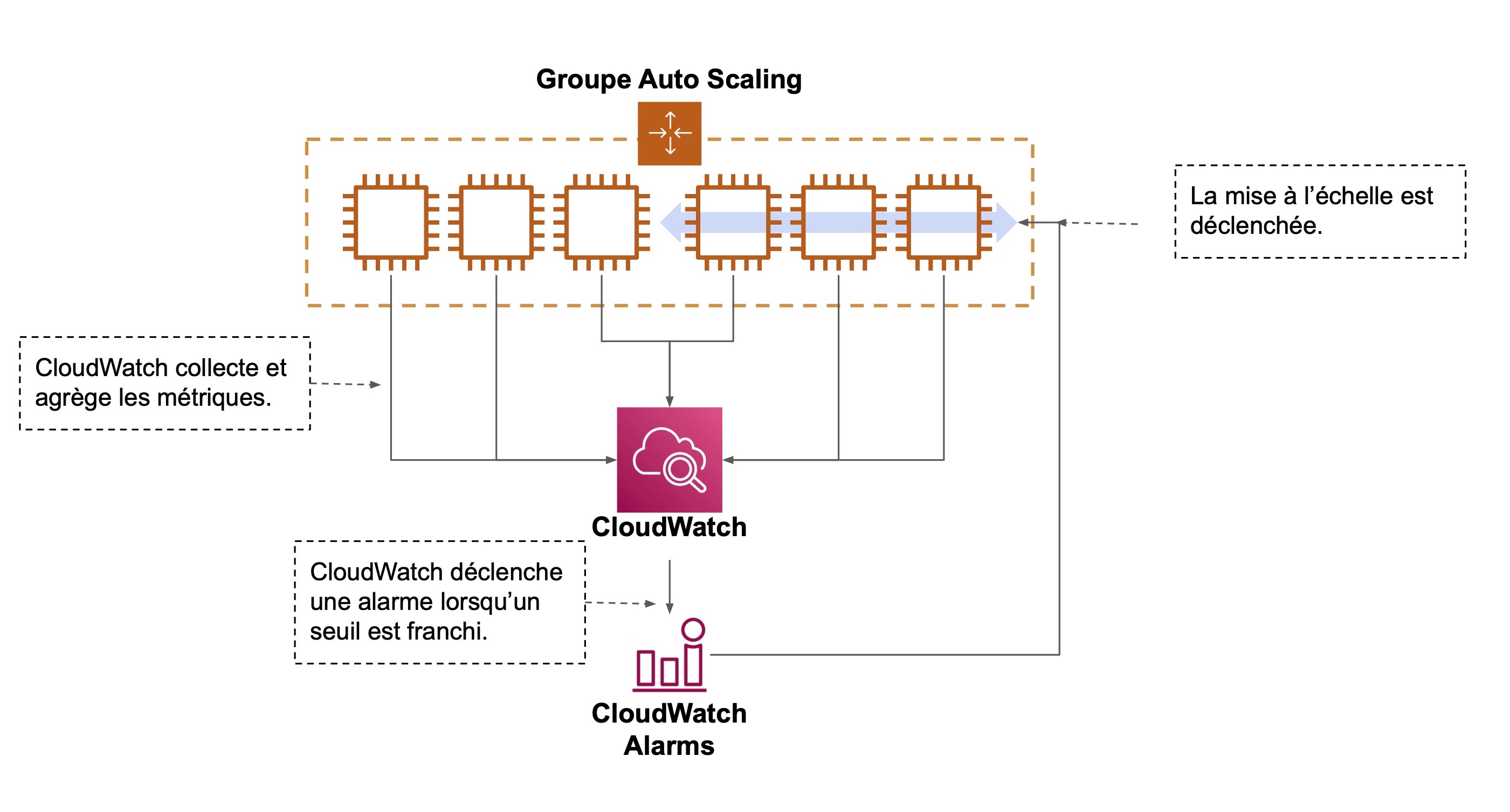
Le groupe Auto Scaling est le socle de la scalabilité qui vous garantit une capacité (le nombre d’instances) minimum, désirée et maximum. Il gère automatiquement l’ajout (scale-in) et la suppression (scale-out) d’instances en fonction de la charge.
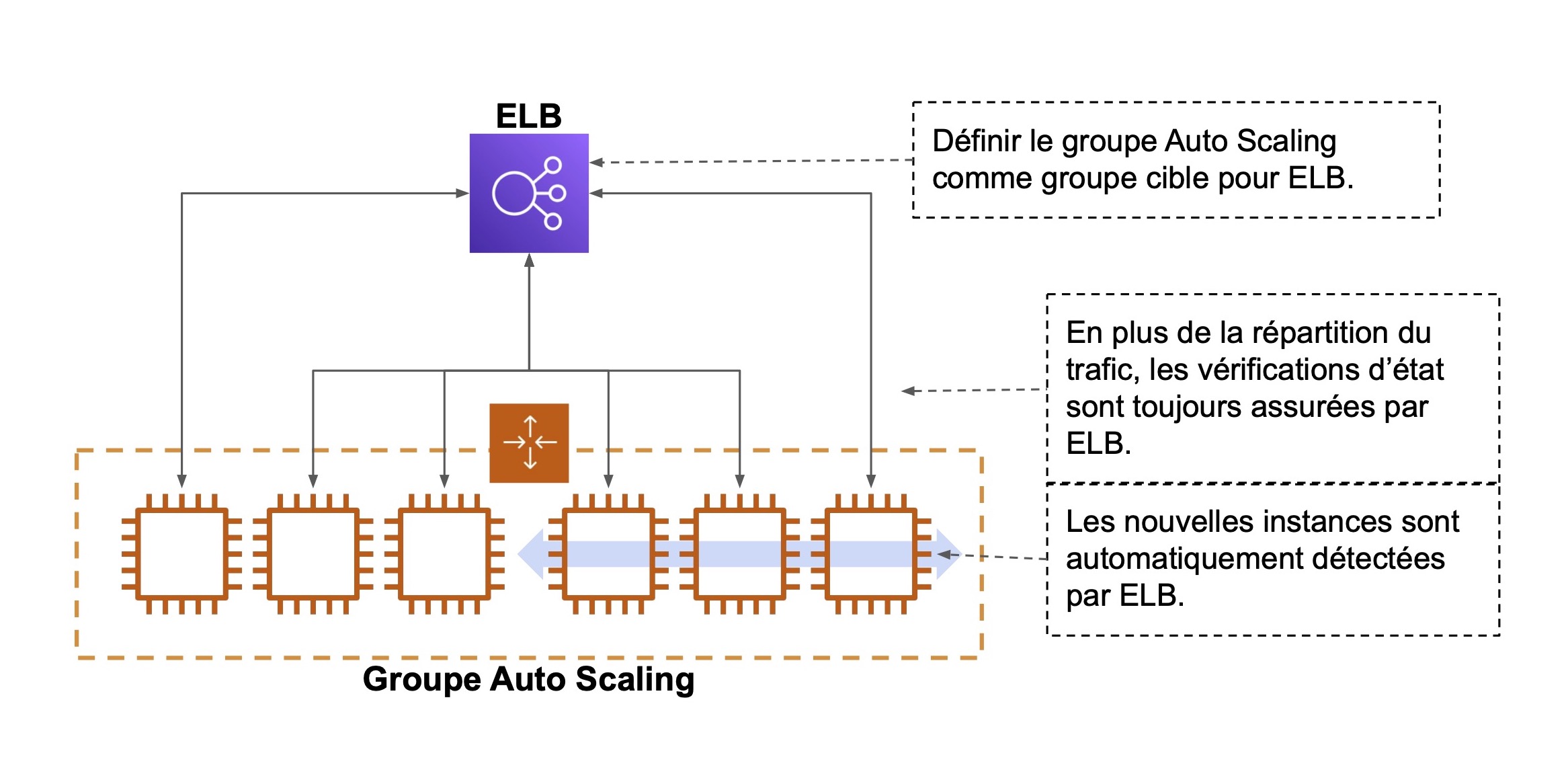
Un groupe Auto Scaling s’intègre avec ELB en l’attachant à un groupe cible.
Il est possible de définir des politiques de mise à l’échelle dynamique pour un groupe Auto Scaling. Une politique se définit à partir de métriques CloudWatch, un service qui collecte et agrège automatiquement des données (mémoire, CPU…) sur les instances pour en construire des métriques. Par exemple, un groupe Auto Scaling a deux instances dont une est à 60 % de CPU et l'autre à 40 % de CPU. La métrique de CPU moyen est de 50 %. Voici les métriques concernées :
ASGAverageCPUUtilization : Utilisation CPU moyenne sur les instances.
ASGAverageNetworkIn/ASGAverageNetworkOut : Nombre moyen d'octets reçus/envoyés par une instance.
ALBRequestCountPerTarget : Nombre de demandes ALB par cible.
N’importe quelle métrique personnalisée.
La mise à l’échelle dynamique du groupe Auto Scaling peut être déclenchée grâce aux alarmes CloudWatch (voir ci-dessous). En effet, les métriques vous permettent de définir des seuils qui, lorsqu’ils sont franchis, déclenchent des alarmes.
Ci-dessous la liste des politiques de mise à l’échelle :
Par suivi de cible (target tracking scaling) : L’objectif est de maintenir la métrique autour d’une valeur prédéfinie – par exemple, maintenir le CPU moyen à 50%.
Simple (simple scaling) : Définissez un seuil pour augmenter ou réduire d’un certain nombre la capacité actuelle du groupe –par exemple, à 50% de CPU moyen, ajouter une instance.
Par étapes (step scaling) : Définissez des étapes correspondant à des seuils pour augmenter ou réduire d’un certain nombre la capacité actuelle du groupe – par exemple, à 80% de CPU moyen, ajouter 2 instances et, à 20%, retirer une.
Planifiée (scheduled actions) : Définissez les intervalles de temps pour déclencher une action (augmenter ou réduire) en fonction de vos prévisions – par exemple, chaque lundi de 8h à 13h le trafic vers l'application web est très élevé, une action sera déclenchée dans cet intervalle pour augmenter la capacité du groupe, puis retour à la normale.
Prédictive(predictive) : Utilisez le machine learning pour prédire la capacité requise en fonction des données historiques de CloudWatch.
Préparez-vous à la certification vis-à-vis de la scalabilité
Voici encore quelques détails qui seront importants à savoir lors de l’examen.
Un groupe Auto Scaling crée un modèle de lancement où vous définissez :
les capacités minimales, désirées et maximales ;
la politique de mise à l’échelle ;
les rôles IAM ;
le type d’instance ;
la paire de clefs ;
les groupes de sécurité ;
VPC et sous-réseaux ;
les volumes.
User-Data.
Un groupe Auto Scaling utilise une politique de résiliation par défaut (termination policy) pour déterminer quelles instances sont à résilier en premier lors d'événements de mise à l'échelle. Vous pouvez en choisir ou créer avec vos critères, par exemple privilégier un type d’instance.
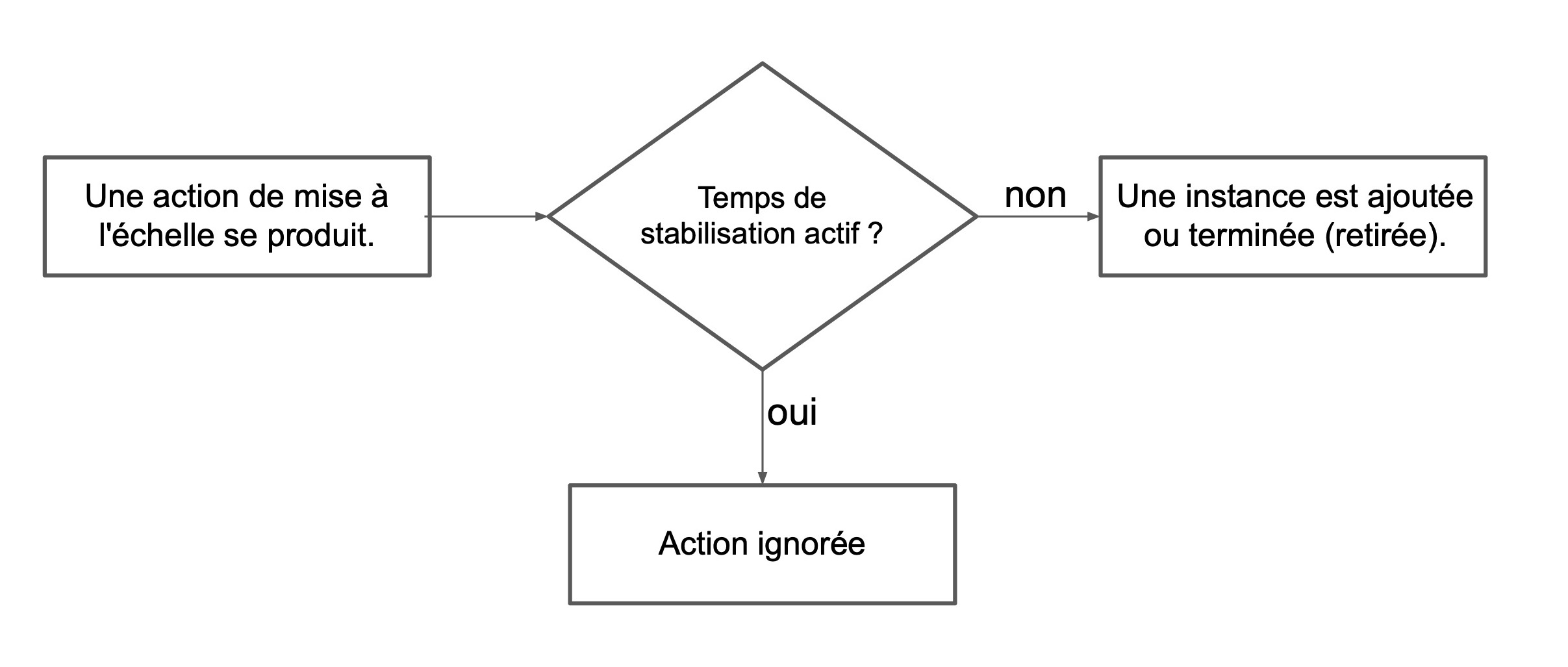
Lors de l’ajout ou de la suppression d’une instance dans un groupe Auto Scaling, vous pouvez appliquer des actions personnalisées sur l’instance grâce aux hooks de cycle de vie.
Questions types de l'examen
Voici un exemple de question sur les sujets vus dans ce chapitre que vous pourriez avoir à l'examen. Essayez d'y réfléchir vous-même avant de vérifier la réponse.
Une entreprise a récemment déployé un nouveau système d'audit pour centraliser les informations sur les versions du système d'exploitation, les correctifs et les logiciels installés pour les instances Amazon EC2. Un architecte de solutions doit s'assurer que toutes les instances provisionnées via les groupes Auto Scaling envoient avec succès des rapports au système d'audit dès qu'elles sont lancées et arrêtées.
Quelle solution atteint ces objectifs le PLUS efficacement ?
Utilisez une fonction AWS Lambda planifiée et exécutez un script à distance sur toutes les instances EC2 pour envoyer des données au système d'audit.
Utilisez une configuration de lancement pour le groupe Auto Scaling afin d’exécuter un script personnalisé via les données utilisateur afin d'envoyer des données au système d'audit lorsque les instances sont lancées et résiliées.
Utilisez les hooks de cycle de vie pour exécuter un script personnalisé afin d'envoyer des données au système d'audit lorsque les instances sont lancées et résiliées.
Exécutez un script personnalisé sur le système d'exploitation de l'instance pour envoyer des données au système d'audit. Configurez le script à exécuter par le groupe Auto Scaling au démarrage et à l'arrêt de l'instance.
À vous de jouer !

Pour délivrer le contenu dynamique du site The Green Earth Post, il est temps d’installer une nouvelle architecture qui va supporter le serveur d’API, pour assurer à la fois la scalabilité et la haute disponibilité. Vous devrez également apporter des modifications au niveau de la base de données RDS.
Pour cela, effectuez les actions suivantes :
Créez un groupe de sécurité pour le futur équilibreur de charge et un pour le futur groupe Auto Scaling.
Modifiez les règles entrantes et sortantes des deux précédents groupes de sécurité ainsi que du groupe de sécurité de la base de données RDS (on va garder la même base de données).
Pour le moment, le protocole pour le trafic entrant sera HTTP, on modifiera cela plus tard dans la suite de la partie.
Créez un équilibreur de charge de type application dans les sous-réseaux appropriés. Il faudra également créer un groupe cible vierge (pour le moment sur le port 80).
Créez un modèle de lancement pour le groupe Auto Scaling. Hormis le VPC et le groupe de sécurité, les paramètres sont les mêmes que ceux utilisés dans la partie 2.
Créez un groupe Auto Scaling via le précédent modèle de lancement et attachez-le à l’équilibreur de charge.
Configurez une capacité minimale de 1, maximale de 6 et désirée de 3.
N’activez pas de politique de mise à l’échelle.
Testez avec votre navigateur, et/ou les commandes curls que vous pouvez connaître, la santé du serveur d’API, lire et écrire des commentaires en base.
Utilisez la chaîne de requête showLocalIp=yes pour afficher les adresses IP.
Pour la base de données RDS, créez un réplica en lecture pour la scalabilité horizontale.
Enfin, pour la mise à l’échelle dynamique du groupe Auto Scaling, créez une politique basée sur le nombre de requêtes d’Application Load Balancer par cible. Constatez l’évolution de la capacité désirée du groupe Auto Scaling.
Vous pouvez vérifier si vous avez fait cet exercice correctement ici:
En résumé
Les groupes Auto Scaling assurent la scalabilité.
La scalabilité et la haute disponibilité assurent la résilience du back-end.
Les alarmes CloudWatch peuvent être utilisées pour déclencher la mise à l’échelle d’un groupe Auto Scaling.
Pour un groupe Auto Scaling, les politiques de résiliation permettent de déterminer quelles instances sont à résilier en premier lors d'événements de mise à l'échelle.
Dans le prochain chapitre, nous verrons comment chiffrer nos données et communications !
