Comprenez l’architecture et le déploiement de Kestra
 L’architecture de Kestra a été conçue pour passer à l’échelle, être flexible et tolérante aux erreurs. Kestra peut être déployé sur de nombreux systèmes. Regardons cela plus en détail !
L’architecture de Kestra a été conçue pour passer à l’échelle, être flexible et tolérante aux erreurs. Kestra peut être déployé sur de nombreux systèmes. Regardons cela plus en détail !
Découvrez l’architecture de Kestra
L’architecture principale de Kestra repose sur plusieurs services et un back-end de base donnée de type JDBC :
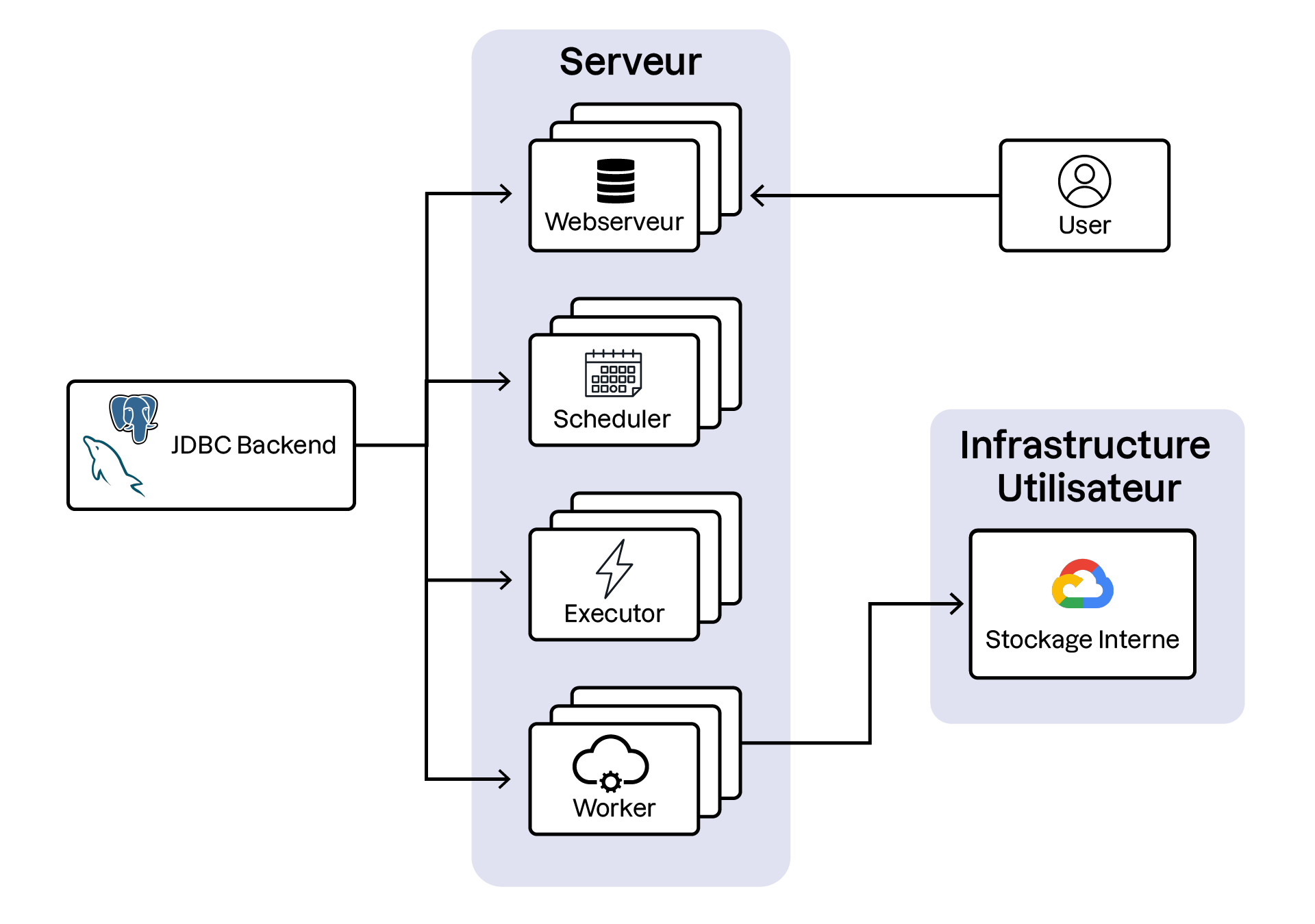
Découvrez les différents services Kestra
Les composants
Kestra est composé de trois composants principaux : les services de compute, la base de données et le stockage interne. Regardons d’abord les services :
Worker : Exécute les tâches et interagit avec l'infrastructure de l'utilisateur.
Executor : Gère la logique d'orchestration, y compris les déclencheurs de flux.
Scheduler : Planifie les workflows et traite tous les déclencheurs.
Web Server : Sert l'API et l'interface utilisateur pour l'interaction avec le système.
Ces services sont indépendants, mais tous indispensables pour faire fonctionner Kestra.
La base de données
La base de données stocke les métadonnées d'orchestration. Tous les flux, exécutions, journaux, etc. sont stockés dans cette base. Chaque composant est découplé les uns des autres et communique via la base de données. Ce découplage du calcul, du stockage et des métadonnées permet une meilleure résilience de l'instance.
Le stockage interne
Le stockage interne est l'endroit où tous les fichiers de données sont stockés. Par exemple, les sorties d'un flux stockées dans la base de données ne sont que des métadonnées contenant le chemin réel des données dans le stockage interne. Les composants du service Kestra ne lisent les données qu'à partir de ce service.
Découvrez les différentes façons de déployer Kestra
ll existe différentes manières de déployer les composants Kestra, chacune avec ses avantages et ses limitations.
Compute
Les composants de compute de Kestra (worker, executor, scheduler et webserver) peuvent être déployés de deux manières différentes : en standalone ou de façon distribuée.
Standalone
Le déploiement standalone (généralement avec docker-compose) est très pratique pour démarrer avec Kestra. C'est simple et ne nécessite aucun réglage particulier. Cependant, il expose un “single point of failure” et ne peut être mis à l’échelle que verticalement, car tout est sur le même serveur.
Distribué
Les composants de compute de Kestra peuvent être distribués sur différents serveurs. Par exemple, il est intéressant de déployer plusieurs workers ou executors sur différents serveurs pour passer à l’échelle horizontalement votre instance Kestra. Cela présente l'avantage d'améliorer la résilience en cas de défaillance d'un seul composant. Les ingénieurs Kestra peuvent déployer leur instance de manière distribuée soit "manuellement", soit via un système de gestion de containers comme Kubernetes.
Selon l'approche choisie, vous pourriez avoir besoin de compétences avancées dans ces technologies pour déployer correctement Kestra de manière distribuée.
Méthode de déploiement | Avantages ✅ | Désavantages ❌ |
Standalone | Petite production, non critique | “Single Point of Failure” Mise à l’échelle seulement verticale |
Distribué | Mise à l’échelle horizontale et verticale Résilient | Demande une attention particulière au déploiement (manuel) |
Distribué (avec Kubernetes) | Facile à déployer avec Helm | Nécessite connaissances en Kubernetes et Helm |
Base de données
La base de données de Kestra est assez simple à déployer : il vous suffit d'avoir une instance (Postgres par exemple) en fonctionnement. Pour simplifier la maintenance de cette base de données, de nombreux ingénieurs préfèrent utiliser des services gérés via des services cloud (tels qu'AWS RDS, GCP CloudSQL, etc.). Cela réduit les charges liées aux sauvegardes, aux redémarrages en cas de panne et à la maintenance générale du système. Il est recommandé de déployer les composants Kestra séparément de la base de données, afin que tout soit découplé en cas de panne.
Stockage interne
Il existe plusieurs configurations possibles pour le stockage interne. Il est vivement encouragé de déployer le stockage interne de Kestra sur des services de stockage objet fournis par les fournisseurs de cloud (AWS S3, Azure BlobStorage, GCP GCS, etc.) ou toute autre possibilité que vous pourriez avoir sur site (comme MinIO). Comme pour la base de données, cela découple les rôles de chaque partie et permet de sauvegarder les données importantes.
En résumé
Kestra est flexible, robuste et peut passer à l’échelle facilement.
Kestra possèdent deux types d’architecture: JDBC ou Kafka.
Kestra repose sur un ensemble de service (worker, executor, scheduler, web-server).
Kestra utilise un metastore (par exemple Postgres) et un stockage interne (système de fichier).
Il est possible de déployer ces éléments de différentes façons: cela dépend de vos besoins et de votre infrastructure.
Nous venons de voir comment déployer les services Kestra, explorons maintenant comment déployer vos flux de façon robuste et automatique.
