Catégorisez l’inconnu avec la pseudo-labellisation

Établissez des prédictions fiables
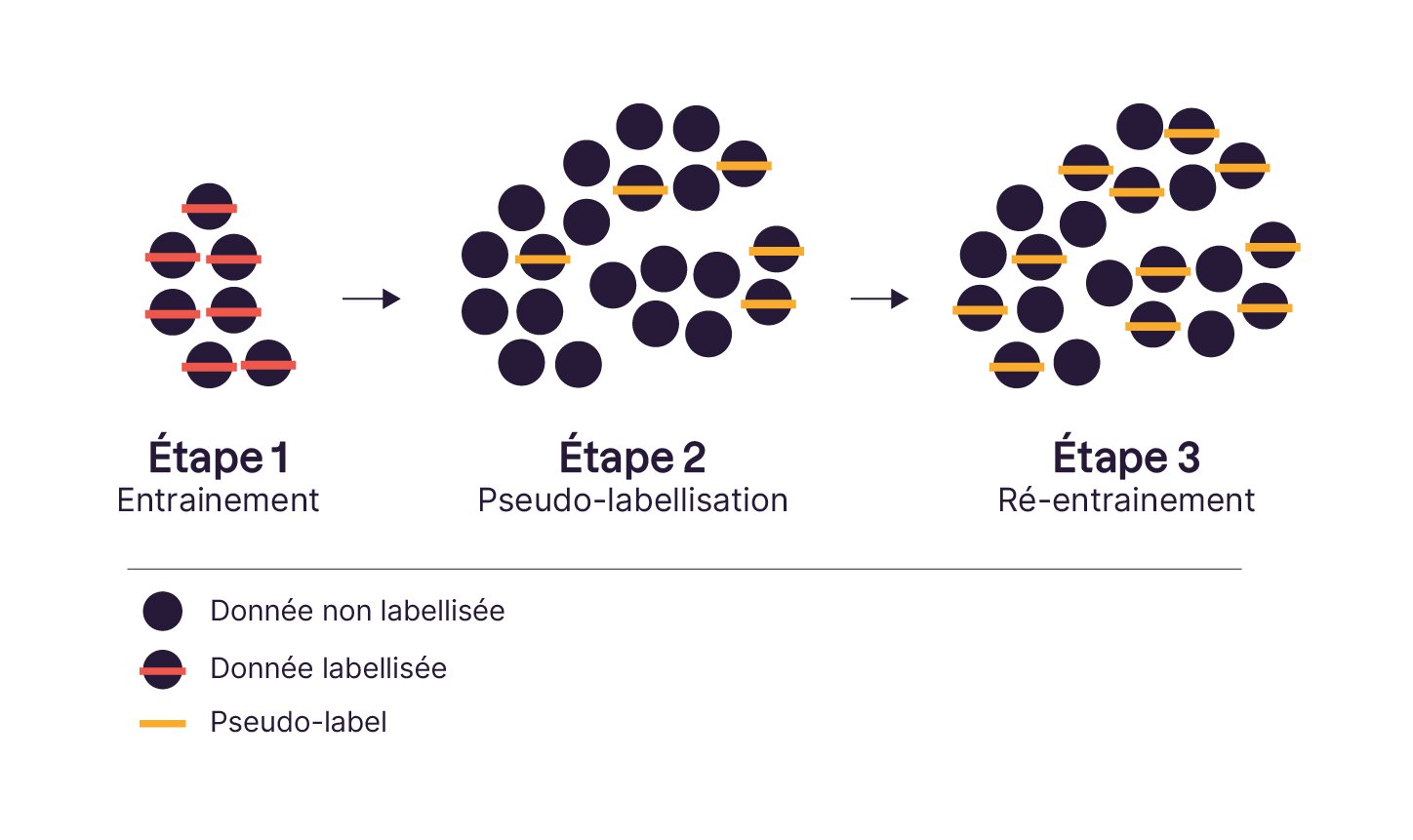
En pratique, voici comment cela fonctionne :
On commence par entraîner un modèle sur le petit jeu de données labellisées dont on dispose.
Ensuite, on fait prédire au modèle les classes des exemples non labellisés.
Lorsque le modèle semble sûr de lui (autrement dit, lorsque sa probabilité de prédiction dépasse un certain seuil de confiance), on récupère ces pseudo-labels pour enrichir le jeu d’entraînement.
Puis on recommence : on ré-entraîne, on prédit, on sélectionne à nouveau.
C’est un cercle vertueux... tant que la confiance est bien placée :
Pourquoi ce seuil est-il si important ?
Considérons un exemple concret :
Si votre modèle prédit une classe avec
0.65de probabilité, cette prédiction est potentiellement bruitée et pourrait introduire des erreurs dans l'entraînement.En revanche, une probabilité de
0.95suggère que le modèle a bien identifié les caractéristiques discriminantes de l'image (texture, bordures, couleur).
C’est d’autant plus important que le processus est itératif : après avoir ajouté les pseudo-labels au jeu d'entraînement, on ré-entraîne le modèle, qui devient alors plus performant pour la prochaine vague de prédictions. Cette boucle est vertueuse tant que des erreurs (mauvais pseudo-labels) ne s’introduisent pas dans l’entraînement.
D’un point de vue mathématique, la pseudo-labellisation agit comme une régularisation implicite : le modèle apprend à se stabiliser autour de ses prédictions les plus certaines. D’un point de vue pratique, c’est surtout une manière astucieuse de tirer parti de la masse de données non annotées sans faire exploser le budget d’annotation.
Découvrez un cas d’usage
Cette implémentation utilise un critère de sélection : le seuil de probabilité 0.9 (On peut imaginer d’autres critères, par exemple : le respect d’une marge de sécurité entre la probabilité du top 1 et la probabilité du top 2 de la prédiction pour une image avant de valider la sélection du pseudo-label.)
Par simplicité, nous resterons sur un seul critère de sélection, mais sentez-vous libre d’en tester autant que vous voulez !
Résultats :
Itération | AUC | Accuracy | F1-score macro |
Baseline | 0.824 | 0.489 | 0.234 |
1 | 0.805 | 0.547 | 0.290 |
2 | 0.845 | 0.586 | 0.308 |
3 | 0.852 | 0.585 | 0.295 |
4 | 0.846 | 0.598 | 0.289 |
5 | 0.844 | 0.605 | 0.301 |
Pourquoi s’arrêter à 5 itérations alors que ça commence tout juste à marcher… ?
Et bien, parce que… je suis fainéant … heu non, pardon… parce que c’est à vous de jouer !
À vous de jouer !

Reprenez ces codes et testez les différentes variantes mentionnées plus haut (et plus d’itérations si ça vous chante).
Vous pouvez également essayer de limiter le nombre de pseudo-labels autorisés par classe et par itération afin d’avoir une stratégie plus fine d’apprentissage.
Ou pourquoi ne pas essayer de faire prédire les pseudo-labels par deux modèles différents et ne retenir que les prédictions communes ?
À vous de voir, mais surtout, amusez-vous bien !
Comprenez les avantages et les pièges de la pseudo-labellisation
Avantages
La pseudo-labellisation brille par sa facilité de mise en œuvre. Avec seulement quelques lignes de code, vous pouvez transformer un modèle supervisé limité en une version semi-supervisée performante.
Dans notre cas, en partant d’un petit ensemble de 350 images étiquetées, nous avons utilisé les prédictions confiantes du modèle pour ajouter progressivement des milliers d’images non étiquetées. Résultat ? Une amélioration notable des performances ! Après cinq itérations, notre modèle a atteint :
une AUC de
0.844une accuracy de
0.605et un F1-score macro de
0.301
(Contre, respectivement, 0.824 , 0.489 et 0.234 pour le modèle supervisé initial).
Ces gains montrent que la pseudo-labellisation a permis au modèle de mieux généraliser en exploitant les motifs visuels des lésions cutanées non annotées.
Pièges et précautions
Le principal danger de la pseudo-labellisation réside dans la propagation des erreurs. Si le modèle génère des pseudo-labels incorrects et les intègre dans l’entraînement, ces erreurs s’amplifient au fil des itérations, créant un biais de confirmation. Dans vos expériences, vous avez peut-être observé que des seuils de confiance trop bas - par exemple
< 0.9- introduisent du bruit, ce qui peut faire stagner voire dégrader le F1-score dans certaines itérations. Cela souligne l’importance de choisir un seuil de confiance élevé (comme0.9dans notre cas) pour ne retenir que les prédictions les plus fiables.Un autre défi est la calibration du modèle. Si les probabilités prédites ne reflètent pas une véritable confiance, le modèle risque de sélectionner des pseudo-labels peu fiables. C’est ici que vous pouvez utiliser des garde-fous comme une marge entre les deux meilleures probabilités (
top1ettop2) pour renforcer la fiabilité des pseudo-labels, et ainsi limiter le nombre d’ajouts par classe pour maintenir l’équilibre. Ces précautions contribuent à stabiliser les performances, mais elles demandent un réglage fin.Enfin, la pseudo-labellisation peut être moins performante sur des classes sous-représentées ou ambiguës. Dans DermaMNIST, certaines lésions (comme les mélanomes) sont plus difficiles à distinguer, ce qui peut limiter les gains si le modèle initial manque de robustesse. C’est pourquoi nos résultats montrent une amélioration progressive mais non spectaculaire du F1-score macro, qui reste sensible au déséquilibre entre classes.
Maximisez les chances de succès
Voici quelques leçons que l’on peut tirer de notre expérimentation en pseudo-labellisation :
Ajustez le seuil de confiance avec soin : Un seuil de
0.9a bien fonctionné pour DermaMNIST, mais il peut varier selon le jeu de données. Testez plusieurs valeurs et suivez les métriques (AUC, accuracy, F1-score) pour trouver le bon équilibre.Surveillez les métriques : Dans notre cas, nous avons tracé l’évolution des performances à chaque itération (voir la courbe des métriques dans le notebook). Cela permet de détecter une stagnation ou une dérive précoce.
Limitez les ajouts : Vous pouvez restreindre les pseudo-labels à 10% du jeu non labellisé par itération et ainsi équilibrer les classes, ce qui peut éviter un emballement des erreurs.
Améliorez la calibration : Une calibration par température ou une validation croisée peut renforcer la fiabilité des probabilités prédites.
En résumé
La pseudo-labellisation est une méthode qui permet de booster les performances d’un modèle en exploitant des données non labellisées, comme démontré avec DermaMNIST, où nous avons amélioré l’exactitude (accuracy) de
0.489à0.605en cinq itérations.Cependant, cette méthode exige une vigilance accrue pour éviter la propagation des erreurs et une calibration rigoureuse pour maximiser les gains.
Avec les bons garde-fous, c’est une porte d’entrée idéale vers le monde du semi-supervisé.
Dans le prochain chapitre, vous explorerez comment exploiter les relations entre les données grâce aux graphes de similarité, pour propager les labels d’une manière encore plus structurée et robuste.
