Classifiez des données non-labellisées avec un générateur et un discriminateur

Découvrez le fonctionnement du générateur et du discriminateur
Et si une IA pouvait dessiner des images inédites comme par magie ?
Pour comprendre comment ça marche, prenons une métaphore :
Imaginez un faussaire talentueux (le “générateur”) qui forge des œuvres d’art. Il est confronté à un expert (le “discriminateur”) chargé de démasquer les contrefaçons parmi les originaux. Le générateur affine ses créations pour duper son rival, tandis que le discriminateur perfectionne son jugement sur des échantillons réels et fabriqués.
Ce duel repose sur une dynamique mathématique : le discriminateur minimise sa perte pour maximiser sa précision, tandis que le générateur maximise sa perte pour brouiller les pistes. Avec des cycles d’entraînement répétés, cette compétition aboutit à des images quasi-réalistes, ouvrant la voie à des applications créatives.
Au début, les outputs (“sorties” en français, mais dans le milieu, on ne parle jamais de “sorties”) du générateur sont brouillons, mais la compétition avec le discriminateur les polit peu à peu. Cette danse collaborative promet des résultats impressionnants, posant les bases pour des applications avancées dans le SSL.
Comprenez le rôle étendu du discriminateur
Comment un modèle conçu pour juger peut-il aussi attribuer des catégories ?
Les semi-supervised GANs (SGANs) élargissent les horizons des GANs classiques en donnant au discriminateur une double mission :
Identifier l’authenticité
Prédire les classes des données non labellisées
Là où un GAN classique offre une décision binaire, un SGAN génère des probabilités par classe (via une couche softmax*) pour les données labellisées, tout en évaluant binairement les données non labellisées ou générées.
Quelles sont les étapes de l’entraînement d’un SGAN ?
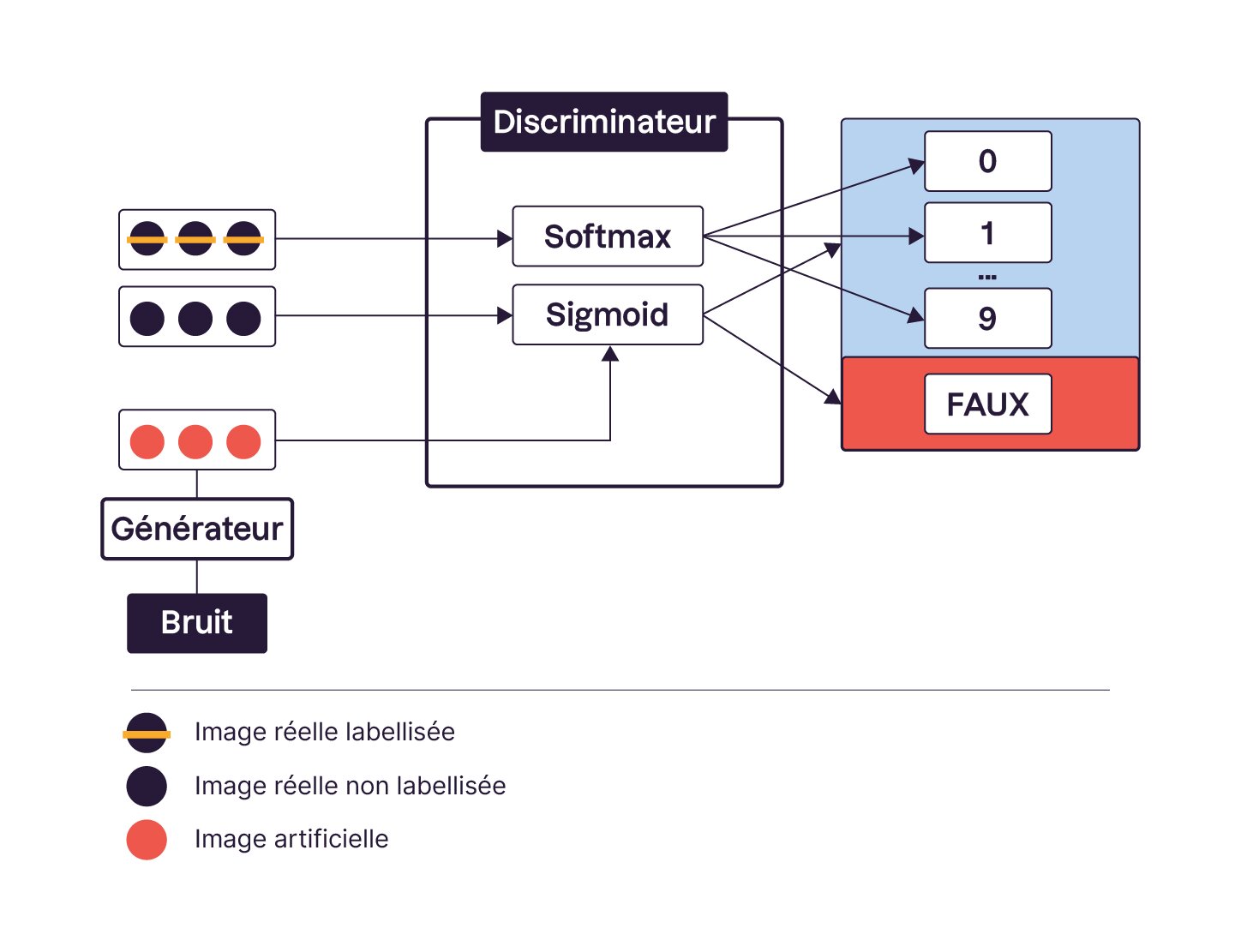
L’entraînement d’un SGAN ressemble à une danse bien orchestrée en trois étapes :
Étape 1 : Entraînement avec les images labellisées Le discriminateur s’entraîne sur des images qui ont déjà leur label (par exemple, de
0à6) pour deviner à quoi elles appartiennent. Il ajuste ses réglages pour réduire une erreur de prédiction, en s’appuyant sur les labels qu’on lui donne.Étape 2 : Entraînement sur les vraies images sans labels Avec les images sans labels, le discriminateur additionne les chances qu’elles appartiennent à des catégories (comme
0à6) et veut montrer qu’elles sont “vraies” en obtenant un score élevé. Une sorte de défi (qu’on appelle perte adverse) l’encourage à bien les reconnaître. Si le score obtenu en additionnant les probabilités des catégories de0à6est moins élevé que la probabilité attribuée à la catégorie "faux", la perte va lui signaler qu’il doit apprendre à mieux repérer les vraies images, en boostant les probabilités des catégories 0 à 6 la prochaine fois, pour qu’elles surpassent la catégorie "faux" et reflètent mieux la réalité.Étape 3 : Duel avec les images inventées Le générateur crée des images fictives à partir de bruits aléatoires, et le discriminateur les juge. Il ajuste ses erreurs pour repérer la catégorie “faux” (par exemple, un
7) au maximum, tandis que le générateur essaie de le piéger en rendant ses fausses images aussi convaincantes que possible !
Une fois ces briques bien assimilées, rien ne vous empêche d’innover !
Par exemple, pourquoi ne pas :
entraîner un SGAN par classe (un modèle pour les mélanomes, un autre pour les nævus) plutôt que sur toutes les classes simultanément ?
ou encore fusionner ces prédictions avec des pseudo-labels issus d’autres méthodes, comme le pseudo-labelling, pour un modèle hybride plus robuste ?
Ces ajustements ouvrent des perspectives intéressantes à explorer dans vos projets.
Utilisez des SGANs
Prêt à appliquer ces concepts avec DermaMNIST ?
Lors de l’évaluation, notre modèle (le discriminateur) a décroché :
un score AUC de
0.612une accuracy de
0.428et un score F1 moyen de
0.392
C’est un peu mieux que la méthode de la propagation des labels : AUC de 0.505
Mais encore loin de la pseudo-labellisation : AUC de 0.844
Pas de panique, ça reste prometteur !
En effet, cette technologie a un gros potentiel, même avec ces résultats modestes ! Pour des raisons de simplicité et de rapidité, j'ai choisi de me limiter à 5 tours d'entraînement (epochs). Mon but, c’est de vous montrer comment ça marche et d’expliquer, pas de tout optimiser à fond.
Vous, par contre, vous pouvez vous amuser à ajuster plein de paramètres pour faire mieux :
Essayez de jouer avec le rythme d’apprentissage, par exemple
0.001ou même0.000001Ou ajoutez un lissage des probabilités d’étiquettes pour stabiliser les choses.
Vous pourriez aussi tester des modèles plus sophistiqués, comme les GANs conditionnels (un générateur qui prend en inputs du bruit mais aussi le label de l’image), pour rendre les images encore plus réussies.
Comprenez les avantages et les limites de ces modèles
Avantages
Les SGANs se distinguent par :
leur aptitude à fabriquer des données synthétiques, comblant les lacunes d’un jeu de données limité ;
la polyvalence du discriminateur qui dope la généralisation.
La versatilité des SGANs ouvre la voie à des usages variés.
Limites
Pourtant, des écueils subsistent :
L’équilibre entre les deux réseaux peut se rompre, causant des instabilités après 150 epochs, par exemple.
La qualité des images fluctue : certaines sont fidèles, mais d’autres souffrent d’artefacts (flous ou déformations), réduisant leur efficacité.
Au-delà de ces défis techniques, il existe un débat animé dans la communauté autour des GANs (et donc SGANs) :
Certains experts soulignent leur utilité incontestable pour générer des données variées (appartenant à tous les groupes du jeu de données et de façon réellement représentative) et ainsi enrichir l’entraînement sans biais.
D’autres questionnent leur fiabilité à grande échelle, en raison de problèmes comme le mode collapse (où le générateur produit des variations limitées).
De plus, des préoccupations éthiques émergent, comme la reproduction de biais présents dans les données d’origine.
Mais pas d’inquiétude : ces discussions stimulent l’innovation et encouragent une utilisation vigilante. Restez curieux et testez par vous-même pour vous forger votre propre opinion !
À vous de jouer !

Optimisez les SGANs en testant une ou plusieurs des variantes suivantes :
Perfectionnez la génération : Passez les dimensions du bruit (le paramètre
z_dimdans le notebook) à200et lancez un entraînement sur 100 epochs. Comparez les résultats visuels avec les données réelles.Renforcez la classification : Intégrez les prédictions du discriminateur (seuil
0.9) comme pseudo-labels et fusionnez-les avec les données initiales. Mesurez les gains sur l’AUC et l’accuracy.Assurez la stabilité : Expérimentez avec un taux d’apprentissage (learning rate) de
0.0001et un label smoothing (par exemple0.1). Analysez l’évolution des pertes pour une convergence plus harmonieuse.Fusion créative : Mélangez les images synthétiques avec des pseudo-labels d’une méthode antérieure. Cela améliore-t-il les performances sur les classes rares ?
Ces challenges vous mèneront vers une maîtrise des SGANs !
En résumé
Les SGANs unissent génération et classification, tirant parti des données non labellisées pour un apprentissage enrichi.
Avec une AUC de
0.612en 5 epochs, cette technique démontre bien un fort potentiel !La force des SGANs réside dans l’augmentation de données, bien que la stabilité et la qualité des outputs demandent des optimisations.
Le prochain chapitre vous initiera à la régularisation par cohérence, une nouvelle aventure passionnante. Restez motivé et continuez à explorer !
