Explorez les réseaux de neurones en couches
Dans ce chapitre, nous allons comprendre les limitations d’un neurone formel, et comment les lever en mettant les neurones en réseau. Ensuite nous allons voir comment utiliser un réseau en couches.
Limitation du neurone formel
Nous avons vu comment on peut utiliser un modèle avec un simple neurone et l'appliquer à une tâche de classification.
Cependant, un seul neurone ne permet pas de répondre à des problèmes complexes.
Mettez plusieurs neurones en réseau
Pour résoudre des problèmes complexes, les neurones biologiques communiquent aussi entre eux via les synapses, et forment un réseau. Nous pouvons associer les neurones formels de la même manière, en affectant la sortie d'un neurone à une ou plusieurs entrées d'autres neurones.
Voici une topologie quelconque de réseaux. Chaque nœud rouge représente un neurone.
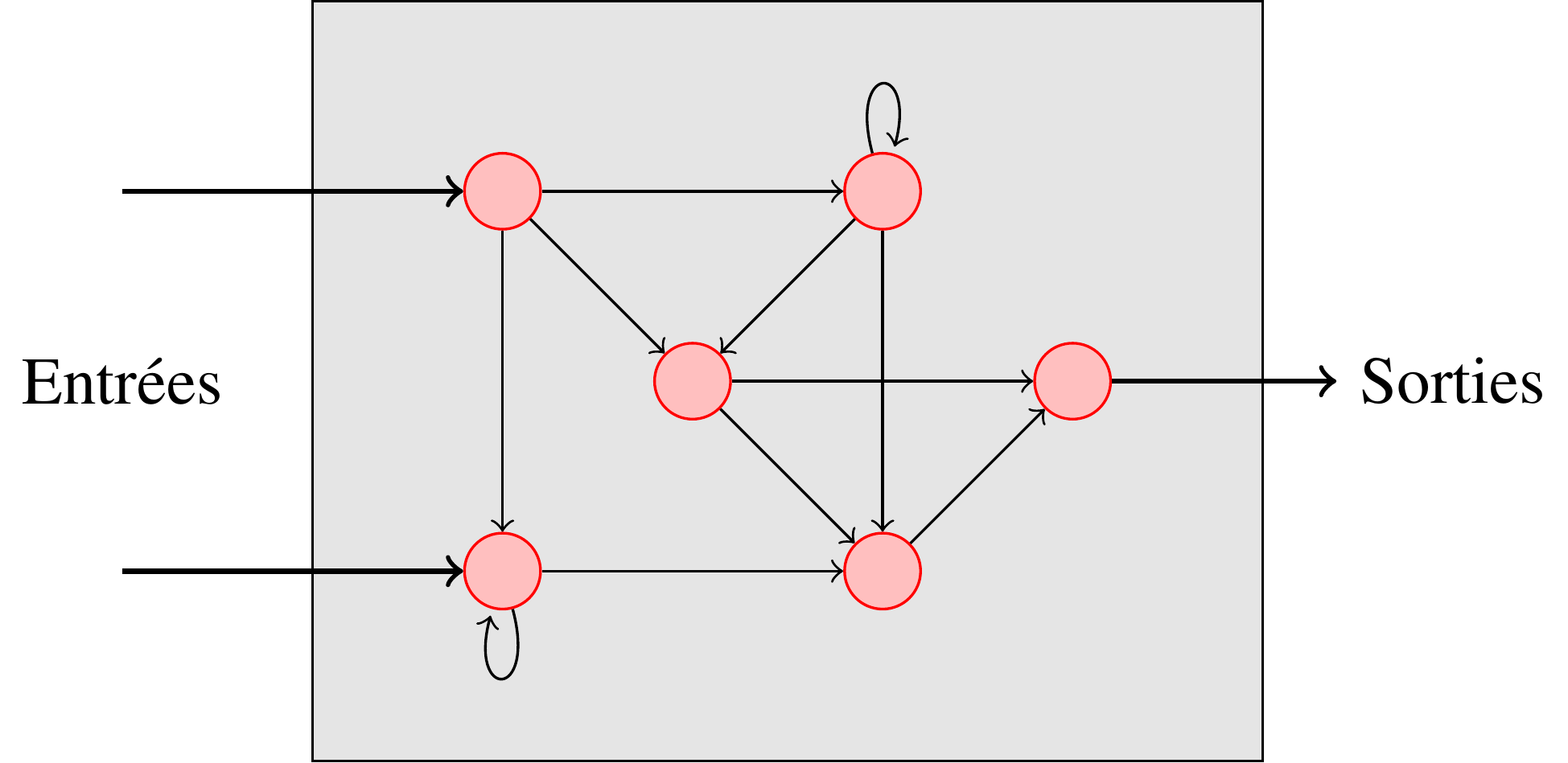
On utilise le plus souvent des réseaux particuliers organisés en couches :
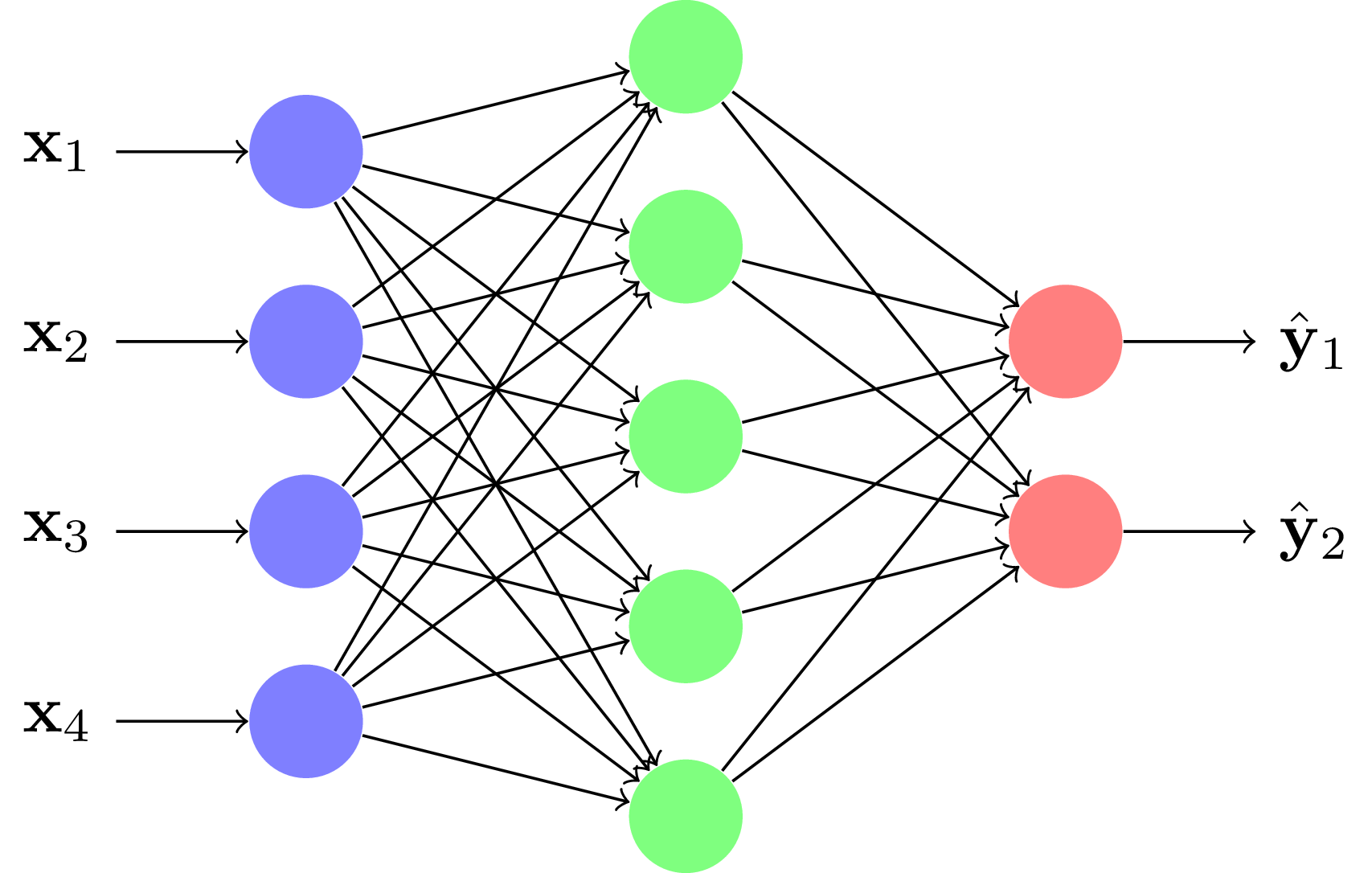
L'influx d'information va toujours des couches d'entrées aux couches de sorties. Ces réseaux peuvent être appris par descente de gradient. Ils sont adaptés aux données de tailles fixes, comme des images. Ils portent le nom de perceptron multicouche (PMC), Feed-Forward ou Multi Layer Perceptron (MLP) en anglais.
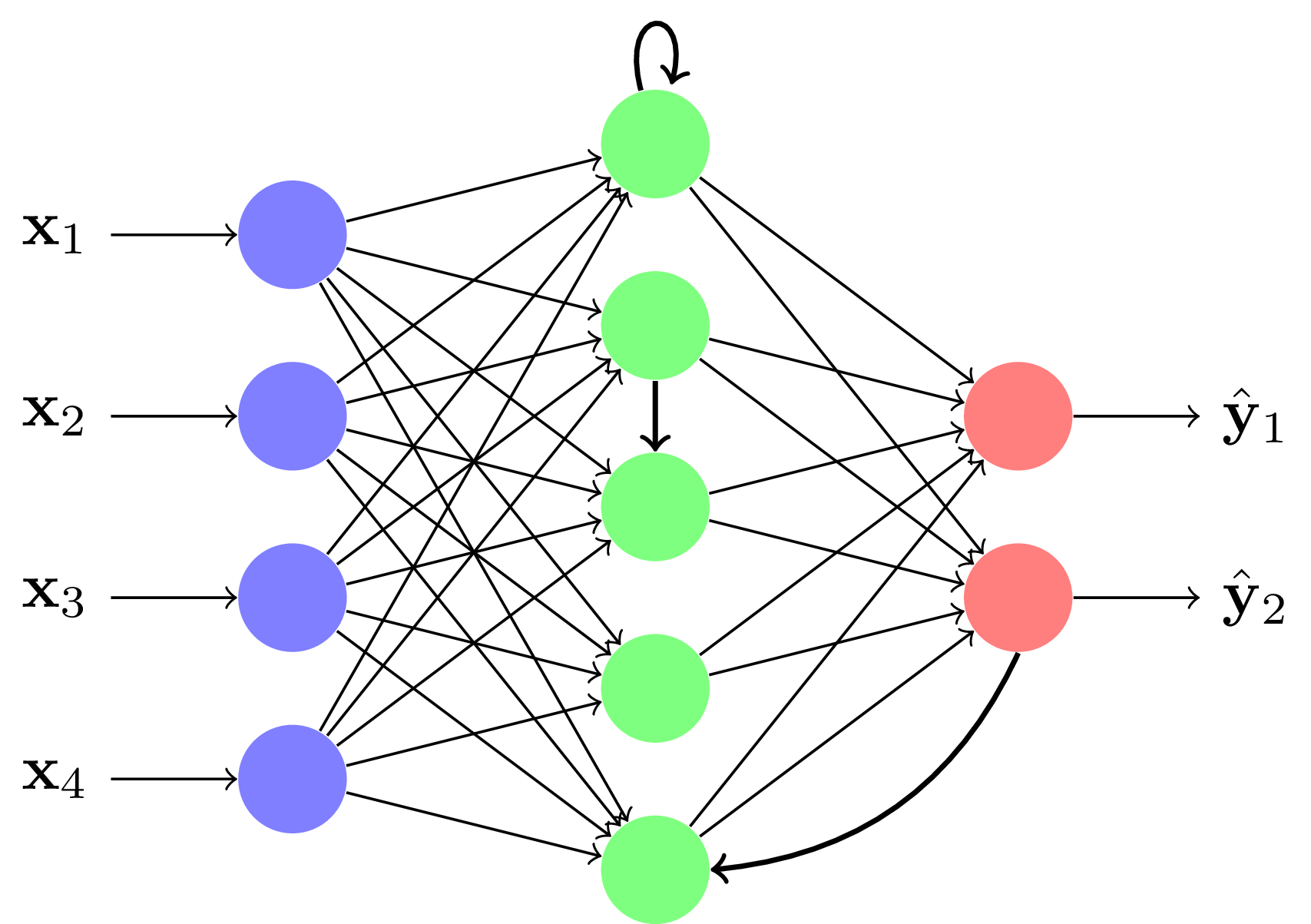
Son apprentissage n'est pas aisé. Nous nous concentrerons d'abord sur les réseaux multicouches. Les réseaux récurrents feront l'objet d'une partie propre dans ce SPOC.
Organisation en une couche
Construisons tout d'abord un réseau à une seule couche.
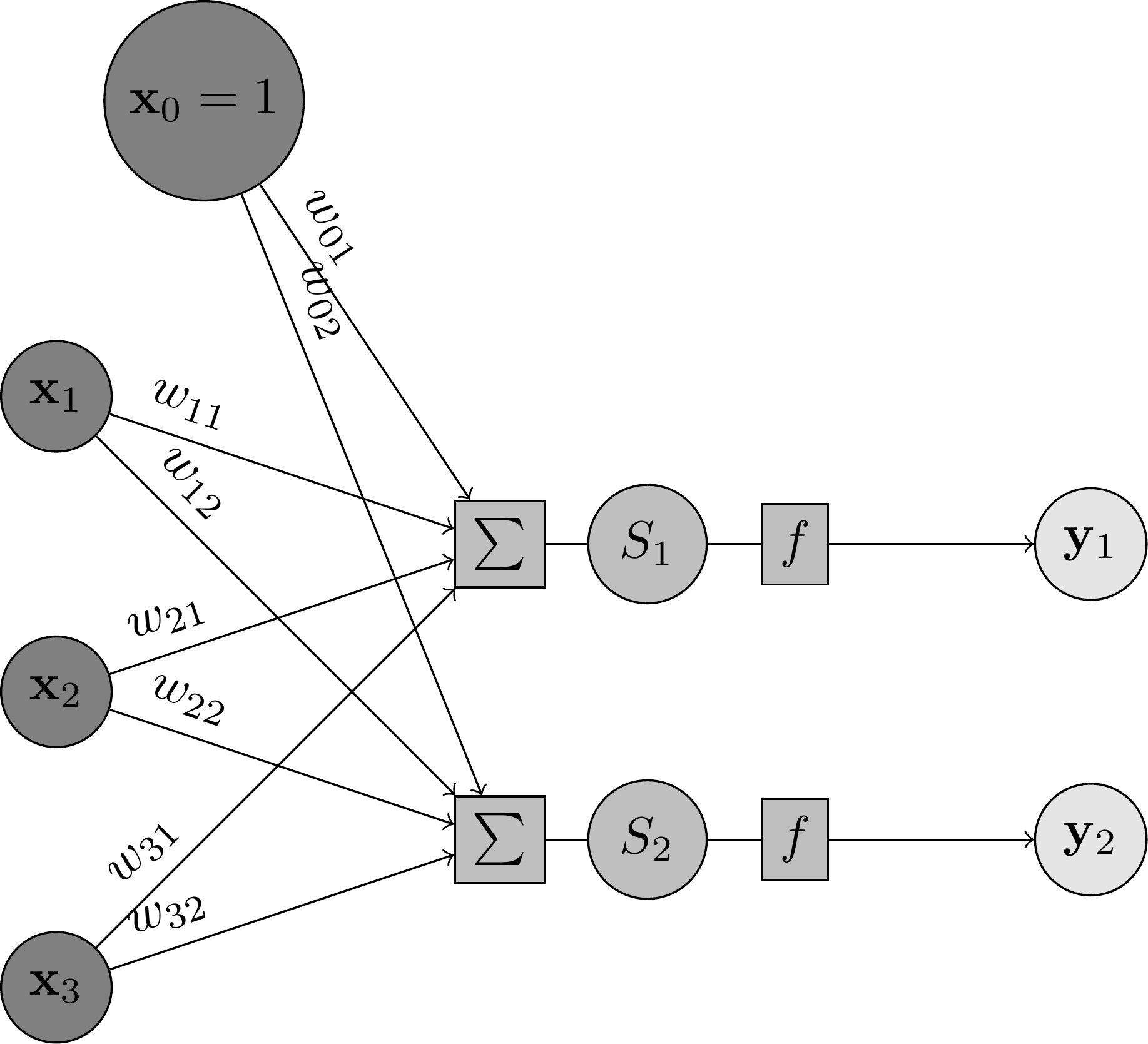
Ici, nous avons mis 2 neurones en parallèle. Les sorties de chaque neurone sont concaténées pour former un vecteur . Les entrées sont toujours un vecteur . Le calcul de la sortie se fait par les équations :
où représente la pondération entre l'entrée et la sortie . On a remplacé le biais à l'aide d'une fausse entrée qui reste constante à la valeur 1. Ainsi, correspond au biais du neurone . forme une matrice contenant les paramètres de la couche.
Comment apprendre un réseau à une seule couche ?
On applique une descente de gradient avec comme déplacement :
Organisation en plusieurs couches
Tout d'abord, nous reprenons l'organisation précédente ; seulement, nous remplaçons l'entrée par une entrée quelconque , et la sortie par une sortie quelconque . Dans la figure suivante, représente le numéro de la couche sur laquelle on se trouve :
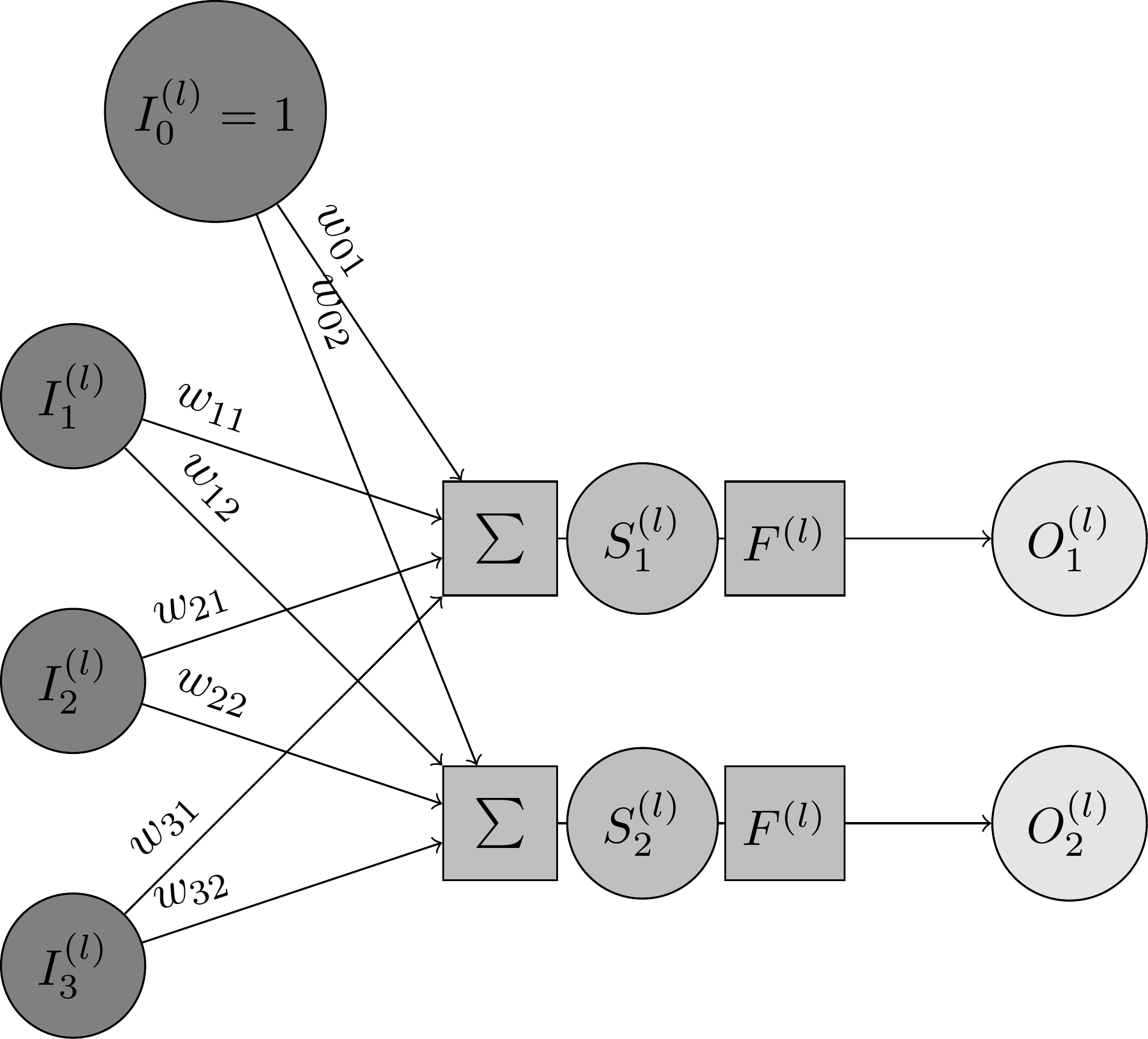
Organisation en plusieurs couches
Tout d'abord, nous reprenons l'organisation précédente ; seulement, nous remplaçons l'entrée par une entrée quelconque , et la sortie par une sortie quelconque . Dans la figure suivante, représente le numéro de la couche sur laquelle on se trouve :
En outre, pour la première couche, on aura l'entrée égale aux caractéristiques . Et pour la dernière couche, la sortie représente l'estimation de la cible :
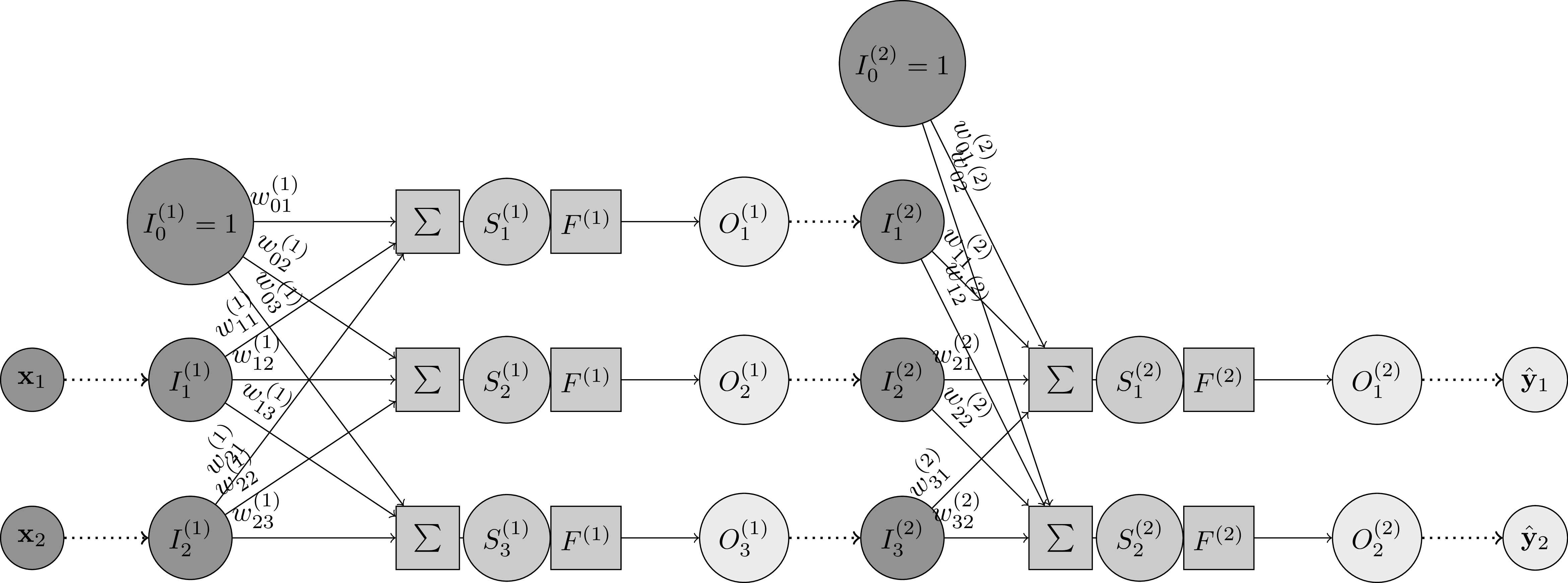
Voici le réseau final :
où est le numéro de couche.
Les équations en phase de décision pour une couche restent les mêmes. L'entrée est simplement remplacée par la sortie de la couche précédente. Et la sortie de la couche est reliée à l'entrée de la couche suivante. Formellement, cela s'écrit ainsi :
Rétropropagation du gradient
où est le numéro de couche.
Rétropropagation du gradient
Regardons ce qui se passe plus en détail sur une couche . On suppose que l'on connaît le gradient de la perte par rapport à la sortie de la couche .
Les gradients de la perte par rapport aux paramètres de la couche sont alors donnés par :
On calcule ensuite les gradients de la perte par rapport aux entrées de la couche :
On voit que l'on somme plusieurs termes. En effet, il faut prendre en compte tous les chemins entre l'entrée et toutes les sorties possibles.
Les gradients de la perte par rapport aux paramètres de la couche sont alors donnés par :
on commence par calculer le gradient des sorties de la dernière couche :
on itère le calcul des gradients sur les couches, en partant de la fin. Le gradient de l'entrée de la couche (l) étant utilisé comme gradient de la sortie de la couche précédente :
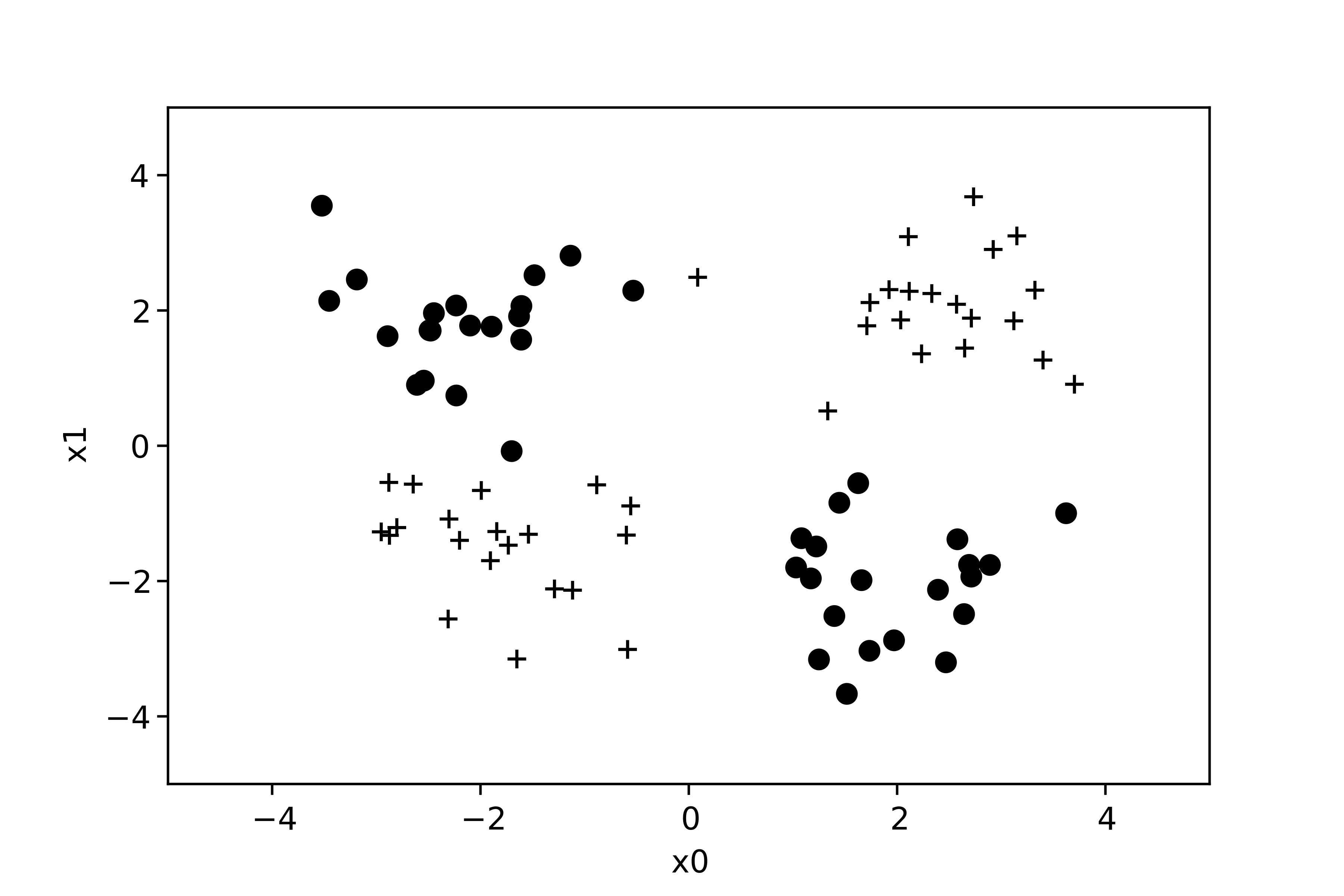
Illustration sur un jeu de données non linéairement séparable
on commence par calculer le gradient des sorties de la dernière couche :
on itère le calcul des gradients sur les couches, en partant de la fin. Le gradient de l'entrée de la couche (l) étant utilisé comme gradient de la sortie de la couche précédente :
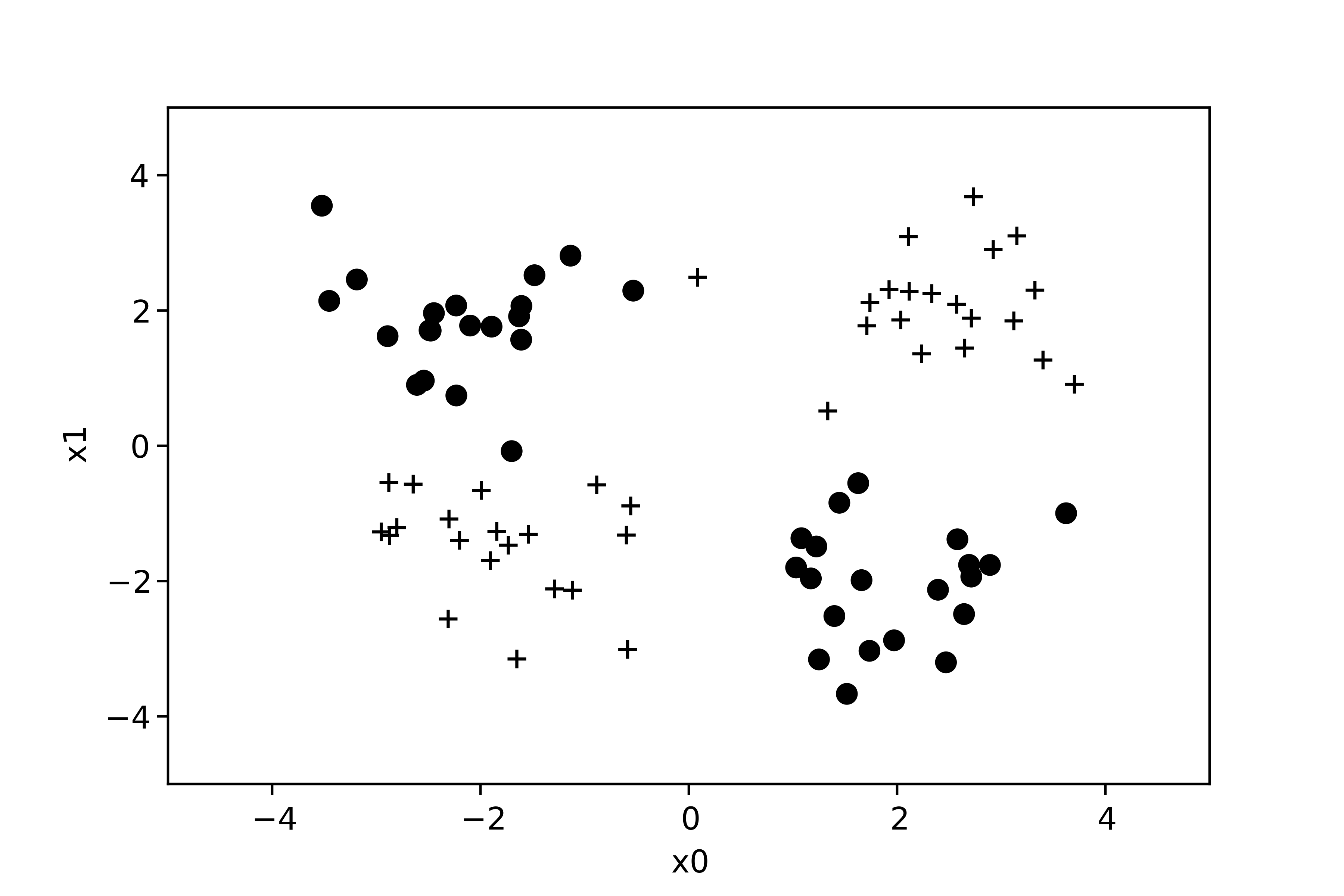
Maintenant, on peut résoudre un problème non linéairement séparable :
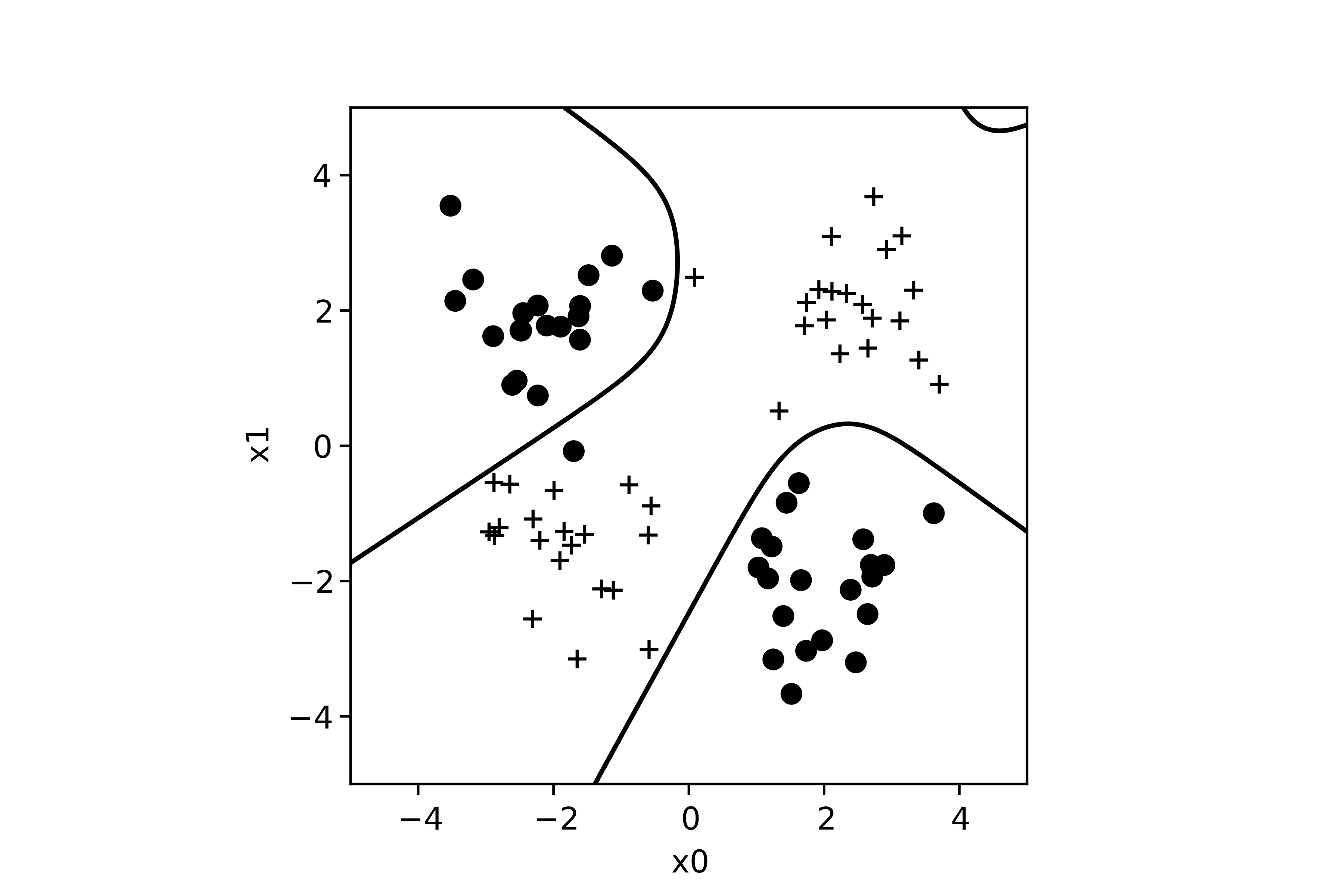
Nous avons construit un réseau contenant 3 neurones sur une première couche, et 2 neurones sur une seconde couche (comme dans l'exemple de la précédente section). Grâce à l'apport du multicouche, on peut maintenant séparer ces exemples en deux groupes :
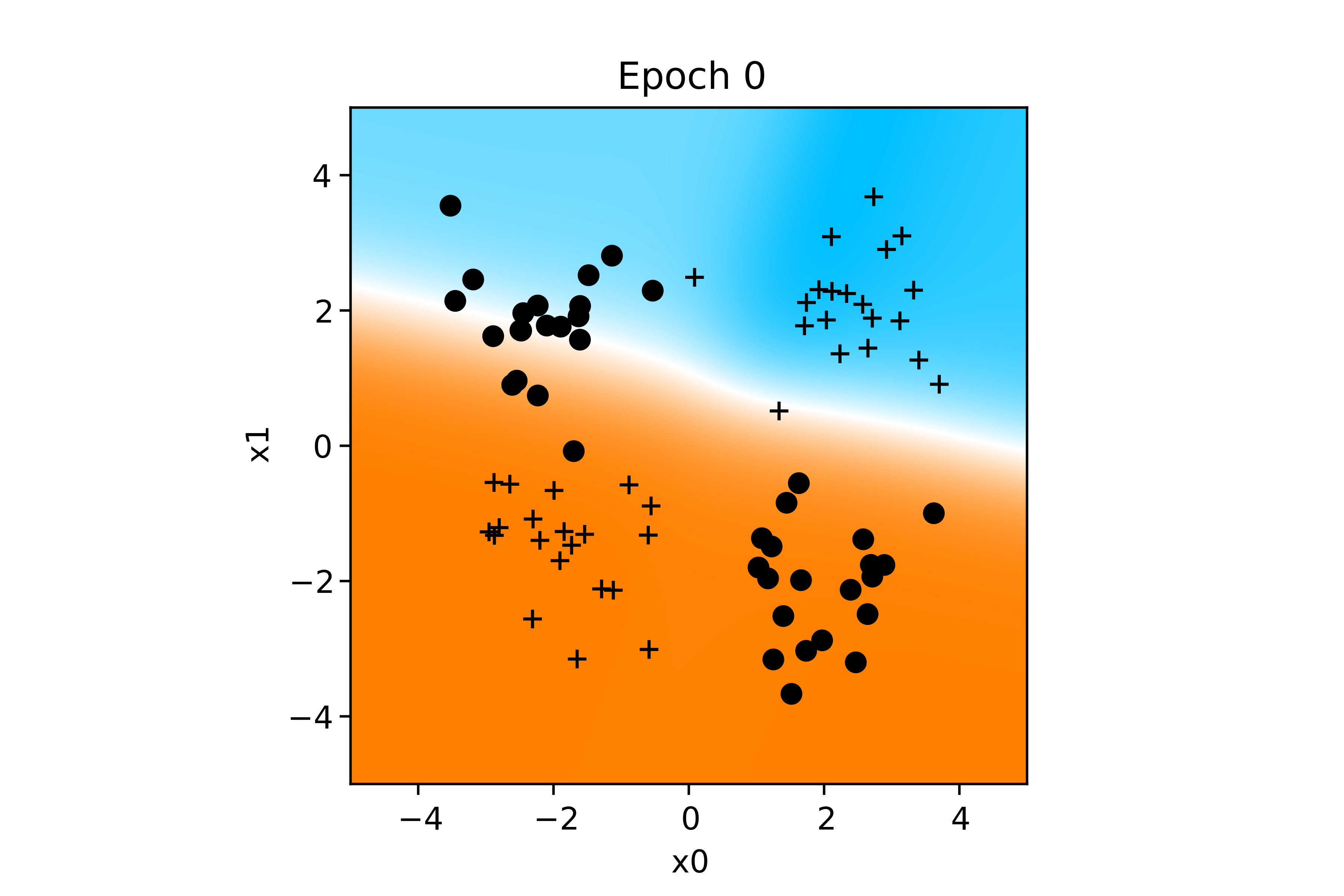
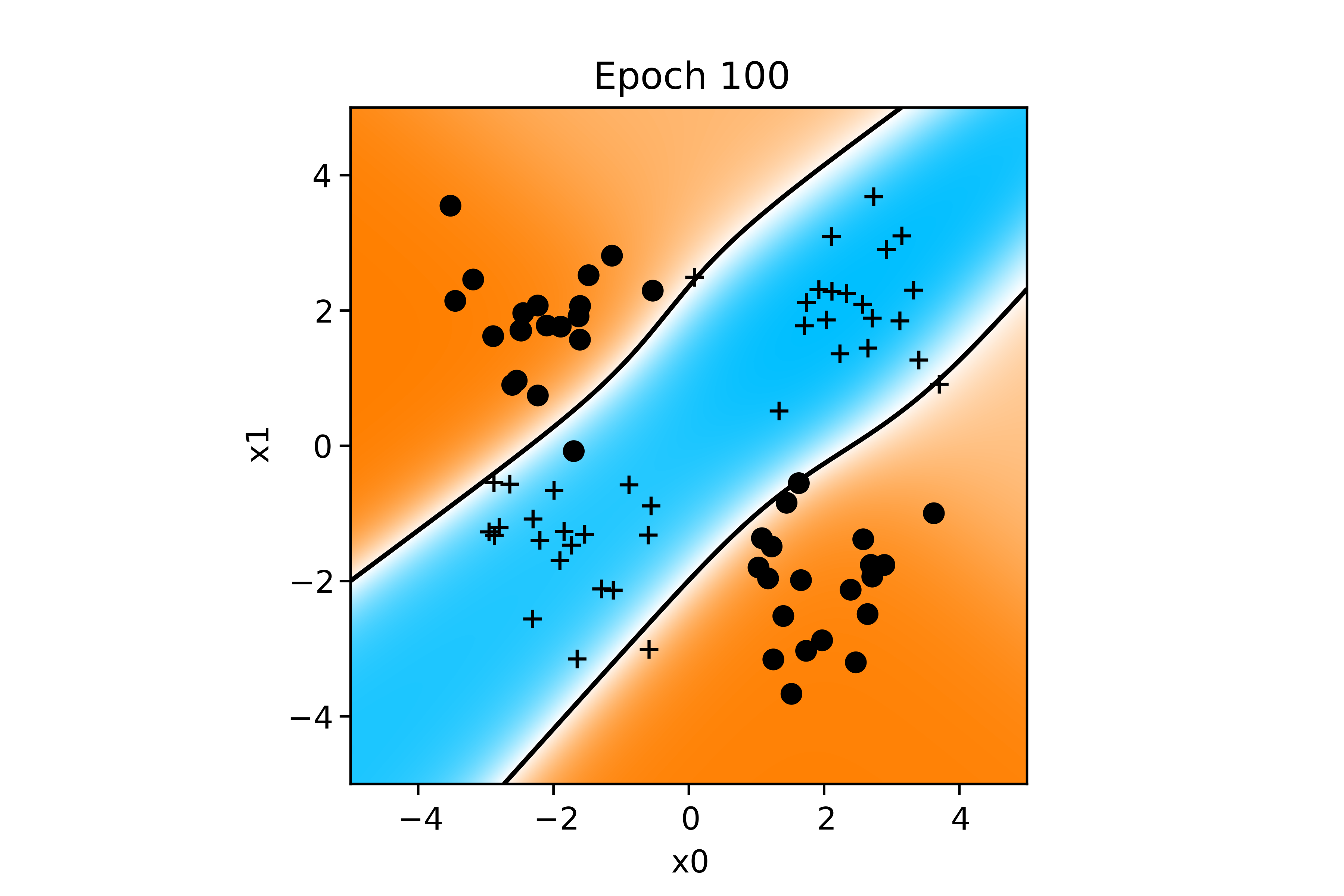
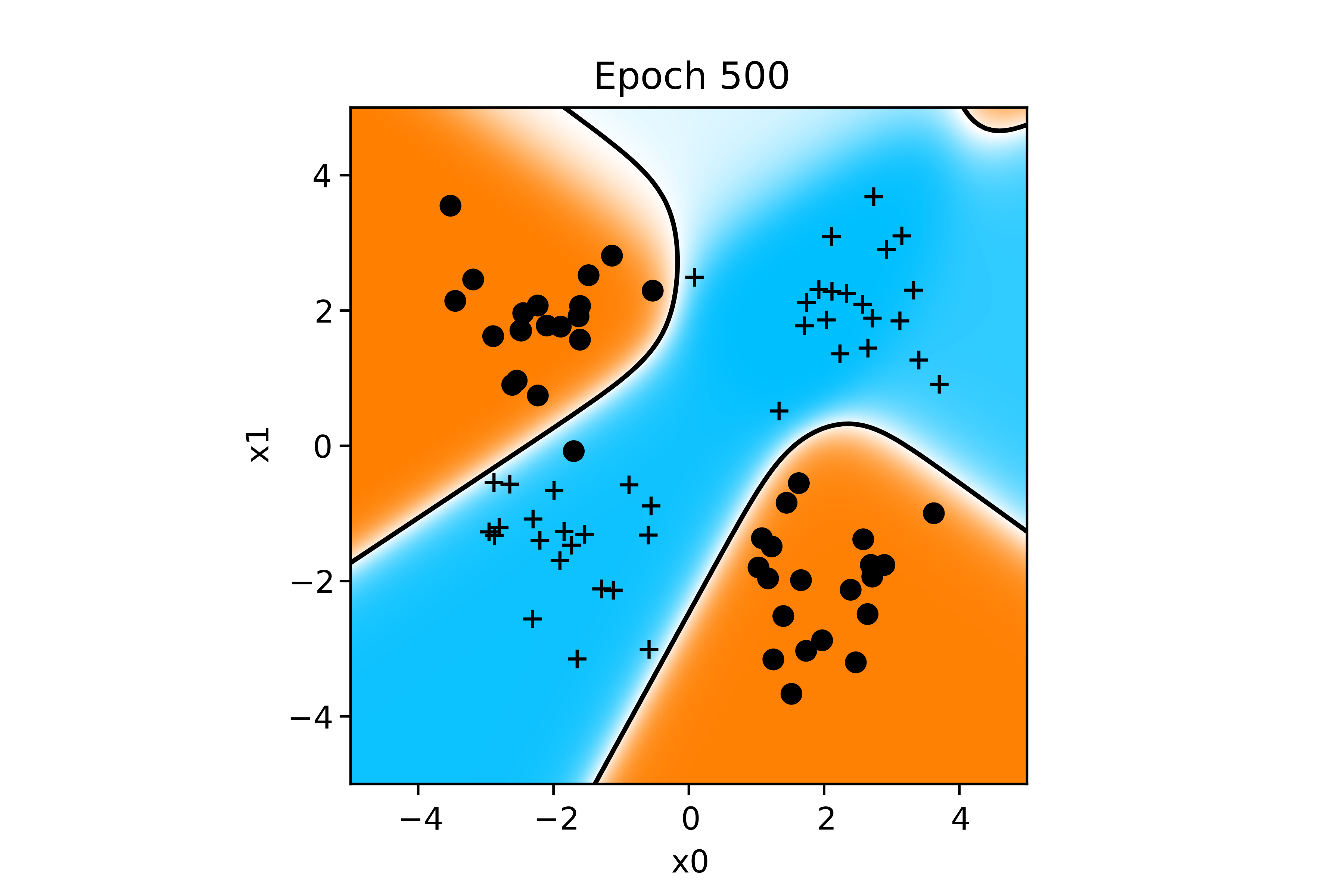
Voici l'évolution de la fonction de décision au cours de l'apprentissage :
Cliquez ici pour visualiser l'animation de l'apprentissage du PMC sur l'exemple XOR.
{kind=link}
Allez plus loin :
Article sur les réseaux de neurones artificiels.
Friedman, J., Hastie, T., & Tibshirani, R. (2001). The elements of statistical learning (Vol. 1, No. 10). New York, NY, USA: Springer series in statistics.
En résumé
Dans ce chapitre, nous avons vu qu'un neurone isolé ne peut pas résoudre de problème non-linéairement séparable. Il faut pour cela regrouper plusieurs neurones entre eux dans un réseau de neurones artificiels. Nous avons différents types de réseaux possibles, et nous nous sommes attardés sur les réseaux de neurones en couches dits perceptrons multicouches. Ce type de réseau s'apprend par un algorithme particulier, la rétropropagation du gradient.
