Construisez des architectures neuronales modulaires
Dans ce chapitre, nous allons constater que les réseaux de neurones sont des architectures modulaires, permettant d'empiler des couches diverses, entraînées avec un seul algorithme. Nous allons identifier le rôle de chaque type de couche et présenter des architectures profondes classiques sur des problèmes réels.
Jouez aux LEGO avec des réseaux de neurones
Tout au long de ce cours "Initiez-vous au Deep Learning", nous avons présenté différents types de couches de neurones, telles que les couches denses, les couches convolutionnelles, les couches récurrentes, etc.
Dans tous les chapitres de ce cours, vous avez peut-être remarqué que pour tous les types de couches, on revenait toujours à l'algorithme d'apprentissage de la rétropropagation du gradient pour apprendre les paramètres du réseau (les poids, voir premier cours, chapitre 2).
Généralisation de la rétropropagation du gradient
Afin de bien comprendre qu'on peut empiler les couches sans se préoccuper de leur nature pour l'apprentissage, il est important de faire un point sur la généralisation de la rétropropagation du gradient.
La figure suivante permet de s'affranchir de la nature de la couche, comme présenté dans le cours de Y. Lecun au collège de France. Les fonctions sont soit des sommes pondérées (couches linéaires paramétrées par ), soit des fonctions d'activation (ReLU, tanh, etc. ; dans ce cas elles n'ont pas de paramètres ) :
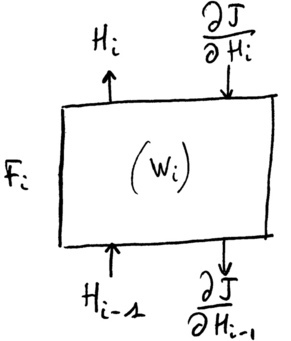
En phase de décision (de bas en haut sur le schéma), on propage l'information des entrées vers les sorties, en calculant simplement les successifs, :
En phase d'apprentissage, on calcule successivement les gradients de l'erreur depuis la sortie vers l'entrée (du haut vers le bas sur le schéma) :
Le terme bleu provenant de la couche précédente, et le terme magenta étant facilement calculable en fonction du type de couche considéré.
Maintenant que nous savons "empiler des couches" et les apprendre, faisons le point sur les différents types de couches et identifions le contexte dans lequel il faut les utiliser.
Intérêt des différents types de couches
Couches denses, pour décider
Les couches denses sont les couches "historiques" des réseaux de neurones feedforward. Elles consistent en une interconnexion totale entre une couche de neurones et la suivante.
Comme leur nom l'indique (elles sont aussi appelées fully connected), ces couches sont assez "lourdes", car elles comportent beaucoup de paramètres.
Les couches denses doivent être utilisées afin de prendre une décision, qu'il s'agisse d'une classification ou d'une régression. Elles sont donc généralement utilisées comme dernière(s) couche(s) d'un modèle.
Couches convolutionnelles, pour caractériser
Les couches convolutionnelles (voir cours 1, chapitre 3) sont beaucoup plus légères, puisqu'elles ne comportent que les poids liés aux filtres (dont la taille est généralement réduite, par exemple ou ), multipliés par quelques dizaines de filtres.
Rappelons que les couches convolutionnelles sont souvent utilisées avec des couches de pooling, afin de concentrer l'information.
Les filtres appris par les couches convolutionnelles peuvent être considérés comme des extracteurs de caractéristiques ; ils sont donc souvent utilisés dans les couches basses des réseaux, afin d'apprendre des représentations adaptées à la fonction de décision considérée.
À titre illustratif, la figure suivante présente un modèle convolutionnel dédié au texte présenté dans l'article "Convolutional neural networks for sentence classification" [1]. Le modèle comporte 4 parties :
la première consiste à encoder les mots sous la forme d'une représentation numérique de taille fixe ;
la seconde est constituée des fameux filtres convolutionnels ;
la troisième réalise une opération de pooling sur l'axe temporel ;
la dernière est une couche dense traditionnelle permettant de classifier le texte.
![Exemple de CNN appliqué à du texte pour la classification de phrase courte (image issue de [2])](https://user.oc-static.com/upload/2019/04/19/15556801636436_cnntext.png)
Couches récurrentes, pour modéliser les dépendances...
Comme nous l'avons vu tout au long de ce chapitre, les RNN permettent de modéliser les dépendances au sein d'un signal.
Ils sont donc adaptés pour tous les problèmes impliquant des séquences. En revanche, les couches récurrentes sont lourdes à cause des connexions récurrentes, notamment dans le cas de l'utilisation de cellule LSTM plus performante.
... ou pour générer des séquences
Voici un exemple de tutoriel pour générer du texte à partir d'un apprentissage du livre Alice au pays des merveilles de Lewis Carroll : lien (en anglais).
Exemple d'architectures "LEGO"
Dans cette section, nous allons analyser certains modèles profonds "classiques" pour traiter des problèmes donnés. Ils sont tous constitués des types de couches standard résumés ci-dessus.
Exemple de modèle profond pour la classification d'images
Plusieurs architectures profondes ont été proposées pour traiter l'immense base "ImageNet", qui contient plus de 14 millions d'images de scènes naturelles (animaux, véhicules, personnes, etc.).
L'une des plus connues s'appelle VGG, proposée dans l'article en anglais "Very deep convolutional networks for large-scale image recognition" [2], destinée à la classification d'images et représentée ci-dessous.
![Modèle profonf proposé par [2] pour la classification d'images](https://user.oc-static.com/upload/2019/04/19/15556818341178_vgg16.png)
Compte tenu de la tâche à effectuer, les choix suivants ont été faits :
les couches basses sont des couches convolutionnelles (en noir dans la figure ci-dessus) pour caractériser les images. Chaque couche possède plusieurs filtres, conduisant à plusieurs cartes de caractéristiques (souvent appelés channels en anglais). Dans la notation , les deux premiers nombres désignent la taille des cartes, et le troisième désigne le nombre de cartes. La version VGG16 comporte 16 couches convolutionnelles ;
les couches convolutionnelles sont alternées avec des couches de max pooling (en rouge) (ici 2 x 2) qui réduisent la taille des cartes de caractéristiques pour concentrer l'information spatiale ;
afin de classifier les images, 3 couches denses (fully connected, en bleu) sont appliquées en sortie des couches convolutionnelles. La dernière fonction d'activation est une "softmax" (en marron) qui permet d'estimer des probabilités a posteriori.
Exemple de modèle profond pour la reconnaissance d'écriture
Un autre exemple d'application est la reconnaissance d'écriture. Dans l'article en anglais "Are Multidimensional Recurrent Layers Really Necessary for Handwritten Text Recognition?" [3], les auteurs proposent un modèle assez classique pour cette tâche, présenté ci-dessous.
![Modèle proposé dans [2] pour la reconnaissance d'écriture manuscrite.](https://user.oc-static.com/upload/2019/04/19/1555681272339_cnn-lstm.png)
Le modèle comporte quatre parties :
l'image d'entrée (Input image) est soumise à des blocs convolutifs avec batch normalization, activation leaky ReLU et max pooling (Convolution + BatchNorm + leaky ReLU + Max Pool) ;
les sorties du bloc précédent sont ensuite concaténées par colonne (Columnwise concat) ;
puis soumises à des blocs récurrents (BLSTM + depth concat) ;
la dernière couche du modèle est naturellement une couche dense (appelée linear sur le schéma) associée à une fonction d'activation softmax pour réaliser la classification en caractères des séquences d'entrée.
L'architecture proposée n'est pas très éloignée du modèle précédent pour la classification d'images. Le modèle est également composé de couches convolutionnelles alternées avec des couches de max pooling sur les couches basses, destinées à extraire des caractéristiques.
La réelle différence avec le modèle VGG est la présence d'une couche BLSTM destinée à traiter l'aspect séquentiel de l'écriture manuscrite.
Exemple de modèle profond pour la génération de légende
Le dernier modèle présenté est le plus complexe. Il est destiné à réaliser la tâche suivante :
"étant donné une image, on cherche à générer une légende décrivant la scène".
L'architecture proposée sur le schéma suivant est composée de plusieurs modules :
1) image d'entrée, 2) extraction de caractéristiques convolutionnelles, 3) réseau récurrent avec modèle d'attention sur l'image, et 4) génération mot par mot.
![architecture proposée dans [4] pour la génération de légende](https://user.oc-static.com/upload/2019/04/19/15556847347972_caption-petit.png)
le premier module est un module caractérisant l'image. Il est naturellement composé de couches convolutionnelles et de pooling, comme dans les autres modèles présentés ci-dessus ;
le dernier module est un module permettant de générer la description textuelle de l'image. Il s'agit d'un réseau de neurones récurrent de type LSTM, utilisé en mode génératif. Il génère itérativement chaque nouveau mot à ajouter à la légende. Ce réseau réalise donc une tâche de classification parmi tous les mots de la langue, anglaise en l'occurrence. Un mot "fin de légende" est ajouté à cette liste pour décider quand la légende est terminée ;
le troisième module permet de "relier" les deux autres modules : il s'agit d'un modèle d'attention. Il permet de présenter au modèle génératif la meilleure partie de l'image, en fonction du contexte, pour chaque nouveau mot. Par exemple, le modèle d'attention va se porter sur les ailes d'un oiseau au moment de sortir le mot "flying" (voler). L'implémentation du modèle d'attention est réalisée par un modèle récurrent, généralement de type LSTM. Nous renvoyons à l'article en anglais "Show, attend and tell: Neural image caption generation with visual attention" [4] pour une description plus détaillée du modèle d'attention.
Concernant l'apprentissage du modèle, il est réalisé en plusieurs étapes. Le modèle convolutionnel est un modèle préappris sur la base ImageNet, et le modèle génératif est également préappris sur une très grosse base de texte telle que Wikipedia. L'apprentissage du système complet, y compris le modèle d'attention, est finalisé sur une base de couples (image, légende) annotés.
Allez plus loin
[1] Kim, Y. (2014). Convolutional neural networks for sentence classification. arXiv preprint arXiv:1408.5882.
[2] Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
[3] Joan Puigcerver: Are Multidimensional Recurrent Layers Really Necessary for Handwritten Text Recognition? ICDAR 2017: 67-72
[4] Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhudinov, R., ... & Bengio, Y. (2015, June). Show, attend and tell: Neural image caption generation with visual attention. In International conference on machine learning (pp. 2048-2057).
En résumé
Dans ce chapitre, nous avons synthétisé le rôle de chaque type de couche. Nous avons montré qu'une architecture adaptée pouvait être mise en place pour traiter des problèmes variés. Il suffit pour cela :
d'empiler les couches adéquates ;
d’entraîner le modèle ainsi construit par la rétropropagation du gradient.
Nous avons ensuite présenté trois modèles classiques pour la reconnaissance d'image, la reconnaissance d'écriture manuscrite et la génération de légende à partir d'une image.
Vous êtes arrivé à la fin de ce cours, félicitations ! Vous avez à présent tous les éléments en main pour :
expliquer les principes de base des réseaux de neurones artificiels ;
mettre en place un modèle de Deep Learning ;
adapter les paramètres d'un modèle de Deep Learning afin de l'améliorer.
N'oubliez pas de réaliser les exercices qui se trouvent à la fin de chaque partie pour valider ces compétences. À vous de jouer, maintenant !
