Mettez en place un Data Lake sous AWS S3
Rappelez-vous des points essentiels d’Amazon S3
Avant de plonger dans la pratique avec Python, rappelons les points essentiels vus dans le cours AWS :
Qu’est-ce qu’Amazon S3 ?
Amazon S3 (Simple Storage Service) est un service de stockage objet proposé par AWS.Il permet de stocker tout type de données (CSV, JSON, images, vidéos, logs, etc.).
Il est hautement scalable (de quelques fichiers à des pétaoctets).
Il est économique et durable, conçu pour la haute disponibilité et la résilience.
Stockez et accédez à des fichiers
Les données sont organisées dans des buckets, qui fonctionnent comme de grands dossiers. Chaque fichier est identifié par une clé unique (chemin/fichier).
Vous pouvez interagir avec vos fichiers via :la console AWS,
la CLI (aws s3 cp, aws s3 ls),
des SDKs comme Boto3 (ce que nous allons utiliser ici).
Sécurité et bonnes pratiques
Par défaut, vos buckets sont privés.
Vous pouvez définir des politiques de bucket et des règles d’accès fines.
Le chiffrement (SSE-S3, SSE-KMS) est recommandé pour protéger vos données sensibles.
Les règles de cycle de vie permettent d’automatiser archivage et suppression.
Droits d’accès et gouvernance
L’accès se gère via IAM (Identity and Access Management).Vous définissez qui peut accéder à quoi (utilisateur, rôle, application).
Appliquez le principe du moindre privilège : donner uniquement les droits nécessaires.
Comprenez l'interaction entre Python et AWS
Pour piloter AWS depuis Python, vous utiliserez Boto3, le SDK officiel AWS.
Boto3 permet de :
s’authentifier auprès des services AWS,
créer et gérer des ressources (ex. un bucket S3),
manipuler vos fichiers (upload, download, list, delete).
Authentification avec Boto3
Pour interagir avec AWS, Boto3 doit savoir qui vous êtes. Il existe plusieurs façons de fournir vos identifiants AWS, voici les plus courantes :
1. Variables d’environnement
export AWS_ACCESS_KEY_ID=your_access_key_id
export AWS_SECRET_ACCESS_KEY=your_secret_access_key2. Fichiers de configuration (méthode recommandée)
Configurez votre profil via la CLI :
aws configureCela enregistre vos identifiants dans ~/.aws/credentials et ~/.aws/config.
3. Directement dans le code (déconseillé en production)
import boto3
client = boto3.client(
's3',
aws_access_key_id='your_access_key_id',
aws_secret_access_key='your_secret_access_key'
)👉 À éviter car cela expose vos clés (ex. si le code est versionné dans GitHub).
Bonnes pratiques sécurité :
Utilisez les fichiers de configuration ou IAM Roles,
Ne stockez jamais vos clés directement dans le code,
Donnez toujours le minimum de droits nécessaires.
Maîtrisez les librairies Python pour Amazon S3
Maintenant que vous savez comment authentifier Python auprès d’AWS, voyons comment manipuler concrètement Amazon S3 avec Boto3.
Amazon S3 est un service de stockage objet : cela signifie que vous ne manipulez pas des “fichiers” comme sur votre ordinateur, mais des objets stockés dans des buckets. Chaque objet est identifié par une clé (qui ressemble à un chemin de fichier).
Avec Boto3, l’interaction est très simple : vous pouvez créer un bucket, y déposer un fichier, ou encore lister son contenu.
Commençons par créer un bucket.
import boto3
# Création d'un client S3
s3 = boto3.client('s3')
# Nom du bucket (doit être unique globalement dans AWS)
bucket_name = "openclassrooms-datalake-8481716"
# Création du bucket
s3.create_bucket(Bucket=bucket_name)
print(f"Bucket {bucket_name} créé avec succès.")Une fois le bucket créé, vous pouvez y déposer des données. Imaginons que vous ayez un fichier local ventes.csv :
s3.upload_file("ventes.csv", bucket_name, "raw/current/ventes.csv")
print("Fichier CSV envoyé dans raw/current.")Remarquez que nous avons choisi d’organiser le bucket avec un dossier logique raw/current/.
En réalité, S3 n’a pas de dossiers réels : ce sont des préfixes dans les clés. Mais cette convention d’organisation est très utilisée en Data Engineering, car elle permet de séparer clairement les zones (raw, processed, archived…).
Enfin, vous pouvez vérifier que le fichier est bien stocké en listant les objets du bucket :
resp = s3.list_objects_v2(Bucket=bucket_name, Prefix="raw/")
for obj in resp.get("Contents", []):
print(" -", obj["Key"])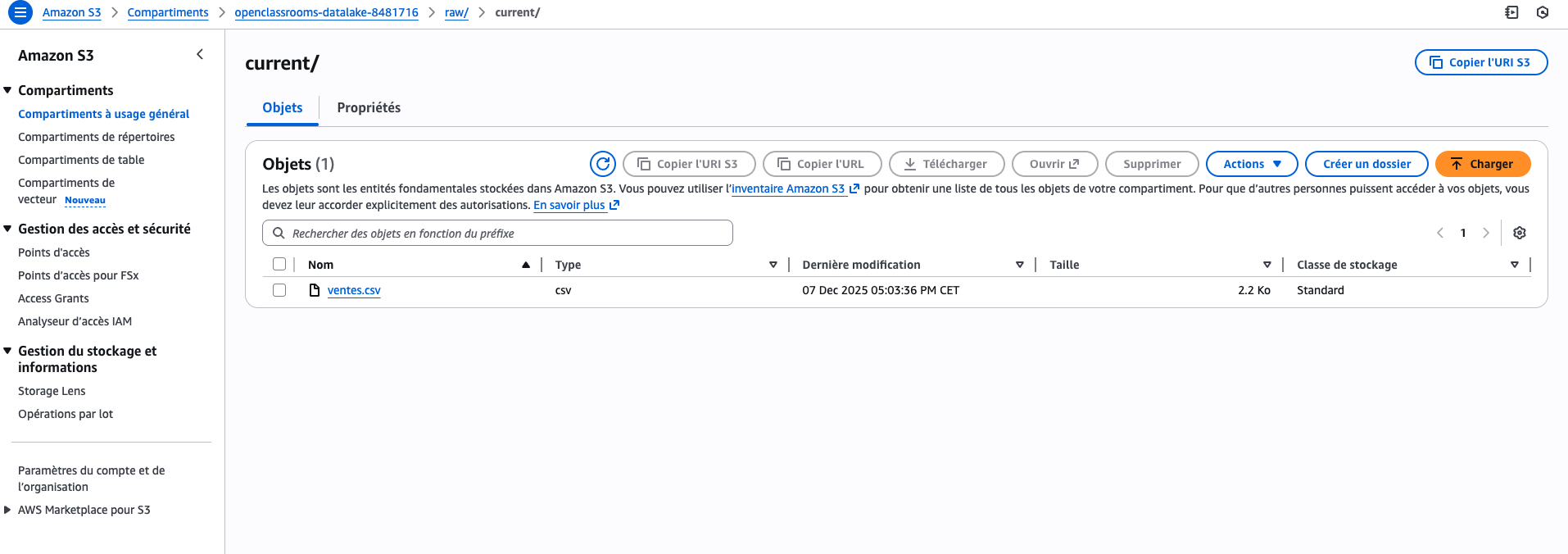
Vous devriez voir apparaître votre fichier, avec l’arborescence raw/current/ dans votre bucket précédemment créé (ici via la console aws).
À ce stade, vous savez donc :
créer un bucket,
y stocker un fichier,
et vérifier son contenu.
Ce sont les bases indispensables pour commencer à construire un Data Lake sur S3.
Dans ce screencast, vous verrez comment l’équipe de GreenFarm fait interagir son code Python avec l’infrastructure AWS. À partir d’un simple script, vous découvrirez comment une application peut créer un bucket S3, y stocker des fichiers et interroger ses ressources de manière sécurisée.
Contenu de la démonstration :
Vérification de la configuration AWS CLI et explication du fonctionnement des identifiants
Installation et utilisation de la librairie Boto3
Création d’un client S3 à partir de la configuration locale
Liste des buckets existants dans le compte AWS
Création d’un bucket dédié au projet GreenFarm
Upload d’un fichier local (
sample.txt) dans une structure logique (raw/current/…)Listing des objets présents dans le bucket pour vérifier l’opération
Créez un flux de données dans Amazon S3
Un Data Lake n’est pas simplement une boîte où l’on stocke des fichiers : il s’intègre dans un flux de traitement.
Les données brutes y arrivent, puis elles sont progressivement nettoyées, transformées et organisées dans différentes zones du Data Lake, afin de pouvoir être utilisées ensuite par des analystes ou des applications.
Dans ce qui suit, nous allons mettre en place un pipeline simple qui illustre ce principe.
Nous allons distinguer deux zones dans notre bucket :
raw/ : où arrivent les fichiers bruts (par ex. un export CSV d’une base de données).
processed/ : où l’on dépose les fichiers transformés dans un format plus adapté à l’analyse (par ex. Parquet).
Ici, pour simplifier, nous allons déposer directement un fichier CSV et le traiter avec Python.
Étape 1 – Lire le fichier brut
Imaginons que vous ayez reçu un fichier ventes.csv dans raw/current/.
Commençons par le lire avec pandas :
import pandas as pd
import pyarrow
df = pd.read_csv("ventes.csv")
print(df.head())Cette première étape est très importante : elle permet de valider le contenu avant tout traitement.
Étape 2 – Transformer le fichier
Appliquons une transformation très simple : suppression des lignes contenant des valeurs manquantes.
df = df.dropna()Bien sûr, dans un vrai pipeline, vous pourriez faire beaucoup plus :
nettoyage des types de colonnes,
ajout de colonnes calculées,
filtrage des données inutiles…
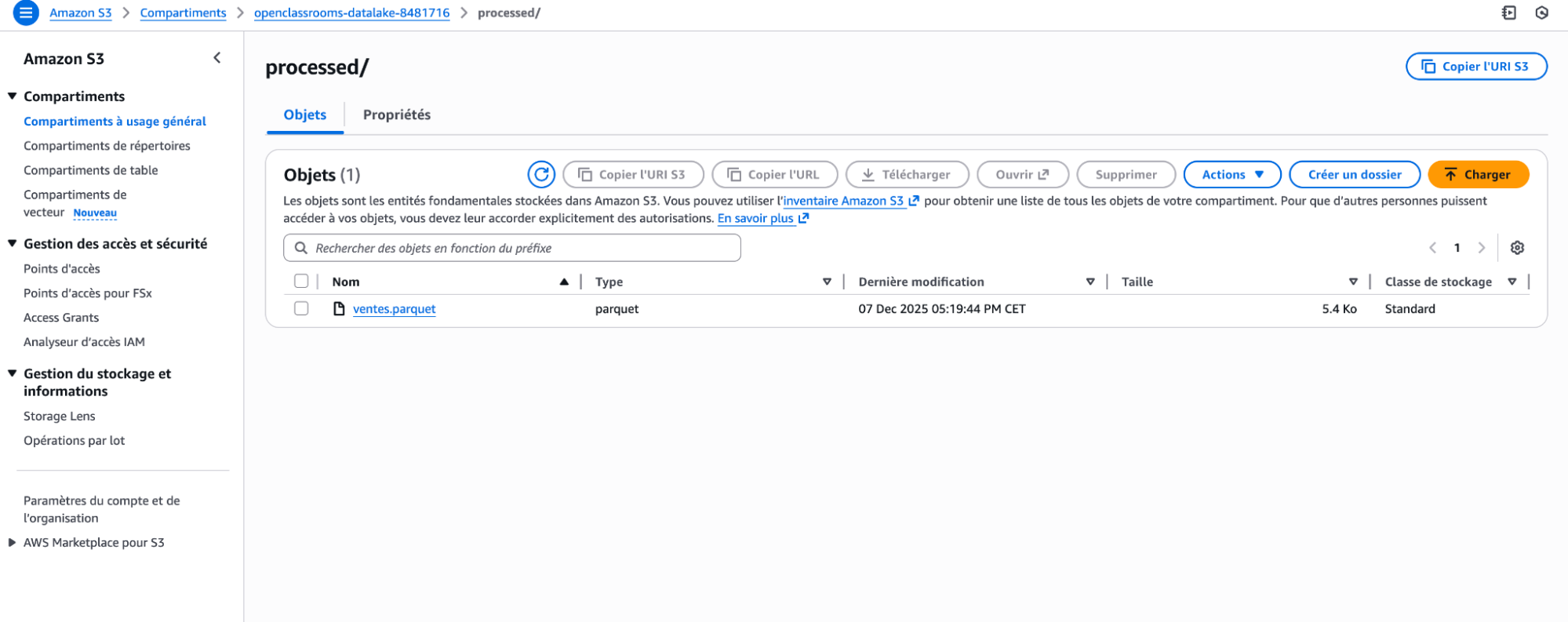
Étape 3 – Sauvegarder dans processed
Une bonne pratique est de stocker les données transformées dans un format colonnaire comme Parquet, qui est beaucoup plus efficace que CSV pour l’analyse.
df.to_parquet("ventes.parquet")
s3.upload_file("ventes.parquet", bucket_name, "processed/ventes.parquet")
print("Fichier transformé et déposé dans processed.")À ce stade, vous avez un premier pipeline raw → processed.
Allons plus loin : archiver les fichiers bruts
Dans un vrai Data Lake, vous allez recevoir régulièrement de nouveaux fichiers bruts.
Si vous laissez tous les fichiers dans raw/current/, cette zone va vite devenir illisible et difficile à gérer.
👉 Une bonne pratique consiste à déplacer les fichiers bruts vers une zone archived/ une fois qu’ils ont été traités.
Cela permet de :
garder raw/current/ toujours propre (uniquement les fichiers en attente de traitement),
conserver un historique complet dans raw/archived/,
assurer la traçabilité et l’audit.
Exemple :
import datetime
raw_key = "raw/current/ventes.csv"
local_file = "ventes.csv"
# Télécharger le fichier brut
s3.download_file(bucket_name, raw_key, local_file)
# Transformer et déposer dans processed
df = pd.read_csv(local_file).dropna()
df.to_parquet("ventes.parquet")
s3.upload_file("ventes.parquet", bucket_name, "processed/ventes.parquet")
# Archiver le fichier brut
timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
archived_key = f"raw/archived/ventes_{timestamp}.csv"
s3.copy_object(
Bucket=bucket_name,
CopySource={"Bucket": bucket_name, "Key": raw_key},
Key=archived_key
)
s3.delete_object(Bucket=bucket_name, Key=raw_key)Votre flux ressemble donc à ceci :
raw/current/ → (traitement) → processed/ + raw/archived/
Une fois toutes les exécutions lancées, vous devriez voir un fichier ventes.parquet dans l’arborescence processed/ et un ventes.csv dans raw/archived/.
Ce pattern est très répandu en entreprise : il vous permet de séparer les données prêtes à traiter, les données traitées et l’historique.
À vous de jouer !

Contexte
GreenFarm continue sa croissance et souhaite mieux exploiter ses données pour optimiser ses cultures et sa distribution. Jusqu’ici, vous avez mis en place un flux de démonstration avec un petit fichier de ventes.
Désormais, l’entreprise vous confie une nouvelle mission concrète : intégrer des données issues de ses capteurs IoT installés dans les champs. Ces capteurs collectent régulièrement des informations comme la température, l’humidité du sol ou le taux d’ensoleillement.
Ces données sont exportées chaque jour sous forme de fichier JSON que vous allez recevoir (fichier fourni pour l’exercice).
Consignes
Créez un bucket greenfarm-datalake-demo-xxx, , où xxx est à remplacer par vos initiales ou un identifiant personnel (exemple : greenfarm-datalake-demo-jd34). Attention : Les noms de buckets S3 sont globaux : si deux personnes utilisent le même, une erreur sera levée.
Déposez le fichier JSON fourni dans la zone raw/current/.
Écrivez un script Python qui :
lit le fichier brut JSON avec pandas ou via le module json,
applique une transformation utile (par exemple :
convertir la date au bon format,
renommer certaines colonnes pour plus de clarté,
calculer une colonne supplémentaire comme la moyenne glissante de la température),
sauvegarde le résultat en Parquet dans processed/.
Une fois le traitement terminé, déplacez le fichier brut dans raw/archived/ en conservant l’horodatage.
Résultat attendu : votre code python
En résumé
Amazon S3 permet de stocker tout type de fichiers dans des buckets, avec une structure organisée par clés (similaires à des chemins).
Avec Boto3 en Python, vous pouvez facilement créer un bucket, envoyer, lister ou télécharger des fichiers.
L’authentification sécurisée se fait via la CLI AWS ou IAM ; évitez de mettre vos clés directement dans le code.
Un pipeline type en Data Lake suit le schéma : raw/current/ → traitement (ex. avec pandas) → processed/.
Les fichiers bruts sont ensuite archivés dans raw/archived/ pour garder une zone de travail claire et tracer l’historique.
GreenFarm dispose désormais d’un premier Data Lake opérationnel sur AWS S3. Mais l’entreprise réfléchit aussi à une solution plus indépendante du cloud et open source, qui pourrait être déployée localement ou dans un environnement hybride. Pour répondre à ce besoin, vous allez maintenant découvrir comment mettre en place un Data Lake basé sur MinIO, tout en conservant la compatibilité avec l’API S3.
