Mettez en place une architecture Lakehouse avec Databricks

Au début de son projet data, GreenFarm s’appuyait sur des traitements Python simples pour exploiter les données issues de ses capteurs agricoles. Les volumes restaient raisonnables, et des scripts batch ou des traitements déclenchés à la demande suffisaient largement.
Cette approche correspond déjà à un pattern Lakehouse :
stockage sur un data lake,
format de table ouvert (Delta Lake),
traitements batch en Python,
données versionnées et historisées.
Mais avec le temps, le contexte évolue. Chaque parcelle agricole génère désormais plusieurs milliers de mesures par jour. À l’échelle de toute l’exploitation, GreenFarm collecte des millions de lignes quotidiennes, auxquelles s’ajoutent :
des données météo historiques,
des données de drones,
des traitements analytiques de plus en plus fréquents.
À ce stade, les traitements Python locaux deviennent plus longs, plus coûteux à maintenir, et plus fragiles. GreenFarm doit donc se poser une nouvelle question :
Comment continuer à exploiter ce Lakehouse lorsque les volumes, la fréquence des traitements et le nombre d’utilisateurs augmentent fortement ?
C’est ici que le calcul distribué entre en jeu.
Passez le Lakehouse à l’échelle
Mettre en place un Lakehouse ne signifie pas forcément utiliser un moteur de calcul distribué dès le départ, ni être limité à des usages non critiques. Un Lakehouse peut parfaitement être exploité en production avec :
des scripts Python,
des jobs batch planifiés,
ou des fonctions serverless déclenchées à la demande,
Tant que l’on s’appuie sur :
un stockage objet,
des formats de tables ouverts et transactionnels,
des mécanismes de versioning et d’historisation.
C’est d’ailleurs ainsi que GreenFarm a structuré ses premiers traitements. Cependant, à mesure que les volumes augmentent et que les usages se multiplient, certains signaux apparaissent progressivement :
les données deviennent difficiles à traiter sur une seule machine;
les temps de calcul ne sont plus compatibles avec les contraintes métier;
plusieurs pipelines doivent s’exécuter en parallèle ;
la fiabilité et la répétabilité des traitements deviennent critiques.
À ce stade, la question n’est plus comment optimiser le code, mais :
Le modèle d’exécution est-il encore adapté à l’échelle atteinte ?
C’est dans ce contexte que le calcul distribué devient particulièrement pertinent.
Traitez les données à grande échelle avec Apache Spark
Apache Spark est un moteur de calcul distribué dont le rôle est de traiter efficacement de grands volumes de données. Spark ne stocke pas les données. Il s’appuie sur le data lake et sur les formats de tables déjà en place, comme Delta Lake, pour exécuter les traitements au plus près des données.
Concrètement, Spark fonctionne sous la forme d’un cluster.
Un composant central, appelé le driver, analyse le code à exécuter et orchestre l’ensemble du calcul. Il découpe le travail à effectuer et le distribue à des processus appelés executors, chargés d’exécuter les calculs en parallèle.
Lorsqu’un traitement est lancé, Spark le structure en plusieurs niveaux :
une action déclenche un job ;
le job est découpé en stages ;
chaque stage est exécuté via plusieurs tasks, réparties sur les executors.
Une exécution optimisée par conception
Un principe fondamental de Spark est celui de l’exécution paresseuse (lazy execution).
Spark ne calcule pas immédiatement les transformations que vous décrivez dans votre code. Il commence par :
analyser l’ensemble des opérations demandées,
construire un plan logique,
optimiser ce plan,
puis exécuter réellement le calcul uniquement lorsqu’un résultat est nécessaire.
Cette approche permet à Spark d’optimiser automatiquement les performances, même sur de très gros volumes de données, sans intervention explicite du développeur.
Lisez et écrivez des tables Delta Lake avec Spark
Spark s’intègre naturellement avec Delta Lake. Lorsqu’il lit une table Delta, Spark ne se contente pas d’ouvrir des fichiers Parquet. Il commence par consulter le journal des transactions (_delta_log), qui décrit l’état logique de la table. À partir de ce journal, Spark reconstruit la version courante de la table, puis lit uniquement les fichiers nécessaires.
df = spark.read.format("delta").load("/data/sensors_delta")
df.show()De la même manière, lorsqu’il écrit des données :
df.write.format("delta") \
.mode("append") \
.save("/data/sensors_delta")Spark garantit que :
l’écriture est atomique,
une nouvelle version de la table est créée,
l’historique reste accessible.
Chez GreenFarm, ce mécanisme permet à plusieurs pipelines de fonctionner simultanément, sans risque de corruption des données.
Découvrez Databricks : plus qu’un simple environnement Spark
Apache Spark et Delta Lake sont des technologies puissantes, mais leur exploitation directe peut rapidement devenir complexe. Gestion des clusters, configuration, sécurité, collaboration, supervision… autant de sujets qui détournent les équipes data de leur objectif principal : créer de la valeur à partir des données. Databricks est une plateforme de données unifiée et ouverte, construite autour de l’architecture Lakehouse, dont l’objectif est de couvrir l’ensemble du cycle de vie de la donnée, de l’ingestion jusqu’à l’analyse et au machine learning.
Elle fournit :
un environnement Spark prêt à l’emploi ;
des notebooks collaboratifs pour écrire, documenter et partager le code ;
une intégration native avec Delta Lake ;
des mécanismes pour structurer les usages et sécuriser les accès.
Databricks a été créée par les inventeurs mêmes d’Apache Spark. On retrouve en effet les créateurs de :
Apache Spark, le moteur de calcul distribué,
Delta Lake, le format de tables transactionnelles,
le pattern Lakehouse, qui unifie data lake et data warehouse,
et MLflow, pour la gestion du cycle de vie du machine learning.
Une plateforme au service de plusieurs usages
Dans une architecture Lakehouse moderne, Databricks s’adresse à plusieurs types d’usages, souvent portés par des équipes différentes.
Pour les data engineers, la plateforme facilite :
le développement et l’exécution de pipelines de données à grande échelle ;
la gestion des tables Delta Lake (création, mise à jour, maintenance) ;
l’industrialisation des traitements batch ou streaming.
Pour les data analysts, Databricks permet :
d’explorer les données stockées dans le Lakehouse ;
d’exécuter des analyses reproductibles ;
de partager des résultats dans des notebooks collaboratifs.
Pour les data scientists et équipes machine learning, Databricks fournit un environnement unifié pour :
expérimenter des modèles ;
entraîner et évaluer des algorithmes ;
gérer le cycle de vie des modèles.
Toutes les équipes travaillent ainsi sur les mêmes données, avec les mêmes formats, sans duplication inutile.
MLflow, IA générative et analytique augmentée
Databricks intègre également des briques dédiées au machine learning et à l’IA, directement connectées aux données du Lakehouse.
La plateforme s’appuie notamment sur MLflow, un outil open source qui permet de :
suivre et comparer des expériences de machine learning ;
versionner des modèles et leurs paramètres ;
structurer le passage de l’expérimentation à la production.
Au-delà du machine learning classique, Databricks propose aujourd’hui une offre complète autour de l’IA générative. Il est possible d’exploiter des modèles de fondation (LLM) directement depuis Databricks, tout en les connectant aux données stockées dans le Lakehouse.
Parmi ces fonctionnalités, on retrouve notamment Databricks Genie, qui permet d’interroger les données en langage naturel, ainsi que des agents spécialisés, capables d’orchestrer des appels à des modèles GenAI en s’appuyant sur les tables Delta, les métadonnées et les données du Lakehouse.
Pour vous permettre de pratiquer dans un environnement proche de celui utilisé en entreprise, Databricks propose une Free Edition, accessible à tous.
Cette version est conçue pour l’apprentissage et l’expérimentation :
aucune carte bancaire n’est requise ;
un environnement Spark est immédiatement disponible ;
vous pouvez manipuler de vraies tables Delta Lake.
Même si cette édition reste plus limitée qu’un environnement de production, elle permet de comprendre concrètement comment Spark et Delta Lake sont utilisés dans une architecture Lakehouse.
Dans ce screencast, vous allez pouvoir découvrir les fonctionnalités de la plateforme Databricks, à travers un compte Free Edition.
À vous de jouer !

Consigne
Créez un compte Databricks Free Edition.
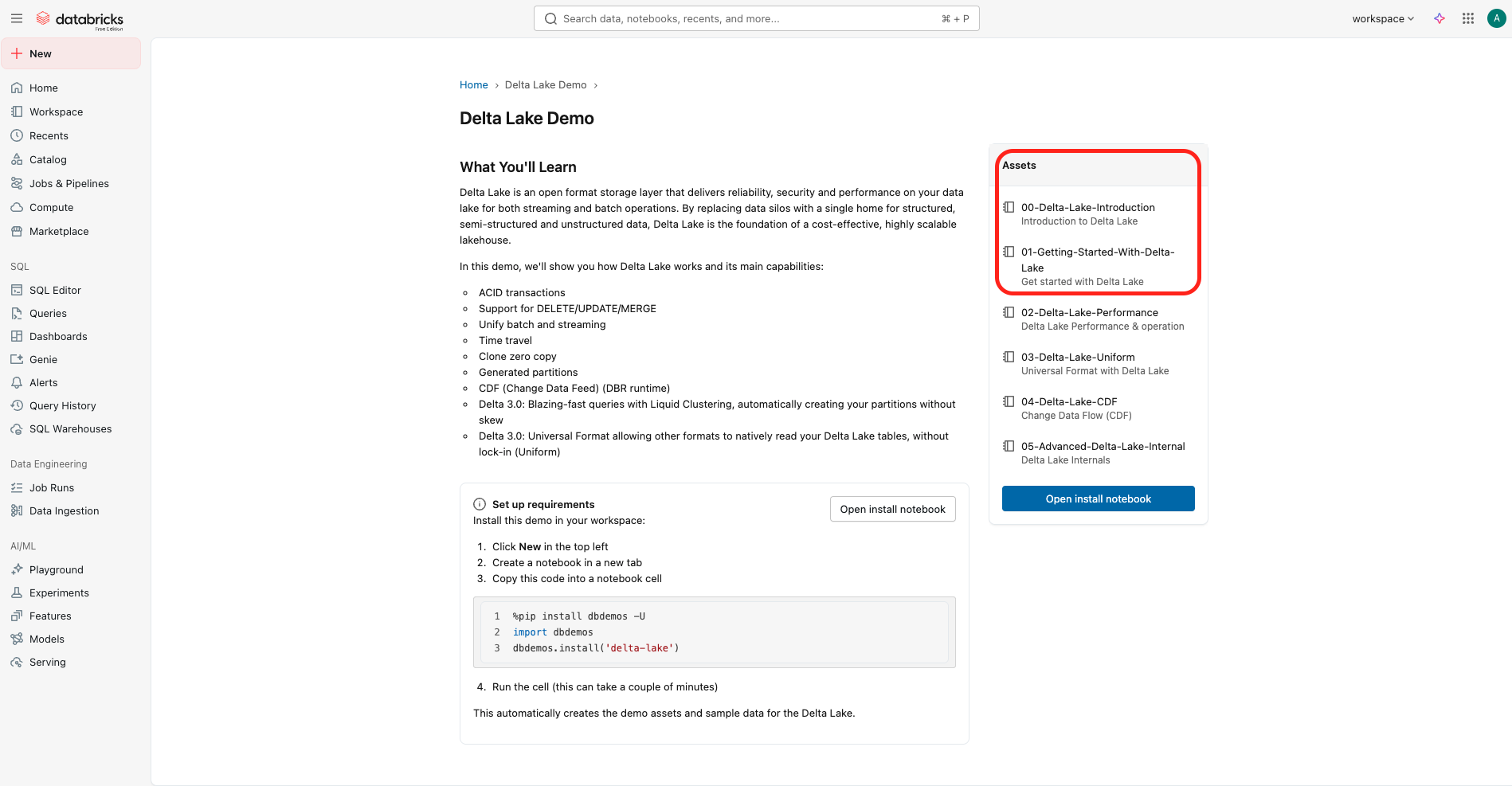
Lancer le Delta Lake Demo, sur la page d'accueil, sous le Pre-built demos (ou copier coller cette url à la suite de votre url existante: /tutorial/delta-lake-demo, exemple d’URL complète: https://dbc-db654913-986e.cloud.databricks.com/tutorial/delta-lake-demo)
Faites l’Asset 00-Delta-Lake-Introduction Introduction to Delta Lake.
Faites l’Asset 01-Getting-Started-With-Delta-Lake Get started with Delta Lake.
En résumé
Le Lakehouse est un pattern d’architecture qui sépare clairement le stockage des données et leur traitement, tout en garantissant cohérence, traçabilité et évolutivité. Lorsque les volumes et la fréquence des traitements augmentent, le calcul distribué devient un levier clé pour passer à l’échelle.
Apache Spark permet de traiter efficacement de grands volumes de données en s’appuyant directement sur le data lake et sur des formats ouverts comme Delta Lake. L’exécution paresseuse et l’optimisation automatique font de Spark un moteur particulièrement adapté aux workloads analytiques complexes.
Databricks propose une plateforme Lakehouse unifiée, conçue par les créateurs de Spark, Delta Lake et MLflow, qui simplifie l’exploitation de ces technologies. La plateforme couvre l’ensemble des usages data : ingénierie des données, analytique, machine learning et IA générative, en s’appuyant sur des briques comme MLflow, Genie et des agents spécialisés.
La Databricks Free Edition permet de se familiariser concrètement avec cet environnement, dans des conditions proches de celles rencontrées en entreprise.
Vous comprenez maintenant l’environnement d’exécution dans lequel évoluent les tables Delta de GreenFarm. Dans le prochain chapitre, vous allez plonger au cœur de Delta Lake et découvrir comment optimiser, gouverner et maintenir vos tables à grande échelle.
