Utilisez des protocoles de routage
Dans cette nouvelle partie, vous allez découvrir comment sont envoyés les messages à travers Internet. C’est ce que l’on appelle les protocoles de routage. Vous pouvez le comparer avec la route que vous empruntez pour aller de votre domicile à celui de votre ami.
À chaque carrefour, vous devez faire des choix, ces choix doivent vous amener chez lui. C’est la même chose pour les paquets que vous envoyez sur Internet, chaque paquet doit, à chaque passage de routeur, se diriger vers une route l'emmenant vers sa destination. Vous apprendrez donc différents protocoles de routage (EIGRP, OSPF) issus de deux familles de protocoles (à état de lien, à vecteur de distance).
Dans ce chapitre, je vous propose d’en apprendre un peu plus sur ce qu’est un protocole de routage. Allez, c’est parti !
Découvrez les protocoles de routage interne
Les protocoles que vous allez étudier vous permettront de configurer des réseaux de petites et moyennes tailles, par exemple un réseau d’entreprise ou celui d’un opérateur. On appelle cela un IGP pour Internal Gateway Protocol (Protocole de Routage Interne). Ils se différencient des EGP pour External Gateway Protocol (Protocole de Routage Externe), utilisés entre deux opérateurs par exemple
Avec cet IGP, vous devez diriger un paquet d’un point A à un point B.
Apprenez à vous diriger
Les directions en réseau s’effectuent uniquement avec la couche 3 du modèle OSI. C’est-à-dire la couche réseau ! Eh oui, certains noms ont du sens.
Cette adresse et ce masque fonctionnent comme une adresse postale : pour vous diriger vers le « 1 avenue des Champs Elysées à Paris », vous allez d’abord prendre l’autoroute direction Paris puis une fois entré dans la ville, vous allez affiner votre recherche. Votre adresse IP et son masque vont fonctionner de la même manière. Par exemple, pour diriger un paquet vers l’adresse 4.3.2.1/24, vous allez d’abord diriger le paquet vers une route 4.X.X.X puis 4.3.X.X puis 4.3.2.X et enfin tomber sur l’adresse de destination.
Il ne s’agit pas simplement d’amener un paquet d’un point A à un point B mais aussi, et surtout, de le faire selon certains critères.
Acheminez un paquet par le chemin le plus court
En général, l’idée sera de rechercher le chemin le plus court entre un point A et un point B. Effectivement, sur un réseau bien fait, il existe plusieurs routes possibles pour pallier les pannes ou la congestion du réseau (les embouteillages).
Pour trouver ce chemin, vous allez utiliser des protocoles qui utilisent des algorithmes comme pour le spanning-tree !
On dit que ces algorithmes sont distribués et itératifs :
Distribués, car ils sont exécutés sur chaque routeur et non pas sur un serveur centralisé. Ce sont donc les routeurs qui choisissent le chemin et non le paquet. Un peu comme si vous étiez obligé de suivre votre GPS.
Itératifs, car ils sont exécutés en boucle, ce qui permet le passage à l'échelle, lorsque l’on ajoute un routeur et la détection de pannes, si un routeur tombe en panne. L’algorithme notera ces modifications dès sa prochaine itération.
Vous configurerez donc ces protocoles sur chaque routeur et ils feront ensuite le travail tout seul ce qui vous facilitera la vie. En effet, vous pourriez aussi créer les routes à la main (on appelle ça le routage statique), c’est d’ailleurs ce que vous avez fait sur votre routeur pour configurer la route par défaut. Cependant, cette façon de faire deviendrait très difficile à maintenir en cas de panne.
Ces algorithmes étant décentralisés, chaque routeur ne connaît que le prochain saut sur lequel il doit envoyer le paquet. Un routeur ne connaît donc pas le chemin entier d’un point A à un point B, mais il sait quelle direction il doit prendre. Cette direction se trouve dans ce que l’on appelle une table de routage.
Faites passer les paquets routeur par routeur
Exemple de table de routage :
Adresse | Masque | Passerelle | Interface | Métrique |
0.0.0.0 | 0.0.0.0 | 1.1.1.2 | 1.1.1.1 | 1 |
4.3.2.0 | /24 | 4.3.2.2 | 4.3.2.3 | 1 |
8.7.6.0 | /24 | 8.7.6.6 | 8.7.6.7 | 1 |
La première ligne est la route par défaut, si le routeur ne connaît pas la route qu’il doit prendre, il envoie le paquet vers la passerelle concernée (1.1.1.2) par son interface (1.1.1.1). La métrique, c’est le coût entre un routeur et un autre, souvent calculé en fonction de la bande passante entre les deux, comme pour le spanning-tree.
Ces tables de routage sont alimentées par les protocoles de routage. Même si les protocoles de routage sont différents, la finalité est la même : mettre à jour les tables de routage.
Justement, voyons ces différents protocoles. Il en existe de nombreux, regroupés en deux grandes familles.
Découvrez les deux familles de protocoles
Deux familles se partagent les différents protocoles de routage :
Les protocoles à vecteur de distance d’une part,
Et le routage à état de lien d’autre part.
Ces deux familles ont leurs particularités et leurs ressemblances. Vous allez les découvrir dans ce chapitre !
Les protocoles à vecteur de distance
Le but du protocole de routage est donc de remplir la table de routage d’un routeur. Cette table de routage est remplie en choisissant le meilleur chemin vers un réseau. Pour choisir le meilleur chemin, le routeur se base sur le nombre de sauts qu’il doit parcourir pour atteindre un réseau. Chaque saut représente un routeur à traverser. Il s’agit en fait de l’algorithme de Bellman-Ford. Les routeurs voisins s’échangent leurs informations afin de remplir leur table de routage. Pour vous aider à comprendre, prenons un exemple où chaque routeur cherche la meilleure direction pour aller au routeur R1 :
Ici R1 s’annonce à R2 et R2 ajoute R1 à sa table de routage qui vaut 1 saut.
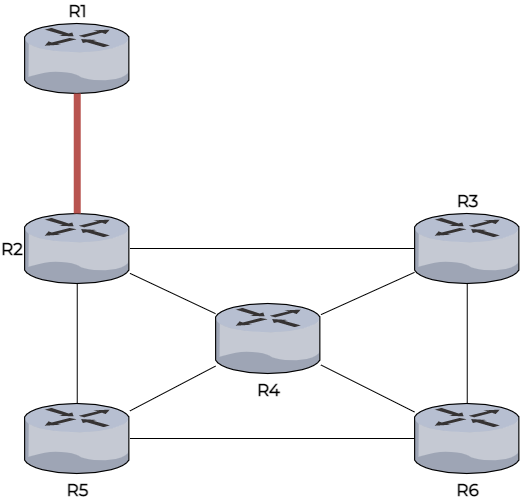
R2 transmet l’information à R3, R4 et R5 qui mettent à jour leurs tables de routage, avec comme valeur 2 sauts pour se rendre à R1.
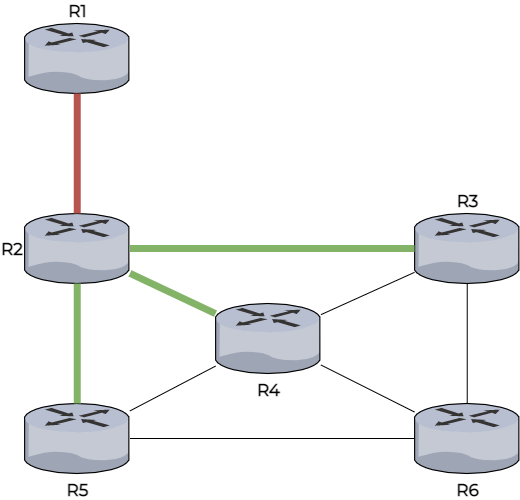
R4 reçoit l’information de plusieurs routeurs :
De R2 une distance de 2 sauts
De R3 et R5 il reçoit une distance de 3 sauts.
R4 choisit donc pour sa table de routage le chemin passant par R2 (le plus court chemin).
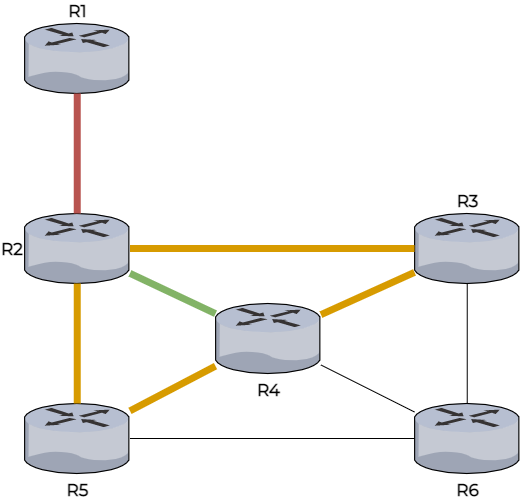
R6 reçoit à son tour des informations de R3, R4 et R5 mais chaque routeur lui donne le même nombre de sauts.
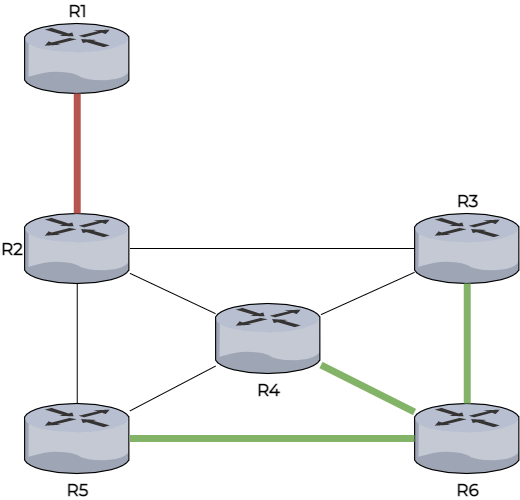
Il choisit donc aléatoirement son chemin vers R1 ou en fonction du nom du routeur ou de son adresse MAC. Ici, il choisit R3.
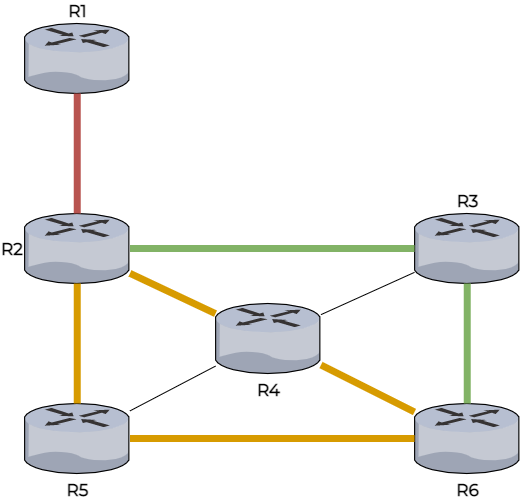
Chaque routeur connaît donc le chemin à suivre pour rejoindre R1. Cette opération se répète pour chaque routeur afin de remplir les tables de routage de tous les routeurs. En cas de panne, la mise à jour périodique de cet algorithme permet aux tables de routage de se mettre à jour avec de nouvelles routes, même si cela peut prendre un certain temps avant de se diffuser à l’ensemble du réseau. Le gros avantage ? Ces informations ne sont pas gourmandes en ressource (CPU, RAM) pour le routeur.
Voyons maintenant la deuxième famille de protocole : les protocoles de routage à état de lien.
Les protocoles de routage à état de lien
Le but ici aussi est de remplir la table de routage de chaque routeur.
En quoi ce protocole est différent, dans ce cas ?
Tout d’abord, dans ce protocole, chaque routeur va avoir connaissance de la topologie du réseau, là où les protocoles de routage à vecteur distance ne connaissaient que les prochains sauts pour rejoindre un réseau distant. D’autre part, la qualité de la bande passante est prise en compte dans ce protocole afin d’établir la meilleure route.
Dans ce type de protocole, chaque routeur va ainsi commencer par établir la liste de ses voisins directs, en leur envoyant des messages, que l’on appelle Hello. Ses messages contiennent l’adresse IP/Masque ainsi que la bande passante.
Observez par exemple R2. Il va établir sa table de voisinage en envoyant des messages à R1, R3, R4 et R5.
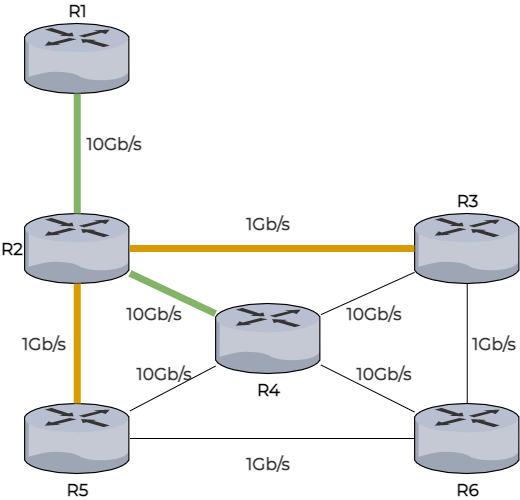
Ainsi, il va obtenir cette table de voisinage :
Table de voisinage R2 | |
R1 | 10Gb/s |
R3 | 1Gb/s |
R4 | 10Gb/s |
R5 | 1Gb/s |
Et il ne va pas garder cette information pour lui ! Effectivement, R2 va la partager avec tous les routeurs du réseau, de R1 à R6 qui vont en faire de même avec leurs propres tables de voisinage. C’est ainsi que chaque routeur connaît la topologie entière du réseau.
Une fois cette topologie connue de tous, chaque routeur va alors créer une route vers chaque routeur du réseau. Pour créer cette route, les routeurs utiliseront l’algorithme de Dijkstra qui se sert du coût des routes, dans notre cas, de la bande passante. Je vous propose de regarder cela sans plus tarder, avec notre exemple où R1 cherche le meilleur chemin vers R6.
Le routeur R1 regarde le meilleur lien dont il dispose dans son voisinage, ici il n’y a que R2.
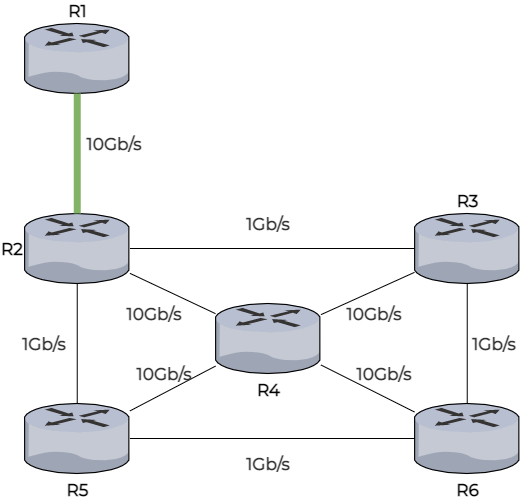
Il regarde ensuite depuis les routeurs qu’il a associés, le chemin le plus rapide vers un autre routeur. De R2 le chemin le plus rapide vers un autre routeur est le chemin le menant à R4.
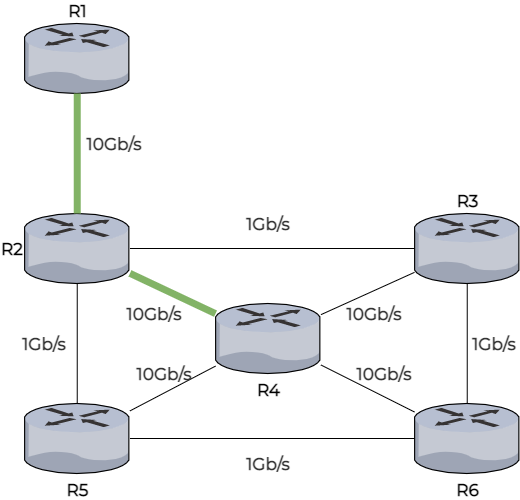
Les meilleurs chemins partant de R1, R2 ou R4 (c’est-à-dire le réseau connu) partent tous de R4 et permettent au routeur R1 de connaître la totalité des chemins menant aux autres routeurs. Le meilleur chemin pour R1 d'accéder à R6 est donc via R2 puis R4.
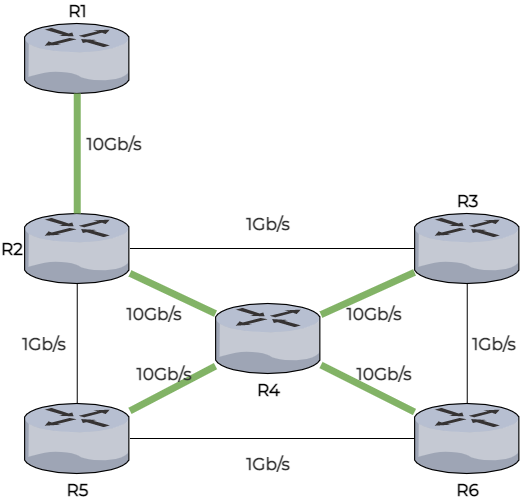
La totalité des chemins est maintenant connue du routeur R1. À l’inverse des protocoles à vecteur distance, la convergence est assez rapide. Le point négatif, vous l’avez probablement deviné, c’est bien sûr que la reconnaissance du réseau demande beaucoup de ressources aux routeurs. D’après mon expérience, ce type de protocole demande un peu plus de travail à l’installation.
Vous savez maintenant ce qu’est un protocole de routage et vous connaissez les deux familles utilisées dans le monde du réseau. Je vous propose de rentrer un peu plus dans les détails dans les prochains chapitres, et d’en étudier deux spécifiquement : EIGRP (vecteur de distance) et OSPF (état de lien).
En résumé
Un IGP est un protocole de routage interne (d’une entreprise ou d’un fournisseur d’accès).
Un protocole de routage sert à créer la table de routage d’un routeur.
Les tables de routage servent à acheminer un paquet vers sa destination.
Le protocole de routage n’utilise que la couche 3 (réseau) pour créer les tables de routage.
Il existe 2 types de protocoles de routage :
À état de lien. Les caractéristiques des routeurs : connaissance du réseau, convergence rapide, gourmande en ressource.
À vecteur distance : Les caractéristiques des routeurs : pas de connaissance du réseau ni de tous leurs voisins, convergence lente, peu gourmande en ressource.
